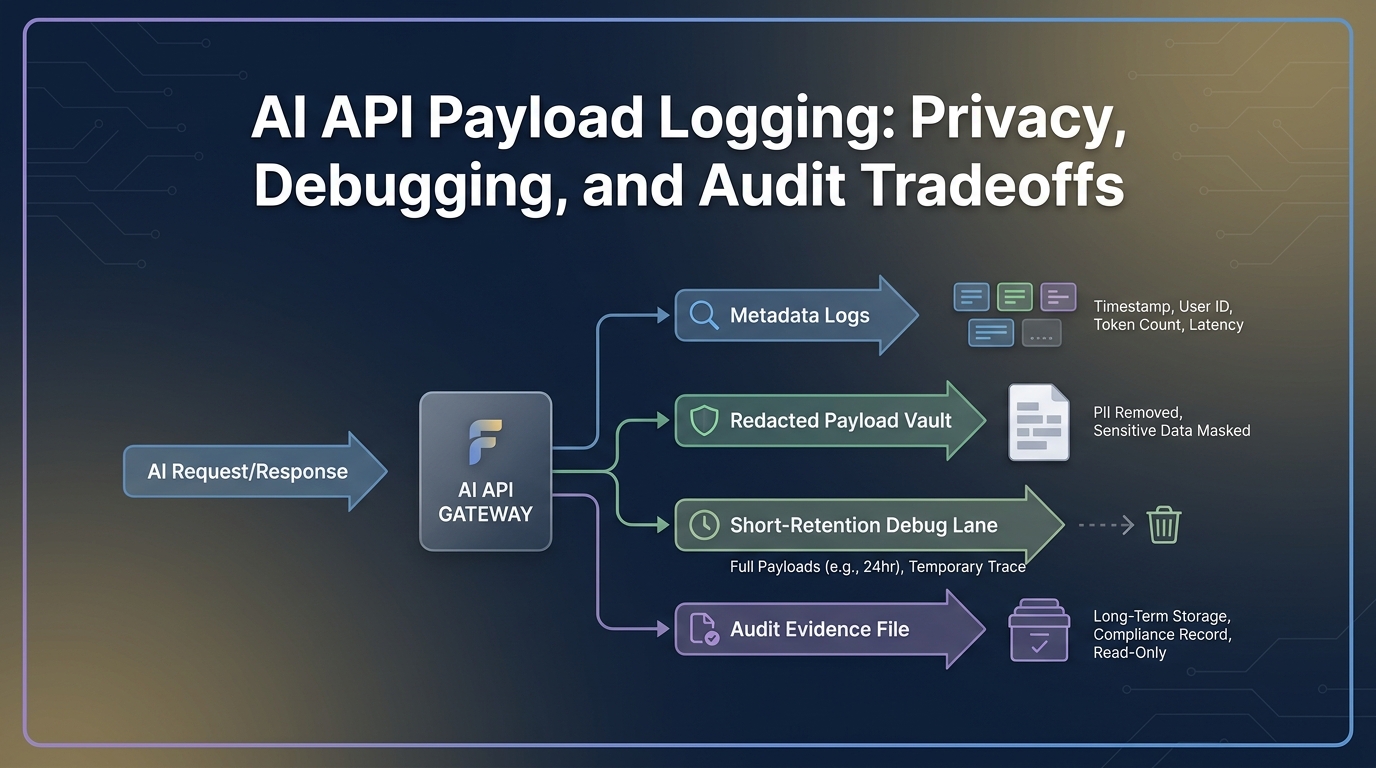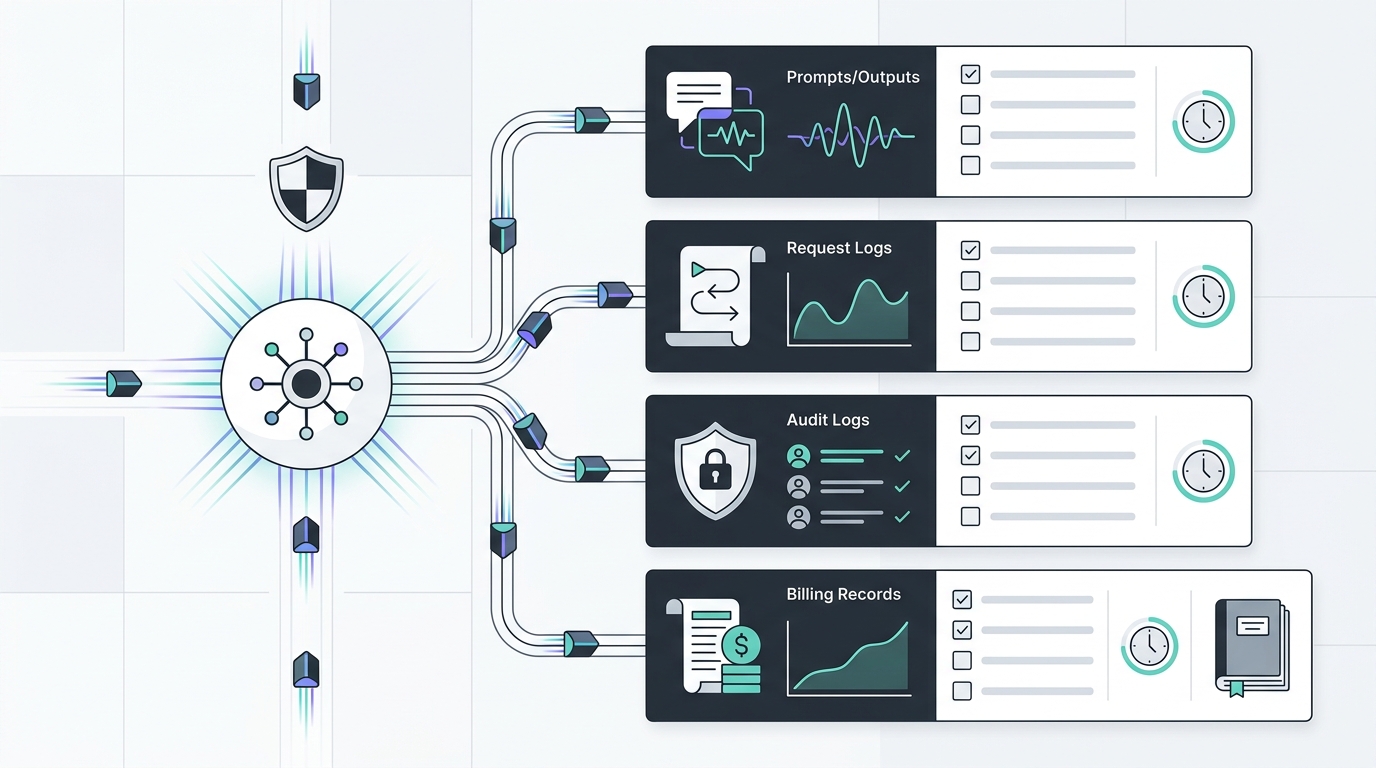
An AI API data retention checklist should answer a simple question before production traffic starts: which records will exist after a model call, who can read them, how long they stay, and what evidence a buyer can review later?
That question gets messy quickly. A single AI request can create prompt records, output records, gateway request logs, provider abuse-monitoring logs, audit events, traces, cache entries, billing rows, support tickets, exports, screenshots, and incident notes. Some records help engineering debug failures. Some help finance reconcile spend. Some help procurement prove that a vendor setting was reviewed. Some should not exist at all for sensitive workloads.
Use this AI API data retention checklist to separate those records before you route real customer data through a gateway. The goal is not to keep fewer records blindly. The goal is to keep the right evidence for operations, security, finance, and procurement without turning every prompt and output into a long-lived data store.
