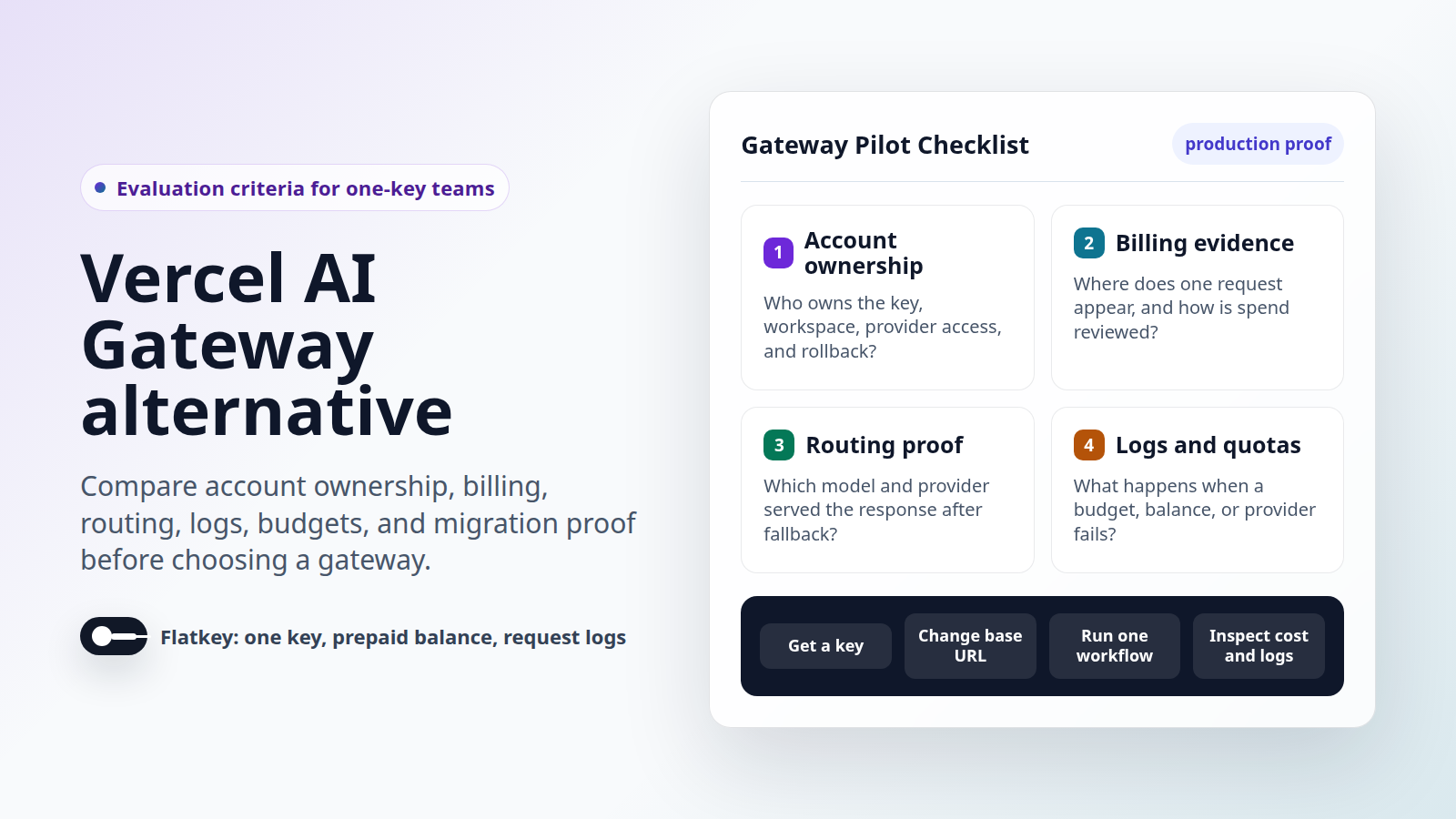
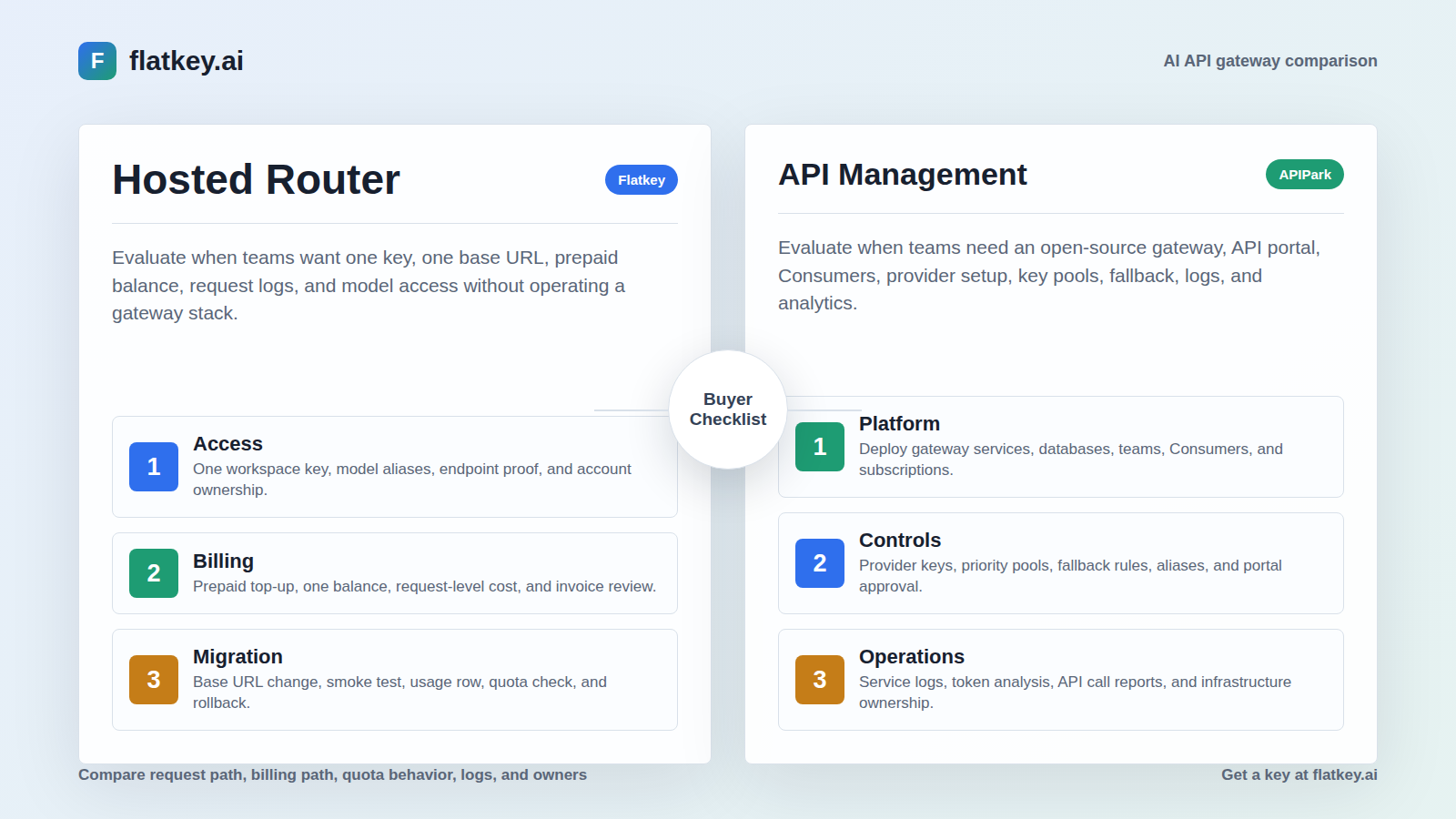
Ein verwaltetes KI-API-Gateway und ein selbst gehosteter LLM-Proxy können beide einen Endpunkt vor mehrere Modellanbieter schalten. Bei dieser Ähnlichkeit hören viele Checklisten für Käufer auf. Die schwierigere Entscheidung ist, wer nach dem Erfolg der ersten Anfrage für Anbieterkonten, Upstream-Schlüssel, Budgetdurchsetzung, Anforderungsprotokolle, Modell-Routing, Kostennachweise, Upgrades, Vorfälle und die Finanzprüfung verantwortlich ist.
Dieser Vergleich richtet sich an Entwickler, KI-Produktteams, Automatisierungsentwickler, Plattform-Ingenieure, Finanzverantwortliche und Beschaffungsprüfer, die entscheiden, ob sie ein gehostetes KI-Gateway kaufen oder einen internen Proxy-Stack betreiben sollen. Die Kurzfassung: Verwenden Sie einen selbst gehosteten Proxy, wenn Kontrolle und Plattform-Eigentum die Hauptanforderung sind. Verwenden Sie ein verwaltetes KI-API-Gateway, wenn das Team schnelleren Zugriff auf mehrere Modelle, Abrechnungsnachweise, eine Nutzungsübersicht und einen geringeren Betriebsaufwand benötigt.
