Eine Checkliste zur Datenaufbewahrung für KI-APIs sollte eine einfache Frage beantworten, bevor der Produktionsverkehr beginnt: Welche Datensätze existieren nach einem Modellaufruf, wer kann sie lesen, wie lange bleiben sie erhalten und welche Nachweise kann ein Käufer später überprüfen?
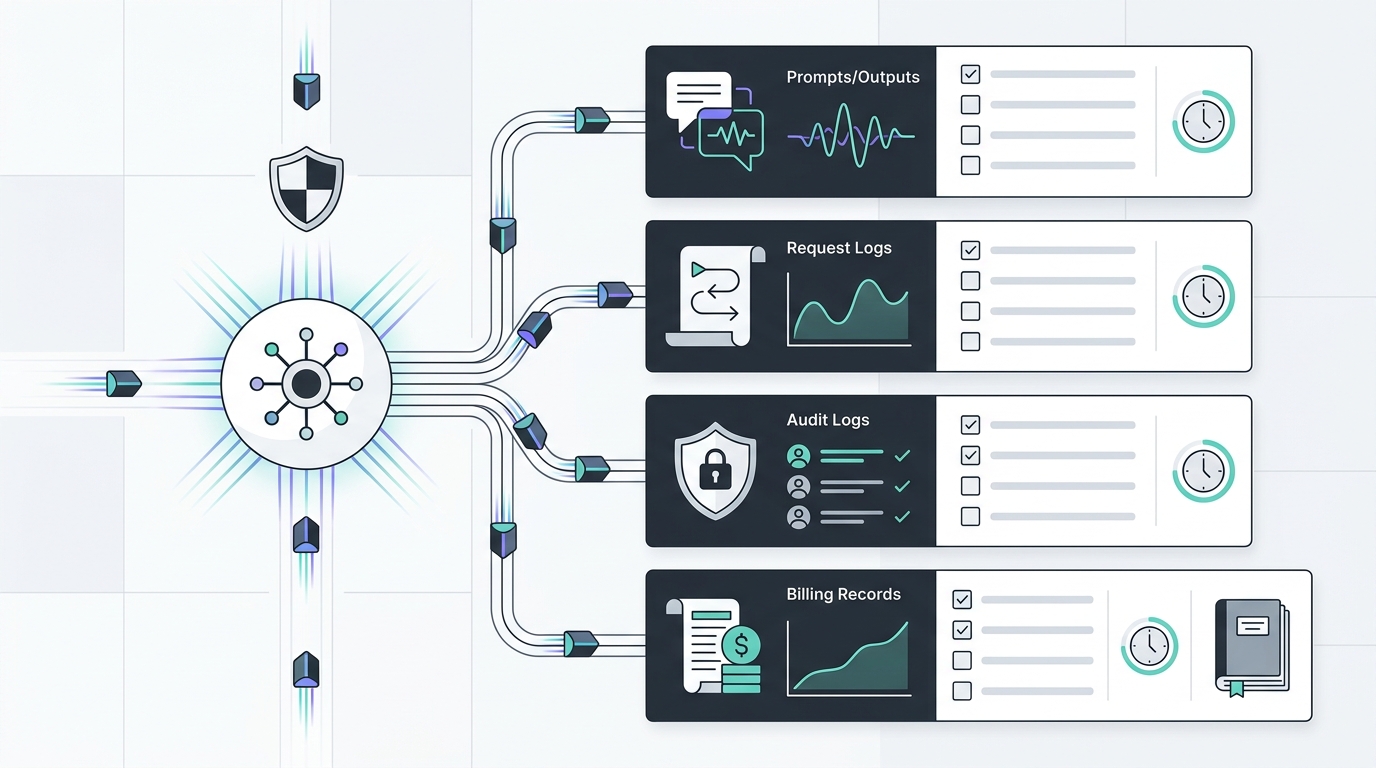
Diese Frage wird schnell unübersichtlich. Eine einzige KI-Anfrage kann Prompt-Datensätze, Output-Datensätze, Gateway-Anforderungsprotokolle, Missbrauchsüberwachungsprotokolle von Anbietern, Audit-Ereignisse, Traces, Cache-Einträge, Abrechnungszeilen, Support-Tickets, Exporte, Screenshots und Vorfallnotizen erstellen. Einige Datensätze helfen der Technik beim Debuggen von Fehlern. Einige helfen der Finanzabteilung beim Abgleich der Ausgaben. Einige helfen der Beschaffung nachzuweisen, dass eine Anbietereinstellung überprüft wurde. Einige sollten bei sensiblen Workloads überhaupt nicht existieren.
Verwenden Sie diese Checkliste zur Datenaufbewahrung für KI-APIs, um diese Datensätze zu trennen, bevor Sie echte Kundendaten durch ein Gateway leiten. Das Ziel ist nicht, blindlings weniger Datensätze aufzubewahren. Das Ziel ist es, die richtigen Nachweise für Betrieb, Sicherheit, Finanzen und Beschaffung aufzubewahren, ohne jeden Prompt und jeden Output in einen langlebigen Datenspeicher zu verwandeln.
