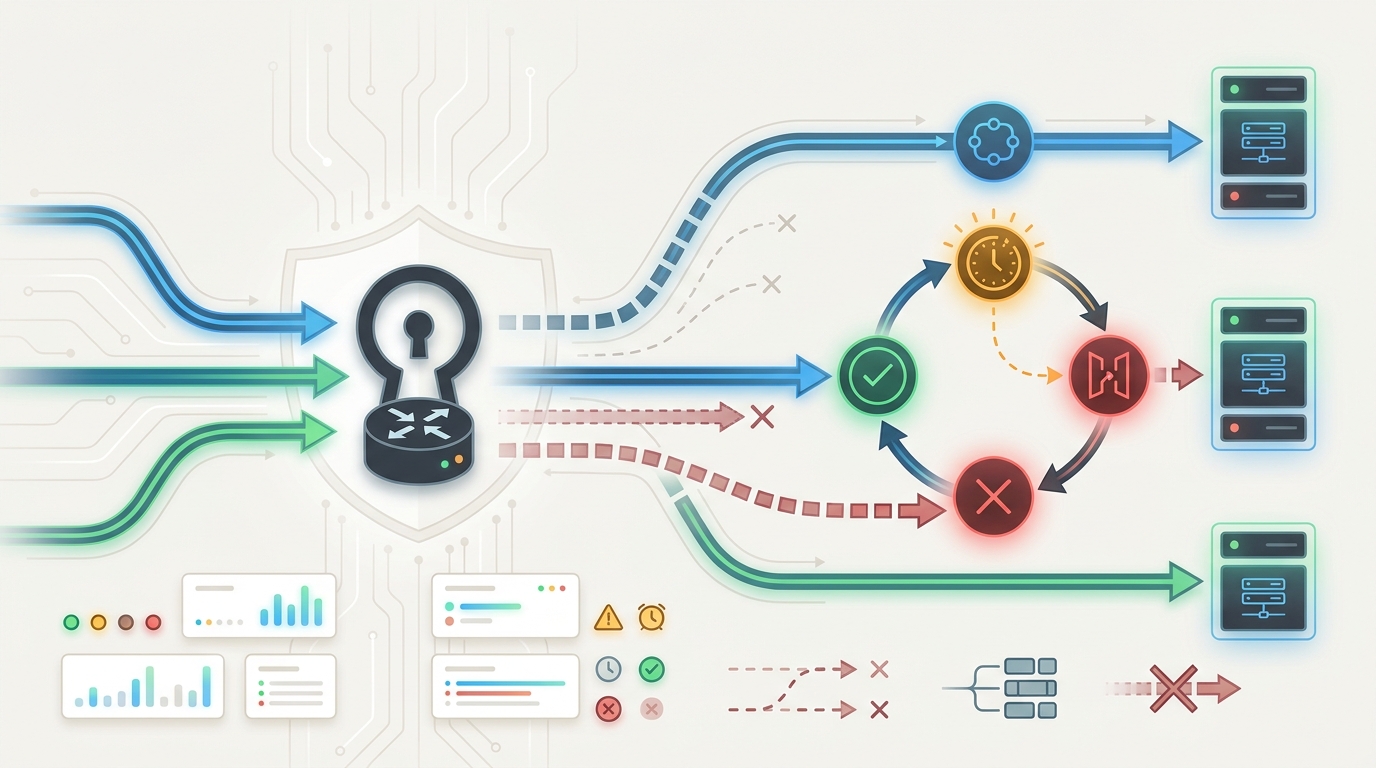
A taxonomia de erros de gateway de LLM é a diferença entre um incidente controlado e uma tempestade de novas tentativas dispendiosa. Um gateway não deve tratar cada chamada de modelo com falha como o mesmo tipo de erro do provedor. Credenciais inválidas, cota esgotada, sobrecarga do provedor, solicitações malformadas, recusas de segurança, tempos limite e cancelamentos do cliente precisam de caminhos de recuperação diferentes.
O erro comum é enviar cada falha para o mesmo loop de nova tentativa e fallback. Isso pode ocultar uma chave revogada, esgotar um limite de gastos, rotear conteúdo inseguro para um provedor diferente ou duplicar o trabalho depois que uma resposta de streaming já começou. Uma taxonomia prática de erros de gateway de LLM oferece às equipes de engenharia, produto e finanças uma linguagem compartilhada para o que aconteceu e o que o gateway deve fazer a seguir.
