Un gateway de API de IA gestionado y un proxy LLM autohospedado pueden poner un único punto de conexión (endpoint) frente a múltiples proveedores de modelos. Esa similitud es donde se detienen muchas listas de verificación de los compradores. La decisión más difícil es quién es el propietario de las cuentas de los proveedores, las claves ascendentes (upstream), la aplicación del presupuesto, los registros de solicitudes, el enrutamiento de modelos, la evidencia de costos, las actualizaciones, los incidentes y la revisión financiera después de que la primera solicitud tenga éxito.
Esta comparación es para desarrolladores, equipos de productos de IA, creadores de automatización, ingenieros de plataforma, operadores financieros y revisores de adquisiciones que deciden si comprar un gateway de IA alojado o ejecutar una pila de proxy interna. La versión corta: utilice un proxy autohospedado cuando el control y la propiedad de la plataforma sean el requisito principal. Utilice un gateway de API de IA gestionado cuando el equipo necesite un acceso más rápido a múltiples modelos, evidencia de facturación, revisión del uso y una menor carga de operaciones.
Nota sobre la fuente: esta guía se verificó el 1 de julio de 2026 con las páginas públicas activas de Flatkey y la documentación oficial de LiteLLM como fuente representativa de un proxy LLM autohospedado. El empaquetado del producto, los catálogos de modelos, la guía de implementación, los precios, el soporte del proveedor, los presupuestos y el comportamiento del enrutamiento pueden cambiar. Utilice esto como una lista de verificación para compradores y luego verifique la consola, los documentos, el contrato y la ruta actuales antes del paso a producción.
