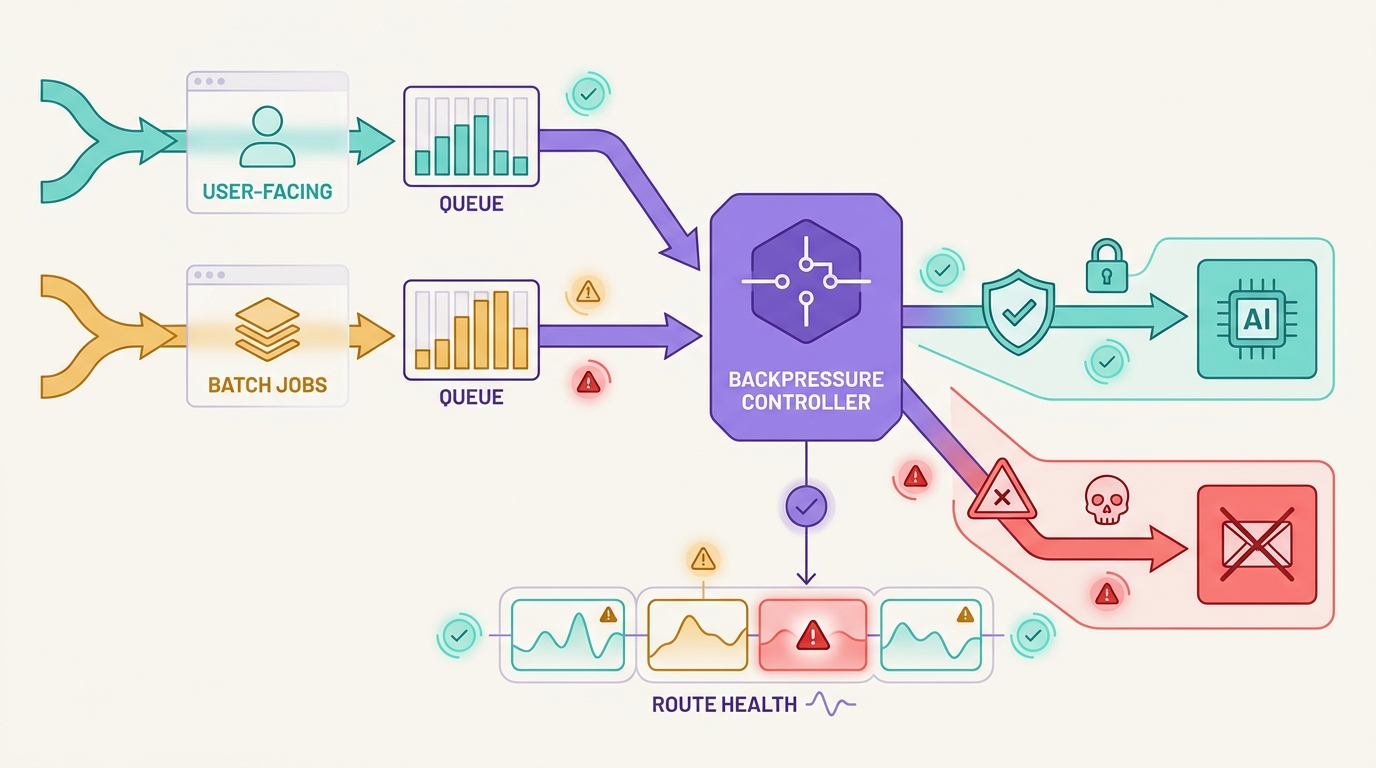
La taxonomía de errores de un gateway de LLM es la diferencia entre un incidente controlado y una costosa tormenta de reintentos. Un gateway no debería tratar cada llamada fallida al modelo como el mismo tipo de error del proveedor. Credenciales no válidas, cuota agotada, sobrecarga del proveedor, solicitudes mal formadas, denegaciones por seguridad, tiempos de espera y cancelaciones del cliente necesitan diferentes rutas de recuperación.