Quellenhinweis: Dieser Leitfaden wurde am 1. Juli 2026 anhand der öffentlichen Seiten von Flatkey und der offiziellen LiteLLM-Dokumentation als repräsentative Quelle für selbst gehostete LLM-Proxys überprüft. Produktpakete, Modellkataloge, Bereitstellungsanleitungen, Preise, Anbieter-Support, Budgets und Routing-Verhalten können sich ändern. Verwenden Sie dies als Checkliste für Käufer und überprüfen Sie dann die aktuelle Konsole, die Dokumentation, den Vertrag und die Route vor der Produktivumstellung.
Kurze Antwort: Verwaltetes KI-API-Gateway vs. selbst gehosteter LLM-Proxy
Wählen Sie ein verwaltetes KI-API-Gateway, wenn Ihr unmittelbares Problem ein einheitlicher KI-Zugang mit nutzbaren Abrechnungs- und Betriebsnachweisen ist. Flatkey passt zu diesem Weg, da seine öffentlichen Seiten es als ein Gateway für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen, Betriebskontrollen, Prepaid-Guthaben, Anforderungsprotokolle, Kostenkontrollen und eine einzige Rechnung über alle Anbieter hinweg positionieren.
Wählen Sie einen selbst gehosteten LLM-Proxy, wenn Ihr Plattformteam die Gateway-Schicht bewusst selbst betreiben möchte. Eine repräsentative Option wie LiteLLM beschreibt einen selbst gehosteten, OpenAI-kompatiblen Proxy mit virtuellen Schlüsseln, Budgets pro Schlüssel/Team/Benutzer, zentralisierter Protokollierung, Leitplanken, Caching, Routing, Fallback, Lastausgleich, Admin-Benutzeroberfläche, Ausgabenverfolgung und Modellzugriffskontrollen. Das sind echte Kontrollen. Sie schaffen aber auch echte Eigenverantwortung und Arbeit.
| Käufersituation | Was zuerst zu vergleichen ist | Wahrscheinliche Richtung |
|---|---|---|
| Sie benötigen schnell einen gehosteten Schlüssel, ein Guthaben, Anforderungsprotokolle und eine für die Finanzabteilung sichtbare Nutzung. | Basis-URL, Modellkatalog, Prepaid-Guthaben, Kosten für Anforderungsprotokolle, Rechnungsweg und Quoten-Workflow. | Evaluieren Sie Flatkey als den Weg des verwalteten KI-API-Gateways. |
| Sie möchten die Gateway-Bereitstellung, die Modellkonfiguration, die Zugriffsrichtlinien, die Protokolle und benutzerdefinierte Integrationen selbst verantworten. | Proxy-Architektur, Datenbank, Secrets, SSO, virtuelle Schlüssel, Ratenbegrenzungen, Routing, Beobachtbarkeit und Verantwortliche für Vorfälle. | Ein selbst gehosteter LLM-Proxy könnte besser passen. |
| Ihr Team verfügt bereits über Plattformkapazitäten für Kubernetes, Postgres, Redis, Secret-Management und Rufbereitschaft. | Betriebshandbuch, Upgrade-Rhythmus, Backup-Plan, Kostendatenbank, Authentifizierungsmodell und Support-Weg. | Self-Hosting kann die zusätzliche Kontrolle rechtfertigen. |
| Entwickler müssen diese Woche einen OpenAI-kompatiblen Workflow validieren, ohne separates Onboarding bei den Anbietern. | Aktuelle Flatkey-Basis-URL, Modell-Alias, API-Schlüssel-Inhaber, Nutzungszeile, Guthaben-Inhaber und Rollback-Diff. | Ein verwaltetes KI-API-Gateway ist das Pilotprojekt mit geringerem Einrichtungsaufwand. |
Wofür ein verwaltetes KI-API-Gateway konzipiert ist
Ein verwaltetes KI-API-Gateway ist darauf ausgelegt, die Menge an Gateway-Infrastruktur zu reduzieren, die der Käufer aufbauen muss, bevor der Modell-Traffic fließen kann. Der Käufer benötigt weiterhin eine Sicherheitsüberprüfung, die Verantwortung für die Schlüssel, die Benennung der Workloads, Routentests, eine Kostenüberprüfung und ein Rollback. Der Unterschied besteht darin, dass der Anbieterzugang, die gehostete Routing-Oberfläche, die Nutzungsaufzeichnungen, der Abrechnungsworkflow und der Support-Weg als Service gebündelt sind, anstatt zu einem internen Plattformprojekt zu werden.
Die für diesen Leitfaden geprüfte Homepage von Flatkey trägt den Titel One API gateway for production AI teams. In der Meta-Beschreibung heißt es, dass flatkey.ai den Modellzugriff, das Routing, die Abrechnung, die Nutzungsanalyse und die Betriebskontrollen für Teams, die KI-Produkte ausliefern, vereinheitlicht. Diese öffentliche Positionierung ist wichtig, denn die Aufgabe des Käufers ist nicht nur, „eine Chat-Vervollständigung zu senden“. Es geht darum nachzuweisen, wer für die Ausgaben verantwortlich ist, welche Anfrage welches Modell verwendet hat und wie das Team die Betriebsnachweise überprüft.
