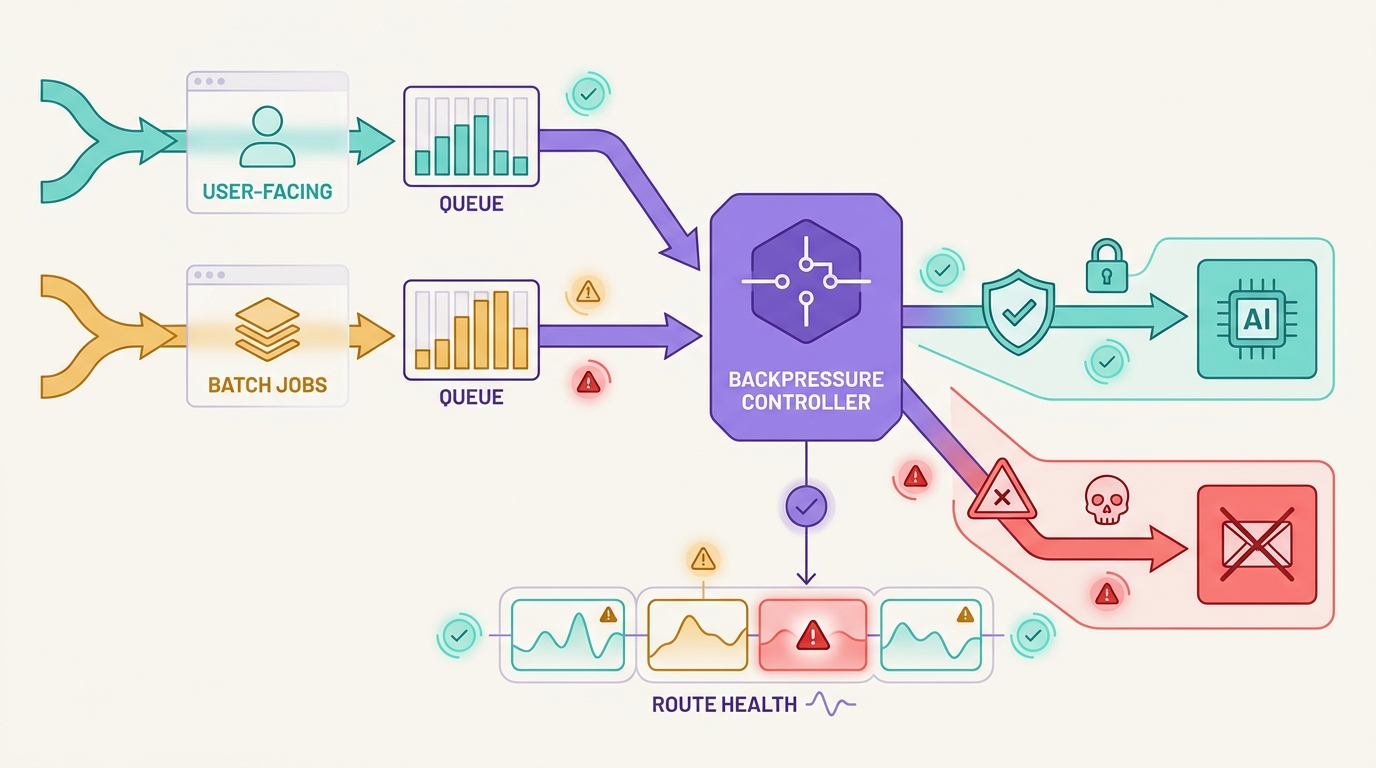
LLM gateway error taxonomy is the difference between a controlled incident and an expensive retry storm. A gateway should not treat every failed model call as the same kind of provider error. Invalid credentials, exhausted quota, provider overload, malformed requests, safety refusals, timeouts, and client cancels all need different recovery paths.
The common mistake is to send every failure into the same retry and fallback loop. That can hide a revoked key, burn through a spend cap, route unsafe content to a different provider, or duplicate work after a streaming response has already started. A practical LLM gateway error taxonomy gives engineering, product, and finance teams one shared language for what happened and what the gateway should do next.