El error común es enviar cada fallo al mismo bucle de reintento y fallback. Eso puede ocultar una clave revocada, agotar un límite de gasto, enrutar contenido no seguro a un proveedor diferente o duplicar el trabajo después de que una respuesta de streaming ya haya comenzado. Una taxonomía práctica de errores de gateway de LLM proporciona a los equipos de ingeniería, producto y finanzas un lenguaje común para describir lo que sucedió y lo que el gateway debe hacer a continuación.
Flatkey encaja en este modelo operativo porque su sitio público actual posiciona el producto como una única superficie de gateway para el acceso a modelos, enrutamiento, facturación, análisis de uso y controles operativos. Utilice esa superficie compartida para clasificar los fallos antes de elegir un comportamiento de reintento, cola, fallback o de fallo cerrado.
Taxonomía de errores de gateway de LLM en una tabla
Comience con la clase, no solo con el estado HTTP. La misma familia de estados puede significar cosas diferentes entre proveedores, SDK y formas de endpoint.
| Clase de error | Señales comunes | ¿Reintentar? | ¿Fallback? | Acción del propietario |
|---|---|---|---|---|
| Autenticación y permisos | 401, 403, clave no válida, clave revocada, proyecto incorrecto, IP no autorizada, permiso denegado |
Sin reintento automático | No | Rotar o reparar credenciales, proyecto, lista de permitidos o permisos |
| Cuota y límite de tasa | 429, límite de tasa, cuota agotada, límite de gasto, límite de tokens/solicitudes, RESOURCE_EXHAUSTED |
A veces, con backoff acotado o encolamiento | Solo dentro de las reglas de coste y calidad aprobadas | Reducir la concurrencia, verificar el uso, aumentar los límites o detener el gasto |
| Proveedor y transporte | 500, 503, 529, sobrecarga, tiempo de espera, conexión restablecida, error de conexión del SDK |
A veces, si es idempotente y dentro del plazo | A veces, antes de la salida parcial y dentro del contrato | Verificar el estado del proveedor, la salud de la ruta, los presupuestos de tiempo de espera y la amplificación de reintentos |
| Solicitud y validación | 400, 422, JSON mal formado, modelo no válido, parámetro no admitido, contexto demasiado largo |
No, a menos que se cambie la solicitud | Raramente | Corregir el esquema, el tamaño del prompt, la forma del endpoint o la capacidad del modelo |
| Seguridad y política | denegación, bloqueo de moderación, bloqueo de prompt, finishReason: SAFETY, error de política de contenido |
Sin reintento automático | Sin fallback de omisión | Mostrar un mensaje de usuario seguro, registrar el contexto de seguridad, solicitar una entrada revisada cuando sea apropiado |
| Cancelación del cliente y plazo | cancelación del usuario, tiempo de espera del cliente, plazo del servidor, stream desconectado | Sin reintento a ciegas | Solo si no se ha confirmado ninguna salida o efecto secundario | Detener el trabajo, marcar la cancelación, preservar el estado de salida parcial |
Esta taxonomía de errores de gateway de LLM está intencionadamente orientada a la acción. No se limita a etiquetar errores para los paneles de control. Decide cuándo el sistema puede gastar más tokens, cuándo debe pedir a un propietario que corrija el estado y cuándo debe detenerse.
Clasificar antes de reintentar
Los documentos oficiales de los proveedores respaldan la separación de estas clases. La guía de errores de OpenAI distingue entre autenticación no válida, claves de API incorrectas, fallos en la lista de IP permitidas, límites de tasa, agotamiento de cuota o facturación, errores del servidor, sobrecarga, errores de conexión del SDK, tiempos de espera del SDK, solicitudes mal formadas, denegaciones de permisos y excepciones de límite de tasa. Su guía sobre límites de tasa recomienda un backoff exponencial aleatorio, pero también señala que las solicitudes fallidas siguen contando para los límites por minuto.