Respuesta rápida: gateway de API de IA gestionado vs. proxy LLM autohospedado
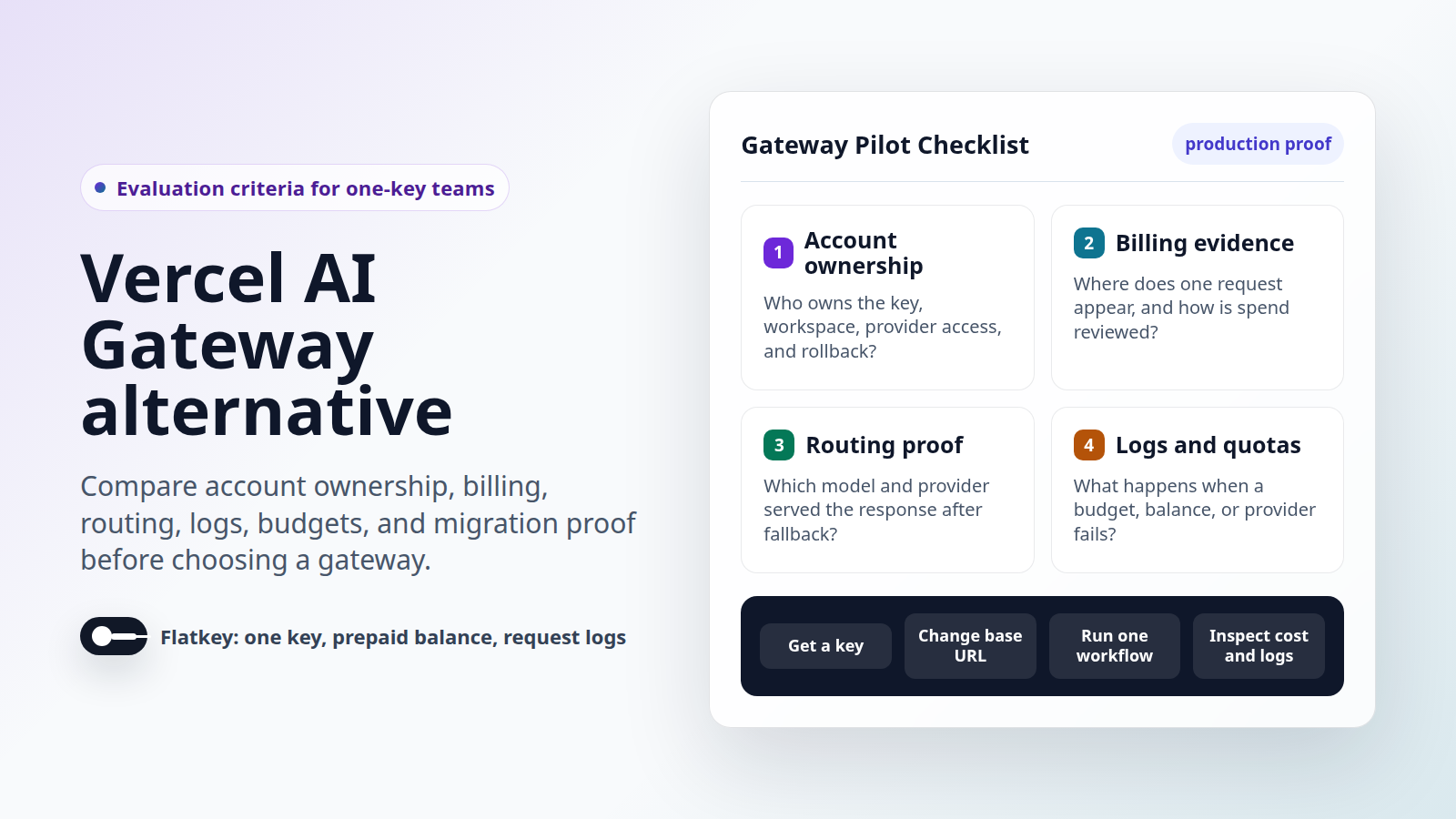
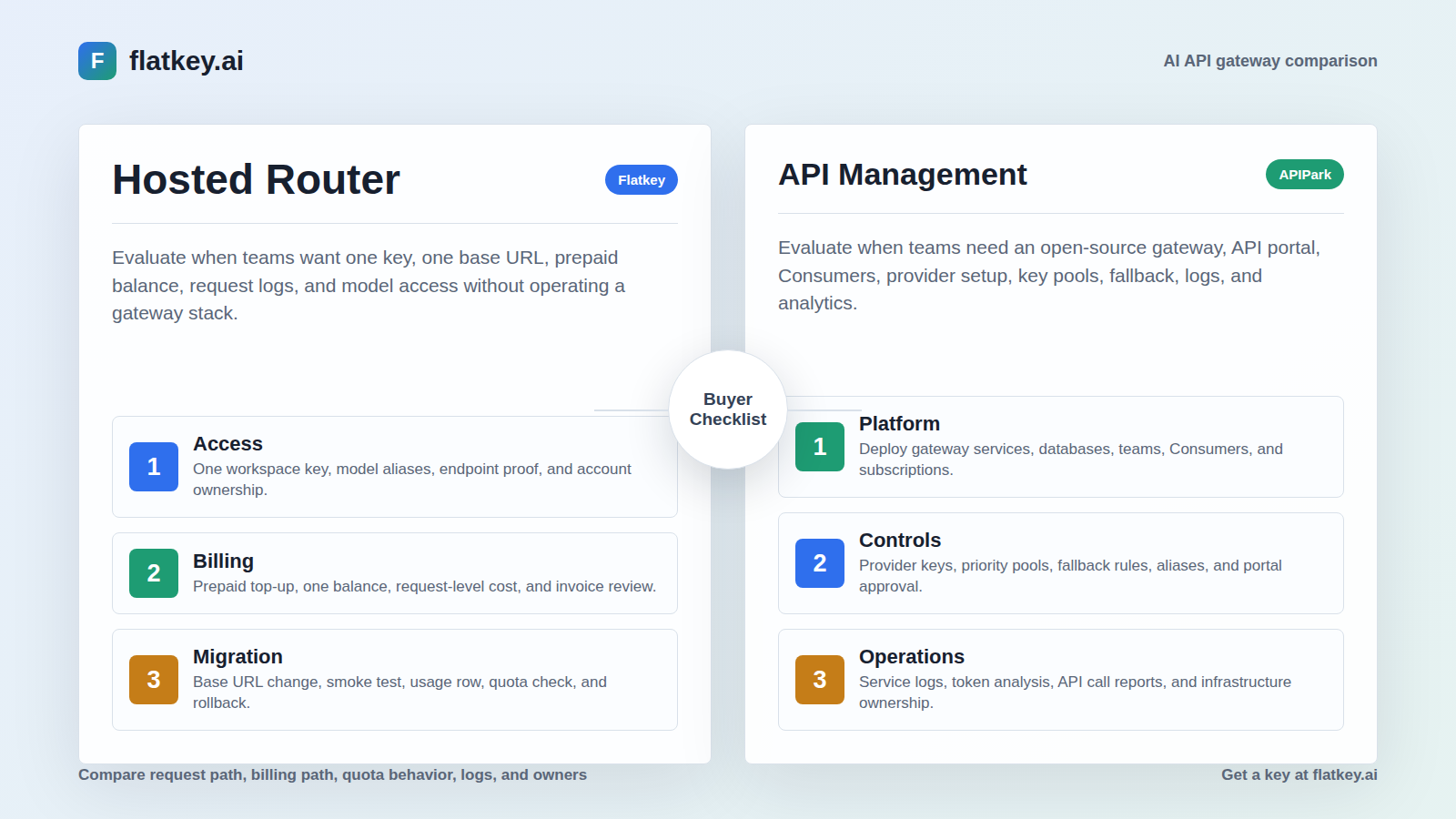
Elija un gateway de API de IA gestionado cuando su problema inmediato sea el acceso unificado a la IA con evidencia operativa y de facturación utilizable. Flatkey encaja en ese camino porque sus páginas públicas lo posicionan en torno a un único gateway para el acceso a modelos, enrutamiento, facturación, análisis de uso, controles operativos, saldo prepago, registros de solicitudes, controles de costos y una única factura para todos los proveedores.
Elija un proxy LLM autohospedado cuando su equipo de plataforma quiera operar intencionadamente la capa del gateway. Una opción representativa como LiteLLM describe un proxy autohospedado compatible con OpenAI con claves virtuales, presupuestos por clave/equipo/usuario, registro centralizado, barreras de protección (guardrails), almacenamiento en caché, enrutamiento, respaldo (fallback), balanceo de carga, interfaz de administración, seguimiento de gastos y controles de acceso a modelos. Esos son controles reales. También crean un trabajo de propiedad real.
| Situación del comprador | Qué comparar primero | Dirección probable |
|---|---|---|
| Necesita rápidamente una clave alojada, un saldo, registros de solicitudes y un uso visible para el área de finanzas. | URL base, catálogo de modelos, saldo prepago, costo del registro de solicitudes, ruta de facturación y flujo de trabajo de cuotas. | Evalúe Flatkey como la opción de gateway de API de IA gestionado. |