Flatkey fits this operating model because its current public site positions the product as one gateway surface for model access, routing, billing, usage analytics, and operational controls. Use that shared surface to classify failures before choosing retry, queue, fallback, or fail-closed behavior.
LLM gateway error taxonomy in one table
Start with the class, not the HTTP status alone. The same status family can mean different things across providers, SDKs, and endpoint shapes.
| Error class | Common signals | Retry? | Fallback? | Owner action |
|---|---|---|---|---|
| Auth and permission | 401, 403, invalid key, revoked key, wrong project, IP not authorized, permission denied |
No automatic retry | No | Rotate or repair credentials, project, allowlist, or permissions |
| Quota and rate limit | 429, rate limit, quota exhausted, spend limit, token/request limit, RESOURCE_EXHAUSTED |
Sometimes, with bounded backoff or queueing | Only inside approved cost and quality rules | Reduce concurrency, check usage, increase limits, or stop spend |
| Provider and transport | 500, 503, 529, overload, timeout, connection reset, SDK connection error |
Sometimes, if idempotent and inside deadline | Sometimes, before partial output and inside contract | Check provider status, route health, timeout budgets, and retry amplification |
| Request and validation | 400, 422, malformed JSON, invalid model, unsupported parameter, context too long |
No, unless request is changed | Rarely | Fix schema, prompt size, endpoint shape, or model capability |
| Safety and policy | refusal, moderation block, prompt block, finishReason: SAFETY, content policy error |
No automatic retry | No bypass fallback | Show a safe user message, log safety context, ask for revised input when appropriate |
| Client cancel and deadline | user abort, client timeout, server deadline, disconnected stream | No blind retry | Only if no output or side effect committed | Stop work, mark cancellation, preserve partial-output state |
This LLM gateway error taxonomy is intentionally action-oriented. It does not just label errors for dashboards. It decides when the system may spend more tokens, when it must ask an owner to fix state, and when it should stop.
Classify before retrying
Official provider docs support separating these classes. OpenAI's error guide distinguishes invalid authentication, incorrect API keys, IP allowlist failures, rate limits, quota or billing exhaustion, server errors, overload, SDK connection errors, SDK timeouts, malformed requests, permission denials, and rate-limit exceptions. Its rate-limit guidance recommends random exponential backoff but also notes that failed requests still count toward per-minute limits.
Anthropic's error docs separate invalid_request_error, authentication_error, permission_error, not_found_error, request_too_large, rate_limit_error, api_error, and overloaded_error. Anthropic also documents 429 rate limits with retry-after guidance, and its stop-reason guidance includes refusal as a model-level stop condition.
Gemini troubleshooting maps authentication and permission failures separately from 429 RESOURCE_EXHAUSTED, 500 internal errors, and 503 unavailability. Gemini rate-limit docs describe request, token, daily request, and spend dimensions. Gemini safety settings also expose prompt blocks, candidate finishReason, and safetyRatings, including finishReason of SAFETY when response content is blocked.
That evidence leads to a simple rule: an LLM gateway error taxonomy should normalize provider-specific signals into decision fields before the gateway chooses an action.
Auth and permission failures
Auth and permission failures should stop immediately. Retrying a bad key or forbidden project usually adds noise without changing the result.
Normalize these signals into the auth class:
| Signal | Likely meaning | Gateway behavior |
|---|---|---|
401 invalid authentication |
Key is wrong, expired, revoked, malformed, or from the wrong project | Do not retry; alert key owner |
401 organization or project membership issue |
Caller is not in the required organization or project | Do not retry; route to account owner |
401 or 403 IP allowlist or permission problem |
Request came from the wrong network or lacks endpoint access | Do not retry; surface permission evidence |
Provider authentication_error or permission_error |
Provider-specific auth or access denial | Do not fallback; fix credential or grant |
In a gateway, auth errors should include owner_key, credential_id, project_id, provider, endpoint_family, requested_model, and route_id. Avoid logging raw secrets. The incident should answer which key failed, which route attempted the call, and who can fix it.
