Um gateway de API de IA gerenciado e um proxy LLM auto-hospedado podem ambos colocar um endpoint na frente de vários provedores de modelos. Essa semelhança é onde muitas listas de verificação de compradores param. A decisão mais difícil é quem é o proprietário das contas de provedor, chaves upstream, aplicação de orçamento, logs de solicitação, roteamento de modelos, evidências de custo, atualizações, incidentes e revisão financeira após o sucesso da primeira solicitação.
Esta comparação é para desenvolvedores, equipes de produtos de IA, criadores de automação, engenheiros de plataforma, operadores financeiros e revisores de aquisições que estão decidindo se compram um gateway de IA hospedado ou executam uma pilha de proxy interna. A versão curta: use um proxy auto-hospedado quando o controle e a propriedade da plataforma forem o requisito principal. Use um gateway de API de IA gerenciado quando a equipe precisar de acesso mais rápido a vários modelos, evidências de faturamento, revisão de uso e uma carga operacional menor.
Nota da fonte: este guia foi verificado em 1 de julho de 2026 em comparação com as páginas públicas ativas da Flatkey e a documentação oficial do LiteLLM como uma fonte representativa de proxy LLM auto-hospedado. O empacotamento do produto, catálogos de modelos, orientação de implantação, preços, suporte do provedor, orçamentos e comportamento de roteamento podem mudar. Use isto como uma lista de verificação do comprador e, em seguida, verifique o console, a documentação, o contrato e a rota atuais antes da transição para a produção.
Resposta rápida: gateway de API de IA gerenciado vs. proxy LLM auto-hospedado
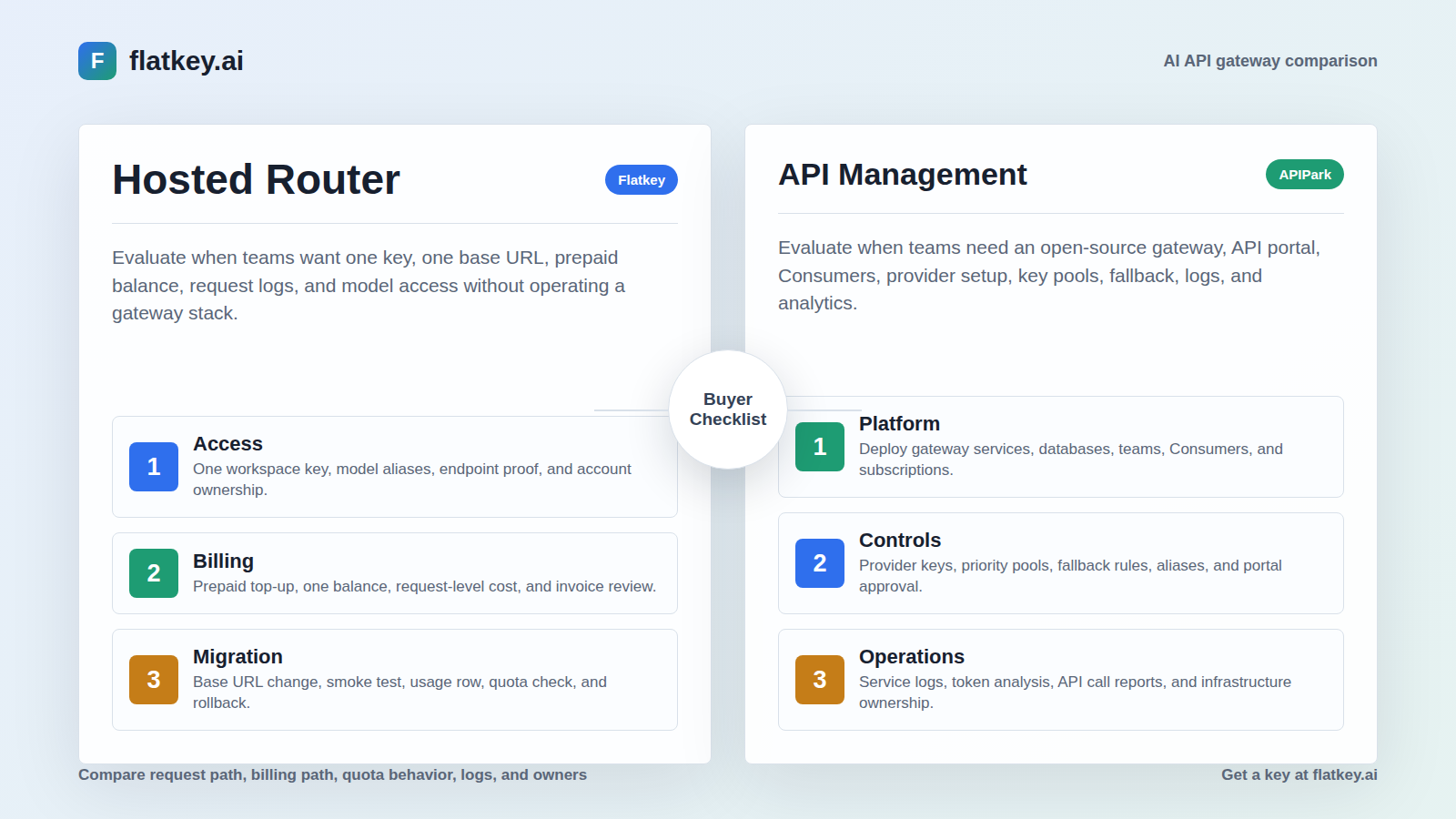
Escolha um gateway de API de IA gerenciado quando seu problema imediato for o acesso unificado à IA com evidências operacionais e de faturamento utilizáveis. A Flatkey se encaixa nesse caminho porque suas páginas públicas a posicionam em torno de um único gateway para acesso a modelos, roteamento, faturamento, análise de uso, controles operacionais, saldo pré-pago, logs de solicitação, controles de custo e uma única fatura para todos os provedores.
