Das Logging von KI-API-Payloads ist eine der schnellsten Methoden, um den Modell-Traffic debuggen zu können, und gleichzeitig eine der schnellsten Methoden, um ein Datenschutzproblem zu schaffen. Derselbe Prompt und dieselbe Antwort, die erklären, warum eine Route fehlgeschlagen ist, können auch Kundennachrichten, Kontodaten, Dokumente, Tool-Ausgaben, internen Code oder regulierte Informationen enthalten.
Die praktische Frage ist nicht, ob ein KI-API-Gateway Logs haben sollte. Sondern was das Gateway standardmäßig aufzeichnen sollte, wann vollständige Payloads erlaubt sind, wie schnell sensible Inhalte verschwinden und welche Nachweise für Auditoren nach dem Schließen des Debug-Fensters verbleiben.
Für Käufer von Flatkey gehört dies in die Vertrauensprüfung, da Flatkey als ein API-Gateway für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und Betriebskontrollen positioniert ist. Ein Gateway mit einem einzigen Schlüssel kann die Beweiserhebung vereinfachen, beseitigt aber nicht die Notwendigkeit einer vom Käufer festgelegten Richtlinie für das Payload-Logging. Behandeln Sie die Richtlinie als Teil des Produktions-Rollouts und nicht als nachträglichen Gedanken, wenn Prompts bereits durch gemeinsame Logs fließen.
Entscheidungsmatrix für das Logging von KI-API-Payloads
Verwenden Sie diese Matrix, bevor Sie die vollständige Speicherung von Prompts und Antworten in einem KI-API-Gateway aktivieren.
| Logging-Modus | Was gespeichert wird | Beste Anwendung | Datenschutzrisiko | Standardempfehlung |
|---|---|---|---|---|
| Nur Metadaten | Anfrage-ID, Schlüssel, Besitzer, Route, Modell, Status, Tokens, Latenz, Kosten, Fehlerklasse, Retry/Fallback-Flags | Betrieb, Überprüfung der Abrechnung, SLO-Überprüfung, Incident Triage | Geringer, wenn Benutzerkennungen minimiert werden | Als Standard für den Großteil des Produktions-Traffics verwenden |
| Geschwärzter Payload | Prompt und Antwort nach deterministischer Maskierung oder Feldentfernung | Debugging wiederholter Fehler ohne Speicherung von rohen Geheimnissen | Mittel, da die Schwärzung kontextspezifische Daten übersehen kann | Für genehmigte Routen nach dem Testen der Schwärzungsqualität zulassen |
| Gestichprobter Payload | Ein kleiner Prozentsatz von Prompts/Antworten, normalerweise mit Schwärzung | Qualitätsprüfung, Regressionsanalyse, Support-Untersuchung | Mittel bis hoch, abhängig von der Datenklasse | Nur mit Genehmigung des Besitzers und Sampling-Regeln verwenden |
| Vollständiger Payload mit kurzer Aufbewahrungsfrist | Roher Prompt und Antwort für ein enges Debug-Fenster | Reproduktion eines schwerwiegenden Vorfalls, Eskalation an den Anbieter, Migrationstests | Hoch | Auf Stunden oder Tage begrenzen, Zugriffsprotokollierung erfordern und planmäßig löschen |
| Kein Payload-Log | Kein Prompt- oder Antwort-Body, manchmal keine Metadaten über die minimalen Abrechnungs-/Sicherheitsfelder hinaus | Sensible Workloads, regulierte Eingaben, Opt-out-Lanes für Kunden | Am niedrigsten | Für Routen mit hohem Risiko oder vertraglich vereinbarter Nicht-Speicherung verwenden |
Dies ist der zentrale Kompromiss: Das Logging von KI-API-Payloads kann das Debugging verbessern, aber die nützlichen Daten sind oft auch die sensiblen Daten. Eine Governance-fähige Gateway-Richtlinie beginnt mit Metadaten, eskaliert nur aus bestimmten Gründen zu Payloads und macht die Aufbewahrung für Sicherheits-, Datenschutz- und Produktverantwortliche sichtbar.