| Quiere ser propietario de la implementación del gateway, la configuración del modelo, la política de acceso, los registros y las integraciones personalizadas. | Arquitectura del proxy, base de datos, secretos, SSO, claves virtuales, límites de velocidad, enrutamiento, observabilidad y propietarios de incidentes. | Un proxy LLM autohospedado puede encajar mejor. |
| Su equipo ya tiene capacidad de plataforma para Kubernetes, Postgres, Redis, gestión de secretos y guardias (on-call). | Manual de operaciones (runbook), cadencia de actualización, plan de respaldo, base de datos de costos, modelo de autenticación y ruta de soporte. | El autohospedaje puede justificar el control adicional. |
| Los desarrolladores necesitan validar un flujo de trabajo compatible con OpenAI esta semana sin un proceso de incorporación (onboarding) de proveedores por separado. | URL base actual de Flatkey, alias del modelo, propietario de la clave de API, fila de uso, propietario del saldo y diferencia de reversión (rollback diff). | Un gateway de API de IA gestionado es el piloto con menor configuración. |
Para qué está diseñado un gateway de API de IA gestionado
Un gateway de API de IA gestionado está diseñado para reducir la cantidad de infraestructura de gateway que el comprador tiene que montar antes de que el tráfico del modelo pueda fluir. El comprador todavía necesita una revisión de seguridad, propiedad de la clave, nomenclatura de la carga de trabajo, pruebas de ruta, revisión de costos y reversión (rollback). La diferencia es que el acceso al proveedor, la superficie de enrutamiento alojada, los registros de uso, el flujo de trabajo de facturación y la ruta de soporte se empaquetan como un servicio en lugar de convertirse en un proyecto de plataforma interna.