La documentación de errores de Anthropic separa invalid_request_error, authentication_error, permission_error, not_found_error, request_too_large, rate_limit_error, api_error y overloaded_error. Anthropic también documenta los límites de tasa 429 con la guía retry-after, y su guía sobre el motivo de la detención incluye refusal como una condición de detención a nivel de modelo.
La solución de problemas de Gemini asigna los fallos de autenticación y permisos por separado de los errores 429 RESOURCE_EXHAUSTED, los errores internos 500 y la falta de disponibilidad 503. La documentación de límites de tasa de Gemini describe las dimensiones de solicitud, token, solicitud diaria y gasto. La configuración de seguridad de Gemini también exponen los bloqueos de prompts, el finishReason del candidato y los safetyRatings, incluyendo un finishReason de SAFETY cuando el contenido de la respuesta está bloqueado.
Esa evidencia conduce a una regla simple: una taxonomía de errores de gateway de LLM debe normalizar las señales específicas del proveedor en campos de decisión antes de que el gateway elija una acción.
Fallos de autenticación y permisos
Los fallos de autenticación y permisos deben detenerse inmediatamente. Reintentar una clave incorrecta o un proyecto prohibido generalmente añade ruido sin cambiar el resultado.
Normalice estas señales en la clase de autenticación:
| Señal | Significado probable | Comportamiento del gateway |
|---|---|---|
401 autenticación no válida |
La clave es incorrecta, ha caducado, ha sido revocada, está mal formada o es del proyecto equivocado | No reintentar; alertar al propietario de la clave |
401 problema de pertenencia a la organización o al proyecto |
El llamador no está en la organización o proyecto requerido | No reintentar; dirigir al propietario de la cuenta |
401 o 403 problema de lista de IP permitidas o de permisos |
La solicitud provino de la red incorrecta o carece de acceso al punto de conexión | No reintentar; mostrar evidencia del permiso |
authentication_error o permission_error del proveedor |
Autenticación específica del proveedor o denegación de acceso | No recurrir a fallback; corregir la credencial o el permiso |
En un gateway, los errores de autenticación deben incluir owner_key, credential_id, project_id, provider, endpoint_family, requested_model y route_id. Evite registrar secretos en bruto. El incidente debe responder qué clave falló, qué ruta intentó la llamada y quién puede solucionarlo.
El fallback suele ser incorrecto para los fallos de autenticación. Si un equipo no ha aprobado un proveedor, cambiar silenciosamente a otro puede eludir las políticas de adquisición, de límites de datos o de modelo. La respuesta controlada es un fallo claro, una alerta al propietario y una ruta de corrección.
Fallos de cuota y límite de velocidad
Los fallos de cuota y límite de velocidad son la clase más perjudicada por una lógica de reintento vaga. Un 429 puede significar control de ráfagas, límites de solicitudes por minuto, límites de tokens por minuto, límites de solicitudes diarias, agotamiento del presupuesto mensual, agotamiento del crédito prepago o límites basados en el gasto. Esos casos no comparten una única ruta de recuperación.
Utilice esta taxonomía de errores de gateway de LLM para las decisiones de cuota:
| Señal de cuota | Ruta de reintento | Ruta de cola | Ruta de detención |
|---|---|---|---|
429 con Retry-After |
Respetar la cabecera si se ajusta al plazo del flujo de trabajo | Encolar trabajos no interactivos hasta el momento del reintento | Detener si la espera excede el plazo |
| 429 sin indicación de espera | Usar backoff con fluctuación y tope para un presupuesto de intentos pequeño | Reducir la concurrencia para el propietario, la ruta o la familia de puntos de conexión | Detener si los intentos repetidos aumentan el uso por minuto |
| Dimensión del límite de tokens | Reducir el prompt, la salida, el tamaño del lote o la concurrencia | Encolar trabajos grandes y reproducirlos con lotes más pequeños | Detener si la solicitud no se ajusta al contrato del modelo o del contexto |
| Agotamiento del gasto o del crédito | No reintentar automáticamente | Encolar solo si el responsable financiero ha aprobado la recarga o el aumento del presupuesto | Fallar en modo cerrado y conservar la evidencia del costo |
| Cuota diaria/de proyecto agotada | No hacer reintentos en bucle corto | Retrasar trabajos por lotes hasta el reinicio solo cuando esté permitido | Fallar en modo cerrado para solicitudes de cara al usuario |
La clave es distinguir el control de ritmo temporal del presupuesto agotado. El backoff ayuda cuando el proveedor le pide que reduzca la velocidad. El backoff no ayuda cuando la cuenta no tiene crédito o el trabajo no puede ajustarse al presupuesto de tokens disponible.