Warum Payload-Logs nützlich sind
Vollständige Payload-Logs können Fragen beantworten, die Metadaten nicht beantworten können:
- Wurde das Modell mit dem Prompt aufgerufen, den die Anwendung senden wollte?
- Hat eine Systemnachricht, ein Tool-Schema oder ein Retrieval-Ergebnis das Modellverhalten geändert?
- Enthielt eine Kundeneingabe versteckte Anweisungen, Geheimnisse, persönliche Daten oder fehlerhaftes JSON?
- Hat eine Fallback-Route einen Prompt erhalten, den nur das primäre Modell sehen durfte?
- Hat ein Upstream-Anbieter eine fehlerhafte Antwort, eine Ablehnung oder einen partiellen Stream zurückgegeben?
- Hat die Anfrage den richtigen Modell-Alias, die richtige Endpunkt-Familie und den richtigen Besitzerschlüssel verwendet?
Ohne Payload-Beweise debuggen Teams KI-Vorfälle oft anhand von Symptomen: Statuscode, Latenz, Kosten und eine Kundenbeschwerde. Das reicht manchmal für Ratenbegrenzungen, Warteschlangen und die Überprüfung der Abrechnung aus. Für Prompt-Injection, Retrieval-Drift, Brüche im Tool-Call-Schema, unerwartete Inhalte oder eine Eskalation an den Anbieter ist es normalerweise nicht ausreichend.
Die Antwort ist nicht, jeden Prompt für immer aufzubewahren. Die Antwort ist zu entscheiden, welche Payload-Beweise notwendig sind, wie sie minimiert werden und wer sie öffnen kann.
Warum Payload-Logs riskant sind
Das OWASP Logging Cheat Sheet ist unmissverständlich, was sensible Daten in Logs angeht: Geheimnisse, Zugriffstokens, sensible persönliche Daten, Zahlungsdaten, Verbindungszeichenfolgen, Verschlüsselungsschlüssel und Daten höherer Klassifizierung sollten normalerweise vor dem Logging entfernt, maskiert, bereinigt, gehasht oder verschlüsselt werden. KI-Payloads können all diese Kategorien enthalten, da Benutzer echte Arbeitsinhalte in Prompts einfügen.
Das Logging von KI-API-Payloads birgt auch Risiken, die gewöhnliche API-Logs nicht immer mit sich bringen:
- Lange Kontextfenster können viele Dokumente, Chat-Verläufe, Dateien und Tool-Ausgaben in einer einzigen Anfrage enthalten.
- Modellantworten können sensible Eingaben wiederholen, Zusammenfassungen vertraulicher Dokumente erstellen oder von Tools zurückgegebene Daten enthalten.
- Wiederholungsversuche und Fallbacks können denselben Payload über mehrere Anbieter oder Gateway-Lanes hinweg duplizieren.
- Observability-Tools können Payloads in Traces, Dashboards, Benachrichtigungen, Exporte und Support-Tickets kopieren.
- Debug-Screenshots und Notizen zu Vorfällen können Payload-Ausschnitte auch nach Ablauf des ursprünglichen Logs erhalten.
Wenn ein Team nicht erklären kann, wohin Payloads kopiert werden, ist die Aufbewahrungseinstellung im Gateway nur ein Teil des tatsächlichen Daten-Fußabdrucks.
Die Aufbewahrung durch den Anbieter ist nicht Ihre Gateway-Richtlinie
Die Datenkontrollen der Anbieter sind wichtig, aber sie sind kein Ersatz für Ihre eigenen Regeln zum Logging von KI-API-Payloads.
Die Datenkontrollen der OpenAI-Plattform besagen, dass API-Daten standardmäßig nicht zum Trainieren von OpenAI-Modellen verwendet werden und dass Protokolle zur Missbrauchsüberwachung Prompts und Antworten enthalten können und bis zu 30 Tage aufbewahrt werden, es sei denn, ein Kunde hat Kontrollen wie Modified Abuse Monitoring oder Zero Data Retention genehmigt. Dieselbe OpenAI-Dokumentation unterscheidet auch zwischen Protokollen zur Missbrauchsüberwachung und dem Anwendungsstatus, und einige Funktionen behalten den Status bis zur Löschung oder für einen funktionsspezifischen Zeitraum bei.
