Une checklist de rétention des données pour les API d'IA devrait répondre à une question simple avant le début du trafic de production : quels enregistrements existeront après un appel de modèle, qui peut les lire, combien de temps ils sont conservés et quelles preuves un acheteur peut examiner plus tard ?
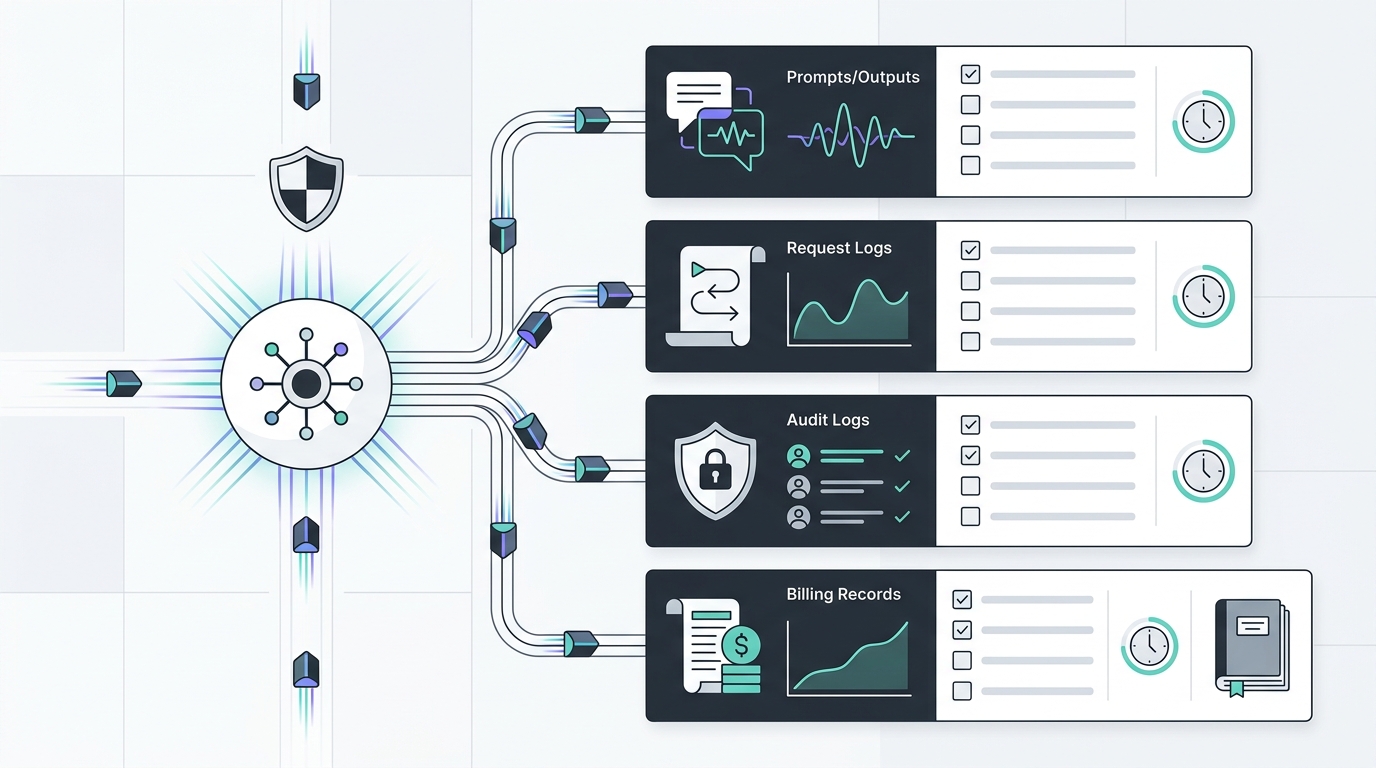
Cette question devient rapidement complexe. Une seule requête d'IA peut créer des enregistrements de prompts, des enregistrements de résultats, des logs de requêtes de passerelle, des logs de surveillance des abus du fournisseur, des événements d'audit, des traces, des entrées de cache, des lignes de facturation, des tickets de support, des exportations, des captures d'écran et des notes d'incident. Certains enregistrements aident l'ingénierie à déboguer les pannes. D'autres aident la finance à rapprocher les dépenses. D'autres encore aident les achats à prouver qu'un paramètre de fournisseur a été examiné. Certains ne devraient pas exister du tout pour les charges de travail sensibles.
