Ein LLM-API-Gateway ist die Steuerungsebene zwischen Anwendungscode und mehreren Modellanbietern. Die nützliche Architektur ist nicht nur eine Proxy-URL. Sie muss Aufrufer authentifizieren, Modelle zuordnen, Richtlinien anwenden, eine Upstream-Route auswählen, Kontingente durchsetzen, Nutzung protokollieren, Kosten berechnen und entscheiden, was passiert, wenn ein Anbieter ausfällt.
Dieser Leitfaden bietet Platform Engineers ein praktisches LLM-API-Gateway-Architekturdiagramm für Multi-Provider-Routing und Failover. Er verwendet öffentliche Gateway-Muster von Vercel und Pydantic als Kategorien-Referenzen und beschränkt dann Flatkey-spezifische Aussagen auf den aktuellen öffentlichen Nachweis: ein API-Schlüssel, ein OpenAI-kompatibler Router-Endpunkt unter https://router.flatkey.ai/v1, klare Preisgestaltung, einheitliche Abrechnung, ein Dashboard für Schlüssel, Nutzung und Routing, automatisches Umschalten und Lastverteilung.
Das Ziel ist, Ihnen zu helfen, das Design zu überprüfen, bevor der Produktionsverkehr davon abhängt. Verwenden Sie das Diagramm als Checkliste für Ihr eigenes Gateway, eine Anbieterevaluierung oder einen Flatkey-Staging-Test.
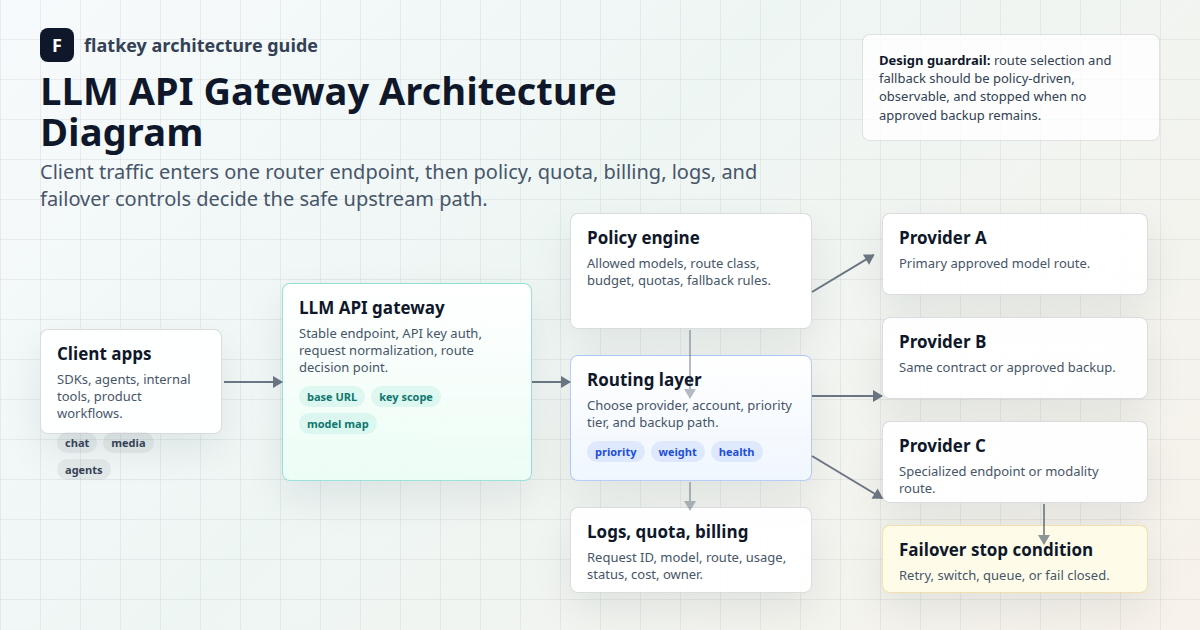
LLM API-Gateway-Architekturdiagramm
Das Diagramm zeigt den Anfragepfad von Client-Apps zu Upstream-Modellanbietern. Im Zentrum der Architektur steht das LLM API-Gateway. Darum herum liegen die Policy-Services, die den sicheren Betrieb des Routings gewährleisten: Key-Scope, Modellzuordnung, Routenkategorie, Kontingent-Ledger, Abrechnung, Logs, Health Checks und Fallback-Regeln.