Die Dokumentation von Anthropic zu API und Datenaufbewahrung beschreibt Zero Data Retention so, dass Kundendaten nach der Rückgabe der API-Antwort nicht im Ruhezustand gespeichert werden, außer wenn dies zur Einhaltung von Gesetzen oder zur Bekämpfung von Missbrauch erforderlich ist. Sie weist auch darauf hin, dass verschiedene APIs und Funktionen unterschiedliche Speicheranforderungen haben, dass einige Funktionen nicht für ZDR qualifiziert sind und dass eine Aufbewahrung aufgrund von Richtlinienverstößen oder gesetzlichen Vorschriften weiterhin gelten kann.
Die Dokumentation der Gemini Developer API von Google besagt, dass Prompts und Antworten von kostenpflichtigen Diensten nicht zur Verbesserung der Produkte von Google verwendet werden, beschreibt aber gleichzeitig eine begrenzte Protokollierung von Prompts und Antworten zur Missbrauchsüberwachung und funktionsspezifische Speicherung wie Grounding, Interaktionen, Dateien und explizites Kontext-Caching. Sie besagt, dass ZDR bestimmte Aktionen oder die Vermeidung bestimmter Funktionen erfordert.
Die Lektion für Käufer ist einfach: Dokumentieren Sie die Einstellungen und Verträge der Anbieter, aber führen Sie eine separate Protokolldatei für das KI-API-Gateway, die angibt, was Ihr eigenes System vor, während und nach dem Anbieteraufruf speichert.
Legen Sie zuerst die Nachweisfelder fest
Der sicherste Weg, die Protokollierung von KI-API-Payloads zu gestalten, besteht darin, mit einer Nachweistabelle zu beginnen, nicht mit einem Schalter namens „Prompts protokollieren“.
| Nachweisfeld | Standardmäßig speichern? | Warum es wichtig ist | Payload erforderlich? |
|---|---|---|---|
| Anfrage-ID und Trace-ID | Ja | Ermöglicht Support, Sicherheit und Technik, sich auf dasselbe Ereignis zu beziehen | Nein |
| API-Schlüssel oder Eigentümer-ID | Ja, vorzugsweise eine stabile interne ID | Ermöglicht Rückbuchungen, Zugriffsüberprüfungen und Missbrauchsuntersuchungen | Nein |
| Benutzerkennung | Manchmal, gehasht oder pseudonymisiert | Hilft bei Missbrauchs- und Kundensupport-Untersuchungen | Nein |
| Route, Anbieter, Modell, Endpunktfamilie | Ja | Zeigt, wohin die Anfrage tatsächlich ging | Nein |
| Anzahl der Prompt-Tokens, Anzahl der Ausgabe-Tokens, Kosten | Ja | Unterstützt die Rechnungsprüfung und Anomalieerkennung | Nein |
| Status, Fehlerklasse, Wiederholungs-/Fallback-Pfad | Ja | Erklärt die Zuverlässigkeit und das Routing-Verhalten | Nein |
| Ergebnis des Abgleichs mit Sicherheits-, DLP- oder Richtlinienvorgaben | Ja, falls verwendet | Zeigt, warum eine Anfrage blockiert oder zugelassen wurde | Normalerweise nicht |
| Prompt-Text | Standardmäßig nein | Erforderlich für die Prompt-Qualität und bestimmte Vorfälle | Ja |
| Antworttext | Standardmäßig nein | Erforderlich für Ausgabefehler und Eskalation an den Anbieter | Ja |
| Tool-Eingaben und -Ausgaben | Standardmäßig nein | Enthält oft Geschäftsdaten aus verbundenen Systemen | Ja |
| Abgerufene Chunks oder Dateien | Standardmäßig nein | Enthält oft Quelldokumente, Verträge oder Kundendaten | Ja |
Für die meisten Produktionsteams sind reine Metadaten-Protokolle plus eine genehmigte Debug-Spur mit kurzer Aufbewahrungsfrist ausreichend. Die vollständige Protokollierung von KI-API-Payloads sollte eine bewusste Ausnahme sein, nicht der Standardzustand bei jedem Modellaufruf.
