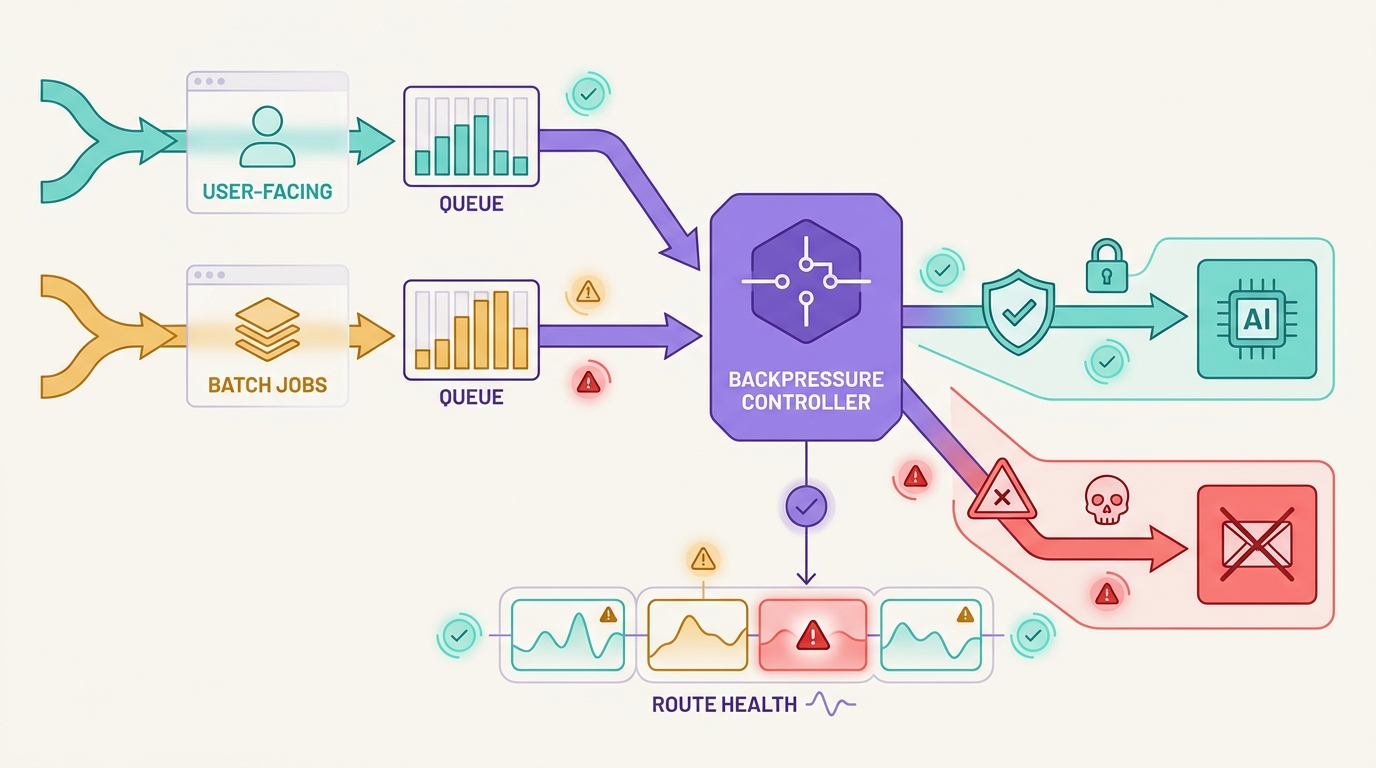
Die Fehlertaxonomie eines LLM-Gateways macht den Unterschied zwischen einem kontrollierten Vorfall und einem teuren Sturm von Wiederholungsversuchen aus. Ein Gateway sollte nicht jeden fehlgeschlagenen Modellaufruf als dieselbe Art von Provider-Fehler behandeln. Ungültige Anmeldeinformationen, erschöpfte Kontingente, Überlastung des Providers, fehlerhafte Anfragen, Sicherheitsverweigerungen, Zeitüberschreitungen und Client-Abbrüche erfordern alle unterschiedliche Wiederherstellungspfade.