| Ebene | Verantwortung | Designfrage |
|---|---|---|
| Client-Apps | Senden Chat-, Response-, Bild-, Video-, Agenten- oder Tool-Anfragen. | Welche SDKs und Endpunktformate müssen weiterhin funktionieren? |
| Gateway-Endpunkt | Nimmt Anfragen über eine stabile Basis-URL und einen API-Schlüssel entgegen. | Können Anwendungen migrieren, indem sie nur den Schlüssel, die Basis-URL oder die Provider-Konfiguration ändern? |
| Authentifizierung und Key-Scope | Identifiziert Aufrufer, Team, App, Umgebung und den zulässigen Modellsatz. | Können Staging-, Produktions- und Kundentraffic getrennt werden? |
| Policy-Engine | Wendet Modellzuordnung, Routenkategorie, Budget, Kontingent und Fallback-Regeln an. | Erklärt die Policy, warum eine Anfrage eine Route verwenden kann oder nicht? |
| Router | Wählt einen Upstream-Provider, ein Konto, ein Modell oder einen Backup-Pfad aus. | Basiert das Routing auf freigegebener Policy statt auf versteckter Magie? |
| Health und Failover | Verfolgt Provider-Fehler, Timeouts, Retries, Fallback und Stoppbedingungen. | Welche Ausfälle sollten erneut versucht, umgeschaltet, in eine Warteschlange gestellt oder geschlossen fehlgeschlagen werden? |
| Logs, Kontingent und Abrechnung | Erfasst Modell, Route, Status, Token- oder Media-Einheiten, Kosten, Owner und Key. | Können Engineers und Finance eine Anfrage nach einem Vorfall nachverfolgen? |
| Upstream-Provider | Stellen das ausgewählte Modell über provider-native oder kompatible APIs bereit. | Welche Provider sind für jede Traffic-Klasse freigegeben? |
Wie eine Anfrage durch das Gateway läuft
Ein produktives LLM-API-Gateway sollte den Anfragepfad leicht erklärbar machen. Wenn Ihr Team den Pfad nicht zeichnen kann, können Sie den Pfad bei einem Ausfall oder einer Abrechnungsprüfung wahrscheinlich auch nicht debuggen.
- Der Client sendet eine Anfrage. Die App ruft das Gateway mit einem Modellnamen, einem Endpoint, Nachrichten oder Medieneingaben und einem Anwendungs-API-Schlüssel auf.
- Das Gateway authentifiziert den Schlüssel. Der Schlüssel wird einem Eigentümer, einer Umgebung, einem Kontingent, einem erlaubten Modellset und einer Logging-Richtlinie zugeordnet.
- Die Policy-Engine klassifiziert den Traffic. Die Anfrage wird als Kunden-Chat, Hintergrundarbeit, Evaluierung, Mediengenerierung, Coding-Tool-Traffic oder eine andere Routing-Klasse markiert.
- Der Router wählt eine Kandidatenroute aus. Er prüft Modellzuordnung, Verfügbarkeit des Providers, erlaubte Upstream-Konten, Kostenrichtlinie, Kontingentstatus und jede konfigurierte Priorität oder Gewichtung.
- Das Gateway sendet die Upstream-Anfrage. Je nach Provider und Endpoint kann dies eine mit OpenAI kompatible Anfragestruktur beibehalten oder ein provider-natives Protokoll verwenden.
- Die Antwort wird, soweit möglich, normalisiert. Das Gateway gibt die erwartete Antwortstruktur, einen Fehler, einen Stream oder eine Job-Referenz an den Client zurück.
- Die Anfrage wird protokolliert. Logs erfassen Route, Modell, Status, Latenz, Nutzungseinheiten, Kostenschätzung, Schlüssel und Eigentümer, damit das Team Ausgaben debuggen und abgleichen kann.
Deshalb ist der Schritt der OpenAI-kompatiblen API-Migration nur ein Teil der Architektur. Das Ändern einer Basis-URL bringt den Traffic zum Gateway. Produktionsreife hängt danach von Policy, Routing, Kontingent, Billing, Logs und Fallback-Verhalten ab.