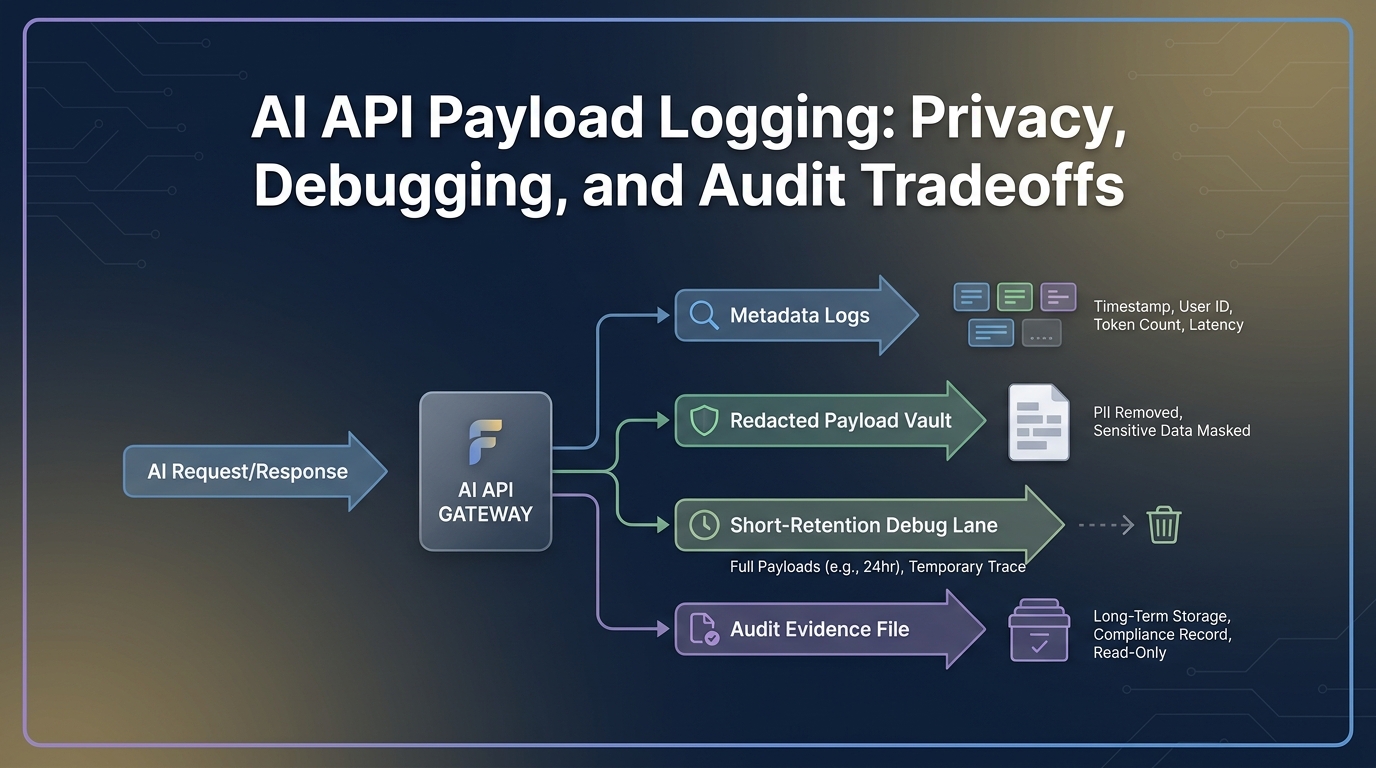
Bauen Sie drei Spuren anstelle eines einzigen Protokoll-Buckets
Ein einziger Protokoll-Bucket schafft die falschen Anreize. Ingenieure wollen Details. Datenschutzprüfer wollen Minimierung. Auditoren wollen Beweise, die Bestand haben. Trennen Sie die Spuren.
