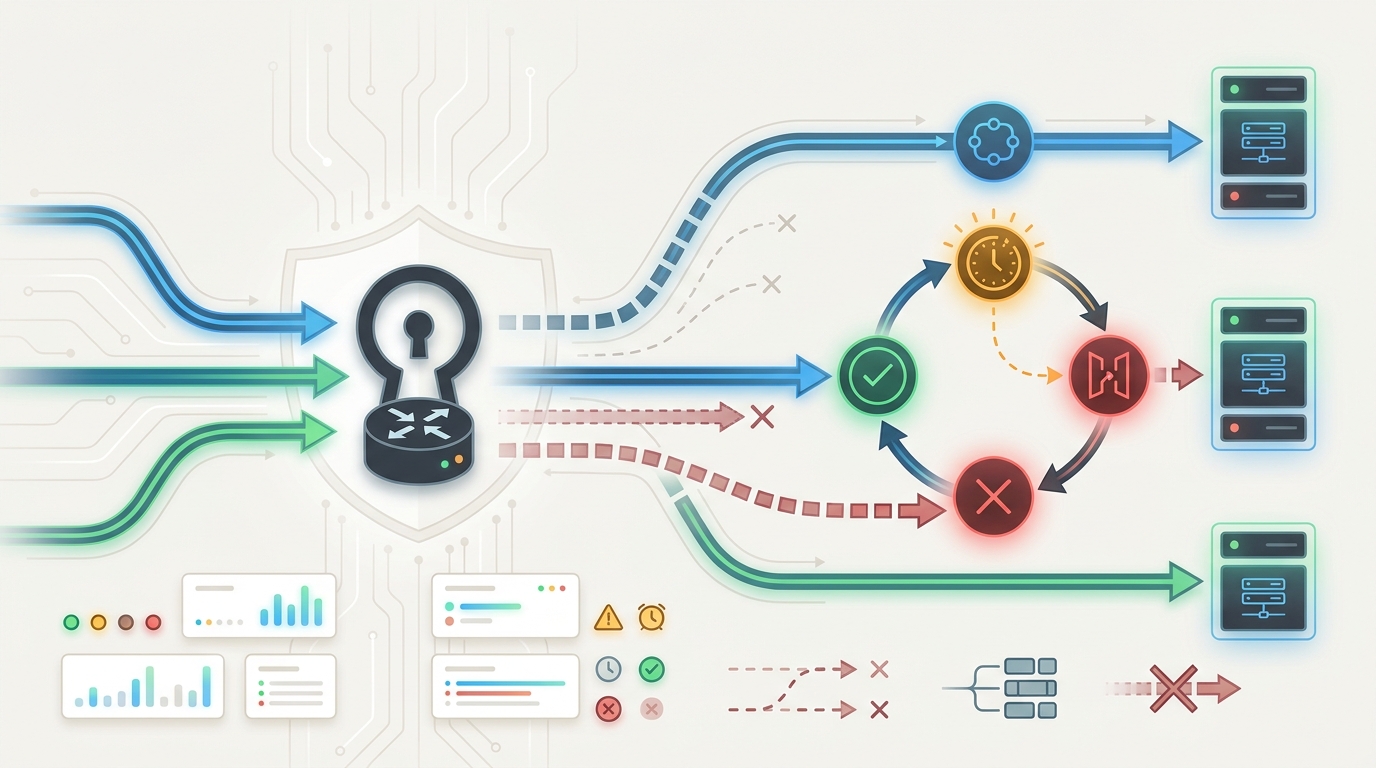
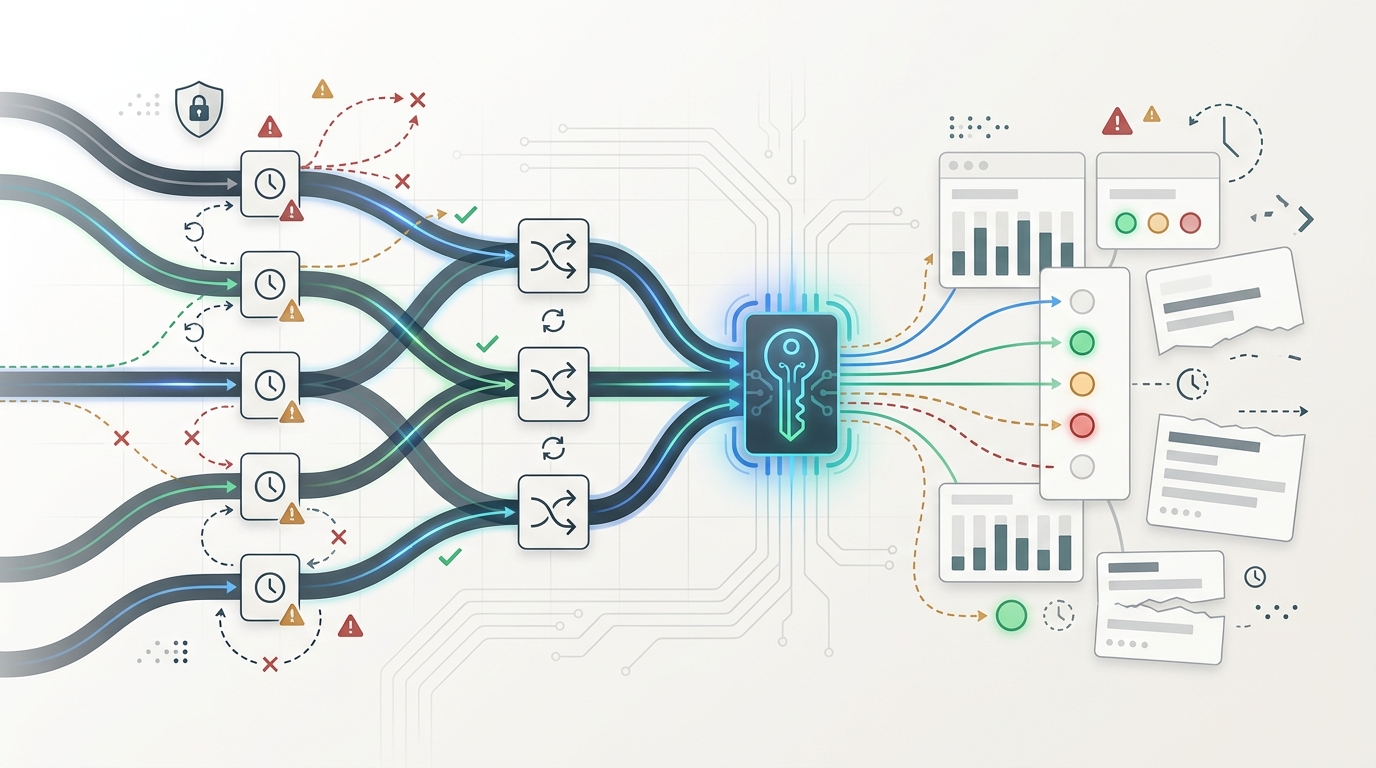
AI API-Load Balancing ist die Zuverlässigkeitsschicht zwischen Ihrer Anwendung und den Modellanbietern, die Produktionsverkehr bedienen. Sie entscheidet, wohin jede Anfrage geht, was passiert, wenn ein Upstream-Konto langsam oder nicht verfügbar ist, wann erneut versucht wird, wann gewechselt wird und wie Ingenieure die Entscheidung nach einem Vorfall nachweisen.
Für Teams, die mehrere Modellanbieter verwenden, besteht die eigentliche Herausforderung nicht nur darin, „Traffic irgendwo anders hinzuschicken“. Die eigentliche Herausforderung besteht darin, eine Richtlinie festzulegen, die Benutzererlebnis, Kosten, Kontingente, Datenverarbeitung und Debugging schützt. Ein Gateway mit nur einem Schlüssel kann die Integration vereinfachen, aber die Routing-Regeln müssen dennoch so eindeutig sein, dass Plattformingenieure sie testen können, bevor der Produktionsverkehr davon abhängt.