Für Flatkey-Käufer gehört diese Überprüfung in die Genehmigungsdatei des Gateways. Die aktuelle öffentliche Website von Flatkey positioniert das Produkt als KI-API-Gateway und Modellbetriebsplattform für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und Betriebskontrollen. Das macht es zu einem natürlichen Ort, um Nachweise über Route, Modell, Eigentümer, Nutzung und Kosten zu zentralisieren. Es entbindet nicht von der Notwendigkeit, vor der Genehmigung die kontospezifische Aufbewahrung, Anbieterverträge und das Speicherverhalten von Payloads zu überprüfen.
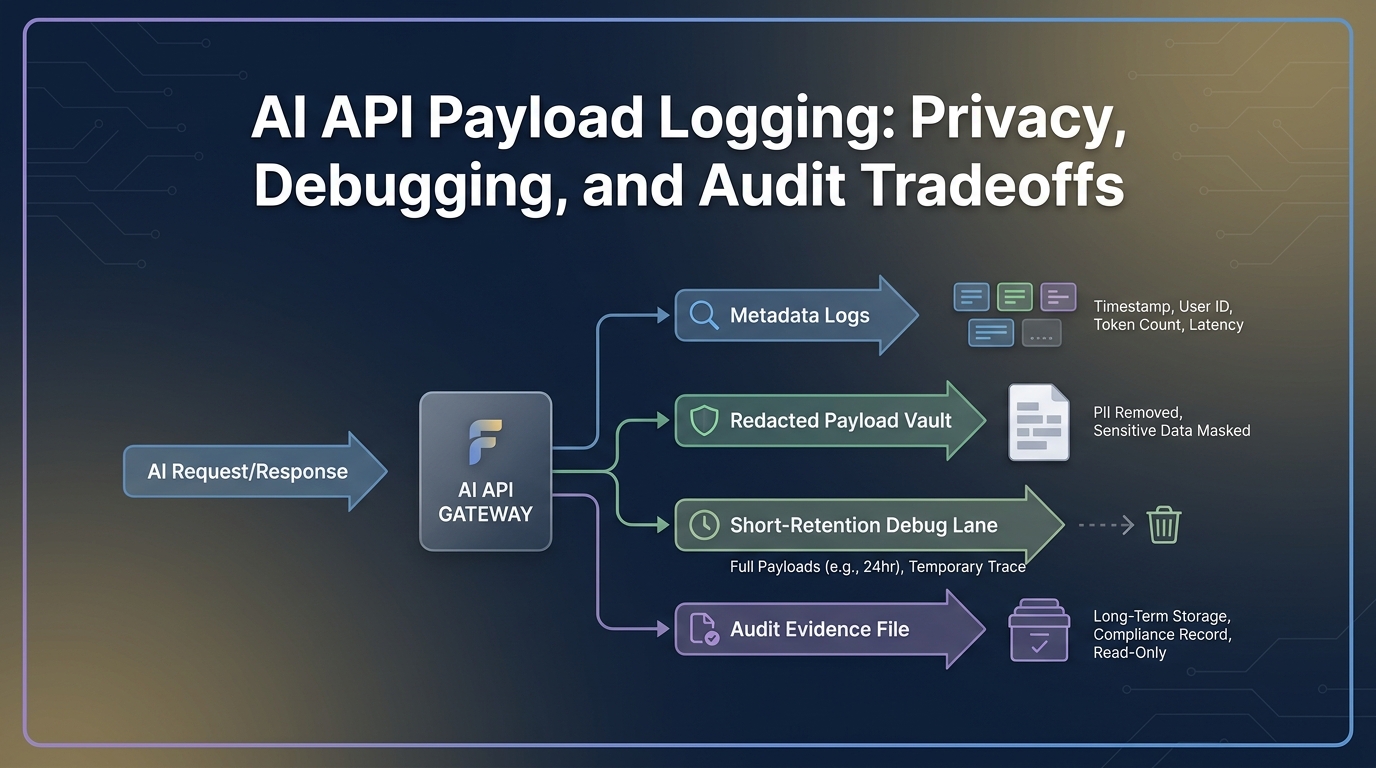
Checkliste zur Datenaufbewahrung für KI-APIs
Beginnen Sie mit der Datenkategorie, nicht mit dem Slogan des Anbieters. „Zero data retention“ für eine Anbieterfunktion beschreibt nicht automatisch Ihre Gateway-Protokolle, Observability-Traces, Abrechnungsbücher, Exporte oder Ihren Support-Workflow.
