Une passerelle API d'IA gérée et un proxy LLM auto-hébergé peuvent tous deux placer un point de terminaison unique devant plusieurs fournisseurs de modèles. C'est là que s'arrêtent de nombreuses listes de contrôle des acheteurs. La décision la plus difficile concerne la responsabilité des comptes fournisseurs, des clés en amont, de l'application du budget, des journaux de requêtes, du routage des modèles, des preuves de coûts, des mises à niveau, des incidents et de l'examen financier après la réussite de la première requête.
Cette comparaison s'adresse aux développeurs, aux équipes de produits d'IA, aux créateurs d'automatisation, aux ingénieurs de plateforme, aux opérateurs financiers et aux évaluateurs d'approvisionnement qui doivent décider s'il faut acheter une passerelle d'IA hébergée ou exploiter une pile de proxy interne. En bref : utilisez un proxy auto-hébergé lorsque le contrôle et la propriété de la plateforme sont les principales exigences. Utilisez une passerelle API d'IA gérée lorsque l'équipe a besoin d'un accès multi-modèle plus rapide, de preuves de facturation, d'un examen de l'utilisation et d'une charge opérationnelle réduite.
Note sur la source : ce guide a été vérifié le 1er juillet 2026 par rapport aux pages publiques de Flatkey et à la documentation officielle de LiteLLM en tant que source représentative de proxy LLM auto-hébergé. Le packaging des produits, les catalogues de modèles, les guides de déploiement, les prix, le support des fournisseurs, les budgets et le comportement de routage peuvent changer. Utilisez ceci comme une liste de contrôle pour l'acheteur, puis vérifiez la console, la documentation, le contrat et la route actuels avant la mise en production.
Réponse rapide : passerelle API d'IA gérée vs proxy LLM auto-hébergé
Choisissez une passerelle API d'IA gérée lorsque votre problème immédiat est un accès unifié à l'IA avec des preuves de facturation et opérationnelles exploitables. Flatkey correspond à cette approche car ses pages publiques le positionnent autour d'une passerelle unique pour l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation, les contrôles opérationnels, le solde prépayé, les journaux de requêtes, le contrôle des coûts et une facture unique pour tous les fournisseurs.
Choisissez un proxy LLM auto-hébergé lorsque votre équipe de plateforme souhaite intentionnellement exploiter la couche de passerelle. Une option représentative telle que LiteLLM décrit un proxy auto-hébergé compatible avec OpenAI avec des clés virtuelles, des budgets par clé/équipe/utilisateur, une journalisation centralisée, des garde-fous, une mise en cache, un routage, un repli, une répartition de charge, une interface d'administration, un suivi des dépenses et des contrôles d'accès aux modèles. Ce sont de vrais contrôles. Ils créent également un vrai travail de prise en charge.
| Situation de l'acheteur | Quoi comparer en premier | Direction probable |
|---|---|---|
| Vous avez besoin rapidement d'une clé hébergée unique, d'un solde unique, de journaux de requêtes et d'une visibilité sur l'utilisation pour la finance. | URL de base, catalogue de modèles, solde prépayé, coût des journaux de requêtes, processus de facturation et flux de travail des quotas. | Évaluez Flatkey comme la voie de la passerelle API d'IA gérée. |
| Vous voulez être propriétaire du déploiement de la passerelle, de la configuration des modèles, de la politique d'accès, des journaux et des intégrations personnalisées. | Architecture du proxy, base de données, secrets, SSO, clés virtuelles, limites de débit, routage, observabilité et responsables des incidents. | Un proxy LLM auto-hébergé pourrait mieux convenir. |
| Votre équipe dispose déjà de la capacité de plateforme pour Kubernetes, Postgres, Redis, la gestion des secrets et les astreintes. | Runbook opérationnel, cadence de mise à niveau, plan de sauvegarde, base de données des coûts, modèle d'authentification et voie de support. | L'auto-hébergement peut justifier le contrôle supplémentaire. |
| Les développeurs doivent valider un flux de travail compatible avec OpenAI cette semaine sans intégration distincte des fournisseurs. | URL de base Flatkey actuelle, alias de modèle, propriétaire de la clé API, ligne d'utilisation, propriétaire du solde et diff de restauration. | Une passerelle API d'IA gérée constitue le pilote nécessitant le moins de configuration. |
Ce pour quoi une passerelle API d'IA gérée est conçue
Une passerelle API d'IA gérée est conçue pour réduire la quantité d'infrastructure de passerelle que l'acheteur doit assembler avant que le trafic des modèles puisse circuler. L'acheteur doit toujours effectuer un examen de sécurité, gérer la propriété des clés, nommer les charges de travail, tester les routes, examiner les coûts et effectuer des restaurations. La différence est que l'accès au fournisseur, la surface de routage hébergée, les enregistrements d'utilisation, le flux de facturation et la voie de support sont fournis sous forme de service au lieu de devenir un projet de plateforme interne.