Routing-Policy steht vor Failover
Der häufigste Architekturfehler besteht darin, Failover als universell gut zu behandeln. Ein LLM API gateway sollte nicht blind jede fehlgeschlagene Anfrage gegen jeden Anbieter erneut senden. Es sollte zuerst entscheiden, ob der Backup-Pfad für diese Traffic-Klasse erlaubt ist.
Öffentliche Gateway-Dokumentationen zeigen, warum diese Unterscheidung wichtig ist. Pydantic dokumentiert Routing-Gruppen, bei denen Anbieter Priorität, Gewichtung und aktiven Status haben können, sodass Failover zwischen Anbietern, die dasselbe Modell bedienen, oder Lastverteilung über Mitglieder mit derselben Priorität möglich ist. Vercel positioniert AI Gateway rund um Routing, Billing, Observability, viele Modelle sowie Provider-/Modell-Routing mit Fallbacks. Diese Muster sind nützliche Referenzen, aber Ihre Produktionsrichtlinie muss dennoch definieren, was für Ihre Workload akzeptabel ist.
| Traffic Class | Primary Routing Rule | Failover Rule |
|---|---|---|
| Customer-facing chat | Use only approved model families and providers. | Switch only to an approved equivalent, or return a controlled error. |
| Background summarization | Prefer cost and throughput when quality requirements are stable. | Retry, queue, or use a lower-cost approved model if output quality remains acceptable. |
| Evaluation and benchmarks | Keep model identity stable. | Fail closed; hidden fallback makes results hard to compare. |
| Media generation | Respect endpoint shape, job lifecycle, media policy, and budget. | Fail closed unless the alternate model has the same approved output contract. |
| Agent workflows | Respect tool support, context limits, data boundary, and audit needs. | Fallback only when tool behavior and data handling stay valid. |
Flatekys öffentliche Beschreibung sagt, dass es mehrere Upstream-Accounts mit automatischem Switching und Lastverteilung routet. Nutzen Sie das als produktiven Ausgangspunkt und definieren Sie dann, welche Ihrer Traffic-Klassen automatisch wechseln dürfen und welche geschlossen fehlschlagen müssen.
Failover braucht eine Stoppbedingung
Jedes Failover-Design für ein LLM-API-Gateway braucht eine Stoppbedingung. Ohne eine solche kann eine fehlerhafte Anfrage zu einer Kaskade wiederholter ungültiger Aufrufe, doppelten Ausgaben, verwirrenden Logs und inkonsistentem Nutzerverhalten werden.
Eine praktische Fehlerleiter sieht so aus:
- Vor dem Upstream ablehnen: bei ungültiger Authentifizierung, verbotenem Modell, überschrittenem Kontingent, nicht unterstütztem Endpunkt oder fehlenden erforderlichen Parametern geschlossen scheitern.
- Dieselbe Route erneut versuchen: nur erneut versuchen, wenn der Fehler plausibel vorübergehend ist, etwa ein Netzwerk-Timeout oder ein ausgewählter Upstream-5xx-Fehler.
- Dasselbe Vertragsschema wechseln: ein anderes Konto, eine andere Region oder einen anderen Provider-Pfad nur dann verwenden, wenn er denselben freigegebenen Modellvertrag bedient.
- Freigegebenes Backup nutzen: zu einem anderen Modell wechseln, nur wenn Produkt-, Qualitäts-, Compliance- und Budgetverantwortliche das Backup genehmigen.
- In Warteschlange stellen oder degradieren: nicht dringende Arbeit verzögern, wenn ein sofortiges Fallback teuer oder riskant wäre.
- Kontrollierten Fehler zurückgeben: stoppen, wenn die Richtlinie sagt, dass kein sicherer Weg mehr bleibt.
Der Leitfaden zu Load Balancing und Failover für KI-APIs behandelt dies ausführlicher. Bei der Architekturprüfung ist die wichtigste Frage, ob jeder Übergang explizit und beobachtbar ist.