For Flatkey buyers, this review belongs in the gateway approval file. Flatkey’s current public site positions the product as an AI API gateway and model operations platform for model access, routing, billing, usage analytics, and operational controls. That makes it a natural place to centralize evidence about route, model, owner, usage, and cost. It does not remove the need to verify account-specific retention, provider contracts, and payload storage behavior before approval.
AI API data retention checklist
Start with the record class, not the vendor slogan. “Zero data retention” for one provider feature does not automatically describe your gateway logs, observability traces, billing ledger, exports, or support workflow.
| Retention surface | What to decide | Evidence to keep | Default posture |
|---|---|---|---|
| Prompts | Whether raw user/system/developer messages, retrieved context, files, and tool inputs are stored | Data-flow diagram, payload setting, redaction test, deletion test | Do not store raw prompts by default |
| Outputs | Whether model responses, tool-call arguments, generated files, and streamed chunks are stored | Output logging policy, retention setting, access test | Do not store raw outputs by default |
| Request logs | Which metadata fields are kept for debugging and operations | Sample log event, field dictionary, retention period | Store metadata without payload bodies |
| Audit logs | Which administrative and policy events are immutable enough for review | Role-change log, key event log, route-policy change log | Store longer than debug payloads |
| Billing records | Which usage, cost, invoice, recharge, tax, and chargeback records survive | Invoice sample, usage export, reconciliation fields | Store according to finance and contract needs |
| Provider records | What upstream model providers retain for abuse monitoring, application state, caching, and feature storage | Provider docs, contract terms, account screenshots | Verify per provider, endpoint, and account |
| Observability exports | Which traces, alerts, dashboards, tickets, and warehouses receive copies | Destination list, masking config, export sample | Minimize and redact before export |
| Support records | Whether incident notes include prompt/output snippets | Support workflow, ticket retention, redaction rule | Store sanitized evidence, not raw payloads |
This is the core AI API data retention checklist: define every record class, assign a retention owner, prove the setting with a dated readback, and set a renewal trigger for every place the data can be copied.
Separate retention from training
Provider training policy is only one row in the review. Procurement teams often ask whether API data is used to train models. That matters, but it does not answer whether prompts or outputs are stored for abuse monitoring, application state, product features, support, analytics, or billing.
OpenAI’s platform data controls distinguish model training, abuse monitoring retention, and application-state retention. The same documentation says abuse monitoring logs may include prompts and responses and are retained up to 30 days by default, while eligible customers can apply for controls such as Modified Abuse Monitoring or Zero Data Retention. It also lists endpoint-specific exceptions, including stored application state for some APIs and feature-specific behavior for files, conversations, videos, caching, web search, hosted containers, and other capabilities.
Anthropic’s API data retention documentation frames Zero Data Retention as customer data not being stored at rest after the API response is returned, with exceptions for legal requirements, misuse prevention, and feature-specific storage. It also notes that feature eligibility can differ by API capability.
Google’s Gemini Developer API ZDR documentation says Paid Services prompts and responses are not used to improve Google’s products, while also describing limited prompt and response logging for abuse monitoring and feature-specific storage for certain capabilities. The page makes ZDR a configuration and feature-selection review, not a universal assumption.
The buyer lesson is practical: keep provider policy evidence, but do not let it replace your own AI API data retention policy. The provider may retain one thing, the gateway may retain another, and your observability stack may copy both.
Prompts and outputs need their own rules
Prompts and outputs are the highest-risk records in an AI API data retention checklist because they often contain the most useful debugging evidence and the most sensitive business data.
Treat prompt and output retention as an exception workflow:
- Default to no raw payload storage for production routes unless a specific workload needs it.
- Allow redacted payload storage only after fixtures prove that masking works across prompts, outputs, tool results, retrieval chunks, errors, and streaming events.
- Allow full payload storage only for a named incident, staging test, customer-approved workflow, or vendor escalation.
- Set expiration before collection so the debug window cannot become permanent storage.
- Log access to payload logs because the log viewer becomes a sensitive system.
- Keep the cleaned incident summary after the payload expires, not the raw prompt or output.