La page d'accueil de Flatkey consultée pour ce guide est intitulée One API gateway for production AI teams. Sa méta-description indique que flatkey.ai unifie l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels pour les équipes qui livrent des produits d'IA. Ce positionnement public est important car la tâche de l'acheteur n'est pas seulement d'« envoyer une complétion de chat ». Il s'agit de prouver qui est responsable des dépenses, quelle requête a utilisé quel modèle et comment l'équipe examine les preuves opérationnelles.
La page de tarification de Flatkey consultée le même jour est intitulée Transparent AI model pricing et décrit les options d'accès aux modèles, de routage et de facturation pour les charges de travail d'IA en production. Elle indique que les forfaits en libre-service sont des recharges prépayées, que le solde est consommé lorsque les requêtes API utilisent des modèles, et qu'un seul solde peut router vers les modèles GPT, Claude, Gemini, DeepSeek, d'image, d'audio et de vidéo via une passerelle unique compatible avec OpenAI. Elle indique également que l'utilisation est mesurée par modèle, type de jeton et journaux de requêtes afin que les équipes puissent examiner les dépenses et contrôler les coûts.
Le répertoire de modèles de Flatkey, vérifié le 1er juillet 2026, indique qu'il publie une tarification rendue côté serveur pour 629 modèles d'IA provenant de 23 fournisseurs. La page expose les noms des modèles, les fournisseurs, les types de points de terminaison, les champs de disponibilité et les informations de tarification en HTML explorable. Sa carte de points de terminaison inclut les routes Anthropic Messages, Gemini, de génération d'images, OpenAI Chat Completions, OpenAI Responses et OpenAI video. Considérez ces chiffres comme une preuve de catalogue public datée, et non comme une garantie que chaque compte peut appeler chaque route sans une vérification actuelle de la clé et de la route.
Cela fait de Flatkey une option pratique de passerelle API d'IA gérée lorsque votre équipe souhaite un chemin d'évaluation unique pour le code de l'application, les finances et les opérations. Le projet pilote peut commencer avec une URL de base actuelle depuis la console, une clé API Flatkey, un alias de modèle sélectionné, une requête mesurée, l'examen du journal des requêtes, l'examen des coûts et une note de décision.
À quoi sert un proxy LLM auto-hébergé
Un proxy LLM auto-hébergé est conçu pour les équipes qui souhaitent posséder la couche de passerelle. La documentation officielle de LiteLLM décrit le proxy comme une passerelle auto-hébergée compatible avec OpenAI, où tout client qui fonctionne avec OpenAI peut fonctionner avec le proxy. La documentation décrit également LiteLLM comme une bibliothèque et une passerelle open source qui fournit une interface unifiée à plus de 100 LLM utilisant le format OpenAI.
La documentation du proxy de LiteLLM énumère la surface opérationnelle qui rend l'auto-hébergement attrayant : clés virtuelles avec budgets par clé, par équipe et par utilisateur ; journalisation centralisée ; garde-fous ; mise en cache ; une interface utilisateur d'administration ; suivi des dépenses ; routage et équilibrage de charge ; modèles de secours ; et contrôles d'accès aux modèles. La documentation sur les clés virtuelles indique que les équipes peuvent suivre les dépenses et contrôler l'accès aux modèles via des clés virtuelles, avec une interface utilisateur pour la génération de clés et le SSO.
