Una checklist de retención de datos para AI API debería responder a una pregunta sencilla antes de que comience el tráfico de producción: ¿qué registros existirán después de una llamada al modelo, quién puede leerlos, cuánto tiempo se conservan y qué pruebas puede revisar un comprador más adelante?
Esa pregunta se complica rápidamente. Una sola solicitud de IA puede crear registros de prompts, registros de resultados, logs de solicitudes de la puerta de enlace, logs de supervisión de abusos del proveedor, eventos de auditoría, trazas, entradas de caché, filas de facturación, tickets de soporte, exportaciones, capturas de pantalla y notas de incidentes. Algunos registros ayudan a ingeniería a depurar fallos. Algunos ayudan a finanzas a conciliar los gastos. Algunos ayudan a adquisiciones a demostrar que se revisó una configuración del proveedor. Algunos no deberían existir en absoluto para cargas de trabajo sensibles.
Utilice esta checklist de retención de datos para AI API para separar esos registros antes de dirigir los datos reales de los clientes a través de una puerta de enlace. El objetivo no es conservar menos registros a ciegas. El objetivo es conservar las pruebas adecuadas para operaciones, seguridad, finanzas y adquisiciones sin convertir cada prompt y resultado en un almacén de datos de larga duración.
Para los compradores de Flatkey, esta revisión pertenece al archivo de aprobación de la puerta de enlace. El sitio público actual de Flatkey posiciona el producto como una puerta de enlace de AI API y una plataforma de operaciones de modelos para el acceso, enrutamiento, facturación, análisis de uso y controles operativos de los modelos. Eso lo convierte en un lugar natural para centralizar las pruebas sobre la ruta, el modelo, el propietario, el uso y el coste. No elimina la necesidad de verificar la retención específica de la cuenta, los contratos del proveedor y el comportamiento del almacenamiento de la carga útil antes de la aprobación.
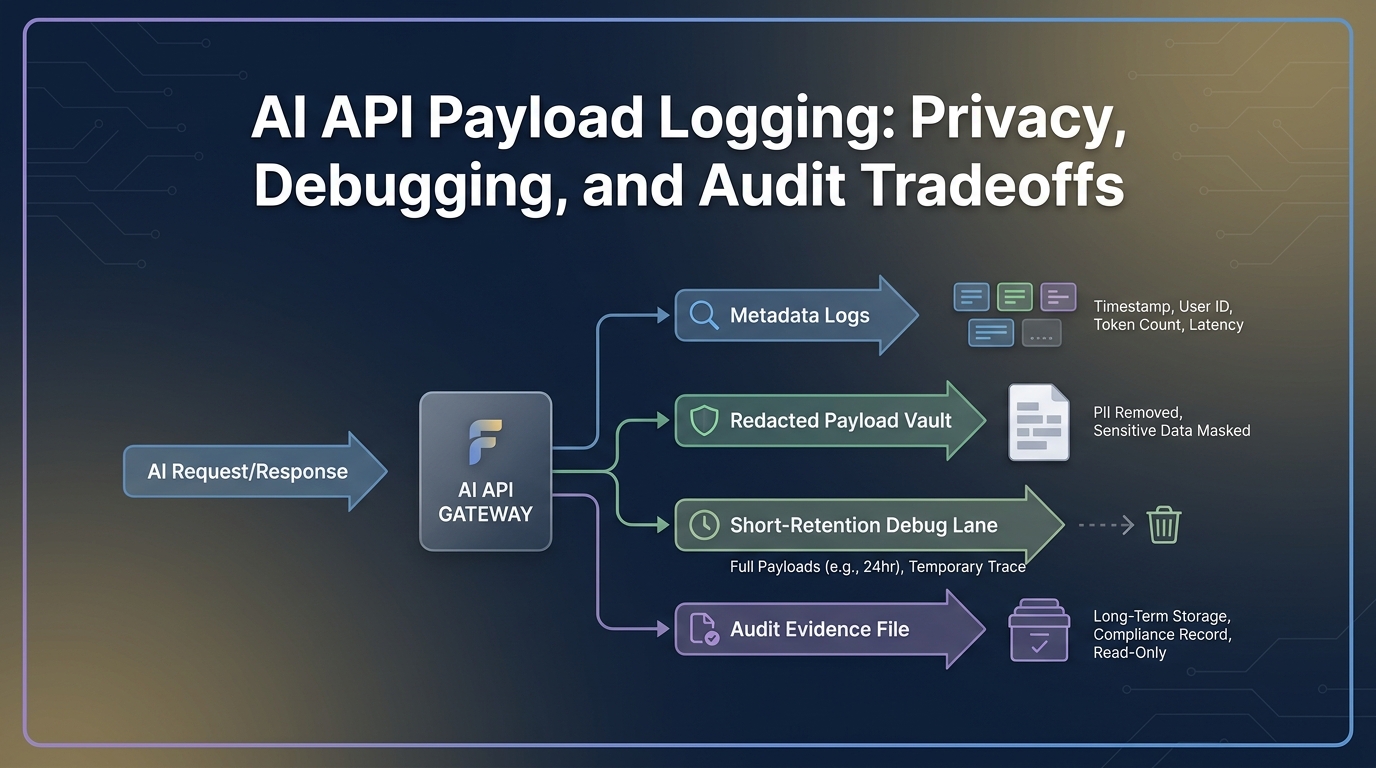
Checklist de retención de datos para AI API
Empiece por la clase de registro, no por el eslogan del proveedor. La “retención cero de datos” para una función de un proveedor no describe automáticamente los logs de su puerta de enlace, las trazas de observabilidad, el libro mayor de facturación, las exportaciones o el flujo de trabajo de soporte.
| Superficie de retención | Qué decidir | Pruebas a conservar | Postura por defecto |
|---|---|---|---|
| Prompts | Si se almacenan los mensajes brutos del usuario/sistema/desarrollador, el contexto recuperado, los archivos y las entradas de herramientas | Diagrama de flujo de datos, configuración de la carga útil, prueba de redacción, prueba de eliminación | No almacenar prompts brutos por defecto |