Utilisez cette checklist de rétention des données pour les API d'IA pour séparer ces enregistrements avant de router les données réelles des clients via une passerelle. L'objectif n'est pas de conserver aveuglément moins d'enregistrements. L'objectif est de conserver les bonnes preuves pour les opérations, la sécurité, la finance et les achats sans transformer chaque prompt et chaque résultat en un magasin de données à longue durée de vie.
Pour les acheteurs de Flatkey, cet examen doit figurer dans le dossier d'approbation de la passerelle. Le site public actuel de Flatkey’s positionne le produit comme une passerelle d'API d'IA et une plateforme d'opérations de modèles pour l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. Cela en fait un endroit naturel pour centraliser les preuves concernant la route, le modèle, le propriétaire, l'utilisation et le coût. Cela ne supprime pas la nécessité de vérifier la rétention spécifique au compte, les contrats des fournisseurs et le comportement de stockage des charges utiles avant l'approbation.
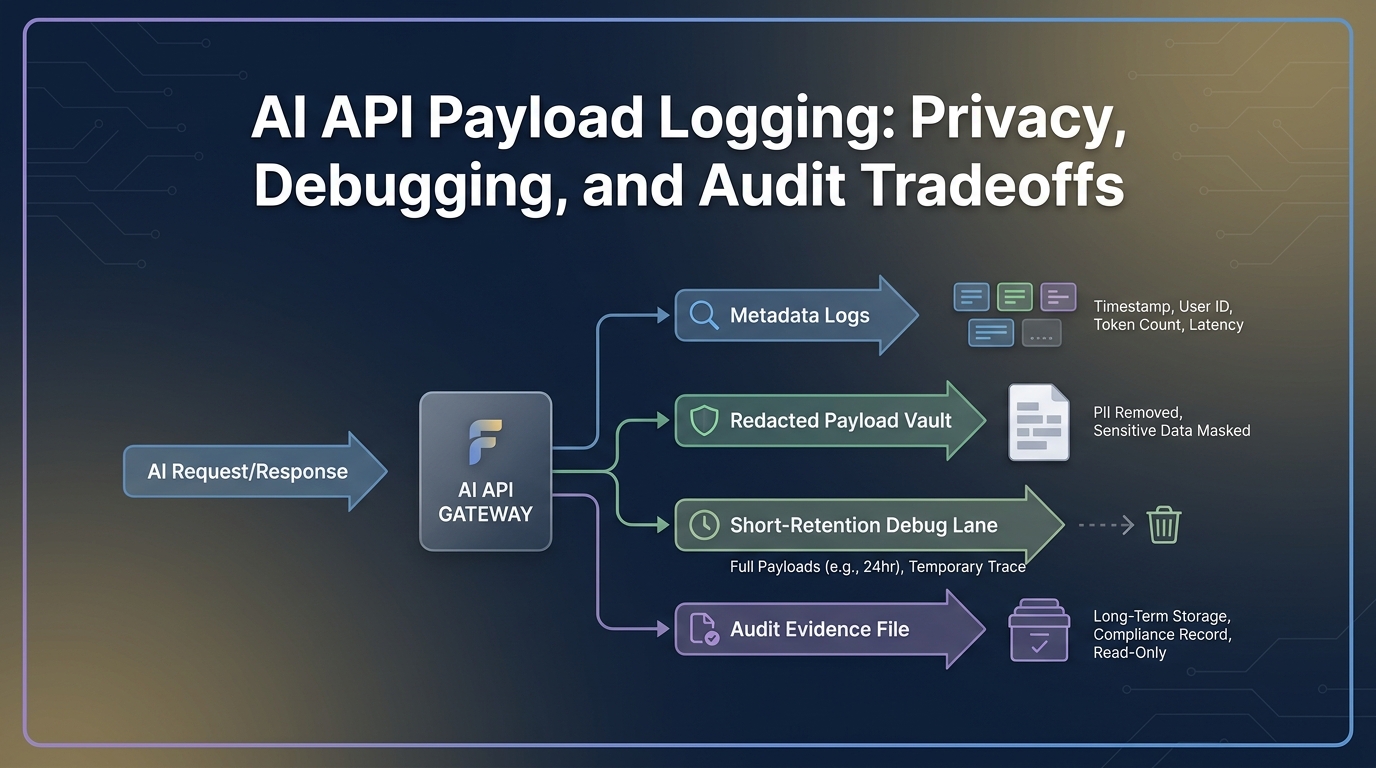
Checklist de rétention des données pour les API d'IA
Commencez par la classe d'enregistrement, pas par le slogan du fournisseur. La « rétention zéro donnée » pour une fonctionnalité d'un fournisseur ne décrit pas automatiquement vos logs de passerelle, vos traces d'observabilité, votre grand livre de facturation, vos exportations ou votre flux de travail de support.