La página de inicio de Flatkey consultada para esta guía se titula One API gateway for production AI teams. Su metadescripción dice que flatkey.ai unifica el acceso a modelos, el enrutamiento, la facturación, el análisis de uso y los controles operativos para los equipos que lanzan productos de IA. Ese posicionamiento público es importante porque la tarea del comprador no es solo "enviar una finalización de chat". Es demostrar quién es el propietario del gasto, qué solicitud utilizó qué modelo y cómo el equipo revisa la evidencia operativa.
La página de precios de Flatkey consultada el mismo día se titula Transparent AI model pricing y describe las opciones de acceso a modelos, enrutamiento y facturación para cargas de trabajo de IA en producción. Indica que los planes de autoservicio son recargas prepagas, que el saldo se consume cuando las solicitudes de API utilizan modelos y que un único saldo puede enrutar a través de los modelos GPT, Claude, Gemini, DeepSeek, de imagen, audio y video a través de un único gateway compatible con OpenAI. También indica que el uso se mide por modelo, tipo de token y registros de solicitudes para que los equipos puedan revisar el gasto y controlar los costos.
El directorio de modelos de Flatkey, consultado el 1 de julio de 2026, indica que publica precios de modelos renderizados en el servidor para 629 modelos de IA de 23 proveedores. La página expone los nombres de los modelos, los proveedores, los tipos de punto de conexión (endpoint), los campos de disponibilidad y la información de precios en HTML rastreable. Su mapa de puntos de conexión incluye rutas para Anthropic Messages, Gemini, generación de imágenes, OpenAI Chat Completions, OpenAI Responses y video de OpenAI. Considere esos recuentos como evidencia de un catálogo público con fecha, no como una garantía de que cada cuenta pueda llamar a cada ruta sin una verificación actual de la clave y la ruta.
Eso convierte a Flatkey en una opción práctica de gateway de API de IA gestionado cuando su equipo quiere una única ruta de evaluación para el código de la aplicación, las finanzas y las operaciones. La prueba piloto puede comenzar con una URL base actual de la consola, una clave de API de Flatkey, un alias de modelo seleccionado, una solicitud medida, la revisión del registro de solicitudes, la revisión de costos y una nota de aprobación/rechazo.
Para qué está diseñado un proxy LLM autohospedado
Un proxy LLM autohospedado está diseñado para equipos que quieren ser dueños de la capa de gateway. La documentación oficial de LiteLLM describe el proxy como un gateway autohospedado compatible con OpenAI donde cualquier cliente que funcione con OpenAI puede funcionar con el proxy. La documentación también describe LiteLLM como una biblioteca y un gateway de código abierto que proporciona una interfaz unificada para más de 100 LLM utilizando el formato de OpenAI.
La documentación del proxy de LiteLLM enumera la superficie operativa que hace atractivo el autohospedaje: claves virtuales con presupuestos por clave, equipo y usuario; registro centralizado; barreras de seguridad (guardrails); almacenamiento en caché; una interfaz de usuario de administrador; seguimiento de gastos; enrutamiento y balanceo de carga; modelos de respaldo; y controles de acceso a modelos. La documentación de las claves virtuales dice que los equipos pueden hacer un seguimiento de los gastos y controlar el acceso a los modelos a través de claves virtuales, con una interfaz de usuario para la generación de claves y SSO.