Flatkeys öffentliche Produkttexte unterstützen diesen Zuverlässigkeitsaspekt in vorsichtigen Formulierungen: Sie verweisen auf einen API-Schlüssel, eine OpenAI-kompatible Base-URL unter https://router.flatkey.ai/v1, ein Dashboard für Schlüssel, Nutzung und Routing sowie mehrere Upstream-Konten mit automatischem Wechsel und Load Balancing. Dieser Leitfaden übersetzt diese Produktsprache in ein praktisches Zuverlässigkeits-Playbook, ohne Verfügbarkeits-, Latenz- oder Incident-Response-Behauptungen aufzustellen, die nicht verifiziert wurden.
AI-API-Lastverteilung beginnt mit Fehlermodi
Beginnen Sie damit, die erwarteten Fehler aufzulisten. AI-API-Lastverteilung ist nur dann sinnvoll, wenn das Gateway eine Richtlinie für den Fehler davor hat. Ein Ausfall des Providers, ein modellspezifischer 500er, ein Rate Limit, ein aufgebrauchtes Guthaben, ein Spitzenwert bei der Latenz im langen Schwanz, ein fehlerhaftes Prompt und eine Ablehnung durch die Inhaltsrichtlinie sollten nicht alle denselben Fallback-Pfad auslösen.
| Fehlermodus | Häufiges Symptom | Zu definierende Routing-Entscheidung | Was protokolliert werden soll |
|---|---|---|---|
| Provider oder Upstream nicht verfügbar | 5xx-Fehler, Verbindungsfehler, fehlgeschlagene Health Checks. | Zu einem anderen Upstream-Konto oder Provider wechseln, der denselben Workflow bedienen kann. | Upstream, Fehlercode, Anzahl der Versuche, Fallback-Ziel. |
| Rate Limit oder Quota-Limit | 429, Guthabenwarnung, Quotenblockade. | Ein anderes freigegebenes Konto verwenden, Arbeit in eine Warteschlange stellen, Traffic reduzieren oder geschlossen fehlschlagen. | Limittyp, Team/Schlüssel, Modell, Retry-After, Kostenträger. |
| Langsame Antwort | Timeout, hohe Zeit bis zum ersten Token, hängender Stream. | Einmal erneut versuchen, Provider wechseln oder basierend auf dem Benutzer-Workflow einen kontrollierten Fehler zurückgeben. | Latenz, Timeout-Schwelle, ausgewählte Route, Auswirkung auf den Benutzer. |
| Modellspezifische Verschlechterung | Ein Modell fällt aus, während andere gesund bleiben. | Nur dann auf ein kompatibles Ersatzmodell zurückfallen, wenn Qualität und Richtlinie dies zulassen. | Primäres Modell, Ersatzmodell, Grund, Antwortmetadaten. |
| Anwendungs- oder Prompt-Fehler | 4xx-Validierungsfehler, fehlerhafter Request-Body, nicht unterstützter Parameter. | Nicht blind erneut versuchen. Die Client-Anfrage korrigieren oder einen präzisen Fehler zurückgeben. | Endpunkt, Parameter, Request-ID, Client-Version. |
Diese Tabelle ist die erste Schutzmaßnahme. Sie verhindert, dass Failover zu einer teuren Schleife wird, die dieselbe fehlerhafte Anfrage über jeden Provider hinweg wiederholt. Außerdem liefert sie Support und Finance die Daten, die sie benötigen, wenn eine Routenänderung Kosten oder Verhalten beeinflusst.
Trennen Sie Verkehrsklassen, bevor Sie routen
Produktionsverkehr sollte sich nicht eine undifferenzierte Routing-Richtlinie teilen. Dieselbe Regel für AI API load balancing passt selten für Chat-Completion, Batch-Evaluation, Bilderzeugung, Videoerzeugung, Hintergrund-Zusammenfassungen und agentische Antworten mit Kundenkontakt.
Gruppieren Sie den Traffic vor der Konfiguration des Routings in Klassen:
- Interaktiver Benutzerverkehr: priorisieren Sie niedrige Fehlerraten, kontrollierte Latenz und vorhersehbares Modellverhalten.
- Hintergrundaufträge: akzeptieren Sie Warteschlangen, verzögertes Retry und Routing mit geringeren Kosten, wenn Aktualität es zulässt.