| Aufbewahrungsbereich | Was zu entscheiden ist | Aufzubewahrende Nachweise | Standardhaltung |
|---|---|---|---|
| Prompts | Ob rohe Benutzer-/System-/Entwicklernachrichten, abgerufener Kontext, Dateien und Werkzeugeingaben gespeichert werden | Datenflussdiagramm, Payload-Einstellung, Schwärzungstest, Löschtest | Standardmäßig keine rohen Prompts speichern |
| Outputs | Ob Modellantworten, Werkzeugaufruf-Argumente, generierte Dateien und gestreamte Chunks gespeichert werden | Richtlinie zur Output-Protokollierung, Aufbewahrungseinstellung, Zugriffstest | Standardmäßig keine rohen Outputs speichern |
| Anforderungsprotokolle | Welche Metadatenfelder für Debugging und Betrieb aufbewahrt werden | Beispiel-Protokollereignis, Feldverzeichnis, Aufbewahrungsfrist | Metadaten ohne Payload-Inhalte speichern |
| Audit-Protokolle | Welche administrativen und Richtlinien-Ereignisse unveränderlich genug für eine Überprüfung sind | Protokoll von Rollenänderungen, Protokoll von Schlüsselereignissen, Protokoll von Routenrichtlinienänderungen | Länger als Debug-Payloads speichern |
| Abrechnungsunterlagen | Welche Nutzungs-, Kosten-, Rechnungs-, Auflade-, Steuer- und Rückbuchungsdatensätze erhalten bleiben | Rechnungsbeispiel, Nutzungsexport, Abgleichsfelder | Gemäß den Anforderungen von Finanzen und Verträgen speichern |
| Anbieterdatensätze | Was vorgelagerte Modellanbieter für Missbrauchsüberwachung, Anwendungsstatus, Caching und Funktionsspeicherung aufbewahren | Anbieterdokumentation, Vertragsbedingungen, Konto-Screenshots | Pro Anbieter, Endpunkt und Konto überprüfen |
| Observability-Exporte | Welche Traces, Alarme, Dashboards, Tickets und Warehouses Kopien erhalten | Zielliste, Maskierungskonfiguration, Exportbeispiel | Vor dem Export minimieren und schwärzen |
| Support-Aufzeichnungen | Ob Vorfallnotizen Prompt-/Output-Ausschnitte enthalten | Support-Workflow, Ticket-Aufbewahrung, Schwärzungsregel | Bereinigte Nachweise speichern, keine rohen Payloads |
Dies ist die Kern-Checkliste zur Datenaufbewahrung für KI-APIs: Definieren Sie jede Datenkategorie, weisen Sie einen Verantwortlichen für die Aufbewahrung zu, belegen Sie die Einstellung mit einer datierten Rückmeldung und legen Sie einen Erneuerungsauslöser für jeden Ort fest, an den die Daten kopiert werden können.
Aufbewahrung vom Training trennen
Die Trainingsrichtlinie des Anbieters ist nur eine Zeile in der Überprüfung. Beschaffungsteams fragen oft, ob API-Daten zum Trainieren von Modellen verwendet werden. Das ist wichtig, beantwortet aber nicht, ob Prompts oder Outputs für Missbrauchsüberwachung, Anwendungsstatus, Produktfunktionen, Support, Analysen oder Abrechnung gespeichert werden.
Die Plattform-Datenkontrollen von OpenAI unterscheiden zwischen Modelltraining, Aufbewahrung zur Missbrauchsüberwachung und Aufbewahrung des Anwendungsstatus. Dieselbe Dokumentation besagt, dass Protokolle zur Missbrauchsüberwachung Prompts und Antworten enthalten können und standardmäßig bis zu 30 Tage aufbewahrt werden, während berechtigte Kunden Kontrollen wie Modified Abuse Monitoring oder Zero Data Retention beantragen können. Sie listet auch endpunktspezifische Ausnahmen auf, einschließlich des gespeicherten Anwendungsstatus für einige APIs und des funktionsspezifischen Verhaltens für Dateien, Konversationen, Videos, Caching, Websuche, gehostete Container und andere Funktionen.
Die Dokumentation zur API-Datenaufbewahrung von Anthropic definiert Zero Data Retention so, dass Kundendaten nach der Rückgabe der API-Antwort nicht im Ruhezustand gespeichert werden, mit Ausnahmen für rechtliche Anforderungen, Missbrauchsprävention und funktionsspezifische Speicherung. Es wird auch darauf hingewiesen, dass die Berechtigung für Funktionen je nach API-Fähigkeit unterschiedlich sein kann.
Die ZDR-Dokumentation der Gemini Developer API von Google besagt, dass Prompts und Antworten von kostenpflichtigen Diensten nicht zur Verbesserung der Produkte von Google verwendet werden, beschreibt aber auch eine begrenzte Protokollierung von Prompts und Antworten zur Missbrauchsüberwachung und funktionsspezifische Speicherung für bestimmte Funktionen. Die Seite macht ZDR zu einer Überprüfung der Konfiguration und Funktionsauswahl, nicht zu einer universellen Annahme.