Fallback is usually wrong for auth failures. If a team has not approved one provider, silently switching to another provider can bypass procurement, data boundary, or model policy. The controlled response is a clear failure, an owner alert, and a remediation path.
Quota and rate-limit failures
Quota and rate-limit failures are the class most often harmed by vague retry logic. A 429 can mean burst pacing, request-per-minute limits, token-per-minute limits, daily request limits, monthly budget exhaustion, prepaid credit exhaustion, or spend-based limits. Those cases do not share one recovery path.
Use this LLM gateway error taxonomy for quota decisions:
| Quota signal | Retry path | Queue path | Stop path |
|---|---|---|---|
429 with Retry-After |
Respect the header if it fits the workflow deadline | Queue non-interactive jobs until the retry time | Stop if the wait exceeds the deadline |
| 429 without wait hint | Use capped jittered backoff for a small attempt budget | Reduce concurrency for the owner, route, or endpoint family | Stop if repeated attempts increase per-minute usage |
| Token limit dimension | Reduce prompt, output, batch size, or concurrency | Queue large jobs and replay with smaller batches | Stop if the request cannot fit the model or context contract |
| Spend or credit exhaustion | Do not retry automatically | Queue only if finance owner has approved recharge or budget increase | Fail closed and preserve cost evidence |
| Daily/project quota exhausted | Do not short-loop retries | Delay batch jobs until reset only when allowed | Fail closed for user-facing requests |
The key is to distinguish temporary pacing from exhausted budget. Backoff helps when the provider is asking you to slow down. Backoff does not help when the account has no credit or the job cannot fit the available token budget.
Pair this section with Flatkey's AI API retry strategy when you need a deeper retry checklist. Keep retry attempts visible in logs so finance and operations can see duplicate token spend.
Provider and transport failures
Provider and transport failures are different from quota failures. They mean the request may be valid, the key may be valid, and the budget may be available, but the route could not complete the call.
Common signals include:
| Signal | Meaning | Gateway decision |
|---|---|---|
500 or provider api_error |
Provider-side internal error | Retry briefly if idempotent; check status if repeated |
503 unavailable or overloaded |
Provider capacity, maintenance, or outage condition | Backoff or fallback before partial output |
Anthropic overloaded_error or HTTP 529 |
Provider-specific overload | Treat as provider capacity, not customer quota |
| SDK connection error | Network, proxy, TLS, DNS, or firewall path failed | Retry only when the transport path is likely transient |
| SDK timeout | Request exceeded a timeout budget | Retry only if workflow deadline and idempotency allow it |
| Streaming disconnect | Partial output may already exist | Resume only with explicit stream policy |
Provider fallback can be useful here, but it needs a contract. The fallback route must preserve endpoint shape, tools, structured output needs, context window, data boundary, model approval, and cost cap. If streaming has already emitted visible tokens, the safer behavior is often to stop and show a controlled failure instead of stitching output from another route.
Use streaming AI API reliability for streaming-specific recovery, and use model fallback evaluation before turning provider errors into automatic route changes.
Request and validation failures
Request and validation failures are usually not provider incidents. They mean the caller sent something the endpoint cannot process.
Examples include missing required fields, malformed JSON, unsupported parameters, wrong endpoint family, invalid model ID, context too long, unsupported tool schema, incompatible modality, or file/image/video input that does not meet the endpoint contract.
The gateway should log these fields:
| Field | Why it matters |
|---|---|
endpoint_family |
Separates OpenAI-compatible chat, responses, messages, Gemini, image, and video shapes |
requested_model |
Identifies invalid or unsupported model names |
request_schema_version |
Shows whether client and gateway disagree |
parameter_name |
Points engineers to the broken field |
input_token_estimate |
Separates malformed input from context overflow |
client_sdk and sdk_version |
Finds migration and compatibility issues |
Do not retry unchanged validation failures. Either transform the request into a valid shape or return a developer-facing error that names the field to fix. When a gateway supports multiple endpoint families, validation errors are especially important because a request can be valid for one provider and invalid for another.
Safety and policy failures
Safety and policy failures need their own class because retry and fallback can accidentally weaken guardrails. A safety refusal is not provider downtime. A moderation block is not quota exhaustion. A blocked output is not a reason to keep sampling until the gateway finds a route that emits the forbidden content.