Die am selben Tag geprüfte Preisseite von Flatkey trägt den Titel Transparent AI model pricing und beschreibt die Optionen für Modellzugriff, Routing und Abrechnung für KI-Workloads in der Produktion. Dort steht, dass Self-Service-Pläne auf Prepaid-Basis funktionieren, dass das Guthaben bei der Nutzung von Modellen durch API-Anfragen verbraucht wird und dass ein einziges Guthaben über ein OpenAI-kompatibles Gateway für GPT-, Claude-, Gemini-, DeepSeek-, Bild-, Audio- und Videomodelle verwendet werden kann. Es wird auch angegeben, dass die Nutzung nach Modell, Token-Typ und Anforderungsprotokollen gemessen wird, damit Teams die Ausgaben überprüfen und die Kosten kontrollieren können.
Das am 1. Juli 2026 geprüfte Modellverzeichnis von Flatkey gibt an, dass es serverseitig gerenderte Modellpreise für 629 KI-Modelle von 23 Anbietern veröffentlicht. Die Seite stellt Modellnamen, Anbieter, Endpunkttypen, Verfügbarkeitsfelder und Preisinformationen in durchsuchbarem HTML bereit. Die Endpunkt-Map umfasst Routen für Anthropic Messages, Gemini, Bilderzeugung, OpenAI Chat Completions, OpenAI Responses und OpenAI Video. Betrachten Sie diese Zahlen als veraltete Nachweise aus dem öffentlichen Katalog und nicht als Garantie dafür, dass jedes Konto jede Route ohne aktuelle Schlüssel- und Routenüberprüfung aufrufen kann.
Das macht Flatkey zu einer praktischen Managed AI API Gateway-Option, wenn Ihr Team einen einzigen Evaluierungspfad für App-Code, Finanzen und Betrieb wünscht. Das Pilotprojekt kann mit einer aktuellen Basis-URL aus der Konsole, einem Flatkey-API-Schlüssel, einem ausgewählten Modell-Alias, einer gemessenen Anfrage, der Überprüfung des Anfrageprotokolls, der Kostenüberprüfung und einer Go/No-Go-Notiz beginnen.
Wofür ein Self-Hosted LLM-Proxy entwickelt wurde
Ein Self-Hosted LLM-Proxy ist für Teams konzipiert, die die Gateway-Schicht selbst besitzen möchten. Die offizielle Dokumentation von LiteLLM beschreibt den Proxy als ein selbst gehostetes, OpenAI-kompatibles Gateway, bei dem jeder Client, der mit OpenAI arbeitet, auch mit dem Proxy arbeiten kann. Die Dokumentation beschreibt LiteLLM auch als eine Open-Source-Bibliothek und ein Gateway, das eine einheitliche Schnittstelle zu über 100 LLMs im OpenAI-Format bietet.
Die Proxy-Dokumentation von LiteLLM listet die betriebliche Oberfläche auf, die das Self-Hosting attraktiv macht: virtuelle Schlüssel mit Budgets pro Schlüssel, Team und Benutzer; zentralisierte Protokollierung; Guardrails; Caching; eine Admin-Benutzeroberfläche; Ausgabenverfolgung; Routing und Lastausgleich; Modell-Fallbacks; und Modellzugriffskontrollen. In der Dokumentation zu virtuellen Schlüsseln heißt es, dass Teams die Ausgaben verfolgen und den Modellzugriff über virtuelle Schlüssel steuern können, mit einer Benutzeroberfläche für die Schlüsselerstellung und SSO.
Dieselbe Dokumentation zeigt, warum das Wort „self-hosted“ wichtig ist. Für Workflows mit virtuellen Schlüsseln und Budgets erfordert LiteLLM die Einrichtung einer Datenbank. Das Docker-Tutorial besagt, dass Docker- oder CLI-Benutzer eine Postgres-Datenbank zum Generieren von Schlüsseln, Benutzern und Teams benötigen, und es zeigt eine database_url-Einstellung in config.yaml oder eine DATABASE_URL-Umgebungsvariable. Es erfordert auch einen Master-Schlüssel für die Proxy-Verwaltung.