The OWASP Logging Cheat Sheet is useful here because it treats sensitive values in logs as a design problem, not a formatting problem. Secrets, access tokens, sensitive personal data, payment data, connection strings, encryption keys, and high-classification data should usually be removed, masked, sanitized, hashed, or encrypted before logging. AI prompts can contain all of those categories.
For redaction patterns, tool docs point in the same direction. Langfuse masking can redact data before trace data leaves the application. Helicone Omit Logs is designed to keep operational metrics while omitting request and response bodies. Portkey request logging controls separate request/response content from metrics-oriented logging. Even if you use a different stack, the pattern is the same: redact or omit before storage and export.
Request logs should be metadata first
Request logs are usually the workhorse of AI API operations. They do not need to contain raw prompts to be useful.
For most production routes, a metadata-first event is enough:
{
"request_id": "req_01jz4...",
"timestamp": "2026-07-04T04:00:00Z",
"environment": "production",
"owner_key_id": "support_summarizer_prod",
"route": "support-summary",
"endpoint_family": "chat_completions",
"requested_model": "approved-summary-route",
"served_provider": "selected_by_gateway",
"prompt_tokens": 1840,
"output_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"retention_class": "ops_metadata_90d"
}
That event supports billing review, incident correlation, routing review, SLO review, abuse investigation, and owner chargeback without retaining the prompt body or response body.
Cloudflare AI Gateway logging shows why request-log decisions need to be explicit. Gateway logs can include provider, model, status, token usage, cost, duration, prompts, responses, and policy actions, and per-request controls can affect whether request and response bodies are stored. A retention checklist should capture both the default gateway setting and any per-request override path.
Use this request-log checklist:
| Field group | Keep by default? | Notes |
|---|---|---|
| Request ID, trace ID, timestamp | Yes | Needed for support and incident review |
| Key, project, route, environment | Yes | Use stable internal IDs; avoid raw secrets |
| Provider, model, endpoint family | Yes | Needed for routing and vendor evidence |
| Status, error class, retry/fallback reason | Yes | Needed for reliability review |
| Token counts, latency, cost | Yes | Needed for finance and anomaly detection |
| Safety/DLP/policy result | Usually | Store decision metadata, not sensitive matched text unless required |
| Prompt body | No by default | Escalate through debug workflow |
| Output body | No by default | Escalate through debug workflow |
| Tool inputs and outputs | No by default | Often contains private system data |
| Retrieval chunks and files | No by default | Often contains documents, contracts, or customer data |
This is where AI API data retention becomes operational instead of theoretical: engineers still get the records they need, while privacy and security owners can see what is intentionally omitted.
Audit logs are not payload logs
Audit logs answer who changed something, when it changed, and whether the control path worked. They should usually survive longer than debug payloads, but they should not become a backdoor payload store.
An AI API data retention checklist should include audit events for:
- API key creation, rotation, disablement, and deletion.
- Workspace, project, route, provider, and model-policy changes.
- Quota, budget, and billing control changes.
- Payload logging enablement, disablement, and exception approvals.
- Access events for sensitive logs and exports.
- Admin role changes and permission grants.
- Data export, deletion, and support escalation events.
Audit logs should name the actor, target, action, timestamp, source system, approval reference, and before/after state. They should avoid storing raw prompts, raw outputs, raw API keys, bearer tokens, payment card data, and unredacted customer data.
Connect this article with Flatkey’s guide to audit logs for AI API usage when procurement needs a durable event model for gateway operations. The audit log should prove a retention policy was applied; it does not need to preserve the sensitive payload that triggered the policy.
Billing records have different retention needs
Billing records are easy to overlook in an AI API data retention checklist because they do not look like prompt data. They still matter.
Billing and finance records may include:
- API key, workspace, team, project, customer, or environment IDs.
- Model, provider, endpoint family, and route.
- Prompt tokens, output tokens, cached tokens, image/video units, duration, or request count.
- Unit price, effective price, markup, credits, taxes, invoice line, recharge record, refund, and balance movement.