Quota, Abrechnung und Protokolle sind Teil des Request-Pfads
Modelverkehr wird nicht wie gewöhnlicher HTTP-Verkehr abgerechnet. Ein einzelnes LLM-API-Gateway muss möglicherweise Eingabetokens, Ausgabetokens, gecachte Tokens, Reasoning-Tokens, Bildeinheiten, Videodauer, Tool-Aufrufe, Retries und anbieterspezifische Quota-Einheiten berücksichtigen. Wenn Abrechnung und Quota als nächtlicher Bericht behandelt werden, kann das Gateway den eskalierenden Verbrauch in dem Moment nicht verhindern.
Platzieren Sie Quota und Abrechnung nahe an der Routing-Policy:
- Prüfen Sie das verbleibende Budget des Aufrufers, bevor Sie teure Anfragen weiterleiten.
- Blockieren oder warnen Sie bei Routen mit fehlenden Preisdaten, wenn Ausgabelimits wichtig sind.
- Protokollieren Sie das ausgewählte Modell, die Endpunktfamilie, die Upstream-Route, den Schlüssel, den Eigentümer, den Status und die Nutzungseinheiten.
- Trennen Sie Retries und Fallback-Aufrufe in den Logs, damit eine Benutzeranfrage nicht mehrere Anbieter-Versuche verdeckt.
- Machen Sie Staging- und Production-Keys als unterschiedliche Kostenstellen sichtbar.
- Exportieren Sie genügend Daten für Finance, Support und Incident-Reviews.
Flatkeys aktuelle öffentliche Positionierung umfasst transparente Preise, einheitliche Abrechnung, Nutzungsübersicht, Quotalimits und ein Dashboard für Schlüssel, Nutzung und Routing. Ein Pricing-API-Snapshot vom Veröffentlichungstag lieferte 656 Modellzeilen und unterstützte Endpunktmetadaten für OpenAI-kompatiblen, OpenAI Responses, Anthropic, Gemini, Bildgenerierungs- und Videogenerierungsverkehr. Betrachten Sie dies als veralteten Beleg und prüfen Sie dann Ihr genaues Modell und Ihre Einheit auf der live Preisseite.
Wo Flatkey in diese Architektur passt
Flatkey wurde entwickelt, um die Ausuferung von Anbieter-Accounts hinter einem Schlüssel zu reduzieren. In dieser Architektur für ein LLM API gateway ordnet sich Flatkey dem gehosteten Gateway-Endpunkt, der Provider-Zugangsschicht, der Dashboard-, Nutzungs-/Abrechnungsschicht und der Routing-Schicht zu.
Ein sorgfältiger Flatkey-Staging-Test sollte so aussehen:
- Erstellen Sie einen Non-Production-Schlüssel im Flatkey-Dashboard.
- Richten Sie einen Client auf
https://router.flatkey.ai/v1aus. - Führen Sie eine bekannte, funktionierende Anfrage für die benötigte Endpunktfamilie aus.
- Bestätigen Sie, dass die Anfrage in den Nutzungsprotokollen mit Modell, Status, Einheiten und Kostennachweis erscheint.
- Prüfen Sie die Live-Preisseite für das ausgewählte Modell und die Abrechnungseinheit.
- Definieren Sie, welche Verkehrsklassen automatisches Umschalten oder Lastverteilung nutzen dürfen.
- Führen Sie einen sicheren Fehlertest aus oder dokumentieren Sie, warum Fehlerinjektion im Staging nicht erlaubt ist.
Leiten Sie aus diesem Artikel keine SLA für Verfügbarkeit, keine Latenzgarantie, keinen exakten Routing-Algorithmus und keine garantierte Verfügbarkeit von Anbietern ab. Die Architektur zeigt Ihnen, was zu validieren ist; Ihre Staging-Nachweise zeigen Ihnen, ob ein bestimmter Rollout bereit ist.