Escolha um proxy LLM auto-hospedado quando sua equipe de plataforma intencionalmente quiser operar a camada de gateway. Uma opção representativa como o LiteLLM descreve um proxy auto-hospedado compatível com OpenAI com chaves virtuais, orçamentos por chave/equipe/usuário, registro centralizado, guardrails, cache, roteamento, fallback, balanceamento de carga, interface de administração, rastreamento de gastos e controles de acesso a modelos. Esses são controles reais. Eles também criam um trabalho real de propriedade.
| Situação do comprador | O que comparar primeiro | Direção provável |
|---|---|---|
| Você precisa rapidamente de uma chave hospedada, um saldo, logs de solicitação e uso visível para o financeiro. | URL base, catálogo de modelos, saldo pré-pago, custo do log de solicitações, caminho da fatura e fluxo de trabalho de cotas. | Avalie a Flatkey como o caminho do gateway de API de IA gerenciado. |
| Você quer ser o proprietário da implantação do gateway, configuração do modelo, política de acesso, logs e integrações personalizadas. | Arquitetura do proxy, banco de dados, segredos, SSO, chaves virtuais, limites de taxa, roteamento, observabilidade e proprietários de incidentes. | Um proxy LLM auto-hospedado pode se encaixar melhor. |
| Sua equipe já tem capacidade de plataforma para Kubernetes, Postgres, Redis, gerenciamento de segredos e plantão (on-call). | Runbook operacional, cadência de atualização, plano de backup, banco de dados de custos, modelo de autenticação e caminho de suporte. | A auto-hospedagem pode justificar o controle adicional. |
| Os desenvolvedores precisam validar um fluxo de trabalho compatível com OpenAI esta semana sem integração separada com o provedor. | URL base atual da Flatkey, alias do modelo, proprietário da chave de API, linha de uso, proprietário do saldo e diff de reversão. | Um gateway de API de IA gerenciado é o piloto com menor configuração. |
Para que serve um gateway de API de IA gerenciado
Um gateway de API de IA gerenciado é construído para reduzir a quantidade de infraestrutura de gateway que o comprador precisa montar antes que o tráfego do modelo possa fluir. O comprador ainda precisa de revisão de segurança, propriedade da chave, nomeação da carga de trabalho, testes de rota, revisão de custos e reversão. A diferença é que o acesso ao provedor, a superfície de roteamento hospedada, os registros de uso, o fluxo de trabalho de faturamento e o caminho de suporte são empacotados como um serviço, em vez de se tornarem um projeto de plataforma interna.
A página inicial da Flatkey verificada para este guia tem o título One API gateway for production AI teams. Sua meta descrição diz que a flatkey.ai unifica o acesso a modelos, roteamento, faturamento, análise de uso e controles operacionais para equipes que enviam produtos de IA. Esse posicionamento público é importante porque a tarefa do comprador não é apenas "enviar uma conclusão de chat". É provar quem é o dono dos gastos, qual solicitação usou qual modelo e como a equipe analisa as evidências operacionais.
A página de preços da Flatkey verificada no mesmo dia tem o título Transparent AI model pricing e descreve as opções de acesso a modelos, roteamento e faturamento para cargas de trabalho de IA de produção. Ela diz que os planos de autoatendimento são recargas pré-pagas, que o saldo é consumido quando as solicitações de API usam modelos e que um único saldo pode rotear entre os modelos GPT, Claude, Gemini, DeepSeek, de imagem, áudio e vídeo por meio de um único gateway compatível com OpenAI. Ela também diz que o uso é medido por modelo, tipo de token e logs de solicitação para que as equipes possam revisar os gastos e controlar os custos.