| Spur | Aufbewahrung | Zugriff | Inhalte | Eigentümer |
|---|---|---|---|---|
| Betriebsmetadaten | 30 bis 180 Tage, je nach Abrechnungs- und Vorfallanforderungen | Technik, Betrieb, Finanzen, Sicherheit | Anfragemetadaten, Nutzung, Kosten, Route, Status, Fehlerklasse | Plattformeigentümer |
| Debug-Payload-Tresor | Stunden bis wenige Tage | Break-Glass- oder benannte Incident-Responder | Geschwärzte Payloads oder vollständige Payloads nur ausnahmsweise | Sicherheit und Plattformeigentümer |
| Audit-Nachweisdatei | Verlängerungs- oder Auditzyklus | Beschaffung, Sicherheit, Finanzen, Recht | Richtlinien, Aufbewahrungseinstellungen, Screenshots, Testergebnisse, Nachweise von Zugriffsüberprüfungen | Trust- oder Beschaffungseigentümer |
Dieses Design hält die langlebigen Nachweise nützlich, ohne die langlebige Speicherung von Payloads zum einfachen Weg zu machen. Die Audit-Datei sollte beweisen, dass die Richtlinie angewendet wurde; sie muss keine rohen Prompts und Antworten enthalten.
Vor dem Speichern schwärzen
Eine Schwärzung nach der Anzeige ist nicht ausreichend. Wenn die Payload bereits in einer Datenbank gespeichert, an einen Tracing-Anbieter weitergeleitet, in ein Ticket exportiert oder in eine Webhook-Benachrichtigung aufgenommen wurde, existiert die sensible Kopie bereits.
Die Maskierungsdokumentation von Langfuse ist ein nützliches Muster: Sie beschreibt Maskierungsfunktionen, die sensible Informationen schwärzen, bevor Trace-Daten die Anwendung verlassen, einschließlich Eingaben, Ausgaben, Metadaten und OpenTelemetry-Span-Attributen. Die Funktion „Omit Logs“ von Helicone zeigt dasselbe Designprinzip aus einem anderen Blickwinkel: Kosten-, Latenz- und Nutzungsmuster beibehalten, während Anfrage- und Antwortinhalte von der Speicherung ausgeschlossen werden. Die Steuerelemente für die Anforderungsprotokollierung von Portkey trennen die vollständige Protokollierung von der reinen Metrikprotokollierung auf Organisationsebene.
Machen Sie die Schwärzung für eine interne Gateway-Richtlinie testbar:
- Erstellen Sie Testdaten (Fixtures) mit E-Mails, Telefonnummern, Zugriffstoken, API-Schlüsseln, Konto-IDs, zahlungsähnlichen Werten, Gesundheitsbegriffen und proprietärem Code.
- Führen Sie dieselben Testdaten durch Prompteingaben, abgerufenen Kontext, Tool-Ausgaben, Modellantworten, Fehlerausgaben und Streaming-Chunks.
- Überprüfen Sie das gespeicherte Protokoll, die Dashboard-Ansicht, die Alert-Payload, den Trace-Exporter und den Support-Export.
- Erfassen Sie Fehlschläge als Sicherheitsfehler, nicht als Probleme mit der Inhaltsqualität.
- Führen Sie die Tests erneut aus, wann immer ein neues SDK, ein Gateway, ein Tracing-Exporter oder ein Modellendpunkt hinzugefügt wird.
Das Logging von KI-API-Payloads sollte niemals auf einem einzelnen Regex beruhen, der in eine Dashboard-Einstellung eingefügt und ungetestet gelassen wird.
Verwenden Sie Überschreibungen pro Anfrage mit Bedacht
Steuerungen pro Anfrage sind nützlich, wenn ein Produkt gemischte Datenklassen hat. Die Dokumentation zum Logging des AI Gateway von Cloudflare beschreibt Header, die das Logging auf Gateway-Ebene überschreiben und separat steuern können, ob rohe Anfrage- und Antwortkörper gespeichert werden, während Metadaten weiterhin protokolliert werden.