Implementierungs-Checkliste
Bevor Sie Produktionsverkehr über ein LLM-API-Gateway leiten, stellen Sie sicher, dass die Architektur diese Kontrollen implementiert hat:
| Checklistenpunkt | Bestehensbedingung |
|---|---|
| Basis-URL- und SDK-Migration | Mindestens eine Staging-Anfrage wird erfolgreich über das Gateway mit dem vorgesehenen SDK oder Client ausgeführt. |
| Modell- und Endpunktzuordnung | Jede Produktions-Endpunktfamilie hat ein freigegebenes Modell, Protokoll und einen Verantwortlichen. |
| Schlüsselbereich | Schlüssel werden bei Bedarf nach App, Umgebung, Team oder Kunde getrennt. |
| Routing-Richtlinie | Verkehrsklassen definieren zulässige Primärrouten und Backup-Routen. |
| Failover-Stoppbedingung | Das Gateway weiß, wann es erneut versuchen, wechseln, in die Warteschlange stellen und geschlossen fehlschlagen soll. |
| Kontingent- und Budgetprüfungen | Limits können teuren Verkehr stoppen oder einschränken, bevor er einen Upstream-Anbieter erreicht. |
| Protokolle und Observability | Anforderungs-, Routen-, Modell-, Verantwortlichen-, Status-, Nutzungs- und Kosten-Nachweise können nachträglich überprüft werden. |
| Rollback | Die App kann zu ihrer vorherigen Anbieterkonfiguration zurückkehren, wenn das Gateway-Rollout fehlschlägt. |
Für einen breiteren Anforderungsausblick beginnen Sie mit der AI-API-Gateway-Checkliste. Für die Plattformvergleichsarbeit zeigt der Leitfaden zu den OpenRouter-Alternativen, wie sich die Kompromisse bei verwalteten Gateways von Anbieter-Marktplätzen und selbst verwalteten Routing-Schichten unterscheiden.
FAQ
Was ist ein LLM-API-Gateway?
Ein LLM-API-Gateway ist eine Kontrollschicht zwischen Anwendungen und Modellanbietern. Es kann API-Schlüssel, Modellzugriff, Routing, Kontingente, Abrechnung, Protokolle und Failover-Richtlinien für LLM-Traffic zentralisieren.
Was sollte eine LLM-API-Gateway-Architektur enthalten?
Eine LLM-API-Gateway-Architektur sollte Client-Apps, einen stabilen Gateway-Endpunkt, Authentifizierung, Schlüsselscope, Richtlinienprüfungen, Modellzuordnung, Provider-Routing, Gesundheitsprüfungen, Failover-Regeln, Kontingente, Abrechnung, Protokolle und Upstream-Provider enthalten.
Ist Failover für LLM-Traffic immer sicher?
Nein. Failover ist nur dann sicher, wenn der Backup-Pfad den freigegebenen Modellvertrag, die Datenbegrenzung, das Endpunktverhalten, die Qualitätserwartungen und die Kostenrichtlinie beibehält. Manche Anfragen sollten lieber geschlossen fehlschlagen, anstatt umgeschaltet zu werden.
Worin unterscheidet sich ein LLM-API-Gateway von einem normalen API-Gateway?
Ein normales API-Gateway verarbeitet allgemeinen API-Traffic. Ein LLM-API-Gateway ergänzt modellbezogene Aspekte wie Anbieterformate, Token- und Mediennutzung, Modellzuordnung, Fallback-Richtlinien, Ausgabekontrollen, Observability für Prompts/Antworten und KI-spezifisches Routing.
Wo passt Flatkey in das Diagramm?
Flatkey passt als gehostete Gateway-, Router-, Provider-Zugriffs-, Nutzungs-, Abrechnungs- und Dashboard-Schicht. Der öffentliche Text unterstützt einen API-Schlüssel, https://router.flatkey.ai/v1, klare Preise, einheitliche Abrechnung, Sichtbarkeit von Nutzung/Routing, automatisches Umschalten und Lastverteilung.
Fazit
Ein produktionsreifes LLM API Gateway sollte den Modellverkehr leichter kontrollierbar machen, nicht schwerer zu erklären. Die Architektur braucht einen stabilen Endpunkt, eingeschränkte Schlüssel, Modellzuordnung, Richtlinienprüfungen, Routing-Regeln, Quoten- und Abrechnungskontrollen, Protokolle und eine Failover-Stop-Bedingung.
Flatkey gibt Teams einen Schlüssel, einen mit OpenAI kompatiblen Router-Endpunkt und ein einziges Dashboard für Modellerzugriff und Betrieb. Um die Architektur mit Ihrer eigenen Staging-Workload zu testen, holen Sie sich einen Schlüssel und überprüfen Sie den Request-Pfad, bevor Sie produktiven Traffic umstellen.