O Flatkey se encaixa nesse modelo operacional porque seu site público atual posiciona o produto como uma única superfície de gateway para acesso a modelos, roteamento, faturamento, análise de uso e controles operacionais. Use essa superfície compartilhada para classificar falhas antes de escolher o comportamento de nova tentativa, fila, fallback ou fail-closed.
Taxonomia de erros de gateway de LLM em uma tabela
Comece com a classe, não apenas com o status HTTP. A mesma família de status pode significar coisas diferentes entre provedores, SDKs e formatos de endpoint.
| Classe de erro | Sinais comuns | Nova tentativa? | Fallback? | Ação do proprietário |
|---|---|---|---|---|
| Autenticação e permissão | 401, 403, chave inválida, chave revogada, projeto errado, IP não autorizado, permissão negada |
Sem nova tentativa automática | Não | Rotacionar ou reparar credenciais, projeto, lista de permissões ou permissões |
| Cota e limite de taxa | 429, limite de taxa, cota esgotada, limite de gastos, limite de token/solicitação, RESOURCE_EXHAUSTED |
Às vezes, com backoff limitado ou enfileiramento | Apenas dentro das regras de custo e qualidade aprovadas | Reduzir a simultaneidade, verificar o uso, aumentar os limites ou interromper os gastos |
| Provedor e transporte | 500, 503, 529, sobrecarga, tempo limite, conexão redefinida, erro de conexão do SDK |
Às vezes, se for idempotente e dentro do prazo | Às vezes, antes da saída parcial e dentro do contrato | Verificar o status do provedor, a integridade da rota, os orçamentos de tempo limite e a amplificação de novas tentativas |
| Solicitação e validação | 400, 422, JSON malformado, modelo inválido, parâmetro não suportado, contexto muito longo |
Não, a menos que a solicitação seja alterada | Raramente | Corrigir esquema, tamanho do prompt, formato do endpoint ou capacidade do modelo |
| Segurança e política | recusa, bloqueio de moderação, bloqueio de prompt, finishReason: SAFETY, erro de política de conteúdo |
Sem nova tentativa automática | Sem fallback de bypass | Mostrar uma mensagem segura ao usuário, registrar o contexto de segurança, solicitar uma entrada revisada quando apropriado |
| Cancelamento do cliente e prazo | abortar do usuário, tempo limite do cliente, prazo do servidor, stream desconectado | Sem nova tentativa cega | Apenas se nenhuma saída ou efeito colateral for confirmado | Parar o trabalho, marcar o cancelamento, preservar o estado de saída parcial |
Esta taxonomia de erros de gateway de LLM é intencionalmente orientada para a ação. Ela não apenas rotula erros para painéis. Ela decide quando o sistema pode gastar mais tokens, quando deve pedir a um proprietário para corrigir o estado e quando deve parar.
Classifique antes de tentar novamente
Os documentos oficiais do provedor apoiam a separação dessas classes. O guia de erros da OpenAI distingue autenticação inválida, chaves de API incorretas, falhas na lista de permissões de IP, limites de taxa, esgotamento de cota ou faturamento, erros de servidor, sobrecarga, erros de conexão do SDK, tempos limite do SDK, solicitações malformadas, negações de permissão e exceções de limite de taxa. Sua orientação de limite de taxa recomenda backoff exponencial aleatório, mas também observa que as solicitações com falha ainda contam para os limites por minuto.
Os documentos de erro da Anthropic separam invalid_request_error, authentication_error, permission_error, not_found_error, request_too_large, rate_limit_error, api_error e overloaded_error. A Anthropic também documenta limites de taxa 429 com orientação retry-after, e sua orientação de motivo de parada inclui refusal como uma condição de parada no nível do modelo.
A solução de problemas do Gemini mapeia falhas de autenticação e permissão separadamente de 429 RESOURCE_EXHAUSTED, erros internos 500 e indisponibilidade 503. Os documentos de limite de taxa do Gemini descrevem as dimensões de solicitação, token, solicitação diária e gastos. As configurações de segurança do Gemini também expõem blocos de prompt, finishReason do candidato e safetyRatings, incluindo finishReason de SAFETY quando o conteúdo da resposta é bloqueado.
Essa evidência leva a uma regra simples: uma taxonomia de erros de gateway de LLM deve normalizar os sinais específicos do provedor em campos de decisão antes que o gateway escolha uma ação.
Falhas de autenticação e permissão
Falhas de autenticação e permissão devem ser interrompidas imediatamente. Tentar novamente com uma chave inválida ou um projeto proibido geralmente adiciona ruído sem alterar o resultado.