Cette même documentation montre pourquoi le terme « auto-hébergé » est important. Pour les flux de travail de clés virtuelles et de budgets, LiteLLM nécessite la configuration d'une base de données. Le tutoriel Docker indique que les utilisateurs de Docker ou de la CLI ont besoin d'une base de données Postgres pour générer des clés, des utilisateurs et des équipes, et il montre un paramètre database_url dans config.yaml ou une variable d'environnement DATABASE_URL. Il nécessite également une clé principale pour l'administration du proxy.
Les contrôles budgétaires peuvent être sophistiqués. La documentation de LiteLLM sur les budgets et les limites de débit décrit les budgets personnels, les budgets d'équipe, les budgets des membres de l'équipe et les budgets des agents. La même page couvre les limites RPM et TPM, les durées de budget, les limites de débit par utilisateur ou par clé, les limites spécifiques aux modèles et une erreur attendue de dépassement de budget pour les dépenses de l'équipe. La documentation sur l'architecture décrit la validation des clés virtuelles, les vérifications de budget, la limitation de débit, les vérifications du cache Redis ou en mémoire, la redirection par le routeur LiteLLM, les rappels de journalisation et les mises à jour des dépenses dans la base de données.
Ces contrôles peuvent être exactement ce que recherche une organisation de plateforme. Mais ils ne sont pas gratuits simplement parce que le logiciel est open source. L'équipe doit gérer le proxy, la base de données, les secrets, les comptes des fournisseurs, le pipeline de déploiement, l'observabilité, la politique budgétaire, les mises à niveau et le processus de gestion des incidents. Une comparaison équitable des passerelles API d'IA gérées doit respecter le contrôle tout en évaluant le coût de possession.
Matrice de comparaison : coût, contrôle et opérations
La décision la plus solide provient de la comparaison des preuves opérationnelles pour le même flux de travail. Demandez aux deux approches de présenter le chemin de la requête, le chemin de la facturation, le chemin du quota, le chemin du journal et le responsable du support.
| Domaine de décision | Preuves à demander pour une passerelle API d'IA gérée | Preuves à demander pour un proxy LLM auto-hébergé | Pourquoi c'est important |
|---|---|---|---|
| Modèle de coût | Recharge prépayée, ligne de prix du modèle actuel, coût du journal des requêtes, impact sur le solde, chemin de facturation et propriétaire de la facturation. | Hébergement cloud, base de données, cache, observabilité, temps d'ingénierie, factures des fournisseurs en amont et couverture du support. | L'auto-hébergement peut éviter la majoration de la passerelle du fournisseur mais ajoute des coûts d'infrastructure et de main-d'œuvre. |
| Contrôle | Permissions de l'espace de travail, propriétaire de la clé, alias de modèle, groupes de fournisseurs, état de la route et chemin de support. | Fichiers de configuration, identifiants du fournisseur, clés virtuelles, politique d'authentification, gestionnaire de secrets, base de données et hooks personnalisés. | Plus de contrôle n'est utile que lorsque l'équipe peut assumer la responsabilité des décisions et des modes de défaillance. |
| Accès au fournisseur | Liste des modèles activés pour le compte, famille de points de terminaison, catalogue de modèles actuel et preuve de route au niveau de la requête. | Comptes de fournisseurs en amont, clés API des fournisseurs, configurations de modèles, cibles de repli et paramètres spécifiques au fournisseur. | La propriété de l'accès détermine l'approvisionnement, la réponse aux incidents, les limites de débit et la rotation des clés. |
| Routage et repli | Alias de modèle sélectionné, famille de points de terminaison, état de la route, forme de la réponse, format d'erreur et attentes en matière de repli. | Configuration du routeur, règle d'équilibrage de charge, politique de nouvelle tentative, chaîne de repli, comportement du cache et journalisation des échecs. | Les affirmations de routage nécessitent une preuve au niveau de la requête avant que le trafic de production ne soit déplacé. |
