AI API payload logging is one of the fastest ways to make model traffic debuggable, and one of the fastest ways to create a privacy problem. The same prompt and response that explain why a route failed may also contain customer messages, account data, documents, tool outputs, internal code, or regulated information.
The practical question is not whether an AI API gateway should have logs. It is what the gateway should record by default, when full payloads are allowed, how quickly sensitive content disappears, and what evidence remains for auditors after the debug window closes.
For Flatkey buyers, this belongs in the trust review because Flatkey is positioned as one API gateway for model access, routing, billing, usage analytics, and operational controls. A one-key gateway can simplify evidence collection, but it does not remove the need for a buyer-owned payload logging policy. Treat the policy as part of the production rollout, not as an afterthought once prompts are already flowing through shared logs.
AI API payload logging decision matrix
Use this matrix before enabling full prompt and response storage in any AI API gateway.
| Logging mode | What it stores | Best use | Privacy risk | Default recommendation |
|---|---|---|---|---|
| Metadata only | Request ID, key, owner, route, model, status, tokens, latency, cost, error class, retry/fallback flags | Operations, billing review, SLO review, incident triage | Lower, if user identifiers are minimized | Use as the default for most production traffic |
| Redacted payload | Prompt and response after deterministic masking or field removal | Debugging repeat failures without keeping raw secrets | Medium, because redaction can miss context-specific data | Allow for approved routes after testing redaction quality |
| Sampled payload | A small percentage of prompts/responses, usually with redaction | Quality review, regression analysis, support investigation | Medium to high, depending on data class | Use only with owner approval and sampling rules |
| Short-retention full payload | Raw prompt and response for a narrow debug window | Reproducing a severe incident, vendor escalation, migration testing | High | Limit to hours or days, require access logging, and purge on schedule |
| No payload log | No prompt or response body, sometimes no metadata beyond minimum billing/security fields | Sensitive workloads, regulated inputs, customer opt-out lanes | Lowest | Use for high-risk or contractual no-storage routes |
This is the core tradeoff: AI API payload logging can improve debugging, but the useful data is often the sensitive data. A governance-ready gateway policy starts with metadata, escalates to payloads only for specific reasons, and makes retention visible to security, privacy, and product owners.
Why payload logs are useful
Full payload logs can answer questions that metadata cannot:
- Was the model called with the prompt the application intended to send?
- Did a system message, tool schema, or retrieval result change the model behavior?
- Did a customer input contain hidden instructions, secrets, personal data, or malformed JSON?
- Did a fallback route receive a prompt that only the primary model was approved to see?
- Did an upstream provider return a malformed response, a refusal, or a partial stream?
- Did the request use the correct model alias, endpoint family, and owner key?
Without payload evidence, teams often debug AI incidents from symptoms: status code, latency, cost, and a customer complaint. That is sometimes enough for rate limits, queueing, and billing review. It is usually not enough for prompt injection, retrieval drift, tool-call schema breaks, unexpected content, or vendor escalation.
The answer is not to keep every prompt forever. The answer is to decide which payload evidence is necessary, how it is minimized, and who can open it.
Why payload logs are risky
The OWASP Logging Cheat Sheet is blunt about sensitive data in logs: secrets, access tokens, sensitive personal data, payment data, connection strings, encryption keys, and higher-classification data should usually be removed, masked, sanitized, hashed, or encrypted before logging. AI payloads can contain all of those categories because users paste real work into prompts.
AI API payload logging also creates risks that ordinary API logs do not always create:
- Long context windows can include many documents, chat turns, files, and tool outputs in one request.
- Model responses can repeat sensitive input, generate summaries of confidential documents, or include tool-returned data.
- Retries and fallbacks can duplicate the same payload across multiple providers or gateway lanes.
- Observability tools can copy payloads into traces, dashboards, alerts, exports, and support tickets.
- Debug screenshots and incident notes can preserve payload snippets after the original log expires.
If a team cannot explain where payloads are copied, the retention setting in the gateway is only part of the real data footprint.
Provider retention is not your gateway policy
Provider data controls are important, but they are not a substitute for your own AI API payload logging rules.
OpenAI's platform data controls say API data is not used to train OpenAI models by default, and that abuse monitoring logs may contain prompts and responses and are retained for up to 30 days unless a customer has approved controls such as Modified Abuse Monitoring or Zero Data Retention. The same OpenAI documentation also distinguishes abuse monitoring logs from application state, and some features retain state until deletion or for a feature-specific period.
Anthropic's API and data retention documentation describes Zero Data Retention as customer data not being stored at rest after the API response is returned, except where needed to comply with law or combat misuse. It also notes that different APIs and features have different storage needs, that some features are not ZDR eligible, and that policy-violation or legal retention can still apply.