Der häufigste Fehler besteht darin, jeden Fehlschlag in dieselbe Wiederholungs- und Fallback-Schleife zu senden. Das kann einen widerrufenen Schlüssel verbergen, ein Ausgabenlimit sprengen, unsichere Inhalte an einen anderen Provider weiterleiten oder Arbeit duplizieren, nachdem eine Streaming-Antwort bereits begonnen hat. Eine praktische LLM-Gateway-Fehlertaxonomie gibt den Teams aus Technik, Produkt und Finanzen eine gemeinsame Sprache dafür, was passiert ist und was das Gateway als Nächstes tun sollte.
Flatkey passt zu diesem Betriebsmodell, da seine aktuelle öffentliche Website das Produkt als eine einzige Gateway-Oberfläche für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und Betriebskontrollen positioniert. Nutzen Sie diese gemeinsame Oberfläche, um Fehler zu klassifizieren, bevor Sie sich für ein Wiederholungs-, Warteschlangen-, Fallback- oder Fail-Closed-Verhalten entscheiden.
LLM-Gateway-Fehlertaxonomie in einer Tabelle
Beginnen Sie mit der Klasse, nicht nur mit dem HTTP-Status. Dieselbe Statusfamilie kann bei verschiedenen Anbietern, SDKs und Endpunktformen unterschiedliche Bedeutungen haben.
| Fehlerklasse | Häufige Signale | Wiederholen? | Fallback? | Aktion des Eigentümers |
|---|---|---|---|---|
| Authentifizierung und Berechtigung | 401, 403, ungültiger Schlüssel, widerrufener Schlüssel, falsches Projekt, IP nicht autorisiert, Berechtigung verweigert |
Keine automatische Wiederholung | Nein | Anmeldeinformationen, Projekt, Allowlist oder Berechtigungen rotieren oder reparieren |
| Kontingent und Ratenlimit | 429, Ratenlimit, Kontingent erschöpft, Ausgabenlimit, Token-/Anfragelimit, RESOURCE_EXHAUSTED |
Manchmal, mit begrenztem Backoff oder Queuing | Nur innerhalb genehmigter Kosten- und Qualitätsregeln | Parallelität reduzieren, Nutzung prüfen, Limits erhöhen oder Ausgaben stoppen |
| Provider und Transport | 500, 503, 529, Überlastung, Zeitüberschreitung, Verbindungszurücksetzung, SDK-Verbindungsfehler |
Manchmal, wenn idempotent und innerhalb der Frist | Manchmal, vor Teilausgabe und innerhalb des Vertrags | Provider-Status, Routen-Zustand, Zeitüberschreitungsbudgets und Wiederholungsverstärkung prüfen |
| Anfrage und Validierung | 400, 422, fehlerhaftes JSON, ungültiges Modell, nicht unterstützter Parameter, Kontext zu lang |
Nein, es sei denn, die Anfrage wird geändert | Selten | Schema, Prompt-Größe, Endpunktform oder Modellfähigkeit korrigieren |
| Sicherheit und Richtlinie | Verweigerung, Moderationssperre, Prompt-Sperre, finishReason: SAFETY, Inhaltsrichtlinienfehler |
Keine automatische Wiederholung | Kein Umgehungs-Fallback | Eine sichere Benutzernachricht anzeigen, Sicherheitskontext protokollieren, gegebenenfalls um überarbeitete Eingabe bitten |
| Client-Abbruch und Frist | Benutzerabbruch, Client-Zeitüberschreitung, Server-Frist, getrennter Stream | Keine blinde Wiederholung | Nur wenn keine Ausgabe oder Nebenwirkung festgeschrieben wurde | Arbeit stoppen, Abbruch markieren, Zustand der Teilausgabe beibehalten |
Diese LLM-Gateway-Fehlertaxonomie ist bewusst handlungsorientiert. Sie kennzeichnet nicht nur Fehler für Dashboards. Sie entscheidet, wann das System mehr Token ausgeben darf, wann es einen Eigentümer bitten muss, einen Zustand zu korrigieren, und wann es anhalten sollte.