| Surface de rétention | Quoi décider | Preuves à conserver | Posture par défaut |
|---|---|---|---|
| Prompts | Savoir si les messages bruts de l'utilisateur/système/développeur, le contexte récupéré, les fichiers et les entrées d'outils sont stockés | Diagramme de flux de données, paramètre de charge utile, test de rédaction, test de suppression | Ne pas stocker les prompts bruts par défaut |
| Résultats | Savoir si les réponses du modèle, les arguments d'appel d'outils, les fichiers générés et les morceaux diffusés en continu sont stockés | Politique de journalisation des résultats, paramètre de rétention, test d'accès | Ne pas stocker les résultats bruts par défaut |
| Logs de requêtes | Quels champs de métadonnées sont conservés pour le débogage et les opérations | Exemple d'événement de log, dictionnaire de champs, période de rétention | Stocker les métadonnées sans les corps des charges utiles |
| Logs d'audit | Quels événements administratifs et de politique sont suffisamment immuables pour être examinés | Log des changements de rôle, log des événements clés, log des changements de politique de routage | Stocker plus longtemps que les charges utiles de débogage |
| Enregistrements de facturation | Quels enregistrements d'utilisation, de coût, de facture, de recharge, de taxe et de rétrofacturation survivent | Exemple de facture, exportation de l'utilisation, champs de rapprochement | Stocker selon les besoins de la finance et du contrat |
| Enregistrements du fournisseur | Ce que les fournisseurs de modèles en amont conservent pour la surveillance des abus, l'état de l'application, la mise en cache et le stockage des fonctionnalités | Documents du fournisseur, termes du contrat, captures d'écran du compte | Vérifier par fournisseur, point de terminaison et compte |
| Exportations d'observabilité | Quelles traces, alertes, tableaux de bord, tickets et entrepôts reçoivent des copies | Liste des destinations, configuration de masquage, exemple d'exportation | Minimiser et rédiger avant l'exportation |
| Enregistrements de support | Savoir si les notes d'incident incluent des extraits de prompts/résultats | Flux de travail du support, rétention des tickets, règle de rédaction | Stocker des preuves assainies, pas des charges utiles brutes |
Ceci est la checklist de base pour la rétention des données des API d'IA : définir chaque classe d'enregistrement, assigner un propriétaire de la rétention, prouver le paramètre avec une relecture datée, et définir un déclencheur de renouvellement pour chaque endroit où les données peuvent être copiées.
Séparer la rétention de l'entraînement
La politique d'entraînement du fournisseur n'est qu'une ligne dans l'examen. Les équipes d'approvisionnement demandent souvent si les données de l'API sont utilisées pour entraîner les modèles. C'est important, mais cela ne répond pas à la question de savoir si les prompts ou les résultats sont stockés pour la surveillance des abus, l'état de l'application, les fonctionnalités du produit, le support, l'analyse ou la facturation.
Les contrôles des données de la plateforme d'OpenAI distinguent l'entraînement des modèles, la rétention pour la surveillance des abus et la rétention de l'état de l'application. La même documentation indique que les logs de surveillance des abus peuvent inclure des prompts et des réponses et sont conservés jusqu'à 30 jours par défaut, tandis que les clients éligibles peuvent demander des contrôles tels que la Surveillance Modifiée des Abus (Modified Abuse Monitoring) ou la Rétention Zéro Donnée (Zero Data Retention). Elle énumère également des exceptions spécifiques aux points de terminaison, y compris l'état de l'application stocké pour certaines API et le comportement spécifique aux fonctionnalités pour les fichiers, les conversations, les vidéos, la mise en cache, la recherche web, les conteneurs hébergés et d'autres capacités.