Normalize these signals into the safety class:
| Signal | Provider-style evidence | Gateway behavior |
|---|---|---|
| Model refusal | OpenAI structured outputs expose refusals; Anthropic stop reasons include refusal |
Present a safe response and do not bypass with fallback |
| Moderation block | OpenAI safety docs recommend moderation; image errors may expose moderation_blocked |
Log safe category context and ask for revised input when appropriate |
| Prompt block | Gemini safety settings expose promptFeedback.blockReason |
Return a controlled message before sending downstream work |
| Output block | Gemini can return finishReason: SAFETY and safety ratings; blocked content is not returned |
Do not retry blindly; log that output was blocked |
| Policy or compliance rule | Application-specific policy, procurement, data boundary, age, or regulated-workflow rule | Fail closed or route to human review |
The practical rule is simple: an LLM gateway error taxonomy should never treat safety as a recoverable provider outage. Fallback may be acceptable only when the fallback route preserves the same or stricter safety policy and the goal is to complete a safe version of the task, not to bypass the block.
The normalized error record
A useful LLM gateway error taxonomy turns provider-specific failures into one durable record.
| Normalized field | Example values | Use |
|---|---|---|
error_class |
auth, quota, provider, request, safety, cancelled |
Drives runbook and dashboard grouping |
http_status |
401, 403, 429, 500, 503, 529 |
Preserves protocol signal |
provider_error_type |
rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, moderation_blocked |
Preserves provider-specific meaning |
provider_error_code |
insufficient_quota, invalid_api_key, SAFETY |
Supports exact branching |
retry_after_ms |
Header-derived delay or null | Prevents guessed retry timing |
retryable |
true or false |
Separates code policy from UI wording |
fallback_allowed |
true or false |
Enforces route contract |
fail_closed_reason |
quota_exhausted, safety_block, contract_mismatch |
Explains why the gateway stopped |
requested_model and served_model |
Model IDs or aliases | Shows whether routing changed behavior |
endpoint_family |
openai, anthropic, gemini, image-generation |
Makes migration issues visible |
partial_output_committed |
true or false |
Prevents duplicate user-visible output |
usage_units and estimated_cost |
tokens, images, seconds, dollars | Makes retry cost visible |
request_id and provider_request_id |
gateway and provider IDs | Supports support tickets and incident review |
Do not reduce this record to a single string like "LLM call failed." That string is not enough to decide whether to rotate a key, wait, recharge, fallback, revise a prompt, or stop.
A simple TypeScript classifier
The classifier does not need to know every provider detail on day one. Start with explicit buckets and a default that fails conservatively.
type ErrorClass =
| "auth"
| "quota"
| "provider"
| "request"
| "safety"
| "cancelled"
| "unknown";
type GatewayErrorInput = {
httpStatus?: number;
providerErrorType?: string;
providerErrorCode?: string;
finishReason?: string;
stopReason?: string;
clientCancelled?: boolean;
timeout?: boolean;
};
function classifyGatewayError(error: GatewayErrorInput): ErrorClass {
const type = (error.providerErrorType || "").toLowerCase();
const code = (error.providerErrorCode || "").toLowerCase();
const stop = (error.stopReason || "").toLowerCase();
const finish = (error.finishReason || "").toLowerCase();
if (error.clientCancelled) return "cancelled";
if (error.httpStatus === 401 || error.httpStatus === 403) return "auth";
if (type.includes("auth") || type.includes("permission")) return "auth";
if (code.includes("invalid_api_key") || code.includes("ip_not_authorized")) {
return "auth";
}
if (error.httpStatus === 429) return "quota";
if (type.includes("rate_limit") || code.includes("quota")) return "quota";
if (code.includes("resource_exhausted")) return "quota";
if (stop === "refusal" || finish === "safety") return "safety";
if (code.includes("moderation") || code.includes("blocked")) return "safety";
if (error.httpStatus === 400 || error.httpStatus === 422) return "request";
if (type.includes("invalid_request") || type.includes("bad_request")) {
return "request";
}
if (error.timeout) return "provider";
if ([500, 502, 503, 504, 529].includes(error.httpStatus || 0)) {
return "provider";
}
if (type.includes("overloaded") || type.includes("api_error")) {
return "provider";
}
return "unknown";
}
Use this only as a starting point. Production classifiers should keep provider-specific mappings in configuration, test fixtures, and incident review, not buried only in application code.