- Evaluationsverkehr: bewahren Sie die Modellidentität, damit Benchmark-Daten nicht durch versteckte Fallbacks verfälscht werden.
- Hochwertige Workflows: verwenden Sie strengere Provider-Allowlists, stärkere Observability und manuelle Rollback-Gates.
- Experimentelle Workflows: isolieren Sie Quoten und Schlüssel, damit Tests kein Produktionsbudget verbrauchen können.
Sobald die Verkehrsklassen klar sind, kann die Gateway-Richtlinie einfach und prüfbar sein: welche Modelle erlaubt sind, welche Upstream-Konten im Pool sind, welche Fehler einen Wechsel auslösen und wer Änderungen an dieser Richtlinie genehmigt.
Build The Routing Policy Behind One Key
Eine One-Key-Architektur reduziert SDK- und Credential-Wildwuchs, aber die Richtlinie hinter dem Schlüssel braucht dennoch Struktur. Ein praktischer Plan für AI API load balancing hat vier Ebenen: Request-Klassifizierung, Auswahl des Anbieters oder Kontos, Failover-Regeln und Post-Request-Logging.
| Policy Layer | Question To Answer | Example Rule |
|---|---|---|
| Request classification | Welchen Workflow bedient diese Anfrage? | Kundensupport-Chat, nächtlicher Batch, Model-Evaluation, interne Automatisierung. |
| Allowed upstreams | Welche Konten, Anbieter oder Modelle dürfen diese Klasse bedienen? | Nur freigegebene Textmodelle für den Kundensupport-Chat; breiterer Pool für interne Entwürfe. |
| Load distribution | Wie wird gesunder Traffic verteilt? | Gewichteter Account-Pool, Anbieterpräferenz, kostenbewusste Route oder latenzbewusste Route. |
| Failover trigger | Wann stoppt das Gateway die Nutzung des aktuellen Pfads? | Verbindungsfehler, wiederholte 5xx, Timeout, Rate Limit oder Health-Check-Fehler. |
| Fallback target | Wohin soll die Anfrage als Nächstes gehen? | Dasselbe Modell auf einem anderen Upstream, freigegebenes Backup-Modell, Queue oder kontrollierter Fehler. |
| Observability | Wie weist das Team nach, was passiert ist? | Request-ID, ausgewählte Route, Attempt-Historie, Modell, Statuscode, Kosten, Tokens, Latenz. |
Vercels AI-Gateway-Dokumentation ist ein nützlicher öffentlicher Maßstab für dieses Maß an Explizitheit. Die Provider-Options-Dokumente beschreiben Routing über Provider hinweg, Reihenfolge, Sortierung, Timeouts und Fallback-Verhalten; die Model-Fallback-Dokumente beschreiben, wie Backup-Modelle in Reihenfolge ausprobiert werden, wenn ein primäres Modell fehlschlägt oder nicht verfügbar ist. Der Punkt für Flatkey-Käufer ist nicht, Vercels API zu kopieren. Der Punkt ist, Routing-Verhalten als dokumentiert, testbar und sichtbar zu erwarten.
Die Failover-Leiter definieren
AI-API-Failover sollte eine Leiter sein, kein Panikknopf. Jede Sprosse sollte zwei Fragen beantworten: Hat dieser Retry eine echte Erfolgschance, und erhält er den Workflow-Vertrag aufrecht?
- Gleicher Upstream-Retry: einmal erneut versuchen bei vorübergehenden Netzwerkfehlern oder klar erneut versuchbaren 5xx-Antworten.
- Gleicher Anbieter, anderes Upstream-Konto: Konten wechseln, wenn das Modell gesund ist, aber ein Konto eingeschränkt, nicht verfügbar oder über dem Kontingent ist.
- Dasselbe Modell, anderer Provider-Pfad: nur verwenden, wenn das Gateway- und Modell-Ökosystem eine gleichwertige Auslieferung über mehrere Anbieter unterstützt.
- Genehmigtes Backup-Modell: verwenden, wenn Ausgabequalität, Tool-Unterstützung, Kontextlimits und Policy-Verhalten für den Workflow akzeptabel sind.