La misma documentación muestra por qué la palabra "autohospedado" es importante. Para los flujos de trabajo de claves virtuales y presupuestos, LiteLLM requiere la configuración de una base de datos. El tutorial de Docker dice que los usuarios de Docker o CLI necesitan una base de datos Postgres para generar claves, usuarios y equipos, y muestra una configuración database_url en config.yaml o una variable de entorno DATABASE_URL. También requiere una clave maestra para la administración del proxy.
Los controles de presupuesto pueden ser sofisticados. La documentación de presupuestos y límites de velocidad de LiteLLM describe presupuestos personales, presupuestos de equipo, presupuestos de miembros del equipo y presupuestos de agente. La misma página cubre los límites de RPM y TPM, la duración de los presupuestos, los límites de velocidad por usuario o clave, los límites específicos del modelo y un error esperado de presupuesto excedido para el gasto del equipo. La documentación de la arquitectura describe la validación de claves virtuales, las comprobaciones de presupuesto, la limitación de velocidad, las comprobaciones de caché en memoria o Redis, el reenvío del enrutador de LiteLLM, las devoluciones de llamada de registro y las actualizaciones de gastos en la base de datos.
Esos controles pueden ser exactamente lo que una organización de plataforma desea. Pero no son gratuitos solo porque el software sea de código abierto. El equipo debe operar el proxy, la base de datos, los secretos, las cuentas de proveedor, el pipeline de despliegue, la observabilidad, la política de presupuesto, las actualizaciones y el proceso de incidentes. Una comparación justa de un gateway de API de IA gestionado debe respetar el control al tiempo que valora el costo de propiedad.
Matriz de comparación: costo, control y operaciones
La decisión más sólida proviene de comparar la evidencia operativa para el mismo flujo de trabajo. Pida a ambas vías que muestren la ruta de la solicitud, la ruta de facturación, la ruta de la cuota, la ruta del registro y el responsable del soporte.
| Área de decisión | Evidencia a solicitar para un gateway de API de IA gestionado | Evidencia a solicitar para un proxy LLM autohospedado | Por qué es importante |
|---|---|---|---|
| Modelo de costo | Recarga prepaga, fila de precios del modelo actual, costo del registro de solicitudes, impacto en el saldo, ruta de la factura y propietario de la facturación. | Alojamiento en la nube, base de datos, caché, observabilidad, tiempo de ingeniería, facturas de proveedores upstream y cobertura de soporte. | El autohospedaje puede evitar el sobreprecio del gateway del proveedor, pero añade costos de infraestructura y mano de obra. |
| Control | Permisos del espacio de trabajo, propietario de la clave, alias de modelos, grupos de proveedores, estado de la ruta y ruta de soporte. | Archivos de configuración, credenciales de proveedor, claves virtuales, política de autenticación, gestor de secretos, base de datos y hooks personalizados. | Tener más control solo es útil cuando el equipo puede hacerse cargo de las decisiones y los modos de fallo. |
| Acceso a proveedores | Lista de modelos habilitados en la cuenta, familia de endpoints, catálogo de modelos actual y prueba de ruta a nivel de solicitud. | Cuentas de proveedores upstream, claves de API de proveedores, configuraciones de modelos, objetivos de fallback y parámetros específicos del proveedor. | La propiedad del acceso impulsa la adquisición, la respuesta a incidentes, los límites de tasa y la rotación de claves. |
| Enrutamiento y fallback | Alias del modelo seleccionado, familia de endpoints, estado de la ruta, forma de la respuesta, formato de error y expectativas de fallback. | Configuración del enrutador, regla de balanceo de carga, política de reintentos, cadena de fallback, comportamiento de la caché y registro de fallos. | Las afirmaciones sobre el enrutamiento necesitan una prueba a nivel de solicitud antes de mover el tráfico de producción. |