Budgetkontrollen können anspruchsvoll sein. Die Dokumentation von LiteLLM zu Budgets und Ratenbegrenzungen beschreibt persönliche Budgets, Teambudgets, Budgets für Teammitglieder und Agentenbudgets. Dieselbe Seite behandelt RPM- und TPM-Limits, Budgetlaufzeiten, Ratenbegrenzungen pro Benutzer oder Schlüssel, modellspezifische Limits und einen erwarteten Fehler bei Budgetüberschreitung für Teamausgaben. Die Architektur-Dokumentation beschreibt die Validierung virtueller Schlüssel, Budgetprüfungen, Ratenbegrenzung, Redis- oder In-Memory-Cache-Prüfungen, die Weiterleitung durch den LiteLLM-Router, Logging-Callbacks und Aktualisierungen der Ausgaben in der Datenbank.
Diese Kontrollen können genau das sein, was eine Plattformorganisation wünscht. Aber sie sind nicht kostenlos, nur weil die Software Open Source ist. Das Team muss den Proxy, die Datenbank, die Secrets, die Anbieterkonten, die Bereitstellungspipeline, die Beobachtbarkeit, die Budgetrichtlinien, die Upgrades und den Incident-Prozess betreiben. Ein fairer Vergleich eines Managed AI API Gateway sollte die Kontrolle respektieren und gleichzeitig die Kosten des Betriebs berücksichtigen.
Vergleichsmatrix: Kosten, Kontrolle und Betrieb
Die fundierteste Entscheidung ergibt sich aus dem Vergleich von Betriebsnachweisen für denselben Workflow. Bitten Sie beide Pfade, den Anfragepfad, den Abrechnungspfad, den Kontingentpfad, den Protokollpfad und den verantwortlichen Support-Ansprechpartner aufzuzeigen.
| Entscheidungsbereich | Anzufordernde Nachweise für Managed AI API Gateway | Anzufordernde Nachweise für selbstgehosteten LLM-Proxy | Warum es wichtig ist |
|---|---|---|---|
| Kostenmodell | Prepaid-Aufladung, aktuelle Modellpreiszeile, Kosten für Anforderungsprotokolle, Auswirkungen auf das Guthaben, Rechnungspfad und Rechnungsverantwortlicher. | Cloud-Hosting, Datenbank, Cache, Observability, Entwicklungszeit, Rechnungen von Upstream-Anbietern und Support-Abdeckung. | Selbsthosting kann den Aufschlag des Gateway-Anbieters vermeiden, verursacht aber zusätzliche Infrastruktur- und Arbeitskosten. |
| Kontrolle | Arbeitsbereichsberechtigungen, Schlüsselverantwortlicher, Modell-Aliase, Anbietergruppen, Routenstatus und Support-Pfad. | Konfigurationsdateien, Anbieter-Anmeldeinformationen, virtuelle Schlüssel, Authentifizierungsrichtlinie, Secret-Manager, Datenbank und benutzerdefinierte Hooks. | Mehr Kontrolle ist nur dann nützlich, wenn das Team die Verantwortung für die Entscheidungen und Ausfallmodi übernehmen kann. |
| Anbieterzugriff | Liste der für das Konto aktivierten Modelle, Endpunktfamilie, aktueller Modellkatalog und Nachweis der Route auf Anforderungsebene. | Konten von Upstream-Anbietern, API-Schlüssel der Anbieter, Modellkonfigurationen, Fallback-Ziele und anbieterspezifische Parameter. | Die Zuständigkeit für den Zugriff steuert die Beschaffung, die Reaktion auf Vorfälle, die Ratenbegrenzungen und die Schlüsselrotation. |
| Routing und Fallback | Ausgewählter Modell-Alias, Endpunktfamilie, Routenstatus, Antwortformat, Fehlerformat und Fallback-Erwartungen. | Router-Konfiguration, Load-Balancing-Regel, Wiederholungsrichtlinie, Fallback-Kette, Cache-Verhalten und Fehlerprotokollierung. | Routing-Ansprüche benötigen einen Nachweis auf Anforderungsebene, bevor der Produktionsverkehr umgeleitet wird. |
| Budgets und Kontingente | Prepaid-Guthaben, Kontingentkontrollen, Kostenkontrollen, Nutzungsanalysen, Anforderungsprotokolle und Eskalationspfad des Verantwortlichen. | Budget für virtuelle Schlüssel, Teambudget, Ratenbegrenzungen, RPM/TPM-Regeln, modellspezifische Limits und Verhalten bei Budgetüberschreitung. | Ein Kontingent ist nur dann nützlich, wenn die Teams wissen, ob es blockiert, alarmiert, auf ein Fallback zurückgreift oder manuelles Eingreifen erfordert. |