Google's Gemini Developer API documentation says Paid Services prompts and responses are not used to improve Google's products, while also describing limited prompt and response logging for abuse monitoring and feature-specific storage such as grounding, interactions, files, and explicit context caching. It says ZDR requires specific actions or avoiding certain features.
The buyer lesson is simple: document provider settings and contracts, but keep a separate AI API gateway logging file that says what your own system stores before, during, and after the provider call.
Decide the evidence fields first
The safest way to design AI API payload logging is to start with an evidence table, not a toggle called "log prompts."
| Evidence field | Store by default? | Why it matters | Payload needed? |
|---|---|---|---|
| Request ID and trace ID | Yes | Lets support, security, and engineering refer to the same event | No |
| API key or owner ID | Yes, preferably stable internal ID | Enables chargeback, access review, and abuse investigation | No |
| User identifier | Sometimes, hashed or pseudonymous | Helps abuse and customer support investigations | No |
| Route, provider, model, endpoint family | Yes | Shows where the request actually went | No |
| Prompt token count, output token count, cost | Yes | Supports billing review and anomaly detection | No |
| Status, error class, retry/fallback path | Yes | Explains reliability and routing behavior | No |
| Safety, DLP, or policy match result | Yes, if used | Shows why a request was blocked or allowed | Usually no |
| Prompt text | No by default | Needed for prompt quality and certain incidents | Yes |
| Response text | No by default | Needed for output defects and vendor escalation | Yes |
| Tool inputs and outputs | No by default | Often contains business data from connected systems | Yes |
| Retrieval chunks or files | No by default | Often contains source documents, contracts, or customer data | Yes |
For most production teams, metadata-only logs plus an approved short-retention debug lane are enough. Full AI API payload logging should be a conscious exception, not the default state of every model call.
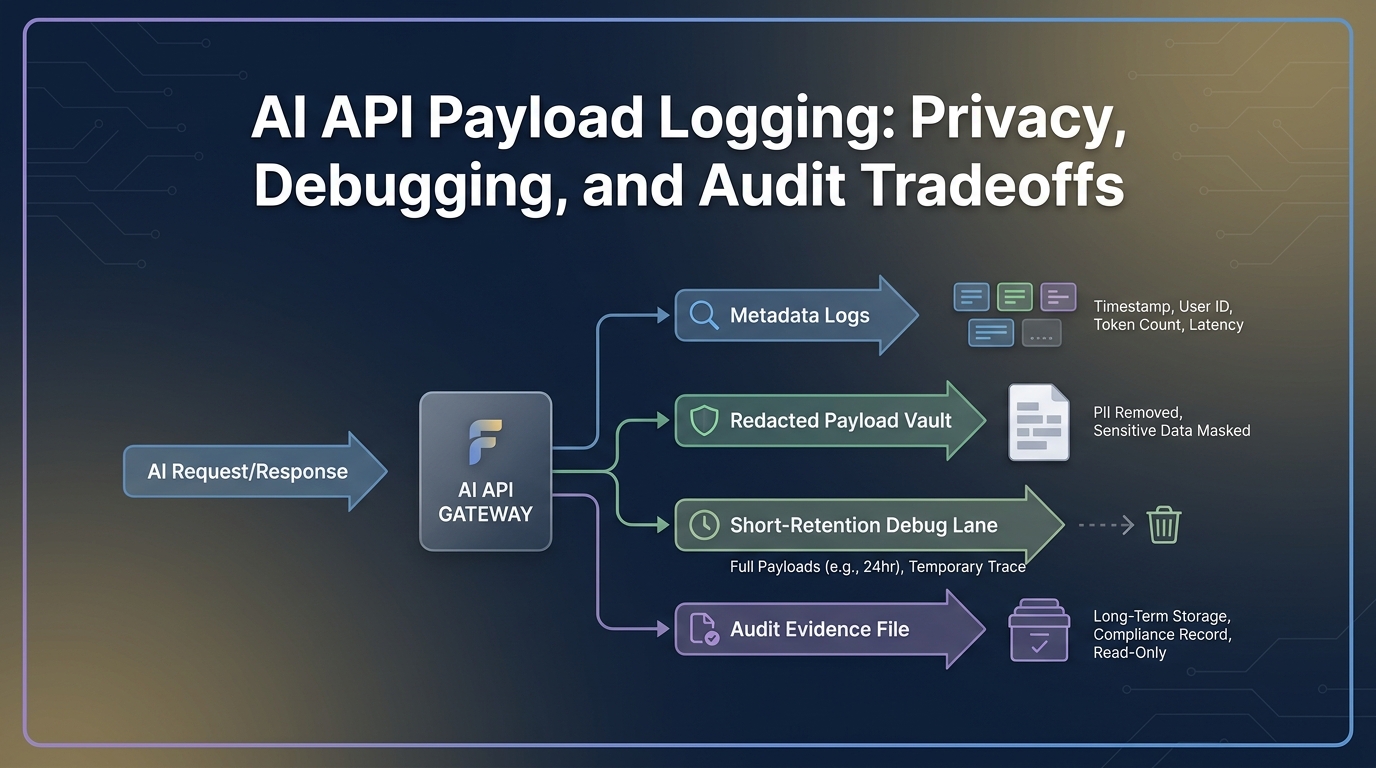
Build three lanes instead of one log bucket
A single log bucket creates the wrong incentives. Engineers want detail. Privacy reviewers want minimization. Auditors want evidence that survives. Separate the lanes.