Die praktische Lektion für Käufer lautet: Bewahren Sie Nachweise über die Richtlinien des Anbieters auf, aber lassen Sie diese nicht Ihre eigene Richtlinie zur Datenaufbewahrung für KI-APIs ersetzen. Der Anbieter bewahrt möglicherweise eine Sache auf, das Gateway eine andere, und Ihr Observability-Stack kopiert möglicherweise beide.
Prompts und Outputs benötigen eigene Regeln
Prompts und Outputs sind die risikoreichsten Datensätze in einer Checkliste zur Datenaufbewahrung für KI-APIs, da sie oft die nützlichsten Beweise für das Debugging und die sensibelsten Geschäftsdaten enthalten.
Behandeln Sie die Aufbewahrung von Prompts und Outputs als Ausnahme-Workflow:
- Standardmäßig keine Speicherung von Roh-Payloads für Produktionsrouten, es sei denn, ein bestimmter Workload erfordert dies.
- Geschwärzte Payload-Speicherung nur dann zulassen, wenn Fixtures beweisen, dass die Maskierung über Prompts, Outputs, Tool-Ergebnisse, Retrieval-Chunks, Fehler und Streaming-Ereignisse hinweg funktioniert.
- Vollständige Payload-Speicherung nur zulassen für einen benannten Vorfall, einen Staging-Test, einen vom Kunden genehmigten Workflow oder eine Eskalation an den Anbieter.
- Ablaufdatum vor der Erfassung festlegen, damit das Debug-Fenster nicht zu einem permanenten Speicher wird.
- Zugriff auf Payload-Logs protokollieren, da der Log-Viewer zu einem sensiblen System wird.
- Die bereinigte Zusammenfassung des Vorfalls aufbewahren, nachdem der Payload abgelaufen ist, nicht den rohen Prompt oder Output.
Das OWASP Logging Cheat Sheet ist hier nützlich, da es sensible Werte in Logs als Designproblem und nicht als Formatierungsproblem behandelt. Secrets, Zugriffstoken, sensible personenbezogene Daten, Zahlungsdaten, Verbindungszeichenfolgen, Verschlüsselungsschlüssel und Daten mit hoher Klassifizierung sollten in der Regel vor der Protokollierung entfernt, maskiert, bereinigt, gehasht oder verschlüsselt werden. KI-Prompts können all diese Kategorien enthalten.
Bei Schwärzungsmustern weisen die Tool-Dokumentationen in die gleiche Richtung. Langfuse masking kann Daten schwärzen, bevor Trace-Daten die Anwendung verlassen. Helicone Omit Logs ist darauf ausgelegt, operative Metriken beizubehalten, während Anfrage- und Antwortkörper weggelassen werden. Portkey request logging controls trennen Anfrage-/Antwortinhalte von der metrikenorientierten Protokollierung. Auch wenn Sie einen anderen Stack verwenden, ist das Muster dasselbe: vor der Speicherung und dem Export schwärzen oder weglassen.
Bei Anfrage-Logs sollten Metadaten an erster Stelle stehen
Anfrage-Logs sind in der Regel das Arbeitspferd des KI-API-Betriebs. Sie müssen keine rohen Prompts enthalten, um nützlich zu sein.
Für die meisten Produktionsrouten reicht ein Ereignis, das primär Metadaten enthält:
{
"request_id": "req_01jz4...",
"timestamp": "2026-07-04T04:00:00Z",
"environment": "production",
"owner_key_id": "support_summarizer_prod",
"route": "support-summary",
"endpoint_family": "chat_completions",
"requested_model": "approved-summary-route",
"served_provider": "selected_by_gateway",
"prompt_tokens": 1840,
"output_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"retention_class": "ops_metadata_90d"
}
Dieses Ereignis unterstützt die Überprüfung von Abrechnungen, die Korrelation von Vorfällen, die Überprüfung des Routings, die Überprüfung von SLOs, die Untersuchung von Missbrauch und die Rückverrechnung an den Eigentümer, ohne den Prompt- oder Antwortkörper aufzubewahren.
Die Protokollierung des Cloudflare AI Gateway zeigt, warum Entscheidungen zur Anfrageprotokollierung explizit sein müssen. Gateway-Logs können Anbieter, Modell, Status, Token-Nutzung, Kosten, Dauer, Prompts, Antworten und Richtlinienaktionen enthalten, und anfragespezifische Steuerungen können beeinflussen, ob Anfrage- und Antwortkörper gespeichert werden. Eine Checkliste zur Aufbewahrung sollte sowohl die Standardeinstellung des Gateways als auch jeden Pfad zur anfragespezifischen Überschreibung erfassen.