Klassifizieren vor dem Wiederholen
Offizielle Provider-Dokumentationen unterstützen die Trennung dieser Klassen. Der Fehlerleitfaden von OpenAI unterscheidet zwischen ungültiger Authentifizierung, falschen API-Schlüsseln, Fehlern bei der IP-Allowlist, Ratenlimits, Erschöpfung von Kontingenten oder Abrechnungen, Serverfehlern, Überlastung, SDK-Verbindungsfehlern, SDK-Zeitüberschreitungen, fehlerhaften Anfragen, Berechtigungsverweigerungen und Ausnahmen bei Ratenlimits. Seine Anleitung zu Ratenlimits empfiehlt einen zufälligen exponentiellen Backoff, weist aber auch darauf hin, dass fehlgeschlagene Anfragen weiterhin zu den Limits pro Minute zählen.
Die Fehlerdokumentation von Anthropic trennt invalid_request_error, authentication_error, permission_error, not_found_error, request_too_large, rate_limit_error, api_error und overloaded_error. Anthropic dokumentiert auch 429-Ratenlimits mit retry-after-Anleitung, und seine Anleitung zu Stop-Gründen enthält refusal als Stop-Bedingung auf Modellebene.
Die Fehlerbehebung für Gemini bildet Authentifizierungs- und Berechtigungsfehler getrennt von 429 RESOURCE_EXHAUSTED, 500 internen Fehlern und 503 Nichtverfügbarkeit ab. Die Dokumentation zu den Ratenlimits von Gemini beschreibt Dimensionen für Anfragen, Token, tägliche Anfragen und Ausgaben. Die Sicherheitseinstellungen von Gemini legen auch Prompt-Sperren, Kandidaten-finishReason und safetyRatings offen, einschließlich eines finishReason von SAFETY, wenn Antwortinhalte blockiert werden.
Diese Erkenntnis führt zu einer einfachen Regel: Eine Fehlertaxonomie für LLM-Gateways sollte anbieterspezifische Signale in Entscheidungsfelder normalisieren, bevor das Gateway eine Aktion auswählt.
Authentifizierungs- und Berechtigungsfehler
Authentifizierungs- und Berechtigungsfehler sollten sofort gestoppt werden. Ein erneuter Versuch mit einem ungültigen Schlüssel oder für ein verbotenes Projekt erzeugt in der Regel nur Rauschen, ohne das Ergebnis zu ändern.
Normalisieren Sie diese Signale in die Authentifizierungsklasse:
| Signal | Wahrscheinliche Bedeutung | Gateway-Verhalten |
|---|---|---|
401 ungültige Authentifizierung |
Schlüssel ist falsch, abgelaufen, widerrufen, fehlerhaft formatiert oder vom falschen Projekt | Nicht erneut versuchen; Schlüsselbesitzer benachrichtigen |
401 Problem mit der Organisations- oder Projektmitgliedschaft |
Aufrufer ist nicht in der erforderlichen Organisation oder dem erforderlichen Projekt | Nicht erneut versuchen; an den Kontoinhaber weiterleiten |
401 oder 403 IP-Allowlist- oder Berechtigungsproblem |
Anfrage kam aus dem falschen Netzwerk oder es fehlt der Endpunktzugriff | Nicht erneut versuchen; Berechtigungsnachweis anzeigen |
Anbieter-authentication_error oder permission_error |
Anbieterspezifische Authentifizierungs- oder Zugriffsverweigerung | Kein Fallback; Anmeldeinformationen oder Berechtigung korrigieren |
In einem Gateway sollten Authentifizierungsfehler owner_key, credential_id, project_id, provider, endpoint_family, requested_model und route_id enthalten. Vermeiden Sie das Protokollieren von rohen Geheimnissen. Der Vorfall sollte beantworten, welcher Schlüssel fehlgeschlagen ist, welche Route den Aufruf versucht hat und wer das Problem beheben kann.
Ein Fallback ist bei Authentifizierungsfehlern in der Regel falsch. Wenn ein Team einen Anbieter nicht genehmigt hat, kann ein stillschweigender Wechsel zu einem anderen Anbieter Beschaffungs-, Datengrenzen- oder Modellrichtlinien umgehen. Die kontrollierte Reaktion ist ein klarer Fehler, eine Benachrichtigung des Besitzers und ein Behebungspfad.
