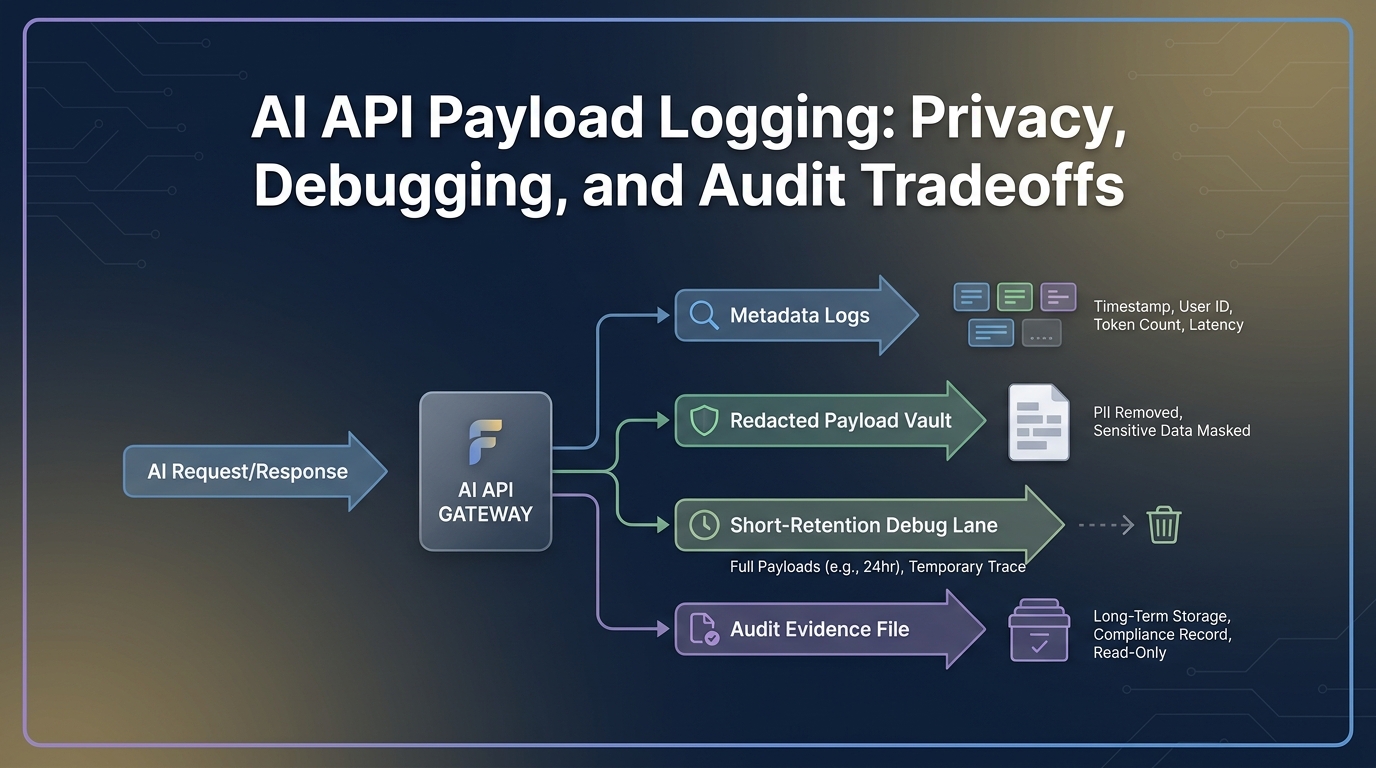
Логирование полезной нагрузки AI API — это один из самых быстрых способов сделать трафик модели отлаживаемым и один из самых быстрых способов создать проблему с конфиденциальностью. Тот же самый промпт и ответ, которые объясняют, почему маршрут не сработал, могут также содержать сообщения клиентов, данные учетных записей, документы, выводы инструментов, внутренний код или регулируемую информацию.
Практический вопрос не в том, должен ли шлюз AI API иметь логи. Вопрос в том, что шлюз должен записывать по умолчанию, когда разрешены полные полезные нагрузки, как быстро исчезает конфиденциальный контент и какие доказательства остаются для аудиторов после закрытия окна отладки.