Normalize esses sinais na classe de autenticação:
| Sinal | Significado provável | Comportamento do gateway |
|---|---|---|
401 autenticação inválida |
A chave está incorreta, expirada, revogada, malformada ou é do projeto errado | Não tente novamente; alerte o proprietário da chave |
401 problema de associação à organização ou ao projeto |
O chamador não está na organização ou no projeto necessário | Não tente novamente; encaminhe para o proprietário da conta |
401 ou 403 problema de lista de permissões de IP ou de permissão |
A solicitação veio da rede errada ou não tem acesso ao endpoint | Não tente novamente; apresente a evidência da permissão |
authentication_error ou permission_error do provedor |
Autenticação específica do provedor ou negação de acesso | Não use fallback; corrija a credencial ou a concessão |
Em um gateway, os erros de autenticação devem incluir owner_key, credential_id, project_id, provider, endpoint_family, requested_model e route_id. Evite registrar segredos brutos. O incidente deve responder qual chave falhou, qual rota tentou a chamada e quem pode corrigi-la.
O fallback geralmente é inadequado para falhas de autenticação. Se uma equipe não aprovou um provedor, mudar silenciosamente para outro pode contornar políticas de aquisição, de fronteira de dados ou de modelo. A resposta controlada é uma falha clara, um alerta ao proprietário e um caminho de remediação.
Falhas de cota e limite de taxa
Falhas de cota e limite de taxa são a classe mais frequentemente prejudicada por lógicas de repetição vagas. Um 429 pode significar controle de rajada, limites de solicitações por minuto, limites de tokens por minuto, limites diários de solicitações, esgotamento do orçamento mensal, esgotamento de crédito pré-pago ou limites baseados em gastos. Esses casos não compartilham um único caminho de recuperação.
Use esta taxonomia de erros de gateway de LLM para decisões de cota:
| Sinal de cota | Caminho de repetição | Caminho de fila | Caminho de parada |
|---|---|---|---|
429 com Retry-After |
Respeite o cabeçalho se ele se ajustar ao prazo do fluxo de trabalho | Coloque trabalhos não interativos na fila até o tempo de repetição | Pare se a espera exceder o prazo |
| 429 sem dica de espera | Use backoff com jitter limitado para um pequeno orçamento de tentativas | Reduza a concorrência para o proprietário, rota ou família de endpoints | Pare se tentativas repetidas aumentarem o uso por minuto |
| Dimensão do limite de token | Reduza o prompt, a saída, o tamanho do lote ou a concorrência | Coloque trabalhos grandes na fila e execute novamente com lotes menores | Pare se a solicitação não couber no contrato do modelo ou do contexto |
| Esgotamento de gastos ou crédito | Não tente novamente automaticamente | Coloque na fila apenas se o responsável financeiro aprovou a recarga ou o aumento do orçamento | Falhe de forma segura e preserve a evidência de custo |
| Cota diária/do projeto esgotada | Não faça repetições em loop curto | Atrase trabalhos em lote até a redefinição, somente quando permitido | Falhe de forma segura para solicitações voltadas ao usuário |
O segredo é distinguir o controle de ritmo temporário do esgotamento do orçamento. O backoff ajuda quando o provedor está pedindo para você diminuir a velocidade. O backoff não ajuda quando a conta não tem crédito ou o trabalho não cabe no orçamento de tokens disponível.
Combine esta seção com a estratégia de repetição de API de IA do Flatkey quando precisar de uma lista de verificação de repetição mais detalhada. Mantenha as tentativas de repetição visíveis nos logs para que as equipes financeiras e de operações possam ver o gasto duplicado de tokens.
Falhas de provedor e de transporte
Falhas de provedor e de transporte são diferentes de falhas de cota. Elas significam que a solicitação pode ser válida, a chave pode ser válida e o orçamento pode estar disponível, mas a rota não conseguiu completar a chamada.