Das ist die richtige Form für KI-Traffic mit hoher Varianz, aber es braucht Leitplanken:
- Machen Sie die sichere Einstellung zum Standard für neue Routen.
- Fordern Sie eine Code-Überprüfung für jede Route, die die Speicherung von Payloads aktiviert.
- Verknüpfen Sie Überschreibungen mit der Workload-Klasse, dem Kundenvertrag, der Umgebung und der Incident-ID.
- Verhindern Sie, dass clientgesteuerte Header unbemerkt das Payload-Logging aktivieren.
- Protokollieren Sie die Richtlinienentscheidung selbst: warum die Payload beibehalten oder weggelassen wurde.
- Führen Sie ein „Fail-Closed“ durch, wenn die Richtlinie nicht ausgewertet werden kann.
Das Logging von KI-API-Payloads pro Anfrage sollte eine Richtlinienentscheidung sein, die von vertrauenswürdigem Anwendungs- oder Gateway-Code getroffen wird, und kein beliebiger Wert, der von einem Endbenutzer übergeben wird.
Was Sie einen Gateway-Anbieter fragen sollten
Beschaffungsteams sollten nach Nachweisen fragen, nicht nur nach Funktionsnamen. Verwenden Sie diese Checkliste bei der Bewertung eines KI-API-Gateways oder einer Observability-Schicht.
| Frage | Anzufordernder Nachweis | Auslöser für Erneuerung |
|---|---|---|
| Können wir reine Metadaten-Logs ohne Prompt- oder Antwortkörper ausführen? | Screenshot oder API-Antwort, die zeigt, dass die Payload-Speicherung deaktiviert ist, während die Nutzungsmetadaten erhalten bleiben | Jede Änderung an Logging- oder Observability-Funktionen |
| Können wir das Payload-Logging für eine einzelne Route, einen Schlüssel, einen Workspace oder einen Incident aktivieren? | Screenshot der Richtlinie, API-Einstellung oder Testanfrage mit Verhalten auf Routenebene | Neue Route, neuer Kundentarif oder neues Workspace-Modell |
| Können Payloads vor der Speicherung geschwärzt werden? | Ausgabe des Schwärzungstests für Prompt, Antwort, Tool-Ausgabe und Trace-Export | Neuer Modellendpunkt, neues SDK, neuer Exporter oder neue Tool-Integration |
| Können vollständige Payloads automatisch ablaufen? | Aufbewahrungseinstellung, Nachweis des Löschauftrags, Rücklesen nach Ablauf | Änderung der Aufbewahrungsrichtlinie oder Audit-Zyklus |
| Werden Zugriffsereignisse auf die Payload-Logs selbst protokolliert? | Beispiel für ein Zugriffsprotokoll, Rollenmatrix, Genehmigungsworkflow | Rollenänderung oder Sicherheitsvorfall |
| Werden Protokolle an Drittanbieter-Tools exportiert? | Datenflussdiagramm und Zielliste | Neue SIEM-, APM-, Support- oder Warehouse-Integration |
| Können wir historische Payload-Logs löschen oder bereinigen? | Nachweis der Lösch-API oder des Support-Prozesses | Löschanfrage des Kunden oder Vertragskündigung |
| Unterscheidet das Gateway zwischen der Aufbewahrung durch den Anbieter und der Aufbewahrung durch das Gateway? | Vertrauensdokumentation, die beide Schichten trennt | Anbietervertrag oder Änderung der Gateway-Architektur |
Die Nachweisdatei sollte datiert sein. Ein Screenshot vom 4. Juli 2026 ist aussagekräftiger als eine allgemeine Behauptung auf einer Vertrauensseite, da er einem zukünftigen Prüfer genau sagt, was und wann geprüft wurde.