Combine esta sección con la estrategia de reintento de API de IA de Flatkey cuando necesite una lista de verificación de reintentos más detallada. Mantenga los intentos de reintento visibles en los registros para que los equipos de finanzas y operaciones puedan ver el gasto duplicado de tokens.
Fallos del proveedor y de transporte
Los fallos del proveedor y de transporte son diferentes de los fallos de cuota. Significan que la solicitud puede ser válida, la clave puede ser válida y el presupuesto puede estar disponible, pero la ruta no pudo completar la llamada.
Las señales comunes incluyen:
| Señal | Significado | Decisión del gateway |
|---|---|---|
500 o api_error del proveedor |
Error interno del lado del proveedor | Reintentar brevemente si es idempotente; verificar el estado si se repite |
503 no disponible o sobrecargado |
Condición de capacidad, mantenimiento o interrupción del proveedor | Backoff o fallback antes de una salida parcial |
overloaded_error de Anthropic o HTTP 529 |
Sobrecarga específica del proveedor | Tratar como capacidad del proveedor, no como cuota del cliente |
| Error de conexión del SDK | Falló la ruta de red, proxy, TLS, DNS o firewall | Reintentar solo cuando la ruta de transporte sea probablemente transitoria |
| Tiempo de espera del SDK agotado | La solicitud excedió un presupuesto de tiempo de espera | Reintentar solo si el plazo del flujo de trabajo y la idempotencia lo permiten |
| Desconexión de la transmisión | Puede que ya exista una salida parcial | Reanudar solo con una política de transmisión explícita |
El fallback del proveedor puede ser útil aquí, pero necesita un contrato. La ruta de fallback debe preservar la forma del punto de conexión, las herramientas, las necesidades de salida estructurada, la ventana de contexto, los límites de datos, la aprobación del modelo y el límite de costos. Si la transmisión ya ha emitido tokens visibles, el comportamiento más seguro suele ser detenerse y mostrar un fallo controlado en lugar de unir la salida de otra ruta.
Utilice la fiabilidad de la API de IA de streaming para la recuperación específica del streaming y la evaluación de fallback del modelo antes de convertir los errores del proveedor en cambios de ruta automáticos.
Fallos de solicitud y validación
Los fallos de solicitud y validación no suelen ser incidentes del proveedor. Significan que el llamador envió algo que el endpoint no puede procesar.
Algunos ejemplos son campos obligatorios faltantes, JSON malformado, parámetros no compatibles, familia de endpoint incorrecta, ID de modelo no válido, contexto demasiado largo, esquema de herramienta no compatible, modalidad incompatible o entradas de archivo/imagen/vídeo que no cumplen el contrato del endpoint.