Quoten- und Ratenbegrenzungsfehler
Quoten- und Ratenbegrenzungsfehler sind die Klasse, die am häufigsten durch vage Wiederholungslogik beeinträchtigt wird. Ein 429 kann Burst-Pacing, Anfragen-pro-Minute-Limits, Token-pro-Minute-Limits, tägliche Anfragelimits, monatliche Budgeterschöpfung, Erschöpfung von Prepaid-Guthaben oder ausgabenbasierte Limits bedeuten. Diese Fälle haben keinen gemeinsamen Wiederherstellungspfad.
Verwenden Sie diese LLM-Gateway-Fehlertaxonomie für Quotenentscheidungen:
| Quotensignal | Wiederholungspfad | Warteschlangenpfad | Stopp-Pfad |
|---|---|---|---|
429 mit Retry-After |
Respektieren Sie den Header, wenn er zur Workflow-Frist passt | Nicht-interaktive Jobs bis zur Wiederholungszeit in die Warteschlange stellen | Stoppen, wenn die Wartezeit die Frist überschreitet |
| 429 ohne Wartehinweis | Verwenden Sie einen begrenzten Jittered Backoff für ein kleines Versuchsbudget | Reduzieren Sie die Gleichzeitigkeit für den Besitzer, die Route oder die Endpunktfamilie | Stoppen, wenn wiederholte Versuche die Nutzung pro Minute erhöhen |
| Token-Limit-Dimension | Reduzieren Sie Prompt, Ausgabe, Batch-Größe oder Gleichzeitigkeit | Große Jobs in die Warteschlange stellen und mit kleineren Batches wiederholen | Stoppen, wenn die Anfrage nicht zum Modell- oder Kontextvertrag passt |
| Ausgaben- oder Guthabenerschöpfung | Nicht automatisch erneut versuchen | Nur in die Warteschlange stellen, wenn der Finanzverantwortliche eine Aufladung oder Budgeterhöhung genehmigt hat | Fail-Closed und Kostennachweis aufbewahren |
| Tages-/Projektquote erschöpft | Keine kurzschleifigen Wiederholungen | Batch-Jobs nur bei Erlaubnis bis zum Zurücksetzen verzögern | Fail-Closed für benutzerseitige Anfragen |
Der Schlüssel liegt darin, zwischen vorübergehender Drosselung und erschöpftem Budget zu unterscheiden. Backoff hilft, wenn der Anbieter Sie auffordert, langsamer zu werden. Backoff hilft nicht, wenn das Konto kein Guthaben hat oder der Job nicht in das verfügbare Token-Budget passt.
Kombinieren Sie diesen Abschnitt mit der KI-API-Wiederholungsstrategie von Flatkey, wenn Sie eine detailliertere Checkliste für Wiederholungsversuche benötigen. Halten Sie Wiederholungsversuche in den Protokollen sichtbar, damit Finanz- und Betriebsabteilungen doppelte Token-Ausgaben sehen können.
Anbieter- und Transportfehler
Anbieter- und Transportfehler unterscheiden sich von Quotenfehlern. Sie bedeuten, dass die Anfrage gültig sein kann, der Schlüssel gültig sein kann und das Budget verfügbar sein kann, aber die Route den Aufruf nicht abschließen konnte.