Для покупателей Flatkey этот вопрос относится к проверке доверия, поскольку Flatkey позиционируется как единый шлюз API для доступа к моделям, маршрутизации, биллинга, аналитики использования и операционного контроля. Шлюз с одним ключом может упростить сбор доказательств, но не устраняет необходимость в собственной политике логирования полезной нагрузки покупателя. Рассматривайте эту политику как часть развертывания в производственной среде, а не как запоздалое решение, когда промпты уже проходят через общие логи.
Матрица принятия решений по логированию полезной нагрузки AI API
Используйте эту матрицу перед включением полного хранения промптов и ответов в любом шлюзе AI API.
| Режим логирования | Что сохраняется | Лучшее применение | Риск для конфиденциальности | Рекомендация по умолчанию |
|---|---|---|---|---|
| Только метаданные | ID запроса, ключ, владелец, маршрут, модель, статус, токены, задержка, стоимость, класс ошибки, флаги повтора/отката | Операционная деятельность, проверка биллинга, проверка SLO, сортировка инцидентов | Низкий, если идентификаторы пользователей минимизированы | Использовать по умолчанию для большей части производственного трафика |
| Отредактированная полезная нагрузка | Промпт и ответ после детерминированного маскирования или удаления полей | Отладка повторяющихся сбоев без хранения необработанных секретов | Средний, так как редактирование может пропустить контекстно-зависимые данные | Разрешить для утвержденных маршрутов после проверки качества редактирования |
| Выборочная полезная нагрузка | Небольшой процент промптов/ответов, обычно с редактированием | Проверка качества, регрессионный анализ, расследование в рамках поддержки | От среднего до высокого, в зависимости от класса данных | Использовать только с одобрения владельца и по правилам выборки |
| Полная полезная нагрузка с коротким сроком хранения | Необработанные промпт и ответ для узкого окна отладки | Воспроизведение серьезного инцидента, эскалация поставщику, тестирование миграции | Высокий | Ограничить часами или днями, требовать логирования доступа и удалять по расписанию |
| Без лога полезной нагрузки | Без тела промпта или ответа, иногда без метаданных, кроме минимальных полей для биллинга/безопасности | Конфиденциальные рабочие нагрузки, регулируемые входные данные, каналы для отказа клиентов | Самый низкий | Использовать для маршрутов с высоким риском или с договорным запретом на хранение |
В этом и заключается основной компромисс: логирование полезной нагрузки AI API может улучшить отладку, но полезные данные часто являются конфиденциальными. Готовая к управлению политика шлюза начинается с метаданных, переходит к полезным нагрузкам только по определенным причинам и делает срок хранения видимым для владельцев безопасности, конфиденциальности и продукта.
Почему логи полезной нагрузки полезны
Полные логи полезной нагрузки могут ответить на вопросы, на которые не могут ответить метаданные:
- Была ли модель вызвана с тем промптом, который приложение намеревалось отправить?
- Изменили ли системное сообщение, схема инструмента или результат извлечения поведение модели?
- Содержал ли ввод клиента скрытые инструкции, секреты, личные данные или некорректный JSON?
- Получил ли резервный маршрут промпт, который был разрешен для просмотра только основной модели?
- Вернул ли вышестоящий провайдер некорректный ответ, отказ или частичный поток?
- Использовал ли запрос правильный псевдоним модели, семейство конечных точек и ключ владельца?
Без доказательств из полезной нагрузки команды часто отлаживают инциденты с ИИ по симптомам: код состояния, задержка, стоимость и жалоба клиента. Иногда этого достаточно для анализа ограничений скорости, очередей и биллинга. Обычно этого недостаточно для расследования внедрения промптов, дрейфа извлечения, нарушений схемы вызова инструментов, неожиданного контента или эскалации поставщику.
Ответ не в том, чтобы хранить каждый промпт вечно. Ответ в том, чтобы решить, какие доказательства из полезной нагрузки необходимы, как они минимизируются и кто может их открывать.
Почему логи полезной нагрузки рискованны
Шпаргалка по логированию от OWASP прямолинейна в отношении конфиденциальных данных в логах: секреты, токены доступа, конфиденциальные личные данные, платежные данные, строки подключения, ключи шифрования и данные более высокой классификации обычно должны быть удалены, замаскированы, очищены, хешированы или зашифрованы перед логированием. Полезные нагрузки ИИ могут содержать все эти категории, потому что пользователи вставляют реальную работу в промпты.
Логирование полезной нагрузки AI API также создает риски, которых не всегда создают обычные логи API:
- Длинные контекстные окна могут включать множество документов, реплик чата, файлов и выводов инструментов в одном запросе.