| Budgets et quotas | Solde prépayé, contrôles de quota, contrôles des coûts, analyses d'utilisation, journaux de requêtes et chemin d'escalade du propriétaire. | Budget de clé virtuelle, budget d'équipe, limites de débit, règles RPM/TPM, limites spécifiques au modèle et comportement en cas de dépassement de budget. | Un quota n'est utile que si les équipes savent s'il bloque, alerte, se replie ou nécessite une action manuelle. |
| Journaux et analyses | Journaux de requêtes, champs de modèle et de jeton, visibilité des coûts, analyses d'utilisation, état de la route et besoins d'exportation. | Mises à jour des dépenses de la base de données du proxy, rappels de journalisation, intégration d'observabilité externe, rétention et contrôles d'accès. | Le débogage, l'examen financier et l'examen de sécurité dépendent des champs visibles après une requête. |
| Effort de migration | Changement d'URL de base compatible OpenAI, clé API Flatkey, mappage d'alias de modèle, test de fumée, examen de l'utilisation et diff de restauration. | Déploiement du proxy, configuration de la base de données, clé principale, configuration du fournisseur, clés virtuelles, authentification, routage, surveillance et runbooks. | Une petite modification du SDK peut cacher un grand projet de plateforme. |
| Responsable des opérations | Support du fournisseur, administrateur de l'espace de travail, propriétaire de la facturation, propriétaire de la clé et propriétaire de la vérification de la production. | Astreinte de la plateforme, propriétaire de la base de données, propriétaire des secrets, propriétaire des mises à niveau, propriétaire de la politique et propriétaire de l'escalade fournisseur. | La voie gagnante est celle que votre organisation peut exploiter de manière fiable. |
Quand un proxy LLM auto-hébergé est-il la meilleure solution ?
Un proxy LLM auto-hébergé est probablement la meilleure solution lorsque votre équipe de plateforme a besoin d'un contrôle approfondi sur le chemin des requêtes. Cela inclut l'authentification personnalisée, la politique de routage personnalisée, les exigences internes du gestionnaire de secrets, le déploiement spécifique à une région, les contrôles de réseau privé, les rappels d'observabilité personnalisés, une architecture stricte de résidence des données et des règles de refacturation interne qui doivent résider au sein de votre plateforme.
L'auto-hébergement convient également lorsque l'organisation dispose déjà d'une capacité opérationnelle. Si votre équipe gère régulièrement Postgres, Redis, Kubernetes ou des services de conteneurs, la rotation des secrets, le SSO, les pipelines de journalisation, la réponse aux incidents et les fenêtres de mise à niveau, la responsabilité supplémentaire peut être acceptable. Dans ce cas, le proxy devient un autre composant de la plateforme plutôt qu'un outil ponctuel.
Enfin, un proxy auto-hébergé peut être judicieux lorsque la passerelle elle-même fait partie de l'architecture de votre produit. Si vous devez exposer l'accès à l'IA à de nombreuses équipes internes avec des clés personnalisées, des restrictions de modèle personnalisées, des budgets par équipe, des attentes en matière d'audit et une politique de routage contrôlée par vos propres ingénieurs, la configuration supplémentaire peut offrir un avantage utile.
Quand Flatkey devrait-il être sur votre liste de sélection ?
Flatkey devrait être sur votre liste de sélection lorsque l'équipe souhaite une passerelle API d'IA gérée plutôt qu'un projet d'opérations de passerelle. Les cas d'utilisation les plus pertinents sont les flux de travail de produits multi-modèles, l'automatisation interne, les agents, les outils de codage et les projets pilotes examinés par le service financier où les questions clés sont : quelle clé a envoyé la requête, quel modèle l'a servie, combien cela a-t-il coûté, où se trouve le journal et qui approuve la prochaine étape d'utilisation ?
Flatkey est également pertinent lorsque le chemin de migration est compatible avec OpenAI. Au lieu de déployer un proxy, de provisionner une base de données, de définir une clé principale, de configurer des fournisseurs en amont, d'émettre des clés virtuelles et de connecter les journaux avant qu'un développeur puisse tester un seul flux de travail, le projet pilote Flatkey peut commencer avec une URL de base, une clé API, un alias de modèle, un test de requête, un examen de l'utilisation et une note de restauration.