Sinais comuns incluem:
| Sinal | Significado | Decisão do gateway |
|---|---|---|
500 ou api_error do provedor |
Erro interno do lado do provedor | Tente novamente brevemente se for idempotente; verifique o status se repetido |
503 indisponível ou sobrecarregado |
Capacidade do provedor, manutenção ou condição de interrupção | Backoff ou fallback antes da saída parcial |
overloaded_error da Anthropic ou HTTP 529 |
Sobrecarga específica do provedor | Trate como capacidade do provedor, não como cota do cliente |
| Erro de conexão do SDK | Falha no caminho da rede, proxy, TLS, DNS ou firewall | Tente novamente apenas quando o caminho de transporte for provavelmente transitório |
| Timeout do SDK | A solicitação excedeu um orçamento de timeout | Tente novamente apenas se o prazo do fluxo de trabalho e a idempotência permitirem |
| Desconexão de streaming | A saída parcial já pode existir | Retome apenas com uma política de stream explícita |
O fallback de provedor pode ser útil aqui, mas precisa de um contrato. A rota de fallback deve preservar o formato do endpoint, ferramentas, necessidades de saída estruturada, janela de contexto, fronteira de dados, aprovação do modelo e limite de custo. Se o streaming já emitiu tokens visíveis, o comportamento mais seguro geralmente é parar e mostrar uma falha controlada em vez de juntar a saída de outra rota.
Use confiabilidade da API de IA de streaming para recuperação específica de streaming e use a avaliação de fallback de modelo antes de transformar erros do provedor em alterações automáticas de rota.
Falhas de solicitação e validação
Falhas de solicitação e validação geralmente não são incidentes do provedor. Elas significam que o chamador enviou algo que o endpoint não pode processar.
Exemplos incluem campos obrigatórios ausentes, JSON malformado, parâmetros não suportados, família de endpoint incorreta, ID de modelo inválido, contexto muito longo, esquema de ferramenta não suportado, modalidade incompatível ou entrada de arquivo/imagem/vídeo que não atende ao contrato do endpoint.
O gateway deve registrar estes campos:
| Campo | Por que é importante |
|---|---|
endpoint_family |
Separa os formatos de chat, respostas, mensagens, Gemini, imagem e vídeo compatíveis com OpenAI |
requested_model |
Identifica nomes de modelos inválidos ou não suportados |
request_schema_version |
Mostra se o cliente e o gateway discordam |
parameter_name |
Indica aos engenheiros o campo com problema |
input_token_estimate |
Separa a entrada malformada do estouro de contexto |
client_sdk e sdk_version |
Encontra problemas de migração e compatibilidade |
Não tente novamente falhas de validação inalteradas. Transforme a solicitação em um formato válido ou retorne um erro voltado para o desenvolvedor que nomeie o campo a ser corrigido. Quando um gateway suporta várias famílias de endpoints, os erros de validação são especialmente importantes porque uma solicitação pode ser válida para um provedor e inválida para outro.
Falhas de segurança e política
Falhas de segurança e política precisam de sua própria classe porque as tentativas e o fallback podem enfraquecer acidentalmente as proteções. Uma recusa de segurança não é tempo de inatividade do provedor. Um bloqueio de moderação não é esgotamento de cota. Uma saída bloqueada não é um motivo para continuar amostrando até que o gateway encontre uma rota que emita o conteúdo proibido.
Normalize estes sinais na classe de segurança:
| Sinal | Evidência no estilo do provedor | Comportamento do gateway |
|---|---|---|
| Recusa do modelo | As saídas estruturadas da OpenAI expõem recusas; os motivos de parada da Anthropic incluem refusal |
Apresente uma resposta segura e não contorne com fallback |
| Bloqueio de moderação | Os documentos de segurança da OpenAI recomendam moderação; erros de imagem podem expor moderation_blocked |
Registre o contexto da categoria de segurança e peça uma entrada revisada quando apropriado |
| Bloqueio de prompt | As configurações de segurança do Gemini expõem promptFeedback.blockReason |
Retorne uma mensagem controlada antes de enviar o trabalho downstream |
| Bloqueio de saída | O Gemini pode retornar finishReason: SAFETY e classificações de segurança; o conteúdo bloqueado não é retornado |
Não tente novamente às cegas; registre que a saída foi bloqueada |
| Regra de política ou conformidade | Política específica da aplicação, aquisição, limite de dados, idade ou regra de fluxo de trabalho regulamentado | Falhe fechado ou encaminhe para revisão humana |
A regra prática é simples: uma taxonomia de erros de gateway de LLM nunca deve tratar a segurança como uma interrupção recuperável do provedor. O fallback pode ser aceitável apenas quando a rota de fallback preserva a mesma política de segurança ou uma mais rigorosa, e o objetivo é concluir uma versão segura da tarefa, não contornar o bloqueio.