- Ответы модели могут повторять конфиденциальные входные данные, генерировать резюме конфиденциальных документов или включать данные, возвращенные инструментами.
- Повторные попытки и откаты могут дублировать одну и ту же полезную нагрузку у нескольких провайдеров или по разным каналам шлюза.
- Инструменты наблюдаемости могут копировать полезные нагрузки в трассировки, дашборды, оповещения, экспорты и тикеты поддержки.
- Скриншоты отладки и заметки об инцидентах могут сохранять фрагменты полезной нагрузки после истечения срока действия исходного лога.
Если команда не может объяснить, куда копируются полезные нагрузки, настройка срока хранения в шлюзе — это лишь часть реального следа данных.
Хранение данных у провайдера — это не ваша политика шлюза
Средства контроля данных у провайдера важны, но они не заменяют ваши собственные правила логирования полезной нагрузки AI API.
В элементах управления данными платформы OpenAI говорится, что данные API по умолчанию не используются для обучения моделей OpenAI, а журналы мониторинга злоупотреблений могут содержать промпты и ответы и хранятся до 30 дней, если только клиент не утвердил такие элементы управления, как Modified Abuse Monitoring или Zero Data Retention. В той же документации OpenAI также проводится различие между журналами мониторинга злоупотреблений и состоянием приложения, а некоторые функции сохраняют состояние до удаления или в течение определенного для функции периода.
В документации Anthropic по API и хранению данных описывается Zero Data Retention как состояние, при котором данные клиента не хранятся в состоянии покоя после возврата ответа API, за исключением случаев, когда это необходимо для соблюдения законодательства или борьбы с неправомерным использованием. Также отмечается, что разные API и функции имеют разные потребности в хранении, что некоторые функции не подпадают под действие ZDR, и что хранение данных в случае нарушения политики или по юридическим причинам все еще может применяться.
В документации Google по Gemini Developer API говорится, что промпты и ответы платных сервисов не используются для улучшения продуктов Google, при этом также описывается ограниченное логирование промптов и ответов для мониторинга злоупотреблений и хранения данных для конкретных функций, таких как заземление, взаимодействия, файлы и явное кэширование контекста. В ней говорится, что ZDR требует выполнения определенных действий или отказа от использования некоторых функций.
Урок для покупателя прост: документируйте настройки и контракты с поставщиком, но ведите отдельный файл журнала шлюза AI API, в котором указано, что ваша собственная система хранит до, во время и после вызова поставщика.
Сначала определите поля для доказательств
Самый безопасный способ спроектировать логирование полезной нагрузки AI API — это начать с таблицы доказательств, а не с переключателя «логировать промпты».
| Поле доказательства | Хранить по умолчанию? | Почему это важно | Нужна ли полезная нагрузка? |
|---|---|---|---|
| ID запроса и ID трассировки | Да | Позволяет поддержке, безопасности и инженерам ссылаться на одно и то же событие | Нет |
| Ключ API или ID владельца | Да, предпочтительно стабильный внутренний ID | Обеспечивает возвратные платежи, проверку доступа и расследование злоупотреблений | Нет |
| Идентификатор пользователя | Иногда, хешированный или псевдонимный | Помогает в расследованиях злоупотреблений и поддержке клиентов | Нет |
| Маршрут, поставщик, модель, семейство конечных точек | Да | Показывает, куда на самом деле ушел запрос | Нет |
| Количество токенов в промпте, количество токенов в выводе, стоимость | Да | Поддерживает проверку счетов и обнаружение аномалий | Нет |
| Статус, класс ошибки, путь повторной попытки/отката | Да | Объясняет надежность и поведение маршрутизации | Нет |
| Результат проверки безопасности, DLP или соответствия политике | Да, если используется | Показывает, почему запрос был заблокирован или разрешен | Обычно нет |
| Текст промпта | Нет по умолчанию | Необходимо для оценки качества промпта и расследования определенных инцидентов | Да |
| Текст ответа | Нет по умолчанию | Необходимо для выявления дефектов вывода и эскалации поставщику | Да |
| Вводы и выводы инструментов | Нет по умолчанию | Часто содержит бизнес-данные из подключенных систем | Да |
| Извлеченные фрагменты или файлы | Нет по умолчанию | Часто содержит исходные документы, контракты или данные клиентов | Да |
Для большинства производственных команд достаточно журналов, содержащих только метаданные, и утвержденного канала отладки с коротким сроком хранения. Полное логирование полезной нагрузки AI API должно быть осознанным исключением, а не состоянием по умолчанию для каждого вызова модели.