| Resultados | Si se almacenan las respuestas del modelo, los argumentos de llamada a herramientas, los archivos generados y los fragmentos transmitidos | Política de registro de resultados, configuración de retención, prueba de acceso | No almacenar resultados brutos por defecto |
| Logs de solicitudes | Qué campos de metadatos se conservan para la depuración y las operaciones | Evento de log de muestra, diccionario de campos, período de retención | Almacenar metadatos sin los cuerpos de la carga útil |
| Logs de auditoría | Qué eventos administrativos y de políticas son lo suficientemente inmutables para su revisión | Log de cambio de rol, log de eventos clave, log de cambio de política de ruta | Almacenar durante más tiempo que las cargas útiles de depuración |
| Registros de facturación | Qué registros de uso, coste, factura, recarga, impuestos y contracargos sobreviven | Muestra de factura, exportación de uso, campos de conciliación | Almacenar según las necesidades financieras y contractuales |
| Registros del proveedor | Qué retienen los proveedores de modelos ascendentes para la supervisión de abusos, el estado de la aplicación, el almacenamiento en caché y el almacenamiento de funciones | Documentos del proveedor, términos del contrato, capturas de pantalla de la cuenta | Verificar por proveedor, punto final y cuenta |
| Exportaciones de observabilidad | Qué trazas, alertas, paneles, tickets y almacenes reciben copias | Lista de destinos, configuración de enmascaramiento, muestra de exportación | Minimizar y redactar antes de exportar |
| Registros de soporte | Si las notas de incidentes incluyen fragmentos de prompts/resultados | Flujo de trabajo de soporte, retención de tickets, regla de redacción | Almacenar pruebas saneadas, no cargas útiles brutas |
Esta es la checklist principal de retención de datos para AI API: definir cada clase de registro, asignar un propietario de la retención, probar la configuración con una relectura fechada y establecer un activador de renovación para cada lugar donde se puedan copiar los datos.
Separar la retención del entrenamiento
La política de entrenamiento del proveedor es solo una fila en la revisión. Los equipos de adquisiciones a menudo preguntan si los datos de la API se utilizan para entrenar modelos. Eso importa, pero no responde si los prompts o los resultados se almacenan para la supervisión de abusos, el estado de la aplicación, las características del producto, el soporte, los análisis o la facturación.