La documentation sur la rétention des données de l'API d'Anthropic définit la Rétention Zéro Donnée (Zero Data Retention) comme le fait que les données client ne sont pas stockées au repos après le retour de la réponse de l'API, avec des exceptions pour les exigences légales, la prévention des abus et le stockage spécifique à certaines fonctionnalités. Elle note également que l'éligibilité des fonctionnalités peut différer selon la capacité de l'API.
La documentation ZDR de l'API développeur Gemini de Google indique que les prompts et les réponses des Services Payants ne sont pas utilisés pour améliorer les produits de Google, tout en décrivant une journalisation limitée des prompts et des réponses pour la surveillance des abus et un stockage spécifique aux fonctionnalités pour certaines capacités. La page fait de la ZDR un examen de la configuration et de la sélection des fonctionnalités, et non une supposition universelle.
La leçon pour l'acheteur est pratique : conservez les preuves de la politique du fournisseur, mais ne la laissez pas remplacer votre propre politique de rétention des données de l'API d'IA. Le fournisseur peut conserver une chose, la passerelle peut en conserver une autre, et votre pile d'observabilité peut copier les deux.
Les prompts et les résultats nécessitent leurs propres règles
Les prompts et les résultats sont les enregistrements les plus à risque dans une checklist de rétention des données pour les API d'IA, car ils contiennent souvent les preuves de débogage les plus utiles et les données commerciales les plus sensibles.
Traitez la rétention des prompts et des résultats comme un workflow d'exception :
- Par défaut, ne stockez pas les charges utiles brutes pour les routes de production, sauf si une charge de travail spécifique l'exige.
- N'autorisez le stockage des charges utiles expurgées qu'après que des tests aient prouvé que le masquage fonctionne sur les prompts, les résultats, les résultats d'outils, les fragments de récupération, les erreurs et les événements de streaming.
- N'autorisez le stockage complet des charges utiles que pour un incident nommé, un test de pré-production, un workflow approuvé par le client ou une escalade auprès du fournisseur.
- Définissez l'expiration avant la collecte afin que la fenêtre de débogage ne puisse pas devenir un stockage permanent.
- Journalisez l'accès aux logs de charge utile, car le visualiseur de logs devient un système sensible.
- Conservez le résumé de l'incident nettoyé après l'expiration de la charge utile, et non le prompt ou le résultat brut.
La OWASP Logging Cheat Sheet est utile ici, car elle traite les valeurs sensibles dans les logs comme un problème de conception, et non comme un problème de formatage. Les secrets, les jetons d'accès, les données personnelles sensibles, les données de paiement, les chaînes de connexion, les clés de chiffrement et les données hautement classifiées devraient généralement être supprimés, masqués, nettoyés, hachés ou chiffrés avant d'être journalisés. Les prompts d'IA peuvent contenir toutes ces catégories.
Pour les modèles de rédaction, la documentation des outils va dans le même sens. Le masquage Langfuse peut expurger les données avant que les données de trace ne quittent l'application. Helicone Omit Logs est conçu pour conserver les métriques opérationnelles tout en omettant les corps des requêtes et des réponses. Les contrôles de journalisation des requêtes de Portkey séparent le contenu des requêtes/réponses de la journalisation axée sur les métriques. Même si vous utilisez une pile différente, le modèle est le même : expurger ou omettre avant le stockage et l'exportation.
Les logs de requête doivent privilégier les métadonnées
Les logs de requête sont généralement l'outil principal des opérations des API d'IA. Ils n'ont pas besoin de contenir les prompts bruts pour être utiles.
Pour la plupart des routes de production, un événement axé sur les métadonnées est suffisant :
{
"request_id": "req_01jz4...",
"timestamp": "2026-07-04T04:00:00Z",
"environment": "production",
"owner_key_id": "support_summarizer_prod",
"route": "support-summary",
"endpoint_family": "chat_completions",
"requested_model": "approved-summary-route",
"served_provider": "selected_by_gateway",
"prompt_tokens": 1840,
"output_tokens": 312,
"status": "success",
"latency_ms": 1420,
"cost_usd": "0.0042",
"payload_storage": "none",
"retention_class": "ops_metadata_90d"
}
Cet événement prend en charge l'examen de la facturation, la corrélation des incidents, l'examen du routage, l'examen des SLO, les enquêtes sur les abus et la refacturation au propriétaire sans conserver le corps du prompt ou de la réponse.