| Presupuestos y cuotas | Saldo prepago, controles de cuota, controles de costos, análisis de uso, registros de solicitudes y ruta de escalado al propietario. | Presupuesto de clave virtual, presupuesto de equipo, límites de tasa, reglas de RPM/TPM, límites específicos del modelo y comportamiento al exceder el presupuesto. | Una cuota solo es útil si los equipos saben si bloquea, alerta, utiliza un fallback o necesita una acción manual. |
| Registros y análisis | Registros de solicitudes, campos de modelo y token, visibilidad de costos, análisis de uso, estado de la ruta y necesidades de exportación. | Actualizaciones de gasto de la base de datos del proxy, callbacks de registro, integración con observabilidad externa, retención y controles de acceso. | La depuración, la revisión financiera y la revisión de seguridad dependen de los campos visibles después de una solicitud. |
| Esfuerzo de migración | Cambio de URL base compatible con OpenAI, clave de API de Flatkey, mapeo de alias de modelo, prueba de humo, revisión de uso y diff de reversión. | Implementación del proxy, configuración de la base de datos, clave maestra, configuración del proveedor, claves virtuales, autenticación, enrutamiento, monitoreo y runbooks. | Un pequeño cambio en el SDK puede ocultar un gran proyecto de plataforma. |
| Propietario de operaciones | Soporte del proveedor, administrador del espacio de trabajo, propietario de la facturación, propietario de la clave y propietario de la verificación de producción. | Guardia de la plataforma, propietario de la base de datos, propietario de los secretos, propietario de las actualizaciones, propietario de las políticas y propietario del escalado al proveedor. | El camino ganador es aquel que su organización puede operar de manera confiable. |
Cuándo es más adecuado un proxy LLM autohospedado
Un proxy LLM autohospedado es probablemente la mejor opción cuando su equipo de plataforma necesita un control profundo sobre la ruta de la solicitud. Esto incluye autenticación personalizada, política de enrutamiento personalizada, requisitos del gestor de secretos interno, implementación específica de la región, controles de red privada, callbacks de observabilidad personalizados, arquitectura estricta de residencia de datos y reglas de contracargo internas que deben residir dentro de su plataforma.
El autohospedaje también es adecuado cuando la organización ya tiene capacidad operativa. Si su equipo ejecuta habitualmente Postgres, Redis, Kubernetes o servicios de contenedores, rotación de secretos, SSO, pipelines de registro, respuesta a incidentes y ventanas de actualización, la responsabilidad adicional puede ser aceptable. En ese caso, el proxy se convierte en otro componente de la plataforma en lugar de una herramienta aislada.
Finalmente, un proxy autohospedado puede ser la opción correcta cuando el propio gateway forma parte de la arquitectura de su producto. Si necesita exponer el acceso a la IA a muchos equipos internos con claves personalizadas, restricciones de modelo personalizadas, presupuestos por equipo, expectativas de auditoría y una política de enrutamiento controlada por sus propios ingenieros, la configuración adicional puede proporcionar una ventaja útil.
Cuándo debería considerar Flatkey
Debería considerar Flatkey cuando el equipo quiera un gateway de API de IA gestionado en lugar de un proyecto de operaciones de gateway. Los casos de uso más sólidos son los flujos de trabajo de productos multimodelo, la automatización interna, los agentes, las herramientas de codificación y los pilotos revisados por finanzas donde las preguntas clave son: ¿qué clave envió la solicitud?, ¿qué modelo la atendió?, ¿cuánto costó?, ¿dónde está el registro? y ¿quién aprueba el siguiente paso de uso?
Flatkey también es relevante cuando la ruta de migración es compatible con OpenAI. En lugar de implementar un proxy, aprovisionar una base de datos, establecer una clave maestra, configurar proveedores upstream, emitir claves virtuales y conectar registros antes de que un desarrollador pueda probar un flujo de trabajo, el piloto de Flatkey puede comenzar con una URL base, una clave de API, un alias de modelo, una prueba de solicitud, una revisión de uso y una nota de reversión.