Создайте три канала вместо одного хранилища логов
Единое хранилище логов создает неправильные стимулы. Инженеры хотят деталей. Специалисты по конфиденциальности хотят минимизации. Аудиторы хотят доказательств, которые сохранятся. Разделите каналы.
| Канал | Хранение | Доступ | Содержимое | Владелец |
|---|---|---|---|---|
| Операционные метаданные | От 30 до 180 дней, в зависимости от потребностей биллинга и инцидентов | Инженеры, операционный отдел, финансы, безопасность | Метаданные запроса, использование, стоимость, маршрут, статус, класс ошибки | Владелец платформы |
| Хранилище отладочных данных | От нескольких часов до нескольких дней | Экстренный доступ или назначенные ответственные за инциденты | Отредактированные полезные нагрузки или полные полезные нагрузки только в виде исключения | Служба безопасности и владелец платформы |
| Файл аудиторских доказательств | Цикл продления или аудита | Отдел закупок, безопасность, финансы, юридический отдел | Политика, настройки хранения, скриншоты, результаты тестов, доказательства проверки доступа | Владелец отдела доверия или закупок |
Такая конструкция сохраняет полезность долгосрочных доказательств, не делая долгосрочное хранение полезной нагрузки простым путем. Файл аудита должен доказывать, что политика была применена; ему не нужно содержать необработанные промпты и ответы.
Редактируйте перед сохранением
Редактирования после отображения недостаточно. Если полезная нагрузка уже сохранена в базе данных, перенаправлена поставщику услуг трассировки, экспортирована в тикет или включена в оповещение веб-перехватчика, конфиденциальная копия уже существует.
Документация по маскированию от Langfuse является полезным примером: в ней описываются функции маскирования, которые редактируют конфиденциальную информацию до того, как данные трассировки покинут приложение, включая вводы, выводы, метаданные и атрибуты спанов OpenTelemetry. Функция Omit Logs от Helicone показывает тот же принцип проектирования с другой стороны: сохранять данные о стоимости, задержке и шаблонах использования, исключая при этом содержимое запросов и ответов из хранилища. Элементы управления логированием запросов от Portkey разделяют полное логирование и логирование только метрик на уровне организации.
Для внутренней политики шлюза сделайте редактирование тестируемым:
- Создайте тестовые наборы с электронными письмами, номерами телефонов, токенами доступа, ключами API, идентификаторами учетных записей, значениями, похожими на платежные, медицинскими терминами и проприетарным кодом.
- Прогоните те же тестовые наборы через входные данные промпта, извлеченный контекст, вывод инструмента, ответ модели, вывод ошибки и потоковые фрагменты.
- Проверьте сохраненный лог, представление на панели управления, полезную нагрузку оповещения, экспортер трассировки и экспорт для поддержки.
- Регистрируйте пропуски как ошибки безопасности, а не как проблемы с качеством контента.
- Повторно запускайте тесты при добавлении нового SDK, шлюза, экспортера трассировки или конечной точки модели.
Логирование полезной нагрузки AI API никогда не должно полагаться на одно регулярное выражение, вставленное в настройки панели управления и оставленное без тестирования.
Используйте переопределения для каждого запроса с осторожностью
Элементы управления для каждого запроса полезны, когда продукт имеет смешанные классы данных. В документации по логированию AI Gateway от Cloudflare описываются заголовки, которые могут переопределять логирование на уровне шлюза и отдельно контролировать, сохраняются ли необработанные тела запросов и ответов, в то время как метаданные продолжают логироваться.
Это правильная форма для трафика ИИ с высокой вариативностью, но она требует защитных механизмов:
- Сделайте безопасную настройку настройкой по умолчанию для новых маршрутов.
- Требуйте проверку кода для любого маршрута, который включает хранение полезной нагрузки.
- Привяжите переопределения к классу рабочей нагрузки, контракту с клиентом, среде и идентификатору инцидента.
- Предотвращайте тихое включение логирования полезной нагрузки заголовками, контролируемыми клиентом.
- Логируйте само решение политики: почему полезная нагрузка была сохранена или пропущена.
- Применяйте отказ в доступе по умолчанию, если политику невозможно оценить.
Логирование полезной нагрузки AI API для каждого запроса должно быть решением политики, принимаемым доверенным приложением или кодом шлюза, а не произвольным значением, передаваемым от конечного пользователя.