| Lane | Retention | Access | Contents | Owner |
|---|---|---|---|---|
| Operations metadata | 30 to 180 days, based on billing and incident needs | Engineering, operations, finance, security | Request metadata, usage, cost, route, status, error class | Platform owner |
| Debug payload vault | Hours to a few days | Break-glass or named incident responders | Redacted payloads, or full payloads only by exception | Security and platform owner |
| Audit evidence file | Renewal or audit cycle | Procurement, security, finance, legal | Policy, retention settings, screenshots, test results, access-review evidence | Trust or procurement owner |
This design keeps the long-lived evidence useful without making long-lived payload storage the easy path. The audit file should prove the policy was applied; it does not need to contain raw prompts and responses.
Redact before storage
Redaction after display is not enough. If the payload is already stored in a database, forwarded to a tracing vendor, exported to a ticket, or included in a webhook alert, the sensitive copy already exists.
Langfuse's masking documentation is a useful pattern: it describes masking functions that redact sensitive information before trace data leaves the application, including inputs, outputs, metadata, and OpenTelemetry span attributes. Helicone's Omit Logs feature shows the same design principle from another angle: keep cost, latency, and usage patterns while excluding request and response content from storage. Portkey's request logging controls separate full logging from metrics-only logging at the organization level.
For an internal gateway policy, make redaction testable:
- Create fixtures with emails, phone numbers, access tokens, API keys, account IDs, payment-like values, health terms, and proprietary code.
- Run the same fixtures through prompt input, retrieved context, tool output, model response, error output, and streaming chunks.
- Verify the stored log, dashboard view, alert payload, trace exporter, and support export.
- Record misses as security bugs, not content-quality issues.
- Re-run the tests whenever a new SDK, gateway, tracing exporter, or model endpoint is added.
AI API payload logging should never rely on a single regex pasted into a dashboard setting and left untested.
Use per-request overrides carefully
Per-request controls are useful when a product has mixed data classes. Cloudflare's AI Gateway logging documentation describes headers that can override gateway-level logging and separately control whether raw request and response bodies are stored while metadata continues to be logged.
That is the right shape for high-variance AI traffic, but it needs guardrails:
- Make the safe setting the default for new routes.
- Require code review for any route that enables payload storage.
- Tie overrides to workload class, customer contract, environment, and incident ID.
- Prevent client-controlled headers from silently enabling payload logging.
- Log the policy decision itself: why the payload was kept or omitted.
- Fail closed when the policy cannot be evaluated.
Per-request AI API payload logging should be a policy decision made by trusted application or gateway code, not an arbitrary value passed from an end user.
What to ask a gateway vendor
Procurement teams should ask for evidence, not only feature names. Use this checklist when evaluating an AI API gateway or observability layer.
| Question | Evidence to request | Renewal trigger |
|---|---|---|
| Can we run metadata-only logs without prompt or response bodies? | Screenshot or API response showing payload storage disabled while usage metadata remains | Any logging or observability feature change |
| Can we enable payload logging for one route, key, workspace, or incident? | Policy screenshot, API setting, or test request with route-level behavior | New route, customer tier, or workspace model |
| Can payloads be redacted before storage? | Redaction test output across prompt, response, tool output, and trace export | New model endpoint, SDK, exporter, or tool integration |
| Can full payloads expire automatically? | Retention setting, deletion job evidence, readback after expiry | Retention policy change or audit cycle |
| Are access events to payload logs themselves logged? | Access log sample, role matrix, approval workflow | Role change or security incident |
| Are logs exported to third-party tools? | Data-flow diagram and destination list | New SIEM, APM, support, or warehouse integration |
| Can we delete or purge historical payload logs? | Deletion API or support process evidence | Customer deletion request or contract termination |
| Does the gateway distinguish provider retention from gateway retention? | Trust documentation separating both layers | Provider contract or gateway architecture change |
The evidence file should be dated. A screenshot from July 4, 2026 is stronger than a generic trust-page claim because it tells a future reviewer exactly what was checked and when.