- Timestamp, billing period, invoice ID, payment provider ID, and ledger reference.
These records usually need to survive longer than debug payloads because finance, tax, customer support, and procurement teams need reconciliation evidence. They still need minimization. A billing ledger should not need raw prompts or outputs to prove spend.
Use this billing-retention table:
| Billing artifact | Typical owner | Retention question | Payload needed? |
|---|---|---|---|
| Usage row | Finance operations and platform | How long do we need chargeback evidence? | No |
| Invoice | Finance | What tax, audit, and customer contract rules apply? | No |
| Recharge or prepaid balance movement | Finance | Can the team reconcile balance changes to usage? | No |
| Pricing snapshot | Procurement and finance | Which unit price was active when the request ran? | No |
| Customer dispute record | Support and finance | What sanitized evidence explains the charge? | Usually no |
| Vendor invoice | Finance and procurement | Can upstream spend be tied to internal usage? | No |
Flatkey’s current pricing page describes transparent model pricing, pay-as-you-go usage, quota limits, usage analytics, cost controls, and billing review paths. Treat those as useful public screening claims, then verify the live dashboard, account terms, invoices, and exports for your own buyer record.
Build a buyer-owned evidence file
Trust pages are helpful, but the durable artifact should be buyer-owned. A reviewer six months from now should be able to see what was checked on the approval date and what changed later.
Create a folder or governance record with this structure:
| Evidence item | What to capture | Renewal trigger |
|---|---|---|
| Data-flow map | Request path from app to gateway, provider, observability, billing, support, and exports | New provider, tool, route, or exporter |
| Provider settings | Screenshots or API readbacks for retention, training, ZDR/MAM, region, and application-state behavior | Provider contract or feature change |
| Gateway settings | Request logging, payload logging, redaction, deletion, route policy, and export controls | Gateway release or configuration change |
| Sample metadata log | Sanitized production-like event without payload body | New endpoint family or route |
| Redaction test | Fixture results for prompts, outputs, tool data, retrieval chunks, and stream chunks | New SDK, model, tool, or exporter |
| Payload exception record | Who approved full payload logging, why, scope, expiration, and purge evidence | Every incident |
| Audit event sample | Key, route, quota, role, logging, export, and deletion events | Role or admin workflow change |
| Billing sample | Usage row, pricing snapshot, invoice/recharge evidence, and owner mapping | Pricing or billing workflow change |
| Access review | Who can view logs, payload vaults, exports, invoices, and support tickets | Quarterly or role change |
| Deletion test | Proof that logs, payloads, exports, and tickets can expire or be purged | Retention policy or customer deletion process change |
This evidence file turns AI API data retention from a vendor claim into a repeatable review process. It also makes renewals easier because the reviewer can compare the current state with the previous state instead of restarting from marketing copy.
Set retention classes before launch
Do not let each system invent its own retention period. Define retention classes and map every record to one.
retention_classes:
ops_metadata_90d:
stores_payload: false
records:
- request_id
- route
- provider
- model
- status
- latency
- token_usage
- cost
access: engineering_ops_finance_security
debug_payload_72h:
stores_payload: true
approval_required: true
redaction_required: true
expiration_required_before_collection: true
access: named_incident_responders
audit_control_1y:
stores_payload: false
records:
- actor
- action
- target
- before_after_state
- approval_reference
access: security_procurement_admins
finance_ledger_contract_term:
stores_payload: false
records:
- usage
- pricing_snapshot
- invoice
- recharge
- balance_movement
access: finance_procurement
The exact periods should come from your contracts, security policy, tax requirements, and customer commitments. The important part is that the class exists before traffic starts and that payload storage is visible as a separate property.
How this fits with Flatkey
Flatkey can support the operating model because the public product surface centers on one API gateway, model routing, usage visibility, billing, quota controls, and operational review. The July 4, 2026 live pricing API check returned success=true, 45 model rows, 48 vendor records, pricing version a42d372ccf0b5dd13ecf71203521f9d2, and supported endpoint paths including /v1/chat/completions, /v1/messages, Gemini generateContent, image generation, and video endpoints.