- In die Warteschlange stellen oder degraden: Hintergrundarbeit verzögern, eine kleinere Antwort zurückgeben oder auf einen kostengünstigeren Pfad wechseln, wenn die Erwartungen der Nutzer dies zulassen.
- Fail closed: mit dem Wiederholen aufhören, wenn der Fehler eine ungültige Anfrage, eine Entscheidung zu unsicherem Inhalt, ein Auth-Fehler oder ein nicht unterstützter Parameter ist.
Diese Leiter verhindert, dass AI API load balancing ein echtes Problem verdeckt. Wenn ein Upstream eine fehlerhafte Anfrage ablehnt, erzeugt das Senden derselben Anfrage an fünf weitere Anbieter nur Rauschen, Kosten und verwirrende Logs. Wenn ein Upstream einen vorübergehenden 500er hat, kann ein sorgfältig protokollierter Wechsel die User Experience schützen.
Nutzen Sie Health Checks und Circuit Breakers
Load Balancing ist am nützlichsten, wenn das Gateway bereits vor dem Eintreffen einer Benutzeranfrage weiß, welche Upstreams gesund sind. Health Checks und Circuit Breakers sind die Control Plane für AI API Load Balancing.
Ein praxistaugliches Gesundheitsmodell sollte aktuelle Fehler, Rate-Limit-Antworten, Timeout-Verhalten und anbieterspezifische Fehler erfassen. Ein Circuit Breaker sollte einen fehlerhaften Pfad vorübergehend aus dem Pool entfernen und dann eine kleine Anzahl von Probes zulassen, bevor wieder der volle Traffic zurückkehrt. Ohne diesen Schritt kann das Gateway Benutzer weiterhin in einen fehlerhaften Pfad schicken, nur weil die Route in der Konfiguration noch existiert.
Für AI-Traffic sollten Health Checks workflow-bewusst sein. Eine Route zu einem Textmodell kann gesund sein, während ein Video-Endpunkt eingeschränkt ist. Ein Streaming-Pfad kann ausfallen, während nicht-Streaming-Antworten weiterhin funktionieren. Ein Anbieter kann ein Modell zuverlässig bereitstellen, während ein anderes Modell beeinträchtigt ist. Behandeln Sie den Gesundheitszustand als Signal auf Routenebene, nicht als einzelnes Kontrollkästchen für das gesamte Konto.
Schützen Sie Kontingente, Kosten und Modellsemantik
Zuverlässigkeit und Kosten sind miteinander verbunden. Ein Fallback kann eine Anfrage retten, aber er kann den Traffic auch auf ein teureres Modell umleiten, das Kontingent eines anderen Teams verbrauchen oder das Qualitätsprofil der Ausgabe verändern. Starke Pläne für AI API Load Balancing beinhalten nicht nur technische Retries, sondern auch finanzielle und produktbezogene Einschränkungen.
Bevor Sie automatisches Fallback aktivieren, legen Sie fest:
- Ob ein Fallback-Modell teurer sein darf als das primäre Modell.
- Ob ein kundenorientierter Workflow ohne Prüfung zwischen Modellfamilien wechseln darf.
- Ob Batch-Jobs pausieren sollten, statt über ein Premium-Backup Kosten zu verursachen.
- Welches Team die Kosten trägt, wenn Traffic zwischen Konten oder Anbietern verschoben wird.
- Welche Felder im Nutzungs-Dashboard Finance zur Abstimmung des Vorfalls verwenden kann.
Der öffentliche Preis-API-Snapshot von Flatkey vom 11. Juni 2026 gab success: true mit Live-Daten zu Modellen und Endpoint-Familien zurück, und die öffentliche Website verweist Leser auf Preise, einheitliche Abrechnung und Nutzungs-Transparenz. Betrachten Sie dies als datierte Quellenfakten. Für produktive Zuverlässigkeitsarbeit ist der wichtige operative Schritt, die live Preiseseite, Kontingente und Dashboard-Datensätze für die spezifischen Modelle zu bestätigen, die Ihr Workflow verwenden wird.
