AI API retry strategy is the policy that decides what your application should do after a model request fails, slows down, or returns a partial result. The wrong policy is expensive: retry every error and you multiply quota pressure; switch models too early and you change answer quality; queue interactive work and users wait; fail open on safety or auth failures and you hide a real incident.
This guide is a practical decision ladder for production teams using an AI gateway, multi-provider router, or OpenAI-compatible base URL. It covers when to retry the same provider, when to switch models, when to queue work, and when to fail closed. The goal of an AI API retry strategy is not to make every request succeed at any cost. The goal is to recover from transient failures without masking bad requests, auth problems, quota exhaustion, unsafe fallbacks, or routing incidents.
Flatkey fits this problem because its public product copy centers on one API key, an OpenAI-compatible base URL at https://router.flatkey.ai/v1, clear pricing, unified billing, and one dashboard for keys, usage, and routing. Flatkey also describes automatic switching and load balancing. Those features still need an explicit retry policy so teams can explain why a request retried, changed model, queued, or failed closed.
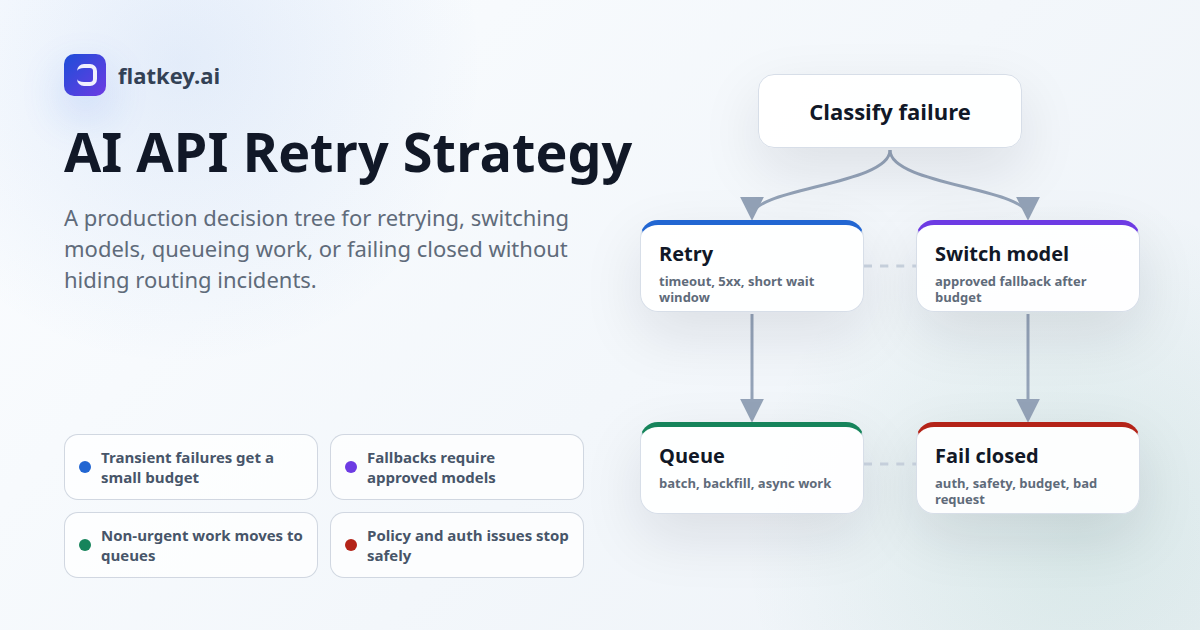
Quick Answer: The AI API Retry Strategy Ladder
Use this decision ladder as the value asset for your AI API retry strategy. It keeps retry behavior tied to the failure owner, user workflow, and blast radius instead of one broad "try again" rule.