Häufige Signale sind:
| Signal | Bedeutung | Gateway-Entscheidung |
|---|---|---|
500 oder Anbieter-api_error |
Anbieterseitiger interner Fehler | Kurz erneut versuchen, wenn idempotent; bei Wiederholung Status prüfen |
503 nicht verfügbar oder überlastet |
Anbieterkapazität, Wartung oder Ausfallzustand | Backoff oder Fallback vor Teilausgabe |
Anthropic overloaded_error oder HTTP 529 |
Anbieterspezifische Überlastung | Als Anbieterkapazität behandeln, nicht als Kundenquote |
| SDK-Verbindungsfehler | Netzwerk-, Proxy-, TLS-, DNS- oder Firewall-Pfad fehlgeschlagen | Nur erneut versuchen, wenn der Transportpfad wahrscheinlich vorübergehend ist |
| SDK-Timeout | Anfrage hat ein Timeout-Budget überschritten | Nur erneut versuchen, wenn Workflow-Frist und Idempotenz es zulassen |
| Streaming-Verbindungsabbruch | Teilausgabe kann bereits vorhanden sein | Wiederaufnahme nur mit expliziter Stream-Richtlinie |
Ein Anbieter-Fallback kann hier nützlich sein, erfordert aber einen Vertrag. Die Fallback-Route muss die Endpunktform, Werkzeuge, Anforderungen an strukturierte Ausgaben, das Kontextfenster, die Datengrenze, die Modellgenehmigung und die Kostenobergrenze beibehalten. Wenn das Streaming bereits sichtbare Token ausgegeben hat, ist das sicherere Verhalten oft, anzuhalten und einen kontrollierten Fehler anzuzeigen, anstatt die Ausgabe von einer anderen Route zusammenzufügen.
Nutzen Sie die Zuverlässigkeit von Streaming-KI-APIs für die Streaming-spezifische Wiederherstellung und die Evaluierung von Modell-Fallbacks, bevor Sie Provider-Fehler in automatische Routenänderungen umwandeln.
Anfrage- und Validierungsfehler
Anfrage- und Validierungsfehler sind in der Regel keine Provider-Vorfälle. Sie bedeuten, dass der Aufrufer etwas gesendet hat, das der Endpunkt nicht verarbeiten kann.
Beispiele hierfür sind fehlende Pflichtfelder, fehlerhaftes JSON, nicht unterstützte Parameter, falsche Endpunktfamilie, ungültige Modell-ID, zu langer Kontext, nicht unterstütztes Tool-Schema, inkompatible Modalität oder Datei-/Bild-/Video-Eingaben, die nicht dem Endpunktvertrag entsprechen.
Das Gateway sollte diese Felder protokollieren:
| Feld | Warum es wichtig ist |
|---|---|
endpoint_family |
Trennt OpenAI-kompatible Chat-, Antwort-, Nachrichten-, Gemini-, Bild- und Videoformate |
requested_model |
Identifiziert ungültige oder nicht unterstützte Modellnamen |
request_schema_version |
Zeigt an, ob Client und Gateway nicht übereinstimmen |
parameter_name |
Weist Entwickler auf das fehlerhafte Feld hin |
input_token_estimate |
Trennt fehlerhafte Eingaben von Kontextüberläufen |
client_sdk und sdk_version |
Findet Migrations- und Kompatibilitätsprobleme |
Versuchen Sie es bei unveränderten Validierungsfehlern nicht erneut. Transformieren Sie entweder die Anfrage in ein gültiges Format oder geben Sie einen für Entwickler bestimmten Fehler zurück, der das zu behebende Feld benennt. Wenn ein Gateway mehrere Endpunktfamilien unterstützt, sind Validierungsfehler besonders wichtig, da eine Anfrage für einen Provider gültig und für einen anderen ungültig sein kann.
Sicherheits- und Richtlinienfehler
Sicherheits- und Richtlinienfehler benötigen eine eigene Klasse, da Wiederholungsversuche und Fallbacks versehentlich Schutzmaßnahmen schwächen können. Eine Sicherheitsverweigerung ist keine Ausfallzeit des Providers. Eine Moderationssperre ist keine Quotenerschöpfung. Eine blockierte Ausgabe ist kein Grund, so lange weiter zu samplen, bis das Gateway eine Route findet, die den verbotenen Inhalt ausgibt.