Verwenden Sie diese Checkliste für Anfrage-Logs:
| Feldgruppe | Standardmäßig aufbewahren? | Anmerkungen |
|---|---|---|
| Anfrage-ID, Trace-ID, Zeitstempel | Ja | Erforderlich für Support und Überprüfung von Vorfällen |
| Schlüssel, Projekt, Route, Umgebung | Ja | Stabile interne IDs verwenden; rohe Secrets vermeiden |
| Anbieter, Modell, Endpunktfamilie | Ja | Erforderlich für Routing und Nachweise für Anbieter |
| Status, Fehlerklasse, Grund für Wiederholung/Fallback | Ja | Erforderlich für die Überprüfung der Zuverlässigkeit |
| Token-Anzahl, Latenz, Kosten | Ja | Erforderlich für Finanzen und Anomalieerkennung |
| Ergebnis von Sicherheit/DLP/Richtlinie | Normalerweise | Metadaten der Entscheidung speichern, nicht den sensiblen übereinstimmenden Text, es sei denn, dies ist erforderlich |
| Prompt-Körper | Standardmäßig nein | Über den Debug-Workflow eskalieren |
| Output-Körper | Standardmäßig nein | Über den Debug-Workflow eskalieren |
| Tool-Eingaben und -Ausgaben | Standardmäßig nein | Enthält oft private Systemdaten |
| Retrieval-Chunks und Dateien | Standardmäßig nein | Enthält oft Dokumente, Verträge oder Kundendaten |
Hier wird die Datenaufbewahrung für KI-APIs operativ statt theoretisch: Ingenieure erhalten weiterhin die Datensätze, die sie benötigen, während die Verantwortlichen für Datenschutz und Sicherheit sehen können, was absichtlich weggelassen wird.
Audit-Logs sind keine Payload-Logs
Audit-Logs beantworten, wer etwas geändert hat, wann es geändert wurde und ob der Kontrollpfad funktioniert hat. Sie sollten in der Regel länger als Debug-Payloads aufbewahrt werden, aber sie sollten nicht zu einem Hintertür-Payload-Speicher werden.
Eine Checkliste zur Datenaufbewahrung für KI-APIs sollte Audit-Ereignisse für Folgendes enthalten:
- Erstellung, Rotation, Deaktivierung und Löschung von API-Schlüsseln.
- Änderungen an Workspace, Projekt, Route, Anbieter und Modellrichtlinien.
- Änderungen an Kontingenten, Budgets und Abrechnungskontrollen.
- Aktivierung, Deaktivierung und Ausnahmegenehmigungen für die Payload-Protokollierung.
- Zugriffsereignisse für sensible Protokolle und Exporte.
- Änderungen von Administratorrollen und Berechtigungsvergaben.
- Ereignisse für Datenexport, -löschung und Support-Eskalationen.
Audit-Protokolle sollten den Akteur, das Ziel, die Aktion, den Zeitstempel, das Quellsystem, die Genehmigungsreferenz und den Vorher-/Nachher-Zustand benennen. Sie sollten die Speicherung von rohen Prompts, rohen Outputs, rohen API-Schlüsseln, Bearer-Token, Zahlungskartendaten und ungeschwärzten Kundendaten vermeiden.
Verbinden Sie diesen Artikel mit dem Leitfaden von Flatkey zu Audit-Protokollen für die Nutzung von KI-APIs, wenn die Beschaffung ein dauerhaftes Ereignismodell für Gateway-Operationen benötigt. Das Audit-Protokoll sollte belegen, dass eine Aufbewahrungsrichtlinie angewendet wurde; es muss nicht die sensible Payload aufbewahren, die die Richtlinie ausgelöst hat.
Abrechnungsunterlagen haben andere Aufbewahrungsanforderungen
Abrechnungsunterlagen werden in einer Checkliste zur Datenaufbewahrung für KI-APIs leicht übersehen, da sie nicht wie Prompt-Daten aussehen. Dennoch sind sie wichtig.
Abrechnungs- und Finanzunterlagen können Folgendes umfassen:
- IDs von API-Schlüsseln, Workspaces, Teams, Projekten, Kunden oder Umgebungen.
- Modell, Anbieter, Endpunktfamilie und Route.
- Prompt-Token, Output-Token, zwischengespeicherte Token, Bild-/Videoeinheiten, Dauer oder Anzahl der Anfragen.
- Stückpreis, effektiver Preis, Aufschlag, Guthaben, Steuern, Rechnungsposition, Aufladedatensatz, Rückerstattung und Kontobewegung.
- Zeitstempel, Abrechnungszeitraum, Rechnungs-ID, Zahlungsanbieter-ID und Hauptbuchreferenz.
Diese Unterlagen müssen in der Regel länger aufbewahrt werden als Debug-Payloads, da Finanz-, Steuer-, Kundensupport- und Beschaffungsteams Abstimmungsnachweise benötigen. Dennoch müssen sie minimiert werden. Ein Abrechnungsbuch sollte keine rohen Prompts oder Outputs benötigen, um Ausgaben nachzuweisen.