Use Flatkey as the gateway evidence surface, then verify the account-specific details that public pages cannot prove:
- Which request metadata Flatkey stores.
- Whether raw prompt and response bodies are stored.
- Whether payload storage can be disabled, scoped, redacted, or time-limited.
- Which audit events are available for keys, routes, quota, billing, and log access.
- Which billing exports are available for finance reconciliation.
- Which provider retention settings apply behind each route.
- Which support, export, and observability paths can copy request data.
This distinction matters. A gateway can simplify operations and evidence collection, but the buyer still owns the final AI API data retention checklist.
Run a pre-production retention test
Before approving a production route, run the checklist against a test workload.
- Send a normal request and confirm the metadata log appears without the prompt or output body.
- Send a request containing seeded sensitive fixtures such as emails, access-token-shaped strings, account IDs, payment-like values, and proprietary-code markers.
- Confirm those fixtures do not appear in logs, traces, alerts, support exports, or billing records unless the route explicitly entered an approved debug lane.
- Enable a scoped debug payload exception in a non-production environment and verify approval, access logging, redaction, and expiration.
- Purge or wait out the debug retention period and confirm readback no longer returns the payload.
- Pull an audit event for the logging-policy change and the purge.
- Pull a billing or usage row and confirm it reconciles without payload content.
- Record screenshots, API readbacks, timestamps, account IDs, and reviewer names in the evidence file.
This test catches the common failure: a team disables payload storage in the gateway but still leaks prompt text through a trace exporter, alert message, support ticket, or debug screenshot.
Where this sits in the trust review
AI API data retention is one part of a broader gateway review. Use the enterprise AI API gateway checklist to cover access, routing, billing, quotas, and operating ownership. Use the AI API vendor risk assessment to compare upstream provider contracts and third-party processors. Use the audit logs for AI API usage guide when procurement asks how a gateway proves who changed keys, routes, quotas, and logging policy.
Those reviews should connect. The gateway checklist shows the control surface. The vendor risk assessment shows the upstream contract and data boundary. The audit log guide shows durable administrative evidence. This AI API data retention checklist shows what stays behind after each request.
FAQ
What is AI API data retention?
AI API data retention is the policy and system behavior that determines how long prompts, outputs, metadata logs, audit events, traces, billing rows, support records, and provider-side records are stored after an AI API request.
Is zero data retention the same as no logs?
No. Zero data retention usually describes a provider or feature-specific control for customer content. It may not cover gateway metadata, audit logs, billing records, observability exports, support tickets, or every provider feature. Always verify scope and exceptions.
Should prompts and outputs be stored for debugging?
Only by exception. Metadata logs should be the default for production traffic. Store redacted or full payloads only for approved workflows, scoped incidents, staging tests, or customer-approved lanes, and set expiration before collection.
How long should AI API request logs be kept?
There is no universal period. Metadata logs often need enough time for incident review, billing reconciliation, and abuse investigation. Raw prompt and output payloads should usually have much shorter retention than metadata, audit logs, or billing records.
What billing records matter for AI API retention?
Keep usage rows, token counts, model/provider identifiers, pricing snapshots, invoices, recharge records, refunds, and owner mappings as finance evidence. These records should not require raw prompt or output bodies.
What should procurement ask a gateway vendor?
Ask for dated evidence of request metadata, payload storage behavior, redaction, deletion, audit logs, access controls, billing exports, provider retention settings, and third-party export destinations. Then compare that evidence with your own data-classification and incident-response policy.
Conclusion
An AI API data retention checklist turns vague trust claims into a reviewable operating file. Separate prompts from outputs, request logs from audit logs, and billing records from debug payloads. Keep metadata by default, store raw payloads only by exception, test redaction before storage, and preserve dated evidence for renewals. When you are ready to centralize model access, usage, billing, and routing through one gateway surface, review Flatkey’s current pricing and model catalog, then get a key.