L'acheteur doit tout de même vérifier l'état actuel du compte. Avant la mise en production, vérifiez l'URL de base de la console Flatkey, la famille de points de terminaison, l'alias de modèle sélectionné, la ligne de tarification du modèle, les autorisations du compte, les journaux de requêtes, les champs de coût, le comportement du quota, le propriétaire du solde et le chemin de support. L'argument utile n'est pas qu'un service géré supprime tout le travail de vérification. C'est que le travail de vérification commence plus près du flux de travail de l'IA et plus loin de l'assemblage de la passerelle.
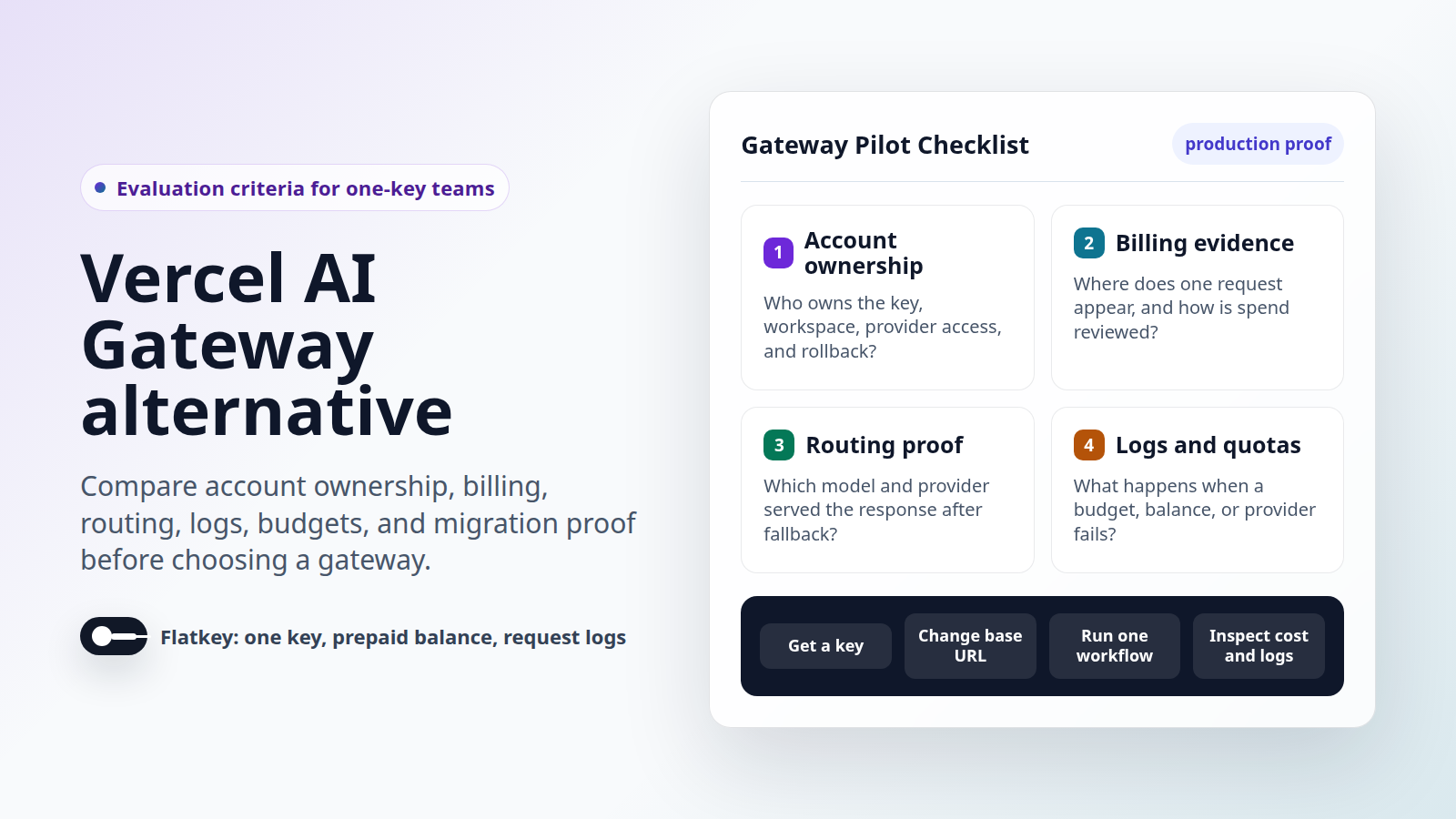
Liste de contrôle du projet pilote pour le même flux de travail
Utilisez cette liste de contrôle avant de choisir une passerelle API d'IA gérée ou un proxy LLM auto-hébergé. Elle permet de fonder la décision sur des preuves que les développeurs, les propriétaires de plateformes, les services financiers et les achats peuvent examiner.