La journalisation de la passerelle IA de Cloudflare montre pourquoi les décisions concernant les logs de requête doivent être explicites. Les logs de la passerelle peuvent inclure le fournisseur, le modèle, le statut, l'utilisation des jetons, le coût, la durée, les prompts, les réponses et les actions de politique, et les contrôles par requête peuvent affecter le stockage des corps des requêtes et des réponses. Une checklist de rétention doit capturer à la fois le paramètre par défaut de la passerelle et tout chemin de dérogation par requête.
Utilisez cette checklist pour les logs de requête :
| Groupe de champs | Conserver par défaut ? | Remarques |
|---|---|---|
| ID de requête, ID de trace, horodatage | Oui | Nécessaire pour le support et l'examen des incidents |
| Clé, projet, route, environnement | Oui | Utilisez des ID internes stables ; évitez les secrets bruts |
| Fournisseur, modèle, famille de points de terminaison | Oui | Nécessaire pour le routage et les preuves du fournisseur |
| Statut, classe d'erreur, raison de la nouvelle tentative/du repli | Oui | Nécessaire pour l'examen de la fiabilité |
| Nombre de jetons, latence, coût | Oui | Nécessaire pour la finance et la détection d'anomalies |
| Résultat de sécurité/DLP/politique | Généralement | Stockez les métadonnées de décision, pas le texte sensible correspondant, sauf si requis |
| Corps du prompt | Non par défaut | Escalader via le workflow de débogage |
| Corps du résultat | Non par défaut | Escalader via le workflow de débogage |
| Entrées et sorties de l'outil | Non par défaut | Contient souvent des données système privées |
| Fragments et fichiers de récupération | Non par défaut | Contient souvent des documents, des contrats ou des données client |
C'est là que la rétention des données des API d'IA devient opérationnelle plutôt que théorique : les ingénieurs obtiennent toujours les enregistrements dont ils ont besoin, tandis que les responsables de la confidentialité et de la sécurité peuvent voir ce qui est intentionnellement omis.
Les logs d'audit ne sont pas des logs de charge utile
Les logs d'audit répondent à la question de savoir qui a changé quelque chose, quand cela a changé et si le chemin de contrôle a fonctionné. Ils devraient généralement survivre plus longtemps que les charges utiles de débogage, mais ils ne doivent pas devenir un magasin de charges utiles dérobé.
Une checklist de rétention des données pour les API d'IA devrait inclure des événements d'audit pour :
- La création, la rotation, la désactivation et la suppression des clés d'API.
- Les modifications d'espaces de travail, de projets, de routes, de fournisseurs et de politiques de modèles.
- Les modifications de quotas, de budgets et de contrôles de facturation.
- L'activation, la désactivation de la journalisation des charges utiles et les approbations d'exceptions.
- Les événements d'accès aux logs et exportations sensibles.
- Les changements de rôles d'administrateur et les attributions d'autorisations.
- Les événements d'exportation, de suppression de données et de remontée au support.
Les logs d'audit devraient nommer l'acteur, la cible, l'action, l'horodatage, le système source, la référence d'approbation et l'état avant/après. Ils devraient éviter de stocker les prompts bruts, les résultats bruts, les clés d'API brutes, les jetons de porteur, les données de carte de paiement et les données client non expurgées.
Associez cet article au guide de Flatkey sur les logs d'audit pour l'utilisation des API d'IA lorsque le service des achats a besoin d'un modèle d'événement durable pour les opérations de la passerelle. Le log d'audit doit prouver qu'une politique de rétention a été appliquée ; il n'a pas besoin de conserver la charge utile sensible qui a déclenché la politique.
Les enregistrements de facturation ont des besoins de rétention différents
Les enregistrements de facturation sont faciles à négliger dans une checklist de rétention des données pour les API d'IA car ils ne ressemblent pas à des données de prompt. Ils restent néanmoins importants.
Les enregistrements de facturation et financiers peuvent inclure :
- Les identifiants de clé d'API, d'espace de travail, d'équipe, de projet, de client ou d'environnement.
- Le modèle, le fournisseur, la famille de points de terminaison et la route.
- Les jetons de prompt, les jetons de résultat, les jetons mis en cache, les unités d'image/vidéo, la durée ou le nombre de requêtes.
- Le prix unitaire, le prix effectif, la marge, les crédits, les taxes, la ligne de facture, l'enregistrement de recharge, le remboursement et le mouvement de solde.