Los controles de datos de la plataforma de OpenAI distinguen entre el entrenamiento de modelos, la retención para la supervisión de abusos y la retención del estado de la aplicación. La misma documentación dice que los logs de supervisión de abusos pueden incluir prompts y respuestas y se retienen hasta 30 días por defecto, mientras que los clientes elegibles pueden solicitar controles como la Supervisión de Abusos Modificada o la Retención Cero de Datos. También enumera excepciones específicas de los puntos finales, incluido el estado de la aplicación almacenado para algunas API y el comportamiento específico de la función para archivos, conversaciones, vídeos, almacenamiento en caché, búsqueda web, contenedores alojados y otras capacidades.
La documentación sobre retención de datos de la API de Anthropic enmarca la Retención Cero de Datos como que los datos del cliente no se almacenan en reposo después de que se devuelve la respuesta de la API, con excepciones para requisitos legales, prevención de uso indebido y almacenamiento específico de la función. También señala que la elegibilidad de la función puede diferir según la capacidad de la API.
La documentación de ZDR de la API para desarrolladores de Gemini de Google dice que los prompts y las respuestas de los Servicios de Pago no se utilizan para mejorar los productos de Google, al tiempo que describe un registro limitado de prompts y respuestas para la supervisión de abusos y el almacenamiento específico de funciones para ciertas capacidades. La página convierte a ZDR en una revisión de la configuración y la selección de funciones, no en una suposición universal.
La lección para el comprador es práctica: conserve la evidencia de la política del proveedor, pero no permita que reemplace su propia política de retención de datos de la AI API. El proveedor puede retener una cosa, el gateway puede retener otra y su pila de observabilidad puede copiar ambas.
Los prompts y los resultados necesitan sus propias reglas
Los prompts y los resultados son los registros de mayor riesgo en una checklist de retención de datos de la AI API porque a menudo contienen la evidencia de depuración más útil y los datos comerciales más sensibles.
Trate la retención de prompts y resultados como un flujo de trabajo de excepción:
- Por defecto, no almacene la carga útil sin procesar para las rutas de producción, a menos que una carga de trabajo específica lo necesite.
- Permita el almacenamiento de la carga útil redactada solo después de que las pruebas demuestren que el enmascaramiento funciona en prompts, resultados, resultados de herramientas, fragmentos de recuperación, errores y eventos de streaming.
- Permita el almacenamiento completo de la carga útil solo para un incidente específico, una prueba de staging, un flujo de trabajo aprobado por el cliente o una escalación al proveedor.
- Establezca la caducidad antes de la recopilación para que la ventana de depuración no se convierta en almacenamiento permanente.
- Registre el acceso a los logs de la carga útil porque el visor de logs se convierte en un sistema sensible.
- Conserve el resumen del incidente depurado después de que la carga útil caduque, no el prompt o el resultado sin procesar.
La OWASP Logging Cheat Sheet es útil aquí porque trata los valores sensibles en los logs como un problema de diseño, no como un problema de formato. Los secretos, los tokens de acceso, los datos personales sensibles, los datos de pago, las cadenas de conexión, las claves de cifrado y los datos de alta clasificación generalmente deben eliminarse, enmascararse, desinfectarse, hashearse o cifrarse antes de registrarse. Los prompts de IA pueden contener todas esas categorías.
Para los patrones de redacción, los documentos de las herramientas apuntan en la misma dirección. El enmascaramiento de Langfuse puede redactar datos antes de que los datos de seguimiento salgan de la aplicación. Helicone Omit Logs está diseñado para mantener métricas operativas mientras se omiten los cuerpos de solicitud y respuesta. Los controles de registro de solicitudes de Portkey separan el contenido de la solicitud/respuesta del registro orientado a métricas. Incluso si utiliza una pila diferente, el patrón es el mismo: redactar u omitir antes del almacenamiento y la exportación.