Что спросить у поставщика шлюза
Отделы закупок должны запрашивать доказательства, а не только названия функций. Используйте этот контрольный список при оценке шлюза AI API или уровня наблюдаемости.
| Вопрос | Какие доказательства запросить | Триггер для пересмотра |
|---|---|---|
| Можем ли мы вести логи только метаданных без тел промптов или ответов? | Скриншот или ответ API, показывающий, что хранение полезной нагрузки отключено, в то время как метаданные об использовании сохраняются | Любое изменение функции логирования или наблюдаемости |
| Можем ли мы включить логирование полезной нагрузки для одного маршрута, ключа, рабочего пространства или инцидента? | Скриншот политики, настройка API или тестовый запрос с поведением на уровне маршрута | Новый маршрут, тарифный план клиента или модель рабочего пространства |
| Можно ли редактировать полезные нагрузки перед сохранением? | Вывод теста редактирования для промпта, ответа, вывода инструмента и экспорта трассировки | Новая конечная точка модели, SDK, экспортер или интеграция с инструментом |
| Могут ли полные полезные нагрузки автоматически истекать? | Настройка хранения, доказательство выполнения задания на удаление, повторное чтение после истечения срока | Изменение политики хранения или цикл аудита |
| Логируются ли сами события доступа к логам полезной нагрузки? | Пример лога доступа, матрица ролей, рабочий процесс утверждения | Изменение роли или инцидент безопасности |
| Экспортируются ли логи в сторонние инструменты? | Диаграмма потоков данных и список назначений | Новая интеграция с SIEM, APM, поддержкой или хранилищем данных |
| Можем ли мы удалять или очищать исторические логи полезной нагрузки? | API удаления или доказательство процесса поддержки | Запрос клиента на удаление или расторжение контракта |
| Различает ли шлюз хранение у провайдера и хранение на шлюзе? | Документация о доверии, разделяющая оба уровня | Контракт с провайдером или изменение архитектуры шлюза |
Файл с доказательствами должен быть датирован. Скриншот от 4 июля 2026 года убедительнее, чем общее заявление на странице доверия, потому что он точно сообщает будущему проверяющему, что и когда было проверено.
Как это соотносится с Flatkey
Публичный сайт Flatkey в настоящее время позиционирует продукт как шлюз AI API и платформу для операций с моделями, которая объединяет доступ к моделям, маршрутизацию, биллинг, аналитику использования и операционные элементы управления для команд, поставляющих продукты с ИИ. Проверка API ценообразования от 4 июля 2026 года вернула живой ответ каталога с поддерживаемыми семействами конечных точек, включая /v1/chat/completions, /v1/messages, Gemini generateContent, генерацию изображений и видео конечные точки.
Это делает Flatkey естественным местом для централизации доказательств по маршрутам, моделям, использованию, затратам и владельцам. Что касается логирования полезной нагрузки AI API, покупателям все равно следует проверять текущую консоль Flatkey, текущие настройки учетной записи, контракты и любую документацию, предоставленную поддержкой, прежде чем предполагать определенное поведение хранения промптов/ответов. Если хранение полезной нагрузки является требованием закупки, запросите датированный файл с доказательствами, который разделяет:
- Что Flatkey хранит в качестве метаданных шлюза.
- Сохраняются ли необработанные тела промптов и ответов.
- Можно ли отключить или ограничить хранение полезной нагрузки.
- Какие применяются элементы управления хранением и удалением.
- Какие настройки хранения у провайдера также влияют на тот же запрос.
- Какие логи доступны покупателю, поддержке Flatkey и вышестоящим провайдерам.
Такое различие защищает обе стороны. Flatkey может быть операционным уровнем, в то время как покупатель сохраняет ясность в отношении границ данных.
Минимальное событие метаданных
Для многих команд самый безопасный вариант по умолчанию в производственной среде выглядит так:
{
"request_id": "req_01jz3...",
"timestamp": "2026-07-04T02:00:00Z",
"environment": "production",
"owner_key_id": "key_support_summarizer",
"customer_tier": "enterprise",
"route": "support-summary",
"endpoint_family": "chat-completions",
"provider": "selected_by_gateway",
"model_alias": "approved-summary-model",
"prompt_tokens": 1840,
"completion_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"redaction_policy": "not_applicable",
"fallback_used": false,
"retention_class": "ops_metadata_90d"
}Это событие может использоваться для проверки счетов, корреляции инцидентов, анализа маршрутов и аудиторских доказательств без сохранения тела запроса или ответа.