Normalisieren Sie diese Signale in die Sicherheitsklasse:
| Signal | Nachweis im Provider-Stil | Gateway-Verhalten |
|---|---|---|
| Modellverweigerung | Strukturierte Ausgaben von OpenAI legen Verweigerungen offen; Anthropic-Stoppgründe umfassen refusal |
Präsentieren Sie eine sichere Antwort und umgehen Sie sie nicht mit einem Fallback |
| Moderationssperre | Die OpenAI-Sicherheitsdokumentation empfiehlt Moderation; Bildfehler können moderation_blocked aufdecken |
Protokollieren Sie den sicheren Kategoriekontext und fordern Sie gegebenenfalls eine überarbeitete Eingabe an |
| Prompt-Sperre | Gemini-Sicherheitseinstellungen legen promptFeedback.blockReason offen |
Geben Sie eine kontrollierte Nachricht zurück, bevor Sie nachgelagerte Arbeiten senden |
| Ausgabesperre | Gemini kann finishReason: SAFETY und Sicherheitsbewertungen zurückgeben; blockierte Inhalte werden nicht zurückgegeben |
Nicht blind wiederholen; protokollieren, dass die Ausgabe blockiert wurde |
| Richtlinien- oder Compliance-Regel | Anwendungsspezifische Richtlinie, Beschaffung, Datengrenze, Alter oder regulierte Workflow-Regel | Bei Fehler schließen oder zur manuellen Überprüfung weiterleiten |
Die praktische Regel ist einfach: Eine LLM-Gateway-Fehlertaxonomie sollte Sicherheit niemals als einen behebbaren Provider-Ausfall behandeln. Ein Fallback ist nur dann akzeptabel, wenn die Fallback-Route die gleiche oder eine strengere Sicherheitsrichtlinie beibehält und das Ziel darin besteht, eine sichere Version der Aufgabe abzuschließen, nicht aber, die Sperre zu umgehen.
Der normalisierte Fehlerdatensatz
Eine nützliche LLM-Gateway-Fehlertaxonomie wandelt providerspezifische Fehler in einen einzigen, dauerhaften Datensatz um.
| Normalisiertes Feld | Beispielwerte | Verwendung |
|---|---|---|
error_class |
auth, quota, provider, request, safety, cancelled |
Steuert die Gruppierung von Runbooks und Dashboards |
http_status |
401, 403, 429, 500, 503, 529 |
Behält das Protokollsignal bei |
provider_error_type |
rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, moderation_blocked |
Behält die anbieterspezifische Bedeutung bei |
provider_error_code |
insufficient_quota, invalid_api_key, SAFETY |
Unterstützt exakte Verzweigungen |
retry_after_ms |
Vom Header abgeleitete Verzögerung oder null | Verhindert geratenes Wiederholungs-Timing |
retryable |
true oder false |
Trennt die Code-Richtlinie von der UI-Formulierung |
fallback_allowed |
true oder false |
Setzt den Routenvertrag durch |
fail_closed_reason |
quota_exhausted, safety_block, contract_mismatch |
Erklärt, warum das Gateway angehalten hat |
requested_model und served_model |
Modell-IDs oder Aliase | Zeigt an, ob das Routing das Verhalten geändert hat |
endpoint_family |
openai, anthropic, gemini, image-generation |
Macht Migrationsprobleme sichtbar |
partial_output_committed |
true oder false |
Verhindert doppelte, für den Benutzer sichtbare Ausgaben |
usage_units und estimated_cost |
Token, Bilder, Sekunden, Dollar | Macht die Kosten für Wiederholungsversuche sichtbar |
request_id und provider_request_id |
Gateway- und Anbieter-IDs | Unterstützt Support-Tickets und die Überprüfung von Vorfällen |
Reduzieren Sie diesen Datensatz nicht auf eine einzelne Zeichenfolge wie „LLM-Aufruf fehlgeschlagen“. Diese Zeichenfolge reicht nicht aus, um zu entscheiden, ob ein Schlüssel rotiert, gewartet, neu geladen, ein Fallback durchgeführt, ein Prompt überarbeitet oder angehalten werden soll.
Ein einfacher TypeScript-Klassifikator
Der Klassifikator muss nicht vom ersten Tag an jedes Anbieterdetail kennen. Beginnen Sie mit expliziten Buckets und einem Standardwert, der konservativ fehlschlägt.