- Nommez un flux de travail. Choisissez un agent de support, un assistant de codage, une tâche par lots, un flux de travail image/vidéo ou un chemin d'automatisation interne. N'évaluez pas l'ensemble de vos modèles en une seule fois.
- Gelez la route actuelle. Enregistrez le fournisseur actuel, le propriétaire de la clé, le modèle, le point de terminaison, la forme de la requête, le comportement des nouvelles tentatives, l'utilisation moyenne et le propriétaire du retour en arrière (rollback).
- Cartographiez la propriété des comptes. Pour Flatkey, identifiez l'espace de travail, le propriétaire de la clé API, le propriétaire du solde, l'alias du modèle, le groupe de fournisseurs et les examinateurs des journaux de requêtes. Pour l'auto-hébergement, identifiez le propriétaire du proxy, les comptes des fournisseurs, le propriétaire de la base de données, le propriétaire des secrets, le propriétaire de la clé virtuelle et le propriétaire de l'astreinte.
- Exécutez une requête minimale. Capturez le statut, la forme de la réponse, le modèle utilisé, les champs d'utilisation, le format d'erreur, la latence et vérifiez si la requête apparaît dans le journal attendu.
- Effectuez un test de budget. Confirmez la portée de la limite, la fenêtre de réinitialisation, le comportement d'application, le chemin d'alerte et qui agit lorsque la limite est atteinte.
- Effectuez un test de facturation. Confirmez l'unité de coût, la source du prix, le coût de la requête, l'impact sur le solde ou la facture du fournisseur, le chemin de facturation et le propriétaire de la révision financière.
- Effectuez un test de défaillance. Simulez un modèle invalide, un échec d'authentification, une limite de débit en amont, une erreur du fournisseur, un budget épuisé et un repli (fallback). Enregistrez ce qui se passe et qui est notifié.
- Rédigez la note de décision (go/no-go). Incluez la différence de code exacte, la différence de variable d'environnement, la preuve de la route, la preuve du journal, la preuve de la facturation, la cartographie des propriétaires et le chemin de retour en arrière.
Modèle de coût : ne comparez pas uniquement les frais des fournisseurs
La comparaison des coûts est l'étape où les équipes créent souvent la mauvaise feuille de calcul. Un proxy auto-hébergé peut sembler moins cher si le seul poste de dépense est le logiciel de la passerelle. Un modèle juste inclut également le calcul, la base de données, le cache, l'observabilité, la revue de sécurité, le temps de configuration par l'ingénierie, l'astreinte, la gestion des incidents, les mises à niveau et l'administration des comptes fournisseurs. Si ces coûts sont déjà absorbés par une équipe de plateforme, l'auto-hébergement peut rester efficace. S'il s'agit de nouvelles tâches, elles doivent être comptabilisées.
Une passerelle API d'IA gérée a une structure de coûts différente. L'acheteur doit examiner la tarification des modèles, le solde prépayé, le coût des journaux de requêtes, le comportement de facturation et toutes les conditions spécifiques au compte. La valeur ne réside pas seulement dans un poste de dépense inférieur. Elle consiste à réduire le nombre de systèmes qu'une équipe doit assembler avant que les services financiers et opérationnels puissent faire confiance au flux de travail.