| Failure Signal | Default Action | When To Escalate | Stop Condition |
|---|---|---|---|
| Network timeout before the provider accepted the request | Retry once with jittered backoff if the operation is idempotent or uses a client request ID. | Switch route after the retry budget is spent and the fallback target is approved for the same workflow. | Stop after the route budget; return a controlled retry-later response. |
| HTTP 429 rate limit with retry guidance | Respect the returned wait signal, slow the caller, and reduce concurrency. | Queue background work or switch to an approved route with separate quota. | Fail closed if quota is exhausted, budget is capped, or no allowed route remains. |
| HTTP 500, 502, 503, 504, or provider overload | Retry a small number of times with exponential backoff and jitter. | Switch models or providers only after confirming the fallback meets quality and policy rules. | Stop when the request would exceed latency, token, cost, or attempt limits. |
| 400 invalid request, schema error, unsupported parameter, or context overflow | Do not retry unchanged. Fix the request, shrink context, or return a user-correctable error. | Route to a model with larger context only if the product accepts the behavior and cost change. | Fail closed on repeated request-shape errors. |
| 401, 403, key disabled, IP not authorized, or permission failure | Fail closed and alert the key owner. | Rotate keys or repair account access through an operator workflow. | Never fall back silently to another account unless your security policy explicitly allows it. |
| Safety block, policy block, tool authorization failure, or data-boundary issue | Fail closed with a safe message and log the policy reason. | Escalate to review if the block appears incorrect or customer-impacting. | Do not retry on a less restricted model just to get an answer. |
| Streaming starts, then stalls or disconnects | Retry only if the operation can be replayed safely and the user experience supports a fresh response. | Switch route for future requests after logs show repeat stream-level failure. | Do not append a second model answer to a partially delivered answer unless the UI is designed for it. |
Why A Blind Retry Loop Breaks AI Products
Most web services can use a standard retry pattern for transient failures. AI APIs need more care because the request can be expensive, stateful, streamed, tool-using, and model-sensitive. A blind LLM API retries loop can create four failures of its own:
- Quota amplification: retrying 429s too aggressively can consume the very request or token capacity that is already constrained.
- Quality drift: a fallback model may answer differently, ignore a tool pattern, or change output format.
- Cost surprise: a successful fallback can be more expensive than the primary route, especially for long context, reasoning, image, or video work.
- Incident hiding: final success can hide five failed attempts unless logs preserve the retry chain.
A good AI API retry strategy is therefore a routing policy, an observability policy, and a product policy. It should say what recovery is allowed, what evidence must be logged, and what user experience is acceptable when recovery fails.
Classify The Failure Before You Retry
Start every AI API retry strategy with a normalized failure taxonomy. Provider docs differ, but the operational categories are stable enough to turn into policy:
| Class | Examples | Owner | Retry Posture |
|---|---|---|---|
| Caller defect | Malformed JSON, invalid parameter, unsupported tool schema, context too long. | Application or prompt pipeline. | Do not retry unchanged. |
| Authentication or permission | Invalid key, disabled key, project membership, IP allowlist, account permission. | Credential owner or security owner. | Fail closed and alert. |
| Rate limit | Requests per minute, tokens per minute, acceleration limits, concurrency limits. | Traffic owner and quota owner. | Back off, queue, reduce concurrency, or switch approved quota pool. |
| Quota or budget exhausted | Credits depleted, monthly spend cap, team quota, customer quota, prepaid balance limit. | Finance, plan owner, or customer owner. | Fail closed or queue behind approval; do not spend through another budget silently. |
| Transient provider failure | Internal server error, overloaded service, temporary gateway error, timeout. | Provider or network path. | Retry with a small budget, then route fallback if approved. |
| Policy or safety block | Moderation block, restricted output, data boundary, tool authorization failure. | Safety, security, or product policy. | Fail closed unless a human-approved remediation path exists. |
OpenAI's error-code guide separates 429 rate limits from quota exhaustion, documents 500 and 503 cases as retry-after-a-wait situations, and treats authentication problems as key or organization fixes rather than retry candidates. Anthropic's error docs similarly separate invalid request, authentication, permission, rate limit, API error, and overloaded categories. Those distinctions are why status code alone is not enough; your gateway should keep the provider error type and safe error code in the log.
When To Retry The Same Model
Retry the same model when the failure looks transient, the request can be replayed safely, and the retry will not make the incident worse. This is the narrowest useful part of an AI API retry strategy.
Good same-route retry candidates include:
- A connect timeout before the provider accepted the request.
- A temporary 500, 502, 503, or 504 response.