Рабочий процесс отладки без постоянного хранения полезной нагрузки
Когда инцидент требует доказательств в виде полезной нагрузки, используйте короткий рабочий процесс:
- Откройте инцидент с указанием владельца, маршрута, влияния на клиента и разрешенного класса данных.
- Включите отредактированное или полное логирование полезной нагрузки только для затронутого маршрута, ключа или образца трассировки.
- Установите срок действия до сбора первой полезной нагрузки.
- Запишите, кто утвердил изменение и кто может читать хранилище полезной нагрузки.
- Соберите наименьший образец, который воспроизводит проблему.
- Сохраните очищенную заметку об инциденте с идентификаторами запросов, классом ошибки, основной причиной и исправлением.
- Очистите хранилище полезной нагрузки или дождитесь истечения срока его действия.
- Сохраняйте аудиторские доказательства, а не необработанный запрос.
Это позволяет сохранить полезность логирования полезной нагрузки AI API для инженеров, ограничивая при этом долгосрочные затраты на конфиденциальность.
Какое место это занимает в проверке доверия
Логирование полезной нагрузки AI API — это один из уровней доказательств в более широкой проверке шлюза. Используйте чек-лист для корпоративного шлюза AI API, чтобы подтвердить доступ, маршрутизацию, биллинг, квоты и владение доказательствами. Используйте руководство по аудиторским логам использования AI API, когда покупателю нужны долговечные аудиторские события без хранения необработанных запросов. Используйте оценку рисков поставщика AI API, чтобы сравнить хранение данных у поставщика, контракты и обработку данных третьими сторонами перед продлением.
Чистая операционная модель заключается в том, чтобы поддерживать связь между этими файлами: чек-лист шлюза для готовности к запуску, аудиторские логи для долговечных доказательств, оценка рисков поставщика для закупок и логирование полезной нагрузки AI API для узкого вопроса о том, когда могут храниться запросы и ответы.
FAQ
Должен ли шлюз AI API логировать запросы и ответы по умолчанию?
Обычно нет. Логи, содержащие только метаданные, являются лучшим вариантом по умолчанию для производственной среды, поскольку они сохраняют доказательства использования, стоимости, маршрутизации, задержки и ошибок без хранения конфиденциальных тел запросов и ответов. Полное логирование полезной нагрузки AI API должно быть ограничено утвержденными рабочими процессами отладки или проверки.
Достаточно ли отредактированного логирования полезной нагрузки для соответствия требованиям?
Само по себе — нет. Качество редактирования, хранение, контроль доступа, места экспорта, контракты и контроль данных у поставщика — все это имеет значение. Рассматривайте редактирование как один из элементов контроля в более крупном файле доказательств.
Как долго следует хранить логи полезной нагрузки AI API?
Храните необработанные полезные нагрузки в течение кратчайшего практического окна отладки, часто это часы или дни, а не месяцы. Храните метаданные и аудиторские доказательства дольше, если этого требуют нужды биллинга, безопасности или закупок.
В чем разница между хранением у поставщика и хранением на шлюзе?
Хранение у поставщика описывает, что хранит вышестоящий поставщик модели после получения запроса. Хранение на шлюзе описывает, что хранит ваш собственный шлюз, уровень наблюдаемости, трассировки, оповещения и экспорты. Вам нужны доказательства для обоих случаев.
Что отдел закупок должен спросить у Flatkey перед утверждением?
Запросите актуальные, специфичные для аккаунта доказательства метаданных шлюза, поведения хранения полезной нагрузки, хранения, удаления, контроля доступа, маршрутизации к поставщикам и любых экспортов логов третьим сторонам. Затем сравните эти доказательства с вашей собственной классификацией данных и политикой реагирования на инциденты.
Итог
Логирование полезной нагрузки AI API должно упрощать отладку производственных AI-систем, не превращая каждый запрос в постоянную запись. Начните с логов, содержащих только метаданные, добавляйте захват отредактированной или краткосрочно хранимой полезной нагрузки только тогда, когда этого требует рабочий процесс, тестируйте редактирование перед сохранением и ведите датированный аудиторский файл для проверки отделом закупок. Когда вы будете готовы централизовать доступ к моделям и доказательства их использования через один шлюз, ознакомьтесь с текущими ценами и каталогом моделей Flatkey, а затем получите ключ.