| Protokolle und Analysen | Anforderungsprotokolle, Modell- und Token-Felder, Kostentransparenz, Nutzungsanalysen, Routenstatus und Exportanforderungen. | Aktualisierungen der Ausgaben in der Proxy-Datenbank, Logging-Callbacks, Integration externer Observability-Tools, Aufbewahrung und Zugriffskontrollen. | Debugging, Finanzprüfung und Sicherheitsüberprüfung hängen von den Feldern ab, die nach einer Anfrage sichtbar sind. |
| Migrationsaufwand | Änderung der OpenAI-kompatiblen Basis-URL, Flatkey-API-Schlüssel, Modell-Alias-Mapping, Smoke-Test, Nutzungsüberprüfung und Rollback-Diff. | Proxy-Bereitstellung, Datenbank-Setup, Master-Schlüssel, Anbieterkonfiguration, virtuelle Schlüssel, Authentifizierung, Routing, Überwachung und Runbooks. | Eine kleine SDK-Änderung kann ein großes Plattformprojekt verbergen. |
| Betriebsverantwortlicher | Anbieter-Support, Arbeitsbereichs-Admin, Rechnungsverantwortlicher, Schlüsselverantwortlicher und Verantwortlicher für die Produktionsverifizierung. | Plattform-Rufbereitschaft, Datenbankverantwortlicher, Secret-Verantwortlicher, Upgrade-Verantwortlicher, Richtlinienverantwortlicher und Verantwortlicher für die Anbiereskalation. | Der erfolgreiche Weg ist der, den Ihre Organisation zuverlässig betreiben kann. |
Wann ein selbstgehosteter LLM-Proxy die bessere Wahl ist
Ein selbstgehosteter LLM-Proxy ist wahrscheinlich die bessere Wahl, wenn Ihr Plattformteam eine tiefgreifende Kontrolle über den Anfragepfad benötigt. Dazu gehören benutzerdefinierte Authentifizierung, benutzerdefinierte Routing-Richtlinien, Anforderungen an den internen Secret-Manager, regionsspezifische Bereitstellung, Kontrollen für private Netzwerke, benutzerdefinierte Observability-Callbacks, eine strikte Architektur für die Datenresidenz und interne Verrechnungsregeln, die innerhalb Ihrer Plattform liegen müssen.
Selbsthosting eignet sich auch, wenn die Organisation bereits über operative Kapazitäten verfügt. Wenn Ihr Team routinemäßig Postgres, Redis, Kubernetes oder Container-Dienste, Secret-Rotation, SSO, Logging-Pipelines, Incident Response und Upgrade-Fenster betreibt, kann die zusätzliche Verantwortung akzeptabel sein. In diesem Fall wird der Proxy zu einer weiteren Plattformkomponente und nicht zu einem einmaligen Werkzeug.
Schließlich kann ein selbstgehosteter Proxy die richtige Wahl sein, wenn das Gateway selbst Teil Ihrer Produktarchitektur ist. Wenn Sie vielen internen Teams KI-Zugriff mit benutzerdefinierten Schlüsseln, benutzerdefinierten Modellbeschränkungen, teambezogenen Budgets, Audit-Erwartungen und einer von Ihren eigenen Ingenieuren kontrollierten Routing-Richtlinie bereitstellen müssen, kann der zusätzliche Einrichtungsaufwand nützliche Vorteile bringen.
Wann Flatkey in die engere Wahl kommen sollte
Flatkey sollte in die engere Wahl kommen, wenn das Team ein verwaltetes KI-API-Gateway anstelle eines Gateway-Betriebsprojekts wünscht. Die stärksten Anwendungsfälle sind Multi-Modell-Produkt-Workflows, interne Automatisierung, Agenten, Codierungswerkzeuge und von der Finanzabteilung geprüfte Pilotprojekte, bei denen die Schlüsselfragen lauten: Welcher Schlüssel hat die Anfrage gesendet, welches Modell hat sie bedient, was hat es gekostet, wo ist das Protokoll und wer genehmigt den nächsten Nutzungsschritt?
Flatkey ist auch relevant, wenn der Migrationspfad OpenAI-kompatibel ist. Anstatt einen Proxy bereitzustellen, eine Datenbank zu provisionieren, einen Master-Schlüssel festzulegen, Upstream-Anbieter zu konfigurieren, virtuelle Schlüssel auszustellen und Protokolle zu verdrahten, bevor ein Entwickler einen einzigen Workflow testen kann, kann das Flatkey-Pilotprojekt mit einer Basis-URL, einem API-Schlüssel, einem Modell-Alias, einem Anforderungstest, einer Nutzungsüberprüfung und einer Rollback-Notiz beginnen.