Verwenden Sie diese Tabelle zur Aufbewahrung von Abrechnungsdaten:
| Abrechnungsartefakt | Typischer Eigentümer | Frage zur Aufbewahrung | Payload erforderlich? |
|---|---|---|---|
| Nutzungszeile | Finanzbetrieb und Plattform | Wie lange benötigen wir Nachweise für Rückbuchungen? | Nein |
| Rechnung | Finanzen | Welche steuerlichen, prüfungsrelevanten und kundenvertraglichen Regeln gelten? | Nein |
| Aufladung oder Bewegung des Prepaid-Guthabens | Finanzen | Kann das Team Guthabenänderungen mit der Nutzung abgleichen? | Nein |
| Preis-Momentaufnahme | Beschaffung und Finanzen | Welcher Stückpreis war zum Zeitpunkt der Anfrage aktiv? | Nein |
| Aufzeichnung von Kundenstreitigkeiten | Support und Finanzen | Welche bereinigten Nachweise erklären die Gebühr? | Normalerweise nicht |
| Lieantenrechnung | Finanzen und Beschaffung | Können vorgelagerte Ausgaben der internen Nutzung zugeordnet werden? | Nein |
Die aktuelle Preisseite von Flatkey beschreibt transparente Modellpreise, Pay-as-you-go-Nutzung, Kontingentgrenzen, Nutzungsanalysen, Kostenkontrollen und Wege zur Rechnungsprüfung. Betrachten Sie diese als nützliche öffentliche Angaben zur Vorauswahl und überprüfen Sie dann das Live-Dashboard, die Kontobedingungen, Rechnungen und Exporte für Ihre eigenen Käuferunterlagen.
Erstellen Sie eine käufereigene Nachweisdatei
Trust-Seiten sind hilfreich, aber das dauerhafte Artefakt sollte im Besitz des Käufers sein. Ein Prüfer sollte in sechs Monaten sehen können, was am Genehmigungsdatum geprüft wurde und was sich später geändert hat.
Erstellen Sie einen Ordner oder einen Governance-Datensatz mit dieser Struktur:
| Nachweiselement | Was zu erfassen ist | Auslöser für die Erneuerung |
|---|---|---|
| Datenflussplan | Anfragepfad von der App zum Gateway, Anbieter, zur Beobachtbarkeit, Abrechnung, zum Support und zu den Exporten | Neuer Anbieter, neues Tool, neue Route oder neuer Exporteur |
| Anbietereinstellungen | Screenshots oder API-Readbacks für Aufbewahrung, Training, ZDR/MAM, Region und Verhalten des Anwendungszustands | Anbietervertrags- oder Funktionsänderung |
| Gateway-Einstellungen | Anfrageprotokollierung, Payload-Protokollierung, Schwärzung, Löschung, Routenrichtlinie und Exportkontrollen | Gateway-Release oder Konfigurationsänderung |
| Beispiel-Metadatenprotokoll | Bereinigtes, produktionsähnliches Ereignis ohne Payload-Body | Neue Endpunktfamilie oder Route |
| Schwärzungstest | Fixture-Ergebnisse für Prompts, Outputs, Werkzeugdaten, Retrieval-Chunks und Stream-Chunks | Neues SDK, Modell, Werkzeug oder Exporteur |
| Aufzeichnung von Payload-Ausnahmen | Wer hat die vollständige Payload-Protokollierung genehmigt, warum, Umfang, Ablaufdatum und Nachweis der Bereinigung | Jeder Vorfall |
| Beispiel für ein Audit-Ereignis | Ereignisse für Schlüssel, Route, Kontingent, Rolle, Protokollierung, Export und Löschung | Änderung der Rolle oder des Admin-Workflows |
| Abrechnungsbeispiel | Nutzungszeile, Preis-Momentaufnahme, Rechnungs-/Aufladungsnachweis und Eigentümerzuordnung | Änderung des Preis- oder Abrechnungs-Workflows |
| Zugriffsüberprüfung | Wer kann Protokolle, Payload-Tresore, Exporte, Rechnungen und Support-Tickets einsehen | Vierteljährlich oder bei Rollenänderung |
| Löschtest | Nachweis, dass Protokolle, Payloads, Exporte und Tickets ablaufen oder bereinigt werden können | Änderung der Aufbewahrungsrichtlinie oder des Kundenlöschprozesses |
Diese Nachweisdatei verwandelt die Datenaufbewahrung für KI-APIs von einer Anbieterbehauptung in einen wiederholbaren Überprüfungsprozess. Sie erleichtert auch Vertragsverlängerungen, da der Prüfer den aktuellen Zustand mit dem vorherigen vergleichen kann, anstatt mit Marketingtexten von vorne zu beginnen.