O registro de erro normalizado
Uma taxonomia útil de erros de gateway de LLM transforma falhas específicas do provedor em um registro durável.
| Campo normalizado | Valores de exemplo | Uso |
|---|---|---|
error_class |
auth, quota, provider, request, safety, cancelled |
Orienta o agrupamento de runbooks e dashboards |
http_status |
401, 403, 429, 500, 503, 529 |
Preserva o sinal do protocolo |
provider_error_type |
rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, moderation_blocked |
Preserva o significado específico do provedor |
provider_error_code |
insufficient_quota, invalid_api_key, SAFETY |
Suporta ramificação exata |
retry_after_ms |
Atraso derivado do cabeçalho ou nulo | Evita a adivinhação do tempo de nova tentativa |
retryable |
true ou false |
Separa a política de código do texto da interface do usuário |
fallback_allowed |
true ou false |
Impõe o contrato da rota |
fail_closed_reason |
quota_exhausted, safety_block, contract_mismatch |
Explica por que o gateway parou |
requested_model e served_model |
IDs de modelo ou aliases | Mostra se o roteamento alterou o comportamento |
endpoint_family |
openai, anthropic, gemini, image-generation |
Torna visíveis os problemas de migração |
partial_output_committed |
true ou false |
Evita a duplicação da saída visível ao usuário |
usage_units e estimated_cost |
tokens, imagens, segundos, dólares | Torna visível o custo da nova tentativa |
request_id e provider_request_id |
IDs de gateway e provedor | Suporta tickets de suporte e revisão de incidentes |
Não reduza este registro a uma única string como "Falha na chamada do LLM". Essa string não é suficiente para decidir se deve rotacionar uma chave, aguardar, recarregar, usar um fallback, revisar um prompt ou parar.
Um classificador TypeScript simples
O classificador não precisa conhecer todos os detalhes do provedor desde o primeiro dia. Comece com categorias explícitas e um padrão que falhe de forma conservadora.
type ErrorClass =
| "auth"
| "quota"
| "provider"
| "request"
| "safety"
| "cancelled"
| "unknown";
type GatewayErrorInput = {
httpStatus?: number;
providerErrorType?: string;
providerErrorCode?: string;
finishReason?: string;
stopReason?: string;
clientCancelled?: boolean;
timeout?: boolean;
};
function classifyGatewayError(error: GatewayErrorInput): ErrorClass {
const type = (error.providerErrorType || "").toLowerCase();
const code = (error.providerErrorCode || "").toLowerCase();
const stop = (error.stopReason || "").toLowerCase();
const finish = (error.finishReason || "").toLowerCase();
if (error.clientCancelled) return "cancelled";
if (error.httpStatus === 401 || error.httpStatus === 403) return "auth";
if (type.includes("auth") || type.includes("permission")) return "auth";
if (code.includes("invalid_api_key") || code.includes("ip_not_authorized")) {
return "auth";
}
if (error.httpStatus === 429) return "quota";
if (type.includes("rate_limit") || code.includes("quota")) return "quota";
if (code.includes("resource_exhausted")) return "quota";
if (stop === "refusal" || finish === "safety") return "safety";
if (code.includes("moderation") || code.includes("blocked")) return "safety";
if (error.httpStatus === 400 || error.httpStatus === 422) return "request";
if (type.includes("invalid_request") || type.includes("bad_request")) {
return "request";
}
if (error.timeout) return "provider";
if ([500, 502, 503, 504, 529].includes(error.httpStatus || 0)) {
return "provider";
}
if (type.includes("overloaded") || type.includes("api_error")) {
return "provider";
}
return "unknown";
}
Use isto apenas como um ponto de partida. Classificadores de produção devem manter mapeamentos específicos do provedor em configurações, dispositivos de teste e revisão de incidentes, e não enterrados apenas no código da aplicação.
Runbook: tentar novamente, enfileirar, usar fallback ou falhar de forma fechada
Uma vez que a classe é conhecida, o gateway pode escolher a ação.