Los logs de solicitudes deben priorizar los metadatos
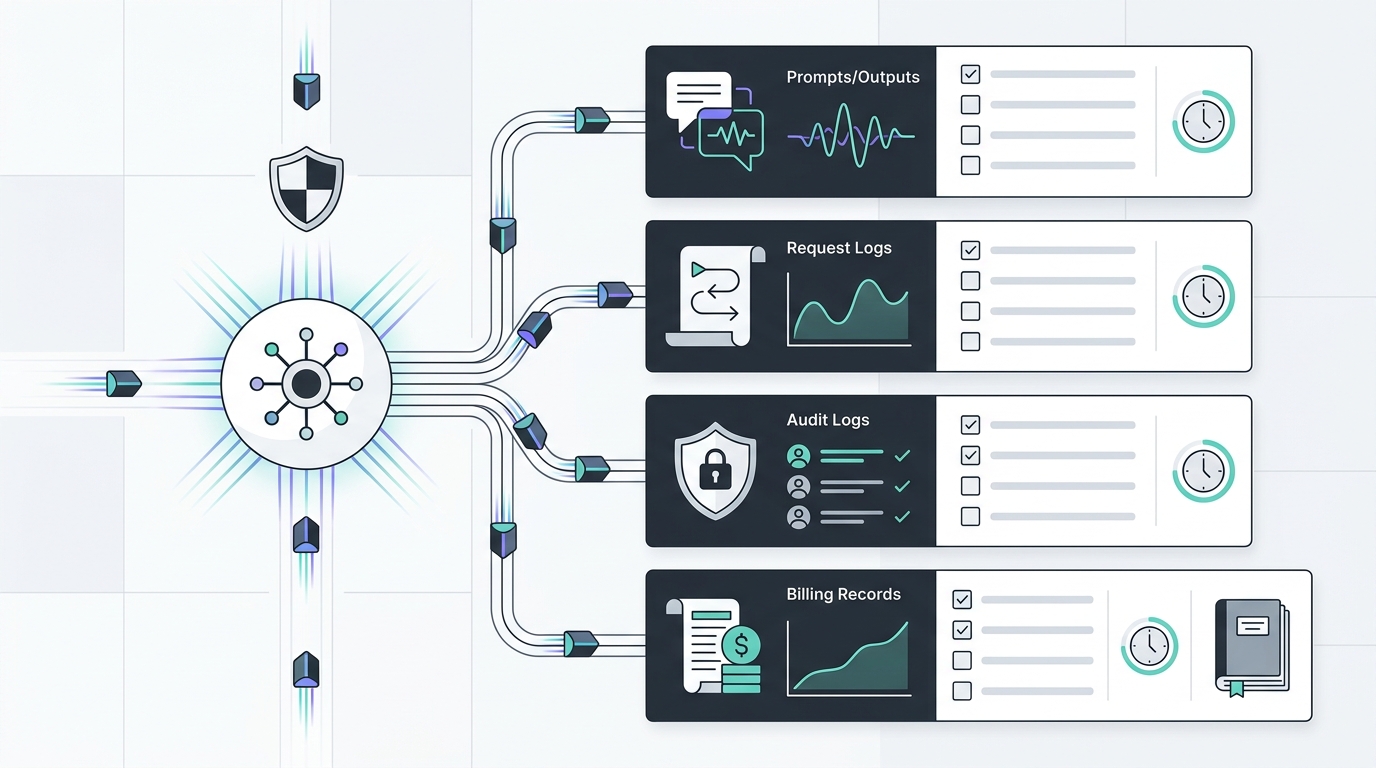
Los logs de solicitudes suelen ser el caballo de batalla de las operaciones de la AI API. No necesitan contener prompts sin procesar para ser útiles.
Para la mayoría de las rutas de producción, un evento que priorice los metadatos es suficiente:
{
"request_id": "req_01jz4...",
"timestamp": "2026-07-04T04:00:00Z",
"environment": "production",
"owner_key_id": "support_summarizer_prod",
"route": "support-summary",
"endpoint_family": "chat_completions",
"requested_model": "approved-summary-route",
"served_provider": "selected_by_gateway",
"prompt_tokens": 1840,
"output_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"retention_class": "ops_metadata_90d"
}
Ese evento permite la revisión de la facturación, la correlación de incidentes, la revisión del enrutamiento, la revisión de los SLO, la investigación de abusos y el contracargo al propietario sin retener el cuerpo del prompt o el cuerpo de la respuesta.