Runbook: retry, queue, fallback, or fail closed
Once the class is known, the gateway can choose the action.
| Class | Default action | Retry condition | Fallback condition | Fail-closed condition |
|---|---|---|---|---|
| Auth | Stop and alert owner | None, unless a credential refresh just occurred | None | Always until key or permission is fixed |
| Quota | Backoff, queue, or stop by limit dimension | Temporary rate limit fits deadline and attempt budget | Approved route keeps cost, quality, and data boundary | Spend, credit, daily quota, or deadline exceeded |
| Provider | Backoff or route around transient provider failure | Idempotent call, no partial output, deadline remains | Equivalent approved route exists | Repeated failure, partial output, or high-risk workflow |
| Request | Return developer-facing validation error | Only after request mutation | Only when a compatible endpoint/model is explicitly selected | Invalid schema, context overflow, unsupported capability |
| Safety | Return safe response or ask for revision | None for unchanged content | Only with same or stricter policy, never to bypass | Blocked prompt/output, refusal, compliance rule |
| Cancelled | Stop work and preserve state | None | Only if user explicitly restarts | User abort, deadline, disconnected client |
This table is the operational center of the LLM gateway error taxonomy. It tells the gateway when more work is safe and when more work becomes risk.
How to apply this in Flatkey
Use the taxonomy as a rollout checklist rather than a one-time dashboard project.
- Pick one workflow, such as support chat, batch extraction, evaluation jobs, or code assistant traffic.
- Define the allowed endpoint families, models, fallback routes, and cost caps for that workflow.
- Normalize provider errors into the fields above.
- Make auth and permission failures owner-visible and non-retryable.
- Split temporary rate limits from quota, spend, and daily-limit exhaustion.
- Require a fallback contract before changing provider or model.
- Treat safety refusal and moderation as policy outcomes, not provider outages.
- Log partial output state before any retry or fallback.
- Review usage and route evidence in Flatkey before expanding to more workflows.
- Link the runbook to Flatkey pricing so operators can verify the current catalog and cost surface.
Flatkey's July 3, 2026 public pricing API snapshot returned 45 model rows, six vendor IDs, and supported endpoint families including openai, anthropic, gemini, and image-generation. Treat those as dated source facts only. Model availability, price, and route behavior should be rechecked before production rollout.
FAQ
What is an LLM gateway error taxonomy?
An LLM gateway error taxonomy is a normalized set of failure classes for model-provider traffic. It separates auth, quota, provider, request, safety, and cancellation failures so the gateway can choose retry, queue, fallback, or fail-closed behavior.
Why not retry every LLM API error?
Retrying every error can make the incident worse. It can amplify rate limits, spend more tokens after quota is exhausted, hide credential failures, duplicate partial output, or bypass safety blocks. The taxonomy decides when retry is actually allowed.
Should safety refusals trigger fallback?
Not by default. Safety refusals, moderation blocks, prompt blocks, and finishReason: SAFETY should be treated as policy outcomes. Fallback should never be used to find a weaker safety route.
How should an LLM gateway classify quota failures?
Separate temporary rate pacing from exhausted spend, prepaid credits, daily limits, token limits, and project limits. Temporary pacing may use bounded backoff or queues. Exhausted budget usually fails closed until an owner approves more capacity.
How does Flatkey help with an LLM gateway error taxonomy?
Flatkey gives teams one gateway surface for model access, routing, billing, usage analytics, and operational controls. Use it to keep normalized error classes tied to owner keys, endpoint families, requested models, served models, and usage evidence.
Start with one workflow, define your LLM gateway error taxonomy, then get a key and test auth, quota, provider, request, safety, and cancellation cases before production traffic depends on automatic recovery.