El gateway debería registrar estos campos:
| Campo | Por qué es importante |
|---|---|
endpoint_family |
Separa las formas de chat, respuestas, mensajes, Gemini, imagen y vídeo compatibles con OpenAI |
requested_model |
Identifica nombres de modelos no válidos o no compatibles |
request_schema_version |
Muestra si el cliente y el gateway no están de acuerdo |
parameter_name |
Indica a los ingenieros el campo defectuoso |
input_token_estimate |
Separa la entrada malformada del desbordamiento de contexto |
client_sdk y sdk_version |
Encuentra problemas de migración y compatibilidad |
No reintente los fallos de validación sin cambios. Transforme la solicitud en una forma válida o devuelva un error orientado al desarrollador que nombre el campo a corregir. Cuando un gateway admite varias familias de endpoints, los errores de validación son especialmente importantes porque una solicitud puede ser válida para un proveedor e inválida para otro.
Fallos de seguridad y política
Los fallos de seguridad y política necesitan su propia clase porque el reintento y el fallback pueden debilitar accidentalmente las barreras de protección. Un rechazo de seguridad no es un tiempo de inactividad del proveedor. Un bloqueo de moderación no es un agotamiento de la cuota. Una salida bloqueada no es una razón para seguir muestreando hasta que el gateway encuentre una ruta que emita el contenido prohibido.
Normalice estas señales en la clase de seguridad:
| Señal | Evidencia de estilo del proveedor | Comportamiento del gateway |
|---|---|---|
| Rechazo del modelo | Las salidas estructuradas de OpenAI exponen los rechazos; los motivos de detención de Anthropic incluyen refusal |
Presente una respuesta segura y no la omita con un fallback |
| Bloqueo de moderación | Los documentos de seguridad de OpenAI recomiendan la moderación; los errores de imagen pueden exponer moderation_blocked |
Registre el contexto de la categoría segura y solicite una entrada revisada cuando sea apropiado |
| Bloqueo del prompt | La configuración de seguridad de Gemini expone promptFeedback.blockReason |
Devuelva un mensaje controlado antes de enviar trabajo downstream |
| Bloqueo de la salida | Gemini puede devolver finishReason: SAFETY y calificaciones de seguridad; el contenido bloqueado no se devuelve |
No reintente a ciegas; registre que la salida fue bloqueada |
| Regla de política o cumplimiento | Política específica de la aplicación, adquisición, límite de datos, edad o regla de flujo de trabajo regulado | Falle en modo cerrado o dirija a revisión humana |
La regla práctica es simple: una taxonomía de errores de gateway de LLM nunca debe tratar la seguridad como una interrupción recuperable del proveedor. El fallback puede ser aceptable solo cuando la ruta de fallback preserva la misma política de seguridad o una más estricta y el objetivo es completar una versión segura de la tarea, no eludir el bloqueo.
El registro de error normalizado
Una taxonomía de errores de gateway de LLM útil convierte los fallos específicos del proveedor en un único registro duradero.
| Campo normalizado | Valores de ejemplo | Uso |
|---|---|---|
error_class |
auth, quota, provider, request, safety, cancelled |
Impulsa la agrupación de runbooks y dashboards |
http_status |
401, 403, 429, 500, 503, 529 |
Conserva la señal del protocolo |
provider_error_type |
rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, moderation_blocked |
Conserva el significado específico del proveedor |
provider_error_code |
insufficient_quota, invalid_api_key, SAFETY |
Admite la ramificación exacta |
retry_after_ms |
Retraso derivado del encabezado o nulo | Evita la temporización de reintentos adivinada |
retryable |
true o false |
Separa la política de código de la redacción de la interfaz de usuario |
fallback_allowed |
true o false |
Hace cumplir el contrato de la ruta |
fail_closed_reason |
quota_exhausted, safety_block, contract_mismatch |
Explica por qué se detuvo el gateway |
requested_model y served_model |
ID de modelo o alias | Muestra si el enrutamiento cambió el comportamiento |
endpoint_family |
openai, anthropic, gemini, image-generation |
Hace visibles los problemas de migración |
partial_output_committed |
true o false |
Evita la salida duplicada visible para el usuario |
usage_units y estimated_cost |
tokens, imágenes, segundos, dólares | Hace visible el costo del reintento |
request_id y provider_request_id |
ID de gateway y proveedor | Admite tickets de soporte y revisión de incidentes |
No reduzca este registro a una sola cadena como "La llamada al LLM falló". Esa cadena no es suficiente para decidir si rotar una clave, esperar, recargar, recurrir a un fallback, revisar un prompt o detenerse.