- A rate-limit response with a short wait window and enough remaining user latency budget.
- A streaming setup failure before any user-visible token was delivered.
Use jittered exponential backoff rather than synchronized sleeps. Google Cloud's retry guidance describes truncated exponential backoff with jitter as the normal retry shape because it avoids thundering-herd retries. For AI APIs, also add a small retry budget by workflow. An interactive chat request might get one or two attempts. A nightly summarization batch can wait longer and retry more carefully. A payment, safety, or customer-action workflow should be stricter.
Each same-route retry should log attempt index, route, provider request ID when available, status code, error class, wait time, and final outcome. Pair this with the AI API observability logs checklist so final success does not erase the failed attempts.
When To Switch Models Or Providers
A model fallback retry is not just another retry. It changes the model, provider, account, cost line, behavior, and sometimes compliance boundary. Switch only when the fallback is pre-approved for that exact workflow.
Switch models or providers when all of these are true:
- The primary route has exhausted its short retry budget or returned a provider-side failure.
- The fallback model is approved for the same data class, customer tier, endpoint family, tool behavior, and output format.
- The product owner accepts the quality difference and user experience.
- The finance owner accepts the cost and quota difference.
- The log records both requested route and selected route.
Do not switch when the request is malformed, unauthorized, blocked by safety policy, or tied to a provider-specific feature the fallback does not support. Vercel's AI Gateway model-fallback docs describe ordered fallback models as a way to recover from failures or unavailability. Treat that as a useful public routing pattern, but still define your own acceptance tests before using fallback in production.
For Flatkey buyers, the operational question is concrete: if one upstream route has errors, which fallback routes are allowed, how many attempts are allowed, and where can engineering see the route chain later? The AI API load balancing and failover playbook is the companion piece for designing that route ladder.
When To Queue Instead Of Retry Synchronously
Queue work when the user does not need an immediate response, when provider capacity is temporarily constrained, or when the request volume belongs in a batch workflow. A queue is not a failure; it is a way to keep the AI API retry strategy from fighting synchronous limits.
OpenAI's rate-limit guide distinguishes synchronous request limits from batch work and notes that non-immediate use cases can use batch-style execution without impacting synchronous request rate limits. The same product principle applies beyond one provider: move non-urgent work away from interactive traffic.
Good queue candidates include:
- Bulk enrichment, summarization, embedding, moderation review, or report generation.
- Customer-visible jobs that already have an async status page or webhook.
- Backfills and migrations where freshness is measured in minutes or hours.
- Retry-after windows that exceed the user's interactive latency budget but fit a job queue.
Queue records should preserve the original request owner, API key, route policy, retry count, requested model, queued-at time, next-attempt time, and budget owner. Otherwise queued retries become invisible cost.
When To Fail Closed
Fail closed when continuing would create security, compliance, data, budget, or product-risk ambiguity. This is the part of an AI API retry strategy that prevents reliability engineering from becoming silent policy bypass.
Fail closed for:
- Invalid or disabled API keys, project permission failures, IP allowlist failures, and unexpected account ownership.
- Safety blocks, moderation blocks, tool permission failures, and data-boundary errors.
- Quota or budget exhaustion where no budget owner has approved spillover.
- Malformed requests that would repeat unchanged.
- Fallback routes that have not passed quality, cost, privacy, and compliance checks.
- Streaming responses that already delivered partial content and cannot be replayed cleanly.
Failing closed does not mean returning a hostile error. It means the system returns a controlled message, records the stop reason, alerts the owner when needed, and avoids a hidden route change. This is especially important for customer-facing AI features where a silent fallback could produce a materially different answer.
A Retry Policy Template For Production Teams
Use this template to turn the ladder into a policy record. It is deliberately generic and should be adapted to your gateway, application, and compliance rules.