Der Käufer sollte dennoch den aktuellen Kontostand überprüfen. Überprüfen Sie vor der Produktion die Basis-URL der Flatkey-Konsole, die Endpunktfamilie, den ausgewählten Modell-Alias, die Modellpreiszeile, die Kontoberechtigungen, die Anforderungsprotokolle, die Kostenfelder, das Kontingentverhalten, den Guthabenverantwortlichen und den Support-Pfad. Die nützliche Behauptung ist nicht, dass ein Managed Service die gesamte Überprüfungsarbeit beseitigt. Es ist vielmehr so, dass die Überprüfungsarbeit näher am KI-Workflow und weiter entfernt von der Gateway-Zusammenstellung beginnt.
Pilot-Checkliste für denselben Workflow
Verwenden Sie diese Checkliste, bevor Sie sich für ein Managed AI API Gateway oder einen selbst gehosteten LLM-Proxy entscheiden. Sie sorgt dafür, dass die Entscheidung auf Nachweisen beruht, die Entwickler, Plattform-Owner, Finanz- und Beschaffungsabteilungen prüfen können.
- Benennen Sie einen Workflow. Wählen Sie einen Support-Agenten, einen Programmierassistenten, einen Batch-Job, einen Bild-/Video-Workflow oder einen internen Automatisierungspfad. Bewerten Sie nicht den gesamten Modellbestand auf einmal.
- Frieren Sie die aktuelle Route ein. Erfassen Sie den aktuellen Anbieter, den Key-Inhaber, das Modell, den Endpunkt, die Anfrageform, das Wiederholungsverhalten, die durchschnittliche Nutzung und den für das Rollback Verantwortlichen.
- Ordnen Sie die Account-Inhaberschaft zu. Identifizieren Sie für Flatkey den Workspace, den Inhaber des API-Keys, den Guthabeninhaber, den Modell-Alias, die Anbietergruppe und die Prüfer der Anfrageprotokolle. Identifizieren Sie für das Self-Hosting den Proxy-Owner, die Anbieter-Accounts, den Datenbank-Owner, den Secret-Owner, den Inhaber des virtuellen Keys und den Verantwortlichen für die Rufbereitschaft.
- Führen Sie eine minimale Anfrage aus. Erfassen Sie den Status, die Antwortform, das verwendete Modell, die Nutzungsfelder, das Fehlerformat, die Latenz und ob die Anfrage im erwarteten Protokoll erscheint.
- Führen Sie einen Budget-Test durch. Bestätigen Sie den Geltungsbereich des Limits, das Rücksetzfenster, das Durchsetzungsverhalten, den Benachrichtigungsweg und wer handelt, wenn das Limit erreicht ist.
- Führen Sie einen Abrechnungstest durch. Bestätigen Sie die Kosteneinheit, die Preisquelle, die Anfragekosten, die Auswirkung auf das Guthaben oder die Anbieterrechnung, den Rechnungsweg und den Verantwortlichen für die Finanzprüfung.
- Führen Sie einen Fehlertest durch. Simulieren Sie ein ungültiges Modell, einen Authentifizierungsfehler, eine Upstream-Ratenbegrenzung, einen Anbieterfehler, ein aufgebrauchtes Budget und einen Fallback. Protokollieren Sie, was passiert und wer benachrichtigt wird.
- Verfassen Sie die Go/No-Go-Notiz. Fügen Sie den exakten Code-Diff, den Diff der Umgebungsvariablen, den Routennachweis, den Protokollnachweis, den Abrechnungsnachweis, die Zuständigkeitsübersicht und den Rollback-Pfad bei.
Kostenmodell: Vergleichen Sie nicht nur die Anbietergebühren
Beim Kostenvergleich erstellen Teams oft die falsche Kalkulationstabelle. Ein selbst gehosteter Proxy mag günstiger erscheinen, wenn der einzige Posten die Gateway-Software ist. Ein faires Modell berücksichtigt auch Rechenleistung, Datenbank, Cache, Observability, Sicherheitsüberprüfung, Einrichtungszeit durch das Engineering, Rufbereitschaft, Incident Handling, Upgrades und die Verwaltung der Anbieter-Accounts. Wenn diese Kosten bereits von einem Plattform-Team getragen werden, kann Self-Hosting dennoch effizient sein. Wenn sie neue Arbeit darstellen, sollten sie mitgezählt werden.
Ein Managed AI API Gateway hat eine andere Kostenstruktur. Der Käufer sollte die Modellpreise, das Prepaid-Guthaben, die Kosten für Anfrageprotokolle, das Rechnungsverhalten und alle kontospezifischen Bedingungen prüfen. Der Wert liegt nicht nur in einem niedrigeren Posten. Er besteht darin, die Anzahl der Systeme zu reduzieren, die ein Team zusammenstellen muss, bevor Finanz- und Betriebsabteilungen dem Workflow vertrauen können.