Un clasificador simple de TypeScript
El clasificador no necesita conocer todos los detalles del proveedor desde el primer día. Comience con cubos explícitos y un valor predeterminado que falle de forma conservadora.
type ErrorClass =
| "auth"
| "quota"
| "provider"
| "request"
| "safety"
| "cancelled"
| "unknown";
type GatewayErrorInput = {
httpStatus?: number;
providerErrorType?: string;
providerErrorCode?: string;
finishReason?: string;
stopReason?: string;
clientCancelled?: boolean;
timeout?: boolean;
};
function classifyGatewayError(error: GatewayErrorInput): ErrorClass {
const type = (error.providerErrorType || "").toLowerCase();
const code = (error.providerErrorCode || "").toLowerCase();
const stop = (error.stopReason || "").toLowerCase();
const finish = (error.finishReason || "").toLowerCase();
if (error.clientCancelled) return "cancelled";
if (error.httpStatus === 401 || error.httpStatus === 403) return "auth";
if (type.includes("auth") || type.includes("permission")) return "auth";
if (code.includes("invalid_api_key") || code.includes("ip_not_authorized")) {
return "auth";
}
if (error.httpStatus === 429) return "quota";
if (type.includes("rate_limit") || code.includes("quota")) return "quota";
if (code.includes("resource_exhausted")) return "quota";
if (stop === "refusal" || finish === "safety") return "safety";
if (code.includes("moderation") || code.includes("blocked")) return "safety";
if (error.httpStatus === 400 || error.httpStatus === 422) return "request";
if (type.includes("invalid_request") || type.includes("bad_request")) {
return "request";
}
if (error.timeout) return "provider";
if ([500, 502, 503, 504, 529].includes(error.httpStatus || 0)) {
return "provider";
}
if (type.includes("overloaded") || type.includes("api_error")) {
return "provider";
}
return "unknown";
}
Utilice esto solo como punto de partida. Los clasificadores de producción deben mantener las asignaciones específicas del proveedor en la configuración, los accesorios de prueba y la revisión de incidentes, no enterradas solo en el código de la aplicación.
Runbook: reintentar, encolar, fallback o fallo cerrado
Una vez que se conoce la clase, el gateway puede elegir la acción.
| Clase | Acción predeterminada | Condición de reintento | Condición de fallback | Condición de fallo cerrado |
|---|---|---|---|---|
| Autenticación | Detener y alertar al propietario | Ninguna, a menos que se acabe de actualizar una credencial | Ninguna | Siempre hasta que se corrija la clave o el permiso |
| Cuota | Retroceso, encolar o detener por dimensión de límite | El límite de tasa temporal se ajusta al plazo y al presupuesto de intentos | La ruta aprobada mantiene el costo, la calidad y el límite de datos | Gasto, crédito, cuota diaria o plazo excedido |
| Proveedor | Retroceso o desvío ante un fallo transitorio del proveedor | Llamada idempotente, sin salida parcial, el plazo se mantiene | Existe una ruta aprobada equivalente | Fallo repetido, salida parcial o flujo de trabajo de alto riesgo |
| Solicitud | Devolver error de validación para el desarrollador | Solo después de la mutación de la solicitud | Solo cuando se selecciona explícitamente un endpoint/modelo compatible | Esquema no válido, desbordamiento de contexto, capacidad no admitida |
| Seguridad | Devolver respuesta segura o solicitar una revisión | Ninguna para contenido sin cambios | Solo con una política igual o más estricta, nunca para eludir | Prompt/salida bloqueada, denegación, regla de cumplimiento |
| Cancelado | Detener el trabajo y preservar el estado | Ninguna | Solo si el usuario reinicia explícitamente | Aborto del usuario, plazo, cliente desconectado |
Esta tabla es el centro operativo de la taxonomía de errores del gateway de LLM. Le indica al gateway cuándo es seguro realizar más trabajo y cuándo más trabajo se convierte en un riesgo.