Routing-Entscheidungen beobachtbar machen
Wenn Ingenieure den Pfad für Route, Wiederholung und Fallback nach einem Fehler nicht einsehen können, wird das Gateway zu einer Blackbox. Observability ist der Punkt, an dem AI API Load Balancing operativ vertrauenswürdig wird.
Mindestens sollte jede Anfrage genügend Informationen hinterlassen, um diese Fragen zu beantworten:
- Welche Anwendung, welcher Schlüssel, welches Team und welche Umgebung hat die Anfrage gesendet?
- Welches Modell und welchen Endpunkt hat der Client angefordert?
- Welches Upstream-Konto oder welcher Anbieter hat die Anfrage bedient?
- Wurde die Anfrage erneut versucht, umgeschaltet, in eine Warteschlange gestellt, abgelehnt oder direkt zurückgegeben?
- Welcher Statuscode, welche Fehlermeldung, Tokenanzahl, Kosten und Latenz wurden aufgezeichnet?
- Wurde die endgültige Antwort über den Primärpfad oder einen Fallback-Pfad bereitgestellt?
- Kann der Support den nutzerseitigen Vorfall mit einer Request-ID verknüpfen?
Der öffentliche Text von Flatkey verweist auf ein Dashboard für Schlüssel, Nutzung und Routing sowie auf Anfragen, Tokens, Kosten und Fehler über ein Dashboard. Nutzen Sie das als Ausgangspunkt für Ihren Abnahmetest: Senden Sie eine kontrollierte Anfrage, lösen Sie nach Möglichkeit einen bekannten Fehler aus, und überprüfen Sie, ob das Dashboard genügend Kontext für die Vorfallsanalyse anzeigt.
Führen Sie vor der Produktion einen Failover-Drill durch
Warten Sie nicht auf einen Vorfall beim Anbieter, um zu erfahren, wie sich Ihre Routing-Richtlinie verhält. Ein Drill vor der Produktion ist der schnellste Weg, fehlende Logs, unsichere Retries und Überraschungen bei Kontingenten zu entdecken.
- Wählen Sie einen Workflow aus: Wählen Sie einen Staging-Endpunkt, der echten Produktionsverkehr repräsentiert.
- Definieren Sie den erwarteten Pfad: primärer Upstream, Backup-Route, Anzahl der Retries, Timeout und Abbruchbedingungen.
- Erstellen Sie einen Nicht-Produktions-Schlüssel: Isolieren Sie den Test von Produktionskontingenten und Billing-Warnungen.
- Simulieren Sie einen Ausfall: Verwenden Sie einen deaktivierten Upstream, eine eingeschränkte Route, ein niedriges Kontingent oder bei vom Gateway unterstützter Funktion einen ungültigen temporären Anbieter-Authentifizierungsnachweis.
- Beobachten Sie das Ergebnis: Prüfen Sie Statuscode, Antworttext, Routenentscheidung, Latenz, Nutzungsprotokoll und Kostenprotokoll.
- Überprüfen Sie das Rollback: Stellen Sie die primäre Route wieder her und bestätigen Sie, dass der Verkehr ohne veralteten Circuit-Breaker-Status zurückkehrt.
- Schreiben Sie das Runbook: Dokumentieren Sie, wer Routing-Regeln ändert, wer Fallback-Kosten genehmigt und wer Vorfälle kommuniziert.
Dieser Drill ist auch der Weg, wie Plattformteams entscheiden, ob ein One-Key-Gateway produktionsreif ist. Gutes AI API load balancing sollte die betriebliche Komplexität reduzieren und sie nicht in eine unsichtbare Control Plane verschieben.
Wie Flatkey in das Reliability-Playbook passt
Flatkey ist für Teams positioniert, die einen API-Schlüssel, eine OpenAI-kompatible Base-URL, transparente Preise, einheitliche Abrechnung und ein Dashboard für Zugriff, Nutzung und Routing möchten. Der relevante öffentliche Belegpunkt für diesen Artikel ist der Zuverlässigkeitstext: Flatkey sagt, dass es mehrere Upstream-Konten mit automatischem Wechsel und Lastverteilung routen kann, um häufige Fehler zu vermeiden.