El comprador aún debe verificar el estado actual de la cuenta. Antes de la producción, verifique la URL base de la consola de Flatkey, la familia de endpoints, el alias del modelo seleccionado, la fila de precios del modelo, los permisos de la cuenta, los registros de solicitudes, los campos de costo, el comportamiento de la cuota, el propietario del saldo y la ruta de soporte. La afirmación útil no es que un servicio gestionado elimina todo el trabajo de revisión. Es que el trabajo de revisión comienza más cerca del flujo de trabajo de la IA y más lejos del ensamblaje del gateway.
Lista de verificación del piloto para el mismo flujo de trabajo
Utilice esta lista de verificación antes de elegir un gateway de API de IA gestionado o un proxy LLM autohospedado. Mantiene la decisión basada en evidencia que los desarrolladores, propietarios de plataformas, finanzas y adquisiciones pueden inspeccionar.
- Nombre un flujo de trabajo. Elija un agente de soporte, asistente de codificación, trabajo por lotes, flujo de trabajo de imagen/video o ruta de automatización interna. No evalúe todo el patrimonio de modelos a la vez.
- Congele la ruta actual. Registre el proveedor actual, el propietario de la clave, el modelo, el punto de conexión, la forma de la solicitud, el comportamiento de reintento, el uso promedio y el propietario de la reversión.
- Mapee la propiedad de la cuenta. Para Flatkey, identifique el espacio de trabajo, el propietario de la clave de API, el propietario del saldo, el alias del modelo, el grupo de proveedores y los revisores del registro de solicitudes. Para el autohospedaje, identifique el propietario del proxy, las cuentas de proveedor, el propietario de la base de datos, el propietario del secreto, el propietario de la clave virtual y el propietario de guardia.
- Ejecute una solicitud mínima. Capture el estado, la forma de la respuesta, el modelo utilizado, los campos de uso, el formato de error, la latencia y si la solicitud aparece en el registro esperado.
- Realice una prueba de presupuesto. Confirme el alcance del límite, la ventana de reinicio, el comportamiento de aplicación, la ruta de alerta y quién actúa cuando se alcanza el límite.
- Realice una prueba de facturación. Confirme la unidad de costo, la fuente del precio, el costo de la solicitud, el impacto en el saldo o en la factura del proveedor, la ruta de la factura y el propietario de la revisión financiera.
- Realice una prueba de fallos. Simule un modelo no válido, un fallo de autenticación, un límite de velocidad ascendente, un error del proveedor, un presupuesto agotado y una alternativa. Registre lo que sucede y a quién se notifica.
- Escriba la nota de aprobación/rechazo. Incluya la diferencia exacta del código, la diferencia de la variable de entorno, la prueba de la ruta, la prueba del registro, la prueba de la facturación, el mapa de propietarios y la ruta de reversión.
Modelo de costos: no compare solo las tarifas de los proveedores
La comparación de costos es donde los equipos a menudo se equivocan de hoja de cálculo. Un proxy autohospedado puede parecer más barato si la única partida es el software del gateway. Un modelo justo también incluye computación, base de datos, caché, observabilidad, revisión de seguridad, tiempo de configuración de ingeniería, guardias, manejo de incidentes, actualizaciones y administración de cuentas de proveedores. Si esos costos ya son absorbidos por un equipo de plataforma, el autohospedaje puede seguir siendo eficiente. Si son trabajo nuevo, deben contabilizarse.
Un gateway de API de IA gestionado tiene una forma de costo diferente. El comprador debe inspeccionar los precios de los modelos, el saldo prepago, el costo del registro de solicitudes, el comportamiento de la facturación y cualquier término específico de la cuenta. El valor no es solo una partida de menor costo. Es reducir el número de sistemas que un equipo debe ensamblar antes de que finanzas y operaciones puedan confiar en el flujo de trabajo.