type ErrorClass =
| "auth"
| "quota"
| "provider"
| "request"
| "safety"
| "cancelled"
| "unknown";
type GatewayErrorInput = {
httpStatus?: number;
providerErrorType?: string;
providerErrorCode?: string;
finishReason?: string;
stopReason?: string;
clientCancelled?: boolean;
timeout?: boolean;
};
function classifyGatewayError(error: GatewayErrorInput): ErrorClass {
const type = (error.providerErrorType || "").toLowerCase();
const code = (error.providerErrorCode || "").toLowerCase();
const stop = (error.stopReason || "").toLowerCase();
const finish = (error.finishReason || "").toLowerCase();
if (error.clientCancelled) return "cancelled";
if (error.httpStatus === 401 || error.httpStatus === 403) return "auth";
if (type.includes("auth") || type.includes("permission")) return "auth";
if (code.includes("invalid_api_key") || code.includes("ip_not_authorized")) {
return "auth";
}
if (error.httpStatus === 429) return "quota";
if (type.includes("rate_limit") || code.includes("quota")) return "quota";
if (code.includes("resource_exhausted")) return "quota";
if (stop === "refusal" || finish === "safety") return "safety";
if (code.includes("moderation") || code.includes("blocked")) return "safety";
if (error.httpStatus === 400 || error.httpStatus === 422) return "request";
if (type.includes("invalid_request") || type.includes("bad_request")) {
return "request";
}
if (error.timeout) return "provider";
if ([500, 502, 503, 504, 529].includes(error.httpStatus || 0)) {
return "provider";
}
if (type.includes("overloaded") || type.includes("api_error")) {
return "provider";
}
return "unknown";
}
Verwenden Sie dies nur als Ausgangspunkt. Produktionsklassifikatoren sollten anbieterspezifische Zuordnungen in der Konfiguration, in Test-Fixtures und bei der Überprüfung von Vorfällen aufbewahren und nicht nur im Anwendungscode vergraben.
Runbook: Wiederholen, in die Warteschlange stellen, Fallback oder Fail-Closed
Sobald die Klasse bekannt ist, kann das Gateway die Aktion auswählen.
| Klasse | Standardaktion | Wiederholungsbedingung | Fallback-Bedingung | Fail-Closed-Bedingung |
|---|---|---|---|---|
| Auth | Anhalten und Besitzer benachrichtigen | Keine, es sei denn, es wurde gerade eine Anmeldeinformation aktualisiert | Keine | Immer, bis der Schlüssel oder die Berechtigung korrigiert ist |
| Kontingent | Backoff, Warteschlange oder Stopp nach Limit-Dimension | Temporäres Ratenlimit passt zu Frist und Versuchbudget | Genehmigte Route hält Kosten, Qualität und Datengrenzen ein | Ausgaben, Guthaben, Tageskontingent oder Frist überschritten |
| Provider | Backoff oder Umleitung bei vorübergehendem Provider-Fehler | Idempotenter Aufruf, keine Teilausgabe, Frist bleibt bestehen | Äquivalente genehmigte Route existiert | Wiederholter Fehler, Teilausgabe oder risikoreicher Workflow |
| Anfrage | Entwicklerseitigen Validierungsfehler zurückgeben | Nur nach Anfrage-Mutation | Nur wenn ein kompatibler Endpunkt/Modell explizit ausgewählt wird | Ungültiges Schema, Kontextüberlauf, nicht unterstützte Fähigkeit |
| Sicherheit | Sichere Antwort zurückgeben oder um Überarbeitung bitten | Keine bei unverändertem Inhalt | Nur mit gleicher oder strengerer Richtlinie, niemals zur Umgehung | Gesperrter Prompt/Ausgabe, Verweigerung, Compliance-Regel |
| Abgebrochen | Arbeit anhalten und Zustand beibehalten | Keine | Nur wenn der Benutzer explizit neu startet | Benutzerabbruch, Frist, getrennter Client |
Diese Tabelle ist das operative Zentrum der LLM-Gateway-Fehlertaxonomie. Sie teilt dem Gateway mit, wann weitere Arbeit sicher ist und wann weitere Arbeit zu einem Risiko wird.
Wie man dies in Flatkey anwendet
Verwenden Sie die Taxonomie als Rollout-Checkliste anstatt als einmaliges Dashboard-Projekt.
- Wählen Sie einen Workflow aus, z. B. Support-Chat, Batch-Extraktion, Evaluierungsjobs oder Code-Assistenten-Traffic.