Damit eignet sich Flatkey für Teams, die AI API Load Balancing hinter einem einzigen Integrationspunkt evaluieren. Der verantwortungsvolle Evaluierungsweg bleibt konkret: Erstellen Sie einen Testschlüssel im Dashboard, richten Sie einen Staging-Client auf https://router.flatkey.ai/v1 aus, führen Sie einen kontrollierten Routing-Test durch, prüfen Sie die Nutzungs- und Fehlerprotokolle und entscheiden Sie dann, welche Workflows automatisches Switching nutzen können und welche bei Fehlern geschlossen bleiben sollten.
Wenn Sie bereits die SDK-Konfiguration ändern, verwenden Sie den Leitfaden zur OpenAI-kompatiblen API-Migration für die Base-URL-Arbeiten. Wenn Kosten und Modell-Einheiten Teil des Rollouts sind, verwenden Sie vorab den Leitfaden zum Vergleich der Preise für KI-Modelle, bevor Sie Fallback-Pfade freigeben, die die Ausgaben verändern können.
FAQ
Was ist AI API Load Balancing?
AI API Load Balancing ist der Prozess, bei dem Anfragen an KI-Modelle über freigegebene Upstream-Konten, Anbieter oder Modellrouten verteilt werden, damit der Traffic weiterfließen kann, wenn ein Pfad langsam, eingeschränkt, nicht verfügbar oder für einen bestimmten Workflow zu teuer ist.
Worin unterscheidet sich AI API Failover von normaler Retry-Logik?
Retry-Logik wiederholt eine Anfrage normalerweise über denselben Pfad. AI API Failover wechselt den Pfad nach einem definierten Auslöser, etwa einem Upstream-Fehler, Timeout, Rate Limit oder Modellausfall. Gutes Failover braucht trotzdem Stoppbedingungen, damit schlechte Anfragen nicht über jeden Anbieter wiederholt werden.
Sollte jede KI-Anfrage ein automatisches Modell-Fallback haben?
Nein. Modell-Fallback ist nützlich, wenn Backup-Modelle für denselben Workflow freigegeben sind, kann aber Qualität, Tool-Verhalten, Kontextlimits, Kosten und Compliance-Haltung verändern. Evaluation-Traffic und regulierte Workflows benötigen oft strengere Routings als Hintergrundjobs.
Was sollten Ingenieure für Multi-Provider-Routing protokollieren?
Protokollieren Sie die Request-ID, App, Key, Umgebung, angefordertes Modell, ausgewählten Upstream, Retry-Anzahl, Fallback-Grund, Statuscode, Latenz, abrechenbare Nutzung, Kosten und ob die endgültige Antwort vom primären Pfad oder von einem Fallback-Pfad kam.
Wo hilft Flatkey beim AI API Load Balancing?
Flatkey gibt Teams einen Key und einen OpenAI-kompatiblen Router-Endpunkt, und der öffentliche Text verweist auf automatisches Umschalten, Load Balancing sowie ein Dashboard für Keys, Nutzung und Routing. Teams sollten dennoch das genaue Routing-Verhalten, die Logs, Quoten und den Rollback-Pfad in ihrem eigenen Staging-Workflow validieren.
Endgültige Checkliste, bevor Sie es einschalten
Bevor Sie sich in der Produktion auf AI API load balancing verlassen, bestätigen Sie die Fehlermodi, Traffic-Klassen, zulässigen Upstreams, Fallback-Hierarchie, Health Checks, Auswirkungen auf das Kontingent, Observability-Felder und das Rollback-Verfahren. Führen Sie dann den Drill mit einem Nicht-Produktionsschlüssel aus und sichern Sie den Nachweis.
Flatkey kann die Integrationsfläche auf einen Schlüssel und eine kompatible Base URL reduzieren. Um diese Zuverlässigkeitsschicht mit Ihrem eigenen Traffic zu testen, holen Sie sich einen Schlüssel, leiten Sie eine Staging-Workload über das Dashboard und überprüfen Sie die Umschalt-, Nutzungs-, Fehler- und Kostendaten, die Ihr Team vor dem Produktions-Rollout benötigt.