- L'horodatage, la période de facturation, l'identifiant de facture, l'identifiant du fournisseur de paiement et la référence du grand livre.
Ces enregistrements doivent généralement survivre plus longtemps que les charges utiles de débogage car les équipes financières, fiscales, de support client et d'approvisionnement ont besoin de preuves de rapprochement. Ils nécessitent tout de même une minimisation. Un grand livre de facturation ne devrait pas avoir besoin de prompts ou de résultats bruts pour prouver les dépenses.
Utilisez ce tableau de rétention pour la facturation :
| Artefact de facturation | Propriétaire typique | Question de rétention | Charge utile nécessaire ? |
|---|---|---|---|
| Ligne d'utilisation | Opérations financières et plateforme | Pendant combien de temps avons-nous besoin de preuves de rétrofacturation ? | Non |
| Facture | Finances | Quelles règles fiscales, d'audit et de contrat client s'appliquent ? | Non |
| Recharge ou mouvement de solde prépayé | Finances | L'équipe peut-elle rapprocher les changements de solde avec l'utilisation ? | Non |
| Instantané des tarifs | Approvisionnement et finances | Quel prix unitaire était actif lorsque la requête a été exécutée ? | Non |
| Dossier de litige client | Support et finances | Quelle preuve expurgée explique la facturation ? | Généralement non |
| Facture du fournisseur | Finances et approvisionnement | Les dépenses en amont peuvent-elles être liées à l'utilisation interne ? | Non |
La page de tarification actuelle de Flatkey décrit la tarification transparente des modèles, l'utilisation avec paiement à l'usage, les limites de quota, les analyses d'utilisation, les contrôles des coûts et les processus de révision de la facturation. Considérez ces informations comme des affirmations publiques utiles pour une première évaluation, puis vérifiez le tableau de bord en direct, les conditions du compte, les factures et les exportations pour votre propre dossier d'acheteur.
Constituez un dossier de preuves appartenant à l'acheteur
Les pages de confiance sont utiles, mais l'artefact durable doit appartenir à l'acheteur. Un examinateur dans six mois devrait pouvoir voir ce qui a été vérifié à la date d'approbation et ce qui a changé par la suite.
Créez un dossier ou un enregistrement de gouvernance avec cette structure :
| Élément de preuve | Quoi capturer | Déclencheur de renouvellement |
|---|---|---|
| Cartographie du flux de données | Chemin de la requête de l'application à la passerelle, au fournisseur, à l'observabilité, à la facturation, au support et aux exportations | Nouveau fournisseur, outil, route ou exportateur |
| Paramètres du fournisseur | Captures d'écran ou lectures d'API pour la rétention, la formation, ZDR/MAM, la région et le comportement de l'état de l'application | Contrat du fournisseur ou changement de fonctionnalité |
| Paramètres de la passerelle | Journalisation des requêtes, journalisation des charges utiles, expurgation, suppression, politique de routage et contrôles d'exportation | Version de la passerelle ou changement de configuration |
| Exemple de log de métadonnées | Événement de type production expurgé sans le corps de la charge utile | Nouvelle famille de points de terminaison ou route |
| Test d'expurgation | Résultats des tests pour les prompts, les résultats, les données d'outils, les fragments de récupération et les fragments de flux | Nouveau SDK, modèle, outil ou exportateur |
| Enregistrement d'exception de charge utile | Qui a approuvé la journalisation complète de la charge utile, pourquoi, la portée, l'expiration et la preuve de purge | Chaque incident |
| Exemple d'événement d'audit | Événements de clé, route, quota, rôle, journalisation, exportation et suppression | Changement de rôle ou de flux de travail administrateur |
| Exemple de facturation | Ligne d'utilisation, instantané des tarifs, preuve de facture/recharge et mappage des propriétaires | Changement de tarification ou de flux de travail de facturation |
| Revue d'accès | Qui peut voir les logs, les coffres-forts de charges utiles, les exportations, les factures et les tickets de support | Trimestriellement ou lors d'un changement de rôle |
| Test de suppression | Preuve que les logs, les charges utiles, les exportations et les tickets peuvent expirer ou être purgés | Changement de la politique de rétention ou du processus de suppression client |
Ce dossier de preuves transforme la rétention des données des API d'IA d'une simple affirmation du fournisseur en un processus de révision reproductible. Il facilite également les renouvellements car l'examinateur peut comparer l'état actuel avec l'état précédent au lieu de repartir de zéro à partir des documents marketing.