- Definieren Sie die erlaubten Endpunktfamilien, Modelle, Fallback-Routen und Kostenobergrenzen für diesen Workflow.
- Normalisieren Sie Provider-Fehler in die oben genannten Felder.
- Machen Sie Authentifizierungs- und Berechtigungsfehler für den Besitzer sichtbar und nicht wiederholbar.
- Trennen Sie temporäre Ratenlimits von Kontingent-, Ausgaben- und Tageslimit-Erschöpfung.
- Fordern Sie einen Fallback-Vertrag an, bevor Sie den Provider oder das Modell ändern.
- Behandeln Sie Sicherheitsverweigerungen und Moderation als Richtlinienergebnisse, nicht als Provider-Ausfälle.
- Protokollieren Sie den Zustand der Teilausgabe vor jeder Wiederholung oder jedem Fallback.
- Überprüfen Sie die Nutzungs- und Routennachweise in Flatkey, bevor Sie auf weitere Workflows expandieren.
- Verlinken Sie das Runbook mit den Flatkey-Preisen, damit die Betreiber den aktuellen Katalog und die Kostenoberfläche überprüfen können.
Der Snapshot der öffentlichen Preisgestaltungs-API von Flatkey vom 3. Juli 2026 lieferte 45 Modellzeilen, sechs Anbieter-IDs und unterstützte Endpunktfamilien wie openai, anthropic, gemini und image-generation. Behandeln Sie diese nur als veraltete Quelldaten. Die Verfügbarkeit von Modellen, Preise und das Routenverhalten sollten vor dem Produktions-Rollout erneut überprüft werden.
FAQ
Was ist eine LLM-Gateway-Fehlertaxonomie?
Eine LLM-Gateway-Fehlertaxonomie ist ein normalisierter Satz von Fehlerklassen für den Modell-Provider-Traffic. Sie trennt Authentifizierungs-, Kontingent-, Provider-, Anfrage-, Sicherheits- und Abbruchfehler, damit das Gateway zwischen Wiederholung, Warteschlange, Fallback oder Fail-Closed-Verhalten wählen kann.
Warum nicht jeden LLM-API-Fehler wiederholen?
Das Wiederholen jedes Fehlers kann den Vorfall verschlimmern. Es kann Ratenlimits verstärken, mehr Token ausgeben, nachdem das Kontingent erschöpft ist, Anmeldeinformationsfehler verbergen, Teilausgaben duplizieren oder Sicherheitsblockaden umgehen. Die Taxonomie entscheidet, wann eine Wiederholung tatsächlich erlaubt ist.
Sollten Sicherheitsverweigerungen einen Fallback auslösen?
Nicht standardmäßig. Sicherheitsverweigerungen, Moderationsblockaden, Prompt-Blockaden und finishReason: SAFETY sollten als Richtlinienergebnisse behandelt werden. Fallback sollte niemals verwendet werden, um eine schwächere Sicherheitsroute zu finden.
Wie sollte ein LLM-Gateway Kontingentfehler klassifizieren?
Trennen Sie temporäres Rate Pacing von erschöpften Ausgaben, vorausbezahlten Guthaben, Tageslimits, Token-Limits und Projektlimits. Temporäres Pacing kann begrenztes Backoff oder Warteschlangen verwenden. Ein erschöpftes Budget führt normalerweise zu einem Fail-Closed, bis ein Besitzer mehr Kapazität genehmigt.
Wie hilft Flatkey bei einer LLM-Gateway-Fehlertaxonomie?
Flatkey bietet Teams eine einzige Gateway-Oberfläche für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und operative Kontrollen. Verwenden Sie es, um normalisierte Fehlerklassen mit Besitzerschlüsseln, Endpunktfamilien, angeforderten Modellen, bereitgestellten Modellen und Nutzungsnachweisen zu verknüpfen.
Beginnen Sie mit einem Workflow, definieren Sie Ihre LLM-Gateway-Fehlertaxonomie, holen Sie sich dann einen Schlüssel und testen Sie Authentifizierungs-, Kontingent-, Provider-, Anfrage-, Sicherheits- und Abbruchfälle, bevor der Produktionsverkehr von der automatischen Wiederherstellung abhängt.