{
"policy_id": "chat-prod-retry-v3",
"workflow": "customer-chat",
"environment": "production",
"idempotency": {
"requires_client_request_id": true,
"allow_replay_after_stream_started": false
},
"same_route_retry": {
"retryable_status_codes": [408, 429, 500, 502, 503, 504],
"max_attempts": 2,
"backoff": "exponential_with_jitter",
"max_elapsed_ms": 9000
},
"fallback": {
"enabled": true,
"allowed_reasons": ["primary_timeout", "provider_overload", "temporary_5xx"],
"blocked_reasons": ["auth_error", "invalid_request", "safety_block", "budget_exhausted"],
"allowed_models": ["approved-backup-chat-model"],
"requires_quality_eval": true,
"requires_cost_owner": true
},
"queue": {
"enabled_for": ["bulk_summary", "nightly_enrichment"],
"not_enabled_for": ["live_customer_chat"]
},
"fail_closed": {
"auth_errors": true,
"policy_errors": true,
"unapproved_fallback": true,
"quota_without_budget_owner": true
},
"logging": {
"record_attempt_chain": true,
"record_retry_after": true,
"record_requested_and_selected_route": true,
"content_logging_mode": "metadata_only"
}
}This is not a Flatkey API contract. It is a review template for engineering, product, finance, and security teams. The most important field is not the exact JSON name; it is the explicit stop condition for each recovery path.
Flatkey Rollout Checklist
Use this checklist when testing an AI API retry strategy through Flatkey or any AI gateway:
- Start in staging: point an OpenAI-compatible client at
https://router.flatkey.ai/v1with a non-production key. - Pick one workflow: choose a chat, summarization, embedding, image, or video route rather than testing every model at once.
- Set a retry budget: define max attempts, max elapsed time, and which status or error classes are retryable.
- Define fallback eligibility: require product approval for output quality, finance approval for cost, and security approval for data class.
- Separate queue traffic: move batch jobs away from interactive user requests where possible.
- Fail closed on policy issues: do not let auth, safety, budget, or request-shape failures spill into another route silently.
- Verify logs: confirm the dashboard or exported logs show requested route, selected route, attempt chain, status, usage, cost, and owner.
- Review spend: use AI API quota management and AI API cost attribution practices so retry recovery does not become a budget surprise.
The live Flatkey pricing page published server-rendered model pricing for 638 AI models across 23 providers when checked on June 18, 2026. Treat that as dated catalog evidence only. Before production traffic, verify the exact model rows, endpoint types, pricing units, availability status, and dashboard fields for your workflow.
Common Mistakes To Avoid
- Retrying all 429s the same way: rate pressure, acceleration limits, and budget exhaustion need different actions.
- Retrying invalid requests: schema, context, and unsupported-parameter errors need request changes, not more attempts.
- Fallback without evals: a cheaper or available model is not automatically acceptable for the same customer workflow.
- Ignoring streaming state: retrying after partial output can create duplicate or conflicting answers.
- Dropping attempt logs: incident review needs the full route chain, not only final success.
- Letting retries bypass budgets: each retry is another request, another token count, and often another cost line.
FAQ
How many times should an AI API retry strategy retry a failed request?
For interactive traffic, start with one or two attempts and a strict elapsed-time budget. Background jobs can use longer backoff and more attempts. The right number depends on idempotency, user latency, provider guidance, quota, cost, and whether fallback is approved.
Should LLM API retries use the same model or a fallback model?
Retry the same model for likely transient failures. Use a fallback only after the same-route retry budget is spent and the fallback has passed quality, cost, tool, privacy, and compliance checks.
When should model fallback retry be blocked?
Block fallback for authentication failures, permission failures, invalid requests, safety or policy blocks, budget exhaustion without approval, and any workflow where a different model could change user-visible behavior beyond the product's tolerance.
What should be logged for retry and fallback incidents?
Log the parent request ID, attempt index, requested route, selected route, provider request IDs when available, status code, error class, retry-after data, latency, token usage, cost, fallback decision reason, and final outcome. Metadata-first logging is usually the right default.
Conclusion: Make Recovery Explicit
An AI API retry strategy is a production control, not a helper function. Retry transient failures with a small budget. Switch models only when the fallback is approved. Queue work that does not need a synchronous answer. Fail closed when security, safety, budget, or request shape is the real problem.
If your team wants one key, one compatible base URL, and a clearer place to review model routing, pricing, usage, and recovery behavior, get a Flatkey key and test your retry ladder in staging before production traffic.