| Classe | Ação padrão | Condição de nova tentativa | Condição de fallback | Condição de falha segura (fail-closed) |
|---|---|---|---|---|
| Autenticação | Parar e alertar o proprietário | Nenhuma, a menos que uma atualização de credencial tenha acabado de ocorrer | Nenhuma | Sempre até que a chave ou permissão seja corrigida |
| Cota | Backoff, enfileirar ou parar por dimensão de limite | O limite de taxa temporário se ajusta ao prazo e ao orçamento de tentativas | A rota aprovada mantém o custo, a qualidade e a fronteira de dados | Gasto, crédito, cota diária ou prazo excedido |
| Provedor | Backoff ou contornar falha transitória do provedor | Chamada idempotente, sem saída parcial, prazo restante | Existe uma rota aprovada equivalente | Falha repetida, saída parcial ou fluxo de trabalho de alto risco |
| Requisição | Retornar erro de validação para o desenvolvedor | Apenas após a mutação da requisição | Apenas quando um endpoint/modelo compatível é explicitamente selecionado | Esquema inválido, estouro de contexto, capacidade não suportada |
| Segurança | Retornar resposta segura ou pedir revisão | Nenhuma para conteúdo inalterado | Apenas com política igual ou mais rigorosa, nunca para contornar | Prompt/saída bloqueado, recusa, regra de conformidade |
| Cancelado | Parar o trabalho e preservar o estado | Nenhuma | Apenas se o usuário reiniciar explicitamente | Cancelamento do usuário, prazo, cliente desconectado |
Esta tabela é o centro operacional da taxonomia de erros de gateway de LLM. Ela informa ao gateway quando mais trabalho é seguro e quando mais trabalho se torna um risco.
Como aplicar isso no Flatkey
Use a taxonomia como uma lista de verificação de implementação em vez de um projeto de painel único.
- Escolha um fluxo de trabalho, como chat de suporte, extração em lote, trabalhos de avaliação ou tráfego de assistente de código.
- Defina as famílias de endpoints, modelos, rotas de fallback e limites de custo permitidos para esse fluxo de trabalho.
- Normalize os erros do provedor nos campos acima.
- Torne as falhas de autenticação e permissão visíveis ao proprietário e não repetíveis.
- Separe os limites de taxa temporários do esgotamento de cota, gastos e limite diário.
- Exija um contrato de fallback antes de alterar o provedor ou o modelo.
- Trate a recusa de segurança e a moderação como resultados da política, não como interrupções do provedor.
- Registre o estado da saída parcial antes de qualquer nova tentativa ou fallback.
- Revise o uso e as evidências de rota no Flatkey antes de expandir para mais fluxos de trabalho.
- Vincule o runbook aos preços do Flatkey para que os operadores possam verificar o catálogo atual e a superfície de custo.
O snapshot da API de preços pública do Flatkey de 3 de julho de 2026 retornou 45 linhas de modelo, seis IDs de fornecedor e famílias de endpoints suportadas, incluindo openai, anthropic, gemini e image-generation. Trate esses dados apenas como fatos de origem datados. A disponibilidade do modelo, o preço e o comportamento da rota devem ser verificados novamente antes da implementação em produção.
FAQ
O que é uma taxonomia de erros de gateway de LLM?
Uma taxonomia de erros de gateway de LLM é um conjunto normalizado de classes de falha para o tráfego do provedor de modelo. Ela separa falhas de autenticação, cota, provedor, requisição, segurança e cancelamento para que o gateway possa escolher o comportamento de nova tentativa, enfileiramento, fallback ou falha segura (fail-closed).
Por que não tentar novamente todos os erros da API de LLM?
Tentar novamente todos os erros pode piorar o incidente. Pode amplificar os limites de taxa, gastar mais tokens após o esgotamento da cota, ocultar falhas de credenciais, duplicar a saída parcial ou contornar bloqueios de segurança. A taxonomia decide quando a nova tentativa é realmente permitida.
As recusas de segurança devem acionar o fallback?
Não por padrão. Recusas de segurança, bloqueios de moderação, bloqueios de prompt e finishReason: SAFETY devem ser tratados como resultados da política. O fallback nunca deve ser usado para encontrar uma rota de segurança mais fraca.
Como um gateway de LLM deve classificar as falhas de cota?
Separe o controle de taxa temporário do esgotamento de gastos, créditos pré-pagos, limites diários, limites de token e limites de projeto. O controle de taxa temporário pode usar backoff limitado ou filas. O orçamento esgotado geralmente resulta em falha segura (fail-closed) até que um proprietário aprove mais capacidade.
Como o Flatkey ajuda com uma taxonomia de erros de gateway de LLM?
O Flatkey oferece às equipes uma única superfície de gateway para acesso a modelos, roteamento, faturamento, análise de uso e controles operacionais. Use-o para manter as classes de erro normalizadas vinculadas às chaves do proprietário, famílias de endpoints, modelos solicitados, modelos servidos e evidências de uso.
Comece com um fluxo de trabalho, defina sua taxonomia de erros de gateway de LLM e, em seguida, obtenha uma chave e teste os casos de autenticação, cota, provedor, requisição, segurança e cancelamento antes que o tráfego de produção dependa da recuperação automática.