Cómo aplicar esto en Flatkey
Utilice la taxonomía como una lista de verificación para el despliegue en lugar de un proyecto de panel de control único.
- Elija un flujo de trabajo, como el chat de soporte, la extracción por lotes, los trabajos de evaluación o el tráfico del asistente de código.
- Defina las familias de endpoints permitidas, los modelos, las rutas de fallback y los límites de costo para ese flujo de trabajo.
- Normalice los errores del proveedor en los campos anteriores.
- Haga que los fallos de autenticación y permisos sean visibles para el propietario y no reintentables.
- Separe los límites de tasa temporales del agotamiento de la cuota, el gasto y el límite diario.
- Exija un contrato de fallback antes de cambiar de proveedor o modelo.
- Trate la denegación de seguridad y la moderación como resultados de la política, no como interrupciones del proveedor.
- Registre el estado de la salida parcial antes de cualquier reintento o fallback.
- Revise el uso y la evidencia de la ruta en Flatkey antes de expandirse a más flujos de trabajo.
- Vincule el runbook a los precios de Flatkey para que los operadores puedan verificar el catálogo actual y la superficie de costos.
La instantánea de la API de precios pública de Flatkey del 3 de julio de 2026 devolvió 45 filas de modelos, seis ID de proveedores y familias de endpoints compatibles, incluidas openai, anthropic, gemini e image-generation. Trate esos datos solo como hechos de origen fechados. La disponibilidad del modelo, el precio y el comportamiento de la ruta deben verificarse nuevamente antes del despliegue en producción.
Preguntas frecuentes
¿Qué es una taxonomía de errores de gateway de LLM?
Una taxonomía de errores de gateway de LLM es un conjunto normalizado de clases de fallos para el tráfico entre el modelo y el proveedor. Separa los fallos de autenticación, cuota, proveedor, solicitud, seguridad y cancelación para que el gateway pueda elegir un comportamiento de reintento, encolamiento, fallback o fallo cerrado.
¿Por qué no reintentar cada error de la API de LLM?
Reintentar cada error puede empeorar el incidente. Puede amplificar los límites de tasa, gastar más tokens después de que se agote la cuota, ocultar fallos de credenciales, duplicar la salida parcial o eludir los bloqueos de seguridad. La taxonomía decide cuándo se permite realmente el reintento.
¿Deberían las denegaciones de seguridad activar un fallback?
No por defecto. Las denegaciones de seguridad, los bloqueos de moderación, los bloqueos de prompts y finishReason: SAFETY deben tratarse como resultados de la política. El fallback nunca debe usarse para encontrar una ruta de seguridad más débil.
¿Cómo debería un gateway de LLM clasificar los fallos de cuota?
Separe el control de ritmo de tasa temporal del gasto agotado, los créditos prepagos, los límites diarios, los límites de tokens y los límites del proyecto. El control de ritmo temporal puede usar retroceso limitado o colas. El presupuesto agotado generalmente resulta en un fallo cerrado hasta que un propietario apruebe más capacidad.
¿Cómo ayuda Flatkey con una taxonomía de errores de gateway de LLM?
Flatkey ofrece a los equipos una única superficie de gateway para el acceso a modelos, enrutamiento, facturación, análisis de uso y controles operativos. Úselo para mantener las clases de error normalizadas vinculadas a las claves del propietario, las familias de endpoints, los modelos solicitados, los modelos servidos y la evidencia de uso.
Comience con un flujo de trabajo, defina su taxonomía de errores de gateway de LLM, luego obtenga una clave y pruebe los casos de autenticación, cuota, proveedor, solicitud, seguridad y cancelación antes de que el tráfico de producción dependa de la recuperación automática.