Legen Sie Aufbewahrungsklassen vor dem Start fest
Lassen Sie nicht jedes System seine eigene Aufbewahrungsfrist erfinden. Definieren Sie Aufbewahrungsklassen und ordnen Sie jeden Datensatz einer solchen zu.
retention_classes:
ops_metadata_90d:
stores_payload: false
records:
- request_id
- route
- provider
- model
- status
- latency
- token_usage
- cost
access: engineering_ops_finance_security
debug_payload_72h:
stores_payload: true
approval_required: true
redaction_required: true
expiration_required_before_collection: true
access: named_incident_responders
audit_control_1y:
stores_payload: false
records:
- actor
- action
- target
- before_after_state
- approval_reference
access: security_procurement_admins
finance_ledger_contract_term:
stores_payload: false
records:
- usage
- pricing_snapshot
- invoice
- recharge
- balance_movement
access: finance_procurement
Die genauen Zeiträume sollten sich aus Ihren Verträgen, Sicherheitsrichtlinien, steuerlichen Anforderungen und Kundenverpflichtungen ergeben. Wichtig ist, dass die Klasse existiert, bevor der Traffic beginnt, und dass die Payload-Speicherung als separate Eigenschaft sichtbar ist.
Wie dies zu Flatkey passt
Flatkey kann das Betriebsmodell unterstützen, da sich die öffentliche Produktoberfläche auf ein API-Gateway, Modell-Routing, Nutzungstransparenz, Abrechnung, Quotensteuerung und operative Überprüfung konzentriert. Die Live-Preis-API-Prüfung vom 4. Juli 2026 lieferte success=true, 45 Modellzeilen, 48 Anbieterdatensätze, Preisversion a42d372ccf0b5dd13ecf71203521f9d2 und unterstützte Endpunktpfade, einschließlich /v1/chat/completions, /v1/messages, Gemini generateContent, Bildgenerierungs- und Video-Endpunkte.
Nutzen Sie Flatkey als Nachweisoberfläche des Gateways und überprüfen Sie dann die kontospezifischen Details, die öffentliche Seiten nicht belegen können:
- Welche Anfragemetadaten Flatkey speichert.
- Ob rohe Prompt- und Antwort-Bodies gespeichert werden.
- Ob die Payload-Speicherung deaktiviert, bereichsbezogen, geschwärzt oder zeitlich begrenzt werden kann.
- Welche Audit-Ereignisse für Schlüssel, Routen, Quoten, Abrechnung und Protokollzugriff verfügbar sind.
- Welche Abrechnungsexporte für den Finanzabgleich verfügbar sind.
- Welche Aufbewahrungseinstellungen des Anbieters hinter jeder Route gelten.
- Welche Support-, Export- und Beobachtbarkeitspfade Anfragedaten kopieren können.
Diese Unterscheidung ist wichtig. Ein Gateway kann den Betrieb und die Beweiserhebung vereinfachen, aber der Käufer ist immer noch für die endgültige Checkliste zur Datenaufbewahrung der KI-API verantwortlich.
Führen Sie einen Vorproduktions-Aufbewahrungstest durch
Bevor Sie eine Produktionsroute genehmigen, führen Sie die Checkliste mit einer Test-Workload durch.
- Senden Sie eine normale Anfrage und bestätigen Sie, dass das Metadatenprotokoll ohne den Prompt- oder Output-Body erscheint.
- Senden Sie eine Anfrage mit gesäten sensiblen Testdaten wie E-Mails, Zeichenketten im Format von Zugriffstoken, Konto-IDs, zahlungsähnlichen Werten und Markern für proprietären Code.
- Bestätigen Sie, dass diese Testdaten nicht in Protokollen, Traces, Warnungen, Support-Exporten oder Abrechnungsunterlagen erscheinen, es sei denn, die Route hat explizit einen genehmigten Debug-Pfad betreten.
- Aktivieren Sie eine bereichsbezogene Ausnahme für Debug-Payloads in einer Nicht-Produktionsumgebung und überprüfen Sie die Genehmigung, Zugriffsprotokollierung, Schwärzung und den Ablauf.
- Löschen Sie die Daten oder warten Sie die Debug-Aufbewahrungsfrist ab und bestätigen Sie, dass beim erneuten Lesen die Payload nicht mehr zurückgegeben wird.
- Rufen Sie ein Audit-Ereignis für die Änderung der Protokollierungsrichtlinie und die Löschung ab.
- Rufen Sie eine Abrechnungs- oder Nutzungszeile ab und bestätigen Sie, dass sie ohne Payload-Inhalt abgeglichen wird.
- Zeichnen Sie Screenshots, API-Readbacks, Zeitstempel, Konto-IDs und Prüfernamen in der Nachweisdatei auf.
Dieser Test deckt den häufigen Fehler auf: Ein Team deaktiviert die Payload-Speicherung im Gateway, gibt aber dennoch Prompt-Text über einen Trace-Exporter, eine Warnmeldung, ein Support-Ticket oder einen Debug-Screenshot preis.