El registro de Cloudflare AI Gateway muestra por qué las decisiones sobre los logs de solicitudes deben ser explícitas. Los logs del gateway pueden incluir el proveedor, el modelo, el estado, el uso de tokens, el costo, la duración, los prompts, las respuestas y las acciones de la política, y los controles por solicitud pueden afectar si se almacenan los cuerpos de la solicitud y la respuesta. Una checklist de retención debe capturar tanto la configuración predeterminada del gateway como cualquier ruta de anulación por solicitud.
Utilice esta checklist para los logs de solicitudes:
| Grupo de campos | ¿Conservar por defecto? | Notas |
|---|---|---|
| ID de solicitud, ID de seguimiento, marca de tiempo | Sí | Necesario para soporte y revisión de incidentes |
| Clave, proyecto, ruta, entorno | Sí | Use ID internos estables; evite secretos sin procesar |
| Proveedor, modelo, familia de endpoints | Sí | Necesario para el enrutamiento y la evidencia del proveedor |
| Estado, clase de error, motivo de reintento/fallback | Sí | Necesario para la revisión de la fiabilidad |
| Recuentos de tokens, latencia, costo | Sí | Necesario para finanzas y detección de anomalías |
| Resultado de seguridad/DLP/política | Generalmente | Almacene los metadatos de la decisión, no el texto coincidente sensible a menos que se requiera |
| Cuerpo del prompt | No por defecto | Escalar a través del flujo de trabajo de depuración |
| Cuerpo del resultado | No por defecto | Escalar a través del flujo de trabajo de depuración |
| Entradas y salidas de la herramienta | No por defecto | A menudo contiene datos privados del sistema |
| Fragmentos y archivos de recuperación | No por defecto | A menudo contiene documentos, contratos o datos de clientes |
Aquí es donde la retención de datos de la AI API se vuelve operativa en lugar de teórica: los ingenieros siguen obteniendo los registros que necesitan, mientras que los responsables de la privacidad y la seguridad pueden ver lo que se omite intencionadamente.
Los logs de auditoría no son logs de carga útil
Los logs de auditoría responden quién cambió algo, cuándo cambió y si la ruta de control funcionó. Generalmente, deben sobrevivir más tiempo que las cargas útiles de depuración, pero no deben convertirse en un almacén de cargas útiles por la puerta de atrás.
Una checklist de retención de datos para AI API debería incluir eventos de auditoría para:
- Creación, rotación, desactivación y eliminación de claves de API.
- Cambios en el espacio de trabajo, proyecto, ruta, proveedor y política de modelo.
- Cambios en la cuota, el presupuesto y el control de facturación.
- Habilitación, desactivación y aprobación de excepciones del registro de payloads.
- Eventos de acceso a logs y exportaciones sensibles.
- Cambios de rol de administrador y concesiones de permisos.
- Eventos de exportación de datos, eliminación y escalado a soporte.
Los logs de auditoría deben nombrar el actor, el objetivo, la acción, la marca de tiempo, el sistema de origen, la referencia de aprobación y el estado antes/después. Deben evitar almacenar prompts sin procesar, resultados sin procesar, claves de API sin procesar, tokens de portador, datos de tarjetas de pago y datos de clientes sin redactar.
Conecte este artículo con la guía de Flatkey sobre logs de auditoría para el uso de AI API cuando el departamento de adquisiciones necesite un modelo de eventos duradero para las operaciones del gateway. El log de auditoría debe demostrar que se aplicó una política de retención; no necesita conservar el payload sensible que activó la política.
Los registros de facturación tienen diferentes necesidades de retención
Los registros de facturación son fáciles de pasar por alto en una checklist de retención de datos para AI API porque no se parecen a los datos de los prompts. Sin embargo, siguen siendo importantes.
Los registros de facturación y finanzas pueden incluir:
- ID de clave de API, espacio de trabajo, equipo, proyecto, cliente o entorno.
- Modelo, proveedor, familia de endpoints y ruta.
- Tokens de prompt, tokens de resultado, tokens en caché, unidades de imagen/video, duración o recuento de solicitudes.
- Precio unitario, precio efectivo, margen, créditos, impuestos, línea de factura, registro de recarga, reembolso y movimiento de saldo.