Wie dies zu Flatkey passt
Die öffentliche Website von Flatkey positioniert das Produkt derzeit als KI-API-Gateway und Model-Operations-Plattform, die den Modellzugriff, das Routing, die Abrechnung, die Nutzungsanalyse und die operativen Kontrollen für Teams, die KI-Produkte ausliefern, vereinheitlicht. Die Überprüfung der Preisgestaltungs-API am 4. Juli 2026 lieferte eine Live-Katalogantwort mit unterstützten Endpunktfamilien, einschließlich /v1/chat/completions, /v1/messages, Gemini generateContent, Bildgenerierungs- und Videoendpunkten.
Das macht Flatkey zu einem natürlichen Ort, um Nachweise zu Routen, Modellen, Nutzung, Kosten und Eigentümern zu zentralisieren. Speziell für das Logging von KI-API-Payloads sollten Käufer dennoch die aktuelle Flatkey-Konsole, die aktuellen Kontoeinstellungen, Verträge und jegliche vom Support bereitgestellte Dokumentation überprüfen, bevor sie ein Speicherverhalten für Prompts/Antworten annehmen. Wenn die Aufbewahrung von Payloads eine Beschaffungsanforderung ist, fragen Sie nach einer datierten Nachweisdatei, die Folgendes trennt:
- Was Flatkey als Gateway-Metadaten speichert.
- Ob rohe Prompt- und Antwortkörper gespeichert werden.
- Ob die Payload-Speicherung deaktiviert oder auf einen bestimmten Bereich beschränkt werden kann.
- Welche Aufbewahrungs- und Löschkontrollen gelten.
- Welche Aufbewahrungseinstellungen des Anbieters sich ebenfalls auf dieselbe Anfrage auswirken.
- Welche Protokolle dem Käufer, dem Flatkey-Support und den Upstream-Anbietern zur Verfügung stehen.
Diese Unterscheidung schützt beide Seiten. Flatkey kann die Betriebsschicht sein, während der Käufer die Datengrenze explizit festlegt.
Ein minimales Metadaten-Ereignis
Für viele Teams sieht der sicherste Produktionsstandard wie folgt aus:
{
"request_id": "req_01jz3...",
"timestamp": "2026-07-04T02:00:00Z",
"environment": "production",
"owner_key_id": "key_support_summarizer",
"customer_tier": "enterprise",
"route": "support-summary",
"endpoint_family": "chat-completions",
"provider": "selected_by_gateway",
"model_alias": "approved-summary-model",
"prompt_tokens": 1840,
"completion_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"redaction_policy": "not_applicable",
"fallback_used": false,
"retention_class": "ops_metadata_90d"
}Dieses Ereignis kann die Überprüfung von Abrechnungen, die Korrelation von Vorfällen, die Routenanalyse und den Audit-Nachweis unterstützen, ohne den Prompt- oder Antwort-Body aufzubewahren.
Debugging-Workflow ohne permanente Speicherung von Payloads
Wenn ein Vorfall einen Payload-Nachweis erfordert, verwenden Sie einen kurzen Workflow:
- Eröffnen Sie einen Vorfall mit Eigentümer, Route, Kundenauswirkung und zulässiger Datenklasse.
- Aktivieren Sie das redigierte oder vollständige Payload-Logging nur für die betroffene Route, den betroffenen Schlüssel oder ein Trace-Beispiel.
- Legen Sie ein Ablaufdatum fest, bevor Sie den ersten Payload erfassen.
- Protokollieren Sie, wer die Änderung genehmigt hat und wer den Payload-Tresor lesen kann.
- Sammeln Sie die kleinste Stichprobe, die das Problem reproduziert.
- Speichern Sie eine bereinigte Vorfallsnotiz mit Anfrage-IDs, Fehlerklasse, Ursache und Behebung.
- Löschen Sie den Payload-Tresor oder lassen Sie ihn ablaufen.
- Bewahren Sie den Audit-Nachweis auf, nicht den rohen Prompt.
Dadurch bleibt das Logging von KI-API-Payloads für das Engineering nützlich, während die langfristigen Datenschutzkosten begrenzt werden.