Wo dies in der Vertrauensprüfung einzuordnen ist
Die Datenaufbewahrung bei KI-APIs ist ein Teil einer umfassenderen Gateway-Überprüfung. Verwenden Sie die Checkliste für Enterprise-KI-API-Gateways, um Zugriff, Routing, Abrechnung, Quoten und die operative Verantwortung abzudecken. Verwenden Sie die Risikobewertung für KI-API-Anbieter, um Verträge mit vorgelagerten Anbietern und Drittverarbeitern zu vergleichen. Verwenden Sie den Leitfaden zu Audit-Protokollen für die KI-API-Nutzung, wenn die Beschaffungsabteilung fragt, wie ein Gateway nachweist, wer Schlüssel, Routen, Quoten und Protokollierungsrichtlinien geändert hat.
Diese Überprüfungen sollten miteinander verbunden sein. Die Gateway-Checkliste zeigt die Steuerungsoberfläche. Die Risikobewertung des Anbieters zeigt den vorgelagerten Vertrag und die Datengrenze. Der Leitfaden zu Audit-Protokollen zeigt dauerhafte administrative Nachweise. Diese Checkliste zur Datenaufbewahrung bei KI-APIs zeigt, was nach jeder Anfrage zurückbleibt.
FAQ
Was ist die Datenaufbewahrung bei KI-APIs?
Die Datenaufbewahrung bei KI-APIs ist die Richtlinie und das Systemverhalten, das festlegt, wie lange Prompts, Outputs, Metadatenprotokolle, Audit-Ereignisse, Traces, Abrechnungszeilen, Support-Aufzeichnungen und anbieterseitige Aufzeichnungen nach einer KI-API-Anfrage gespeichert werden.
Ist eine Null-Datenaufbewahrung dasselbe wie keine Protokolle?
Nein. Null-Datenaufbewahrung beschreibt in der Regel eine anbieter- oder funktionsspezifische Kontrolle für Kundeninhalte. Sie deckt möglicherweise nicht Gateway-Metadaten, Audit-Protokolle, Abrechnungsunterlagen, Beobachtbarkeitsexporte, Support-Tickets oder jede Anbieterfunktion ab. Überprüfen Sie immer den Geltungsbereich und die Ausnahmen.
Sollten Prompts und Outputs zum Debuggen gespeichert werden?
Nur ausnahmsweise. Metadatenprotokolle sollten der Standard für den Produktionsverkehr sein. Speichern Sie geschwärzte oder vollständige Payloads nur für genehmigte Workflows, begrenzte Vorfälle, Staging-Tests oder vom Kunden genehmigte Pfade und legen Sie vor der Erfassung ein Ablaufdatum fest.
Wie lange sollten Protokolle von KI-API-Anfragen aufbewahrt werden?
Es gibt keinen universellen Zeitraum. Metadatenprotokolle benötigen oft genug Zeit für die Überprüfung von Vorfällen, den Abgleich von Abrechnungen und die Untersuchung von Missbrauch. Rohe Prompt- und Output-Payloads sollten in der Regel eine viel kürzere Aufbewahrungsfrist haben als Metadaten, Audit-Protokolle oder Abrechnungsunterlagen.
Welche Abrechnungsunterlagen sind für die Aufbewahrung von KI-APIs wichtig?
Bewahren Sie Nutzungszeilen, Token-Anzahlen, Modell-/Anbieterkennungen, Preis-Snapshots, Rechnungen, Aufladeaufzeichnungen, Rückerstattungen und Eigentümerzuordnungen als Finanznachweise auf. Diese Aufzeichnungen sollten keine rohen Prompt- oder Output-Inhalte erfordern.
Was sollte die Beschaffung einen Gateway-Anbieter fragen?
Fordern Sie datierte Nachweise über Anfragemetadaten, das Speicherverhalten von Payloads, Schwärzung, Löschung, Audit-Logs, Zugriffskontrollen, Abrechnungsexporte, Aufbewahrungseinstellungen des Anbieters und Exportziele von Drittanbietern an. Vergleichen Sie diese Nachweise dann mit Ihrer eigenen Richtlinie zur Datenklassifizierung und Reaktion auf Vorfälle.
Fazit
Eine Checkliste zur Datenaufbewahrung für KI-APIs verwandelt vage Vertrauensbehauptungen in eine überprüfbare Betriebsakte. Trennen Sie Prompts von Outputs, Anfrageprotokolle von Audit-Logs und Abrechnungsunterlagen von Debug-Payloads. Bewahren Sie Metadaten standardmäßig auf, speichern Sie rohe Payloads nur in Ausnahmefällen, testen Sie die Schwärzung vor der Speicherung und bewahren Sie datierte Nachweise für Verlängerungen auf. Wenn Sie bereit sind, Modellzugriff, Nutzung, Abrechnung und Routing über eine einzige Gateway-Schnittstelle zu zentralisieren, sehen Sie sich den aktuellen Preis- und Modellkatalog von Flatkey an und fordern Sie einen Schlüssel an.