How this fits with Flatkey
Flatkey's public site currently positions the product as an AI API gateway and model operations platform that unifies model access, routing, billing, usage analytics, and operational controls for teams shipping AI products. The July 4, 2026 pricing API check returned a live catalog response with supported endpoint families including /v1/chat/completions, /v1/messages, Gemini generateContent, image generation, and video endpoints.
That makes Flatkey a natural place to centralize route, model, usage, cost, and owner evidence. For AI API payload logging specifically, buyers should still validate the current Flatkey console, current account settings, contracts, and any support-provided documentation before assuming a prompt/response storage behavior. If payload retention is a procurement requirement, ask for a dated evidence file that separates:
- What Flatkey stores as gateway metadata.
- Whether raw prompt and response bodies are stored.
- Whether payload storage can be disabled or scoped.
- What retention and deletion controls apply.
- Which provider retention settings also affect the same request.
- Which logs are available to the buyer, Flatkey support, and upstream providers.
That distinction protects both sides. Flatkey can be the operating layer, while the buyer remains explicit about the data boundary.
A minimal metadata event
For many teams, the safest production default looks like this:
{
"request_id": "req_01jz3...",
"timestamp": "2026-07-04T02:00:00Z",
"environment": "production",
"owner_key_id": "key_support_summarizer",
"customer_tier": "enterprise",
"route": "support-summary",
"endpoint_family": "chat-completions",
"provider": "selected_by_gateway",
"model_alias": "approved-summary-model",
"prompt_tokens": 1840,
"completion_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"redaction_policy": "not_applicable",
"fallback_used": false,
"retention_class": "ops_metadata_90d"
}This event can support billing review, incident correlation, route analysis, and audit evidence without keeping the prompt or response body.
Debugging workflow without permanent payload storage
When an incident requires payload evidence, use a short workflow:
- Open an incident with owner, route, customer impact, and allowed data class.
- Enable redacted or full payload logging only for the affected route, key, or trace sample.
- Set an expiry before collecting the first payload.
- Record who approved the change and who can read the payload vault.
- Collect the smallest sample that reproduces the issue.
- Save a sanitized incident note with request IDs, error class, root cause, and fix.
- Purge or let the payload vault expire.
- Keep the audit evidence, not the raw prompt.
This keeps AI API payload logging useful for engineering while limiting the long-term privacy cost.
Where this fits in the trust review
AI API payload logging is one evidence layer in a broader gateway review. Use the enterprise AI API gateway checklist to confirm access, routing, billing, quota, and evidence ownership. Use the AI API usage audit logs guide when the buyer needs durable audit events without storing raw prompts. Use the AI API vendor risk assessment to compare provider retention, contracts, and third-party processing before renewal.
The clean operating model is to keep those files connected: gateway checklist for launch readiness, audit logs for durable evidence, vendor risk assessment for procurement, and AI API payload logging for the narrow question of when prompts and responses may be stored.
FAQ
Should an AI API gateway log prompts and responses by default?
Usually no. Metadata-only logs are a better default for production because they preserve usage, cost, routing, latency, and error evidence without storing sensitive prompt and response bodies. Full AI API payload logging should be scoped to approved debug or review workflows.
Is redacted payload logging enough for compliance?
Not by itself. Redaction quality, retention, access controls, export destinations, contracts, and provider data controls all matter. Treat redaction as one control in a larger evidence file.
How long should AI API payload logs be retained?
Keep raw payloads for the shortest practical debug window, often hours or days rather than months. Keep metadata and audit evidence longer when billing, security, or procurement needs require it.
What is the difference between provider retention and gateway retention?
Provider retention describes what the upstream model provider stores after receiving a request. Gateway retention describes what your own gateway, observability layer, traces, alerts, and exports store. You need evidence for both.
What should procurement ask Flatkey before approval?
Ask for current, account-specific evidence of gateway metadata, payload storage behavior, retention, deletion, access controls, provider routing, and any third-party log exports. Then compare that evidence with your own data classification and incident-response policy.
Bottom line
AI API payload logging should make production AI systems easier to debug without turning every prompt into a permanent record. Start with metadata-only logs, add redacted or short-retention payload capture only when the workflow requires it, test redaction before storage, and keep a dated audit file for procurement review. When you are ready to centralize model access and usage evidence through one gateway, review the current Flatkey pricing and model catalog, then get a key.