Si vous comparez également des produits de passerelle nommés, utilisez la même norme de preuve. Les guides sur les alternatives à OpenRouter, les alternatives à LiteLLM et la liste de contrôle pour les passerelles API d'IA d'entreprise se concentrent tous sur la propriété des comptes, la facturation, la preuve de routage, les journaux, les quotas, l'effort de migration et les preuves opérationnelles. Utilisez la tarification de Flatkey pour la page actuelle d'accès aux modèles et de facturation, puis obtenez une clé lorsque vous êtes prêt à lancer un pilote mesuré.
FAQ
Qu'est-ce qu'une passerelle API d'IA gérée ?
Une passerelle API d'IA gérée est une couche d'accès hébergée pour le trafic des modèles d'IA. Elle fournit généralement aux équipes une surface d'API partagée, le routage des modèles, la visibilité de l'utilisation, un flux de travail de facturation et des contrôles opérationnels sans que l'acheteur n'ait à déployer et à exploiter lui-même l'infrastructure de la passerelle.
Un proxy LLM auto-hébergé est-il moins cher qu'une passerelle API d'IA gérée ?
Parfois, mais seulement si votre équipe peut absorber l'infrastructure et la main-d'œuvre. L'auto-hébergement peut réduire la dépendance à l'égard d'un fournisseur de passerelle et augmenter le contrôle, mais il ajoute des tâches de déploiement, de base de données, de gestion des secrets, d'observabilité, de mises à niveau et d'astreinte. Une passerelle API d'IA gérée intègre une plus grande partie de ce travail dans le service.
L'auto-hébergement offre-t-il plus de contrôle ?
Oui. Un proxy auto-hébergé offre généralement un contrôle plus approfondi sur les informations d'identification des fournisseurs, la politique de routage, les clés virtuelles, les budgets, les journaux et les intégrations. Le compromis est que votre équipe est propriétaire de ces contrôles en production. Plus de contrôle est précieux lorsque vous disposez également des personnes et des processus pour l'exploiter.
Flatkey peut-il remplacer tous les cas d'utilisation de proxy auto-hébergé ?
Non. Flatkey doit être évalué comme un modèle opérationnel alternatif, pas comme un clone de chaque proxy. Si vos exigences incluent une topologie de déploiement personnalisée, un réseau interne uniquement, des plugins d'authentification personnalisés ou une logique de routage propriétaire, l'auto-hébergement peut être plus adapté. Si votre priorité est un accès multi-modèles géré avec des preuves de facturation et d'utilisation, évaluez Flatkey.
Comment le service financier doit-il évaluer le choix ?
Le service financier doit demander un flux de travail concret et le suivre de la requête à la facture. Confirmez les requêtes mensuelles attendues, la combinaison de modèles, les types de jetons, les nouvelles tentatives, les replis, le comportement des quotas, le chemin de facturation, l'impact sur le solde ou la facture du fournisseur, l'accès aux journaux et le propriétaire de l'approbation. Une liste de fonctionnalités ne suffit pas.
Que doivent tester les développeurs avant la migration ?
Les développeurs doivent tester l'URL de base exacte, la clé API, l'alias du modèle, la famille de points de terminaison, le comportement du streaming, le comportement des outils, le format d'erreur, le comportement du délai d'attente, les champs d'utilisation et le chemin de retour en arrière. Une seule requête de chat réussie ne prouve pas que l'ensemble du flux de travail est prêt pour la production.
Règle de décision finale
Choisissez un proxy LLM auto-hébergé lorsque la couche de passerelle est une infrastructure stratégique que votre équipe de plateforme souhaite posséder. Choisissez une passerelle API d'IA gérée lorsque votre équipe souhaite une clé unique, un accès compatible avec OpenAI, une tarification des modèles publiée, un solde prépayé, des analyses d'utilisation, des journaux de requêtes, des contrôles de coûts et un chemin plus rapide pour valider les flux de travail des modèles.
Pour tester Flatkey dans ce modèle d'exploitation géré, consultez la tarification et l'accès aux modèles actuels, puis obtenez une clé et exécutez un workflow mesuré avant de transférer un trafic plus important.