Définissez des classes de rétention avant le lancement
Ne laissez pas chaque système inventer sa propre période de rétention. Définissez des classes de rétention et associez chaque enregistrement à l'une d'entre elles.
retention_classes:
ops_metadata_90d:
stores_payload: false
records:
- request_id
- route
- provider
- model
- status
- latency
- token_usage
- cost
access: engineering_ops_finance_security
debug_payload_72h:
stores_payload: true
approval_required: true
redaction_required: true
expiration_required_before_collection: true
access: named_incident_responders
audit_control_1y:
stores_payload: false
records:
- actor
- action
- target
- before_after_state
- approval_reference
access: security_procurement_admins
finance_ledger_contract_term:
stores_payload: false
records:
- usage
- pricing_snapshot
- invoice
- recharge
- balance_movement
access: finance_procurement
Les périodes exactes doivent provenir de vos contrats, de votre politique de sécurité, de vos exigences fiscales et des engagements de vos clients. L'important est que la classe existe avant le début du trafic et que le stockage de la charge utile (payload) soit visible en tant que propriété distincte.
Comment cela s'intègre avec Flatkey
Flatkey peut prendre en charge le modèle d'exploitation car la surface publique du produit est centrée sur une passerelle API unique, le routage des modèles, la visibilité de l'utilisation, la facturation, les contrôles de quotas et la révision opérationnelle. La vérification de l'API de tarification en direct du 4 juillet 2026 a renvoyé success=true, 45 lignes de modèles, 48 enregistrements de fournisseurs, la version de tarification a42d372ccf0b5dd13ecf71203521f9d2, et a pris en charge les chemins de point de terminaison, y compris /v1/chat/completions, /v1/messages, Gemini generateContent, la génération d'images et les points de terminaison vidéo.
Utilisez Flatkey comme surface de preuve de la passerelle, puis vérifiez les détails spécifiques au compte que les pages publiques ne peuvent pas prouver :
- Quelles métadonnées de requête Flatkey stocke.
- Si les corps bruts des prompts et des réponses sont stockés.
- Si le stockage de la charge utile (payload) peut être désactivé, limité, expurgé ou limité dans le temps.
- Quels événements d'audit sont disponibles pour les clés, les routes, les quotas, la facturation et l'accès aux logs.
- Quelles exportations de facturation sont disponibles pour le rapprochement financier.
- Quels paramètres de rétention des fournisseurs s'appliquent derrière chaque route.
- Quels chemins de support, d'exportation et d'observabilité peuvent copier les données de requête.
Cette distinction est importante. Une passerelle peut simplifier les opérations et la collecte de preuves, mais l'acheteur reste propriétaire de la checklist finale de rétention des données de l'API d'IA.
Effectuer un test de rétention en pré-production
Avant d'approuver une route de production, exécutez la checklist sur une charge de travail de test.
- Envoyez une requête normale et confirmez que le log de métadonnées apparaît sans le corps du prompt ou du résultat.
- Envoyez une requête contenant des données de test sensibles prédéfinies telles que des e-mails, des chaînes de caractères en forme de jeton d'accès, des ID de compte, des valeurs de type paiement et des marqueurs de code propriétaire.
- Confirmez que ces données de test n'apparaissent pas dans les logs, les traces, les alertes, les exportations de support ou les enregistrements de facturation, à moins que la route n'ait explicitement emprunté une voie de débogage approuvée.
- Activez une exception de charge utile (payload) de débogage à portée limitée dans un environnement de non-production et vérifiez l'approbation, la journalisation des accès, l'expurgation et l'expiration.
- Purgez ou attendez la fin de la période de rétention de débogage et confirmez que la relecture ne renvoie plus la charge utile (payload).
- Extrayez un événement d'audit pour le changement de politique de journalisation et la purge.
- Extrayez une ligne de facturation ou d'utilisation et confirmez qu'elle correspond sans le contenu de la charge utile (payload).
- Enregistrez les captures d'écran, les relectures d'API, les horodatages, les ID de compte et les noms des examinateurs dans le fichier de preuves.