- Marca de tiempo, período de facturación, ID de factura, ID de proveedor de pago y referencia del libro mayor.
Estos registros generalmente necesitan sobrevivir más tiempo que los payloads de depuración porque los equipos de finanzas, impuestos, soporte al cliente y adquisiciones necesitan evidencia de conciliación. Aun así, necesitan minimización. Un libro mayor de facturación no debería necesitar prompts o resultados sin procesar para demostrar el gasto.
Utilice esta tabla de retención de facturación:
| Artefacto de facturación | Propietario típico | Pregunta de retención | ¿Se necesita payload? |
|---|---|---|---|
| Fila de uso | Operaciones financieras y plataforma | ¿Durante cuánto tiempo necesitamos evidencia de contracargos? | No |
| Factura | Finanzas | ¿Qué reglas fiscales, de auditoría y de contrato con el cliente se aplican? | No |
| Recarga o movimiento de saldo prepago | Finanzas | ¿Puede el equipo conciliar los cambios de saldo con el uso? | No |
| Instantánea de precios | Adquisiciones y finanzas | ¿Qué precio unitario estaba activo cuando se ejecutó la solicitud? | No |
| Registro de disputa del cliente | Soporte y finanzas | ¿Qué evidencia saneada explica el cargo? | Generalmente no |
| Factura del proveedor | Finanzas y adquisiciones | ¿Se puede vincular el gasto ascendente con el uso interno? | No |
La página de precios actual de Flatkey describe precios de modelo transparentes, uso de pago por uso, límites de cuota, análisis de uso, controles de costos y rutas de revisión de facturación. Trate esas afirmaciones como declaraciones públicas útiles, luego verifique el dashboard en vivo, los términos de la cuenta, las facturas y las exportaciones para su propio registro de comprador.
Cree un archivo de evidencia propiedad del comprador
Las páginas de confianza son útiles, pero el artefacto duradero debe ser propiedad del comprador. Un revisor dentro de seis meses debería poder ver qué se verificó en la fecha de aprobación y qué cambió después.
Cree una carpeta o un registro de gobernanza con esta estructura:
| Elemento de evidencia | Qué capturar | Desencadenante de renovación |
|---|---|---|
| Mapa de flujo de datos | Ruta de la solicitud desde la aplicación al gateway, proveedor, observabilidad, facturación, soporte y exportaciones | Nuevo proveedor, herramienta, ruta o exportador |
| Configuración del proveedor | Capturas de pantalla o lecturas de API para retención, entrenamiento, ZDR/MAM, región y comportamiento del estado de la aplicación | Cambio en el contrato o en las características del proveedor |
| Configuración del gateway | Registro de solicitudes, registro de payloads, redacción, eliminación, política de ruta y controles de exportación | Lanzamiento o cambio de configuración del gateway |
| Log de metadatos de muestra | Evento saneado similar a producción sin el cuerpo del payload | Nueva familia de endpoints o ruta |
| Prueba de redacción | Resultados de pruebas para prompts, resultados, datos de herramientas, fragmentos de recuperación y fragmentos de stream | Nuevo SDK, modelo, herramienta o exportador |
| Registro de excepción de payload | Quién aprobó el registro completo de payloads, por qué, alcance, vencimiento y evidencia de purga | Cada incidente |
| Muestra de evento de auditoría | Eventos de clave, ruta, cuota, rol, registro, exportación y eliminación | Cambio de rol o de flujo de trabajo de administrador |
| Muestra de facturación | Fila de uso, instantánea de precios, evidencia de factura/recarga y mapeo de propietarios | Cambio en los precios o en el flujo de trabajo de facturación |
| Revisión de acceso | Quién puede ver logs, bóvedas de payloads, exportaciones, facturas y tickets de soporte | Trimestralmente o por cambio de rol |
| Prueba de eliminación | Prueba de que los logs, payloads, exportaciones y tickets pueden expirar o ser purgados | Cambio en la política de retención o en el proceso de eliminación del cliente |
Este archivo de evidencia convierte la retención de datos de AI API de una afirmación del proveedor en un proceso de revisión repetible. También facilita las renovaciones porque el revisor puede comparar el estado actual con el estado anterior en lugar de empezar de nuevo desde el texto de marketing.