Wenn Sie auch namentlich genannte Gateway-Produkte vergleichen, verwenden Sie denselben Nachweisstandard. Die Leitfäden zu OpenRouter-Alternativen, LiteLLM-Alternativen und die Checkliste für Enterprise AI API Gateways konzentrieren sich alle auf Account-Zuständigkeiten, Abrechnung, Routing-Nachweise, Protokolle, Quoten, Migrationsaufwand und betriebliche Nachweise. Nutzen Sie die Flatkey-Preise für die aktuelle Seite zum Modellzugriff und zur Abrechnung und holen Sie sich einen Key, wenn Sie bereit sind, ein gezieltes Pilotprojekt durchzuführen.
FAQ
Was ist ein Managed AI API Gateway?
Ein Managed AI API Gateway ist eine gehostete Zugriffsschicht für den KI-Modell-Traffic. Es bietet Teams typischerweise eine gemeinsame API-Oberfläche, Modell-Routing, Einblick in die Nutzung, einen Abrechnungs-Workflow und betriebliche Kontrollen, ohne dass der Käufer die Gateway-Infrastruktur selbst bereitstellen und betreiben muss.
Ist ein selbst gehosteter LLM-Proxy günstiger als ein Managed AI API Gateway?
Manchmal, aber nur, wenn Ihr Team die Infrastruktur und den Arbeitsaufwand stemmen kann. Self-Hosting kann die Abhängigkeit von einem Gateway-Anbieter verringern und die Kontrolle erhöhen, fügt aber auch Arbeit für Bereitstellung, Datenbank, Secret-Management, Observability, Upgrades und Rufbereitschaft hinzu. Ein Managed AI API Gateway bündelt mehr dieser Arbeit in seinem Service.
Bietet Self-Hosting mehr Kontrolle?
Ja. Ein selbst gehosteter Proxy bietet in der Regel eine tiefere Kontrolle über Anbieter-Anmeldeinformationen, Routing-Richtlinien, virtuelle Keys, Budgets, Protokolle und Integrationen. Der Kompromiss ist, dass Ihr Team diese Kontrollen in der Produktion selbst verantwortet. Mehr Kontrolle ist wertvoll, wenn Sie auch die Mitarbeiter und Prozesse haben, um sie zu betreiben.
Kann Flatkey jeden Anwendungsfall für selbst gehostete Proxys ersetzen?
Nein. Flatkey sollte als alternatives Betriebsmodell bewertet werden, nicht als Klon jedes Proxys. Wenn Ihre Anforderungen eine benutzerdefinierte Bereitstellungstopologie, rein internes Networking, benutzerdefinierte Authentifizierungs-Plugins oder proprietäre Routing-Logik umfassen, ist Self-Hosting möglicherweise die bessere Wahl. Wenn Ihre Priorität auf einem verwalteten Multi-Modell-Zugriff mit Abrechnungs- und Nutzungsnachweisen liegt, sollten Sie Flatkey evaluieren.
Wie sollte die Finanzabteilung die Wahl bewerten?
Die Finanzabteilung sollte nach einem konkreten Workflow fragen und ihn von der Anfrage bis zur Rechnung nachverfolgen. Bestätigen Sie die erwarteten monatlichen Anfragen, den Modell-Mix, die Token-Typen, Wiederholungen, Fallbacks, das Quotenverhalten, den Rechnungsweg, die Auswirkung auf das Guthaben oder die Anbieterrechnung, den Protokollzugriff und den Genehmigungsverantwortlichen. Eine Funktionsliste reicht nicht aus.
Was sollten Entwickler vor der Migration testen?
Entwickler sollten die exakte Basis-URL, den API-Key, den Modell-Alias, die Endpunkt-Familie, das Streaming-Verhalten, das Tool-Verhalten, das Fehlerformat, das Timeout-Verhalten, die Nutzungsfelder und den Rollback-Pfad testen. Eine erfolgreiche Chat-Anfrage beweist nicht, dass der gesamte Workflow produktionsreif ist.
Finale Entscheidungsregel
Wählen Sie einen selbst gehosteten LLM-Proxy, wenn die Gateway-Schicht eine strategische Infrastruktur ist, die Ihr Plattform-Team selbst besitzen möchte. Wählen Sie ein Managed AI API Gateway, wenn Ihr Team einen einzigen Key, OpenAI-kompatiblen Zugriff, veröffentlichte Modellpreise, Prepaid-Guthaben, Nutzungsanalysen, Anfrageprotokolle, Kostenkontrollen und einen schnelleren Weg zur Validierung von Modell-Workflows wünscht.
Um Flatkey in diesem verwalteten Betriebsmodell zu testen, überprüfen Sie die aktuellen Preise und den Modellzugang, holen Sie sich einen Schlüssel und führen Sie dann einen gemessenen Workflow aus, bevor Sie den breiteren Traffic umleiten.