Ce test détecte l'échec courant : une équipe désactive le stockage de la charge utile (payload) dans la passerelle mais laisse tout de même fuiter le texte du prompt via un exportateur de traces, un message d'alerte, un ticket de support ou une capture d'écran de débogage.
Où cela se situe dans l'évaluation de la confiance
La rétention des données de l'API d'IA est une partie d'une évaluation plus large de la passerelle. Utilisez la checklist pour les passerelles API d'IA d'entreprise pour couvrir l'accès, le routage, la facturation, les quotas et la propriété opérationnelle. Utilisez l'évaluation des risques des fournisseurs d'API d'IA pour comparer les contrats des fournisseurs en amont et les sous-traitants tiers. Utilisez le guide sur les logs d'audit pour l'utilisation de l'API d'IA lorsque le service des achats demande comment une passerelle prouve qui a modifié les clés, les routes, les quotas et la politique de journalisation.
Ces évaluations doivent être liées. La checklist de la passerelle montre la surface de contrôle. L'évaluation des risques du fournisseur montre le contrat en amont et la frontière des données. Le guide des logs d'audit montre les preuves administratives durables. Cette checklist de rétention des données de l'API d'IA montre ce qui reste après chaque requête.
FAQ
Qu'est-ce que la rétention des données de l'API d'IA ?
La rétention des données de l'API d'IA est la politique et le comportement du système qui déterminent combien de temps les prompts, les résultats, les logs de métadonnées, les événements d'audit, les traces, les lignes de facturation, les enregistrements de support et les enregistrements côté fournisseur sont stockés après une requête à l'API d'IA.
La rétention nulle des données est-elle la même chose que l'absence de logs ?
Non. La rétention nulle des données décrit généralement un contrôle spécifique à un fournisseur ou à une fonctionnalité pour le contenu client. Elle peut ne pas couvrir les métadonnées de la passerelle, les logs d'audit, les enregistrements de facturation, les exportations d'observabilité, les tickets de support ou toutes les fonctionnalités du fournisseur. Vérifiez toujours la portée et les exceptions.
Les prompts et les résultats doivent-ils être stockés pour le débogage ?
Seulement à titre exceptionnel. Les logs de métadonnées devraient être la norme pour le trafic de production. Ne stockez les charges utiles (payloads) expurgées ou complètes que pour les flux de travail approuvés, les incidents à portée limitée, les tests de pré-production ou les voies approuvées par le client, et définissez une expiration avant la collecte.
Combien de temps les logs de requêtes de l'API d'IA doivent-ils être conservés ?
Il n'y a pas de période universelle. Les logs de métadonnées nécessitent souvent suffisamment de temps pour l'examen des incidents, le rapprochement de la facturation et les enquêtes sur les abus. Les charges utiles (payloads) brutes des prompts et des résultats devraient généralement avoir une rétention beaucoup plus courte que les métadonnées, les logs d'audit ou les enregistrements de facturation.
Quels enregistrements de facturation sont importants pour la rétention des API d'IA ?
Conservez les lignes d'utilisation, le nombre de jetons, les identifiants de modèle/fournisseur, les captures de tarification, les factures, les enregistrements de recharge, les remboursements et les mappages de propriétaires comme preuves financières. Ces enregistrements ne devraient pas nécessiter les corps bruts des prompts ou des résultats.
Que devrait demander le service des achats à un fournisseur de passerelle ?
Demandez des preuves datées des métadonnées de requête, du comportement de stockage des charges utiles, de la rédaction, de la suppression, des journaux d'audit, des contrôles d'accès, des exportations de facturation, des paramètres de rétention du fournisseur et des destinations d'exportation tierces. Comparez ensuite ces preuves avec votre propre politique de classification des données et de réponse aux incidents.
Conclusion
Une checklist de rétention des données pour les API d'IA transforme de vagues déclarations de confiance en un dossier d'exploitation vérifiable. Séparez les prompts des résultats, les journaux de requêtes des journaux d'audit et les enregistrements de facturation des charges utiles de débogage. Conservez les métadonnées par défaut, ne stockez les charges utiles brutes que par exception, testez la rédaction avant le stockage et préservez les preuves datées pour les renouvellements. Lorsque vous êtes prêt à centraliser l'accès aux modèles, l'utilisation, la facturation et le routage via une seule interface de passerelle, consultez les tarifs et le catalogue de modèles actuels de Flatkey, puis obtenez une clé.