Establezca clases de retención antes del lanzamiento
No permita que cada sistema invente su propio período de retención. Defina clases de retención y asigne cada registro a una de ellas.
retention_classes:
ops_metadata_90d:
stores_payload: false
records:
- request_id
- route
- provider
- model
- status
- latency
- token_usage
- cost
access: engineering_ops_finance_security
debug_payload_72h:
stores_payload: true
approval_required: true
redaction_required: true
expiration_required_before_collection: true
access: named_incident_responders
audit_control_1y:
stores_payload: false
records:
- actor
- action
- target
- before_after_state
- approval_reference
access: security_procurement_admins
finance_ledger_contract_term:
stores_payload: false
records:
- usage
- pricing_snapshot
- invoice
- recharge
- balance_movement
access: finance_procurement
Los periodos exactos deben provenir de sus contratos, política de seguridad, requisitos fiscales y compromisos con los clientes. La parte importante es que la clase exista antes de que comience el tráfico y que el almacenamiento de la carga útil (payload) sea visible como una propiedad separada.
Cómo encaja esto con Flatkey
Flatkey puede soportar el modelo operativo porque la superficie pública del producto se centra en una única puerta de enlace API, enrutamiento de modelos, visibilidad de uso, facturación, controles de cuota y revisión operativa. La comprobación de la API de precios en tiempo real del 4 de julio de 2026 devolvió success=true, 45 filas de modelos, 48 registros de proveedores, versión de precios a42d372ccf0b5dd13ecf71203521f9d2, y rutas de endpoint compatibles que incluyen /v1/chat/completions, /v1/messages, generateContent de Gemini, generación de imágenes y endpoints de video.
Utilice Flatkey como la superficie de evidencia de la puerta de enlace, luego verifique los detalles específicos de la cuenta que las páginas públicas no pueden probar:
- Qué metadatos de solicitud almacena Flatkey.
- Si se almacenan los cuerpos de los prompts y las respuestas en bruto.
- Si el almacenamiento de la carga útil (payload) se puede deshabilitar, limitar en alcance, redactar o limitar en el tiempo.
- Qué eventos de auditoría están disponibles para claves, rutas, cuotas, facturación y acceso a los logs.
- Qué exportaciones de facturación están disponibles para la conciliación financiera.
- Qué configuraciones de retención del proveedor se aplican detrás de cada ruta.
- Qué rutas de soporte, exportación y observabilidad pueden copiar los datos de la solicitud.
Esta distinción es importante. Una puerta de enlace puede simplificar las operaciones y la recopilación de evidencia, pero el comprador sigue siendo el propietario de la checklist final de retención de datos de la AI API.
Ejecute una prueba de retención de preproducción
Antes de aprobar una ruta de producción, ejecute la checklist con una carga de trabajo de prueba.
- Envíe una solicitud normal y confirme que el log de metadatos aparece sin el cuerpo del prompt o del resultado.
- Envíe una solicitud que contenga datos de prueba sensibles predefinidos, como correos electrónicos, cadenas con formato de token de acceso, ID de cuenta, valores similares a pagos y marcadores de código propietario.
- Confirme que esos datos de prueba no aparecen en logs, trazas, alertas, exportaciones de soporte o registros de facturación, a menos que la ruta haya entrado explícitamente en un carril de depuración aprobado.
- Habilite una excepción de carga útil (payload) de depuración con alcance limitado en un entorno de no producción y verifique la aprobación, el registro de acceso, la redacción y la expiración.
- Purgue o espere a que finalice el período de retención de depuración y confirme que la relectura ya no devuelve la carga útil (payload).
- Extraiga un evento de auditoría para el cambio de la política de registro y la purga.
- Extraiga una fila de facturación o de uso y confirme que se concilia sin el contenido de la carga útil (payload).
- Registre capturas de pantalla, relecturas de la API, marcas de tiempo, ID de cuenta y nombres de los revisores en el archivo de evidencia.
Esta prueba detecta el fallo común: un equipo deshabilita el almacenamiento de la carga útil (payload) en la puerta de enlace pero sigue filtrando el texto del prompt a través de un exportador de trazas, un mensaje de alerta, un ticket de soporte o una captura de pantalla de depuración.