Wo dies in die Vertrauensprüfung passt
Das Logging von KI-API-Payloads ist eine Nachweisebene in einer umfassenderen Gateway-Überprüfung. Verwenden Sie die Checkliste für Enterprise-KI-API-Gateways, um Zugriff, Routing, Abrechnung, Kontingente und den Besitz von Nachweisen zu bestätigen. Verwenden Sie den Leitfaden für Audit-Logs zur Nutzung von KI-APIs, wenn der Käufer dauerhafte Audit-Ereignisse benötigt, ohne rohe Prompts zu speichern. Verwenden Sie die Risikobewertung für KI-API-Anbieter, um die Aufbewahrungsfristen, Verträge und die Verarbeitung durch Dritte der Anbieter vor einer Verlängerung zu vergleichen.
Das saubere Betriebsmodell besteht darin, diese Dateien miteinander zu verbinden: die Gateway-Checkliste für die Startbereitschaft, Audit-Logs für dauerhafte Nachweise, die Risikobewertung von Anbietern für die Beschaffung und das Logging von KI-API-Payloads für die eng gefasste Frage, wann Prompts und Antworten gespeichert werden dürfen.
FAQ
Sollte ein KI-API-Gateway standardmäßig Prompts und Antworten protokollieren?
Normalerweise nicht. Nur-Metadaten-Logs sind eine bessere Standardeinstellung für die Produktion, da sie Nutzungs-, Kosten-, Routing-, Latenz- und Fehlernachweise erhalten, ohne sensible Prompt- und Antwort-Bodies zu speichern. Das vollständige Logging von KI-API-Payloads sollte auf genehmigte Debug- oder Überprüfungs-Workflows beschränkt sein.
Reicht das Logging redigierter Payloads für die Compliance aus?
Nicht allein. Die Qualität der Redaktion, Aufbewahrungsfristen, Zugriffskontrollen, Exportziele, Verträge und Datenkontrollen des Anbieters sind alle von Bedeutung. Betrachten Sie die Redaktion als eine Kontrolle in einer größeren Nachweisdatei.
Wie lange sollten Logs von KI-API-Payloads aufbewahrt werden?
Bewahren Sie rohe Payloads für das kürzestmögliche Debug-Fenster auf, oft Stunden oder Tage statt Monate. Bewahren Sie Metadaten und Audit-Nachweise länger auf, wenn Abrechnungs-, Sicherheits- oder Beschaffungsanforderungen dies erfordern.
Was ist der Unterschied zwischen der Aufbewahrung durch den Anbieter und der Aufbewahrung durch das Gateway?
Die Aufbewahrung durch den Anbieter beschreibt, was der vorgelagerte Modellanbieter nach Erhalt einer Anfrage speichert. Die Aufbewahrung durch das Gateway beschreibt, was Ihr eigenes Gateway, Ihre Observability-Schicht, Traces, Alarme und Exporte speichern. Sie benötigen für beides Nachweise.
Was sollte die Beschaffung Flatkey vor der Genehmigung fragen?
Fragen Sie nach aktuellen, kontospezifischen Nachweisen für Gateway-Metadaten, das Speicherverhalten von Payloads, Aufbewahrung, Löschung, Zugriffskontrollen, Anbieter-Routing und alle Log-Exporte an Dritte. Vergleichen Sie diese Nachweise dann mit Ihrer eigenen Datenklassifizierung und Ihrer Richtlinie zur Reaktion auf Vorfälle.
Fazit
Das Logging von KI-API-Payloads sollte das Debuggen von KI-Produktionssystemen erleichtern, ohne jeden Prompt in einen permanenten Datensatz zu verwandeln. Beginnen Sie mit Nur-Metadaten-Logs, fügen Sie die Erfassung redigierter oder kurzzeitig aufbewahrter Payloads nur hinzu, wenn der Workflow dies erfordert, testen Sie die Redaktion vor der Speicherung und führen Sie eine datierte Audit-Datei für die Überprüfung durch die Beschaffung. Wenn Sie bereit sind, den Modellzugriff und die Nutzungsnachweise über ein einziges Gateway zu zentralisieren, sehen Sie sich die aktuellen Flatkey-Preise und den Modellkatalog an und holen Sie sich dann einen Schlüssel.