Si también está comparando productos de gateway con nombre, utilice el mismo estándar de evidencia. Las guías de alternativas a OpenRouter, alternativas a LiteLLM y la lista de verificación del gateway de API de IA empresarial se centran en la propiedad de la cuenta, la facturación, la prueba de enrutamiento, los registros, las cuotas, el esfuerzo de migración y la evidencia operativa. Utilice los precios de Flatkey para el acceso al modelo actual y la página de facturación, y luego obtenga una clave cuando esté listo para ejecutar un piloto medido.
Preguntas frecuentes
¿Qué es un gateway de API de IA gestionado?
Un gateway de API de IA gestionado es una capa de acceso alojada para el tráfico de modelos de IA. Normalmente, proporciona a los equipos una superficie de API compartida, enrutamiento de modelos, visibilidad del uso, flujo de trabajo de facturación y controles operativos sin requerir que el comprador implemente y opere la infraestructura del gateway por sí mismo.
¿Es un proxy LLM autohospedado más barato que un gateway de API de IA gestionado?
A veces, pero solo si su equipo puede absorber la infraestructura y la mano de obra. El autohospedaje puede reducir la dependencia de un proveedor de gateway y aumentar el control, pero añade trabajo de implementación, base de datos, gestión de secretos, observabilidad, actualizaciones y guardias. Un gateway de API de IA gestionado empaqueta más de ese trabajo en el servicio.
¿El autohospedaje da más control?
Sí. Un proxy autohospedado suele dar un control más profundo sobre las credenciales del proveedor, la política de enrutamiento, las claves virtuales, los presupuestos, los registros y las integraciones. La contrapartida es que su equipo es el propietario de esos controles en producción. Más control es valioso cuando también se tienen las personas y el proceso para operarlo.
¿Puede Flatkey reemplazar todos los casos de uso de un proxy autohospedado?
No. Flatkey debe evaluarse como un modelo operativo alternativo, no como un clon de todos los proxies. Si sus requisitos incluyen una topología de implementación personalizada, redes solo internas, complementos de autenticación personalizados o lógica de enrutamiento propietaria, el autohospedaje puede ser la mejor opción. Si su prioridad es el acceso gestionado a múltiples modelos con evidencia de facturación y uso, evalúe Flatkey.
¿Cómo debería el departamento de finanzas evaluar la elección?
El departamento de finanzas debe solicitar un flujo de trabajo concreto y rastrearlo desde la solicitud hasta la factura. Confirme las solicitudes mensuales esperadas, la combinación de modelos, los tipos de tokens, los reintentos, las alternativas, el comportamiento de las cuotas, la ruta de la factura, el impacto en el saldo o en la factura del proveedor, el acceso a los registros y el propietario de la aprobación. Una lista de características no es suficiente.
¿Qué deben probar los desarrolladores antes de la migración?
Los desarrolladores deben probar la URL base exacta, la clave de API, el alias del modelo, la familia de puntos de conexión, el comportamiento de la transmisión, el comportamiento de la herramienta, el formato de error, el comportamiento del tiempo de espera, los campos de uso y la ruta de reversión. Una solicitud de chat exitosa no demuestra que todo el flujo de trabajo esté listo para producción.
Regla de decisión final
Elija un proxy LLM autohospedado cuando la capa de gateway sea una infraestructura estratégica que su equipo de plataforma quiera poseer. Elija un gateway de API de IA gestionado cuando su equipo quiera una clave única, acceso compatible con OpenAI, precios de modelos publicados, saldo prepago, análisis de uso, registros de solicitudes, controles de costos y una ruta más rápida para validar los flujos de trabajo de los modelos.
Para probar Flatkey en ese modelo operativo gestionado, consulta los precios y el acceso a los modelos actuales, luego obtén una clave y ejecuta un flujo de trabajo medido antes de mover un tráfico más amplio.