Dónde se sitúa esto en la revisión de confianza
La retención de datos de la AI API es una parte de una revisión más amplia de la puerta de enlace. Utilice la checklist para la puerta de enlace de IA API empresarial para cubrir el acceso, el enrutamiento, la facturación, las cuotas y la propiedad operativa. Utilice la evaluación de riesgos de proveedores de AI API para comparar los contratos de los proveedores ascendentes y los procesadores de terceros. Utilice la guía de logs de auditoría para el uso de la AI API cuando el departamento de adquisiciones pregunte cómo una puerta de enlace demuestra quién cambió las claves, las rutas, las cuotas y la política de registro.
Esas revisiones deben estar conectadas. La checklist de la puerta de enlace muestra la superficie de control. La evaluación de riesgos del proveedor muestra el contrato ascendente y el límite de los datos. La guía de logs de auditoría muestra evidencia administrativa duradera. Esta checklist de retención de datos de la AI API muestra lo que queda después de cada solicitud.
Preguntas frecuentes
¿Qué es la retención de datos de la AI API?
La retención de datos de la AI API es la política y el comportamiento del sistema que determina durante cuánto tiempo se almacenan los prompts, los resultados, los logs de metadatos, los eventos de auditoría, las trazas, las filas de facturación, los registros de soporte y los registros del lado del proveedor después de una solicitud a la AI API.
¿Es lo mismo retención de datos cero que no tener logs?
No. La retención de datos cero generalmente describe un control específico de un proveedor o una característica para el contenido del cliente. Es posible que no cubra los metadatos de la puerta de enlace, los logs de auditoría, los registros de facturación, las exportaciones de observabilidad, los tickets de soporte o todas las características del proveedor. Verifique siempre el alcance y las excepciones.
¿Deberían almacenarse los prompts y los resultados para la depuración?
Solo como excepción. Los logs de metadatos deberían ser el valor predeterminado para el tráfico de producción. Almacene las cargas útiles (payloads) redactadas o completas solo para flujos de trabajo aprobados, incidentes con alcance limitado, pruebas de ensayo o carriles aprobados por el cliente, y establezca la expiración antes de la recopilación.
¿Durante cuánto tiempo deben conservarse los logs de solicitudes de la AI API?
No hay un período universal. Los logs de metadatos a menudo necesitan tiempo suficiente para la revisión de incidentes, la conciliación de la facturación y la investigación de abusos. Las cargas útiles (payloads) de prompts y resultados en bruto generalmente deberían tener una retención mucho más corta que los metadatos, los logs de auditoría o los registros de facturación.
¿Qué registros de facturación son importantes para la retención de la AI API?
Conserve las filas de uso, los recuentos de tokens, los identificadores de modelo/proveedor, las instantáneas de precios, las facturas, los registros de recarga, los reembolsos y las asignaciones de propietarios como evidencia financiera. Estos registros no deberían requerir los cuerpos de los prompts o resultados en bruto.
¿Qué debería preguntar el departamento de adquisiciones a un proveedor de gateway?
Solicite evidencia fechada de los metadatos de las solicitudes, el comportamiento de almacenamiento de la carga útil, la redacción, la eliminación, los registros de auditoría, los controles de acceso, las exportaciones de facturación, la configuración de retención del proveedor y los destinos de exportación de terceros. Luego, compare esa evidencia con su propia política de clasificación de datos y de respuesta a incidentes.
Conclusión
Una checklist de retención de datos para AI API convierte las vagas afirmaciones de confianza en un archivo operativo revisable. Separe los prompts de los resultados, los registros de solicitudes de los registros de auditoría y los registros de facturación de las cargas útiles de depuración. Conserve los metadatos por defecto, almacene las cargas útiles en bruto solo como excepción, pruebe la redacción antes del almacenamiento y conserve la evidencia fechada para las renovaciones. Cuando esté listo para centralizar el acceso, el uso, la facturación y el enrutamiento del modelo a través de una única superficie de gateway, revise el actual catálogo de precios y modelos de Flatkey y, a continuación, obtenga una clave.