O diretório de modelos da Flatkey verificado em 1 de julho de 2026 diz que publica preços de modelos renderizados no servidor para 629 modelos de IA de 23 provedores. A página expõe nomes de modelos, fornecedores, tipos de endpoint, campos de disponibilidade e informações de preços em HTML rastreável. Seu mapa de endpoints inclui rotas para Anthropic Messages, Gemini, geração de imagens, OpenAI Chat Completions, OpenAI Responses e vídeo OpenAI. Trate essas contagens como evidências de catálogo público datadas, não como uma garantia de que toda conta pode chamar toda rota sem a verificação atual da chave e da rota.
Isso torna o Flatkey uma opção prática de gateway de API de IA gerenciado quando sua equipe deseja um caminho de avaliação único para o código do aplicativo, finanças e operações. O piloto pode começar com uma URL base atual do console, uma chave de API do Flatkey, um alias de modelo selecionado, uma solicitação medida, revisão do log de solicitações, revisão de custos e uma nota de aprovação/reprovação.
Para que serve um proxy LLM auto-hospedado
Um proxy LLM auto-hospedado é criado para equipes que desejam ser proprietárias da camada de gateway. A documentação oficial do LiteLLM descreve o proxy como um gateway auto-hospedado compatível com OpenAI, onde qualquer cliente que funcione com OpenAI pode funcionar com o proxy. A documentação também descreve o LiteLLM como uma biblioteca e gateway de código aberto que fornece uma interface unificada para mais de 100 LLMs usando o formato OpenAI.
A documentação do proxy do LiteLLM lista a superfície operacional que torna a auto-hospedagem atraente: chaves virtuais com orçamentos por chave, equipe e usuário; registro centralizado; guardrails; cache; uma UI de administração; rastreamento de gastos; roteamento e balanceamento de carga; fallbacks de modelo; e controles de acesso ao modelo. A documentação das chaves virtuais diz que as equipes podem rastrear gastos e controlar o acesso ao modelo por meio de chaves virtuais, com uma UI para geração de chaves e SSO.
A mesma documentação mostra por que a palavra "auto-hospedado" é importante. Para fluxos de trabalho de chave virtual e orçamento, o LiteLLM requer a configuração de um banco de dados. O tutorial do Docker diz que os usuários do Docker ou da CLI precisam de um banco de dados Postgres para gerar chaves, usuários e equipes, e mostra uma configuração database_url em config.yaml ou uma variável de ambiente DATABASE_URL. Ele também requer uma chave mestra para a administração do proxy.
Os controles de orçamento podem ser sofisticados. A documentação de orçamentos e limites de taxa do LiteLLM descreve orçamentos pessoais, orçamentos de equipe, orçamentos de membros da equipe e orçamentos de agentes. A mesma página aborda limites de RPM e TPM, durações de orçamento, limites de taxa por usuário ou chave, limites específicos do modelo e um erro esperado de orçamento excedido para gastos da equipe. A documentação da arquitetura descreve a validação de chave virtual, verificações de orçamento, limitação de taxa, verificações de cache em memória ou Redis, encaminhamento do LiteLLM Router, callbacks de registro e atualizações de gastos no banco de dados.
Esses controles podem ser exatamente o que uma organização de plataforma deseja. Mas eles não são gratuitos apenas porque o software é de código aberto. A equipe deve operar o proxy, o banco de dados, os segredos, as contas de provedor, o pipeline de implantação, a observabilidade, a política de orçamento, as atualizações e o processo de incidentes. Uma comparação justa de gateway de API de IA gerenciado deve respeitar o controle ao mesmo tempo em que precifica a propriedade.
Matriz de comparação: custo, controle e operações
A decisão mais forte vem da comparação de evidências operacionais para o mesmo fluxo de trabalho. Peça a ambos os caminhos para mostrar o caminho da solicitação, o caminho de faturamento, o caminho da cota, o caminho do log e o responsável pelo suporte.
| Área de decisão | Evidência a ser solicitada do gateway de API de IA gerenciado | Evidência a ser solicitada do proxy LLM auto-hospedado | Por que é importante |
|---|---|---|---|
| Modelo de custo | Recarga pré-paga, linha de preço do modelo atual, custo do registro de solicitações, impacto no saldo, caminho da fatura e proprietário do faturamento. | Hospedagem em nuvem, banco de dados, cache, observabilidade, tempo de engenharia, faturas de provedores upstream e cobertura de suporte. | A auto-hospedagem pode evitar a margem de lucro do gateway do fornecedor, mas adiciona custos de infraestrutura e mão de obra. |
| Controle | Permissões do espaço de trabalho, proprietário da chave, aliases de modelo, grupos de provedores, status da rota e caminho de suporte. | Arquivos de configuração, credenciais do provedor, chaves virtuais, política de autenticação, gerenciador de segredos, banco de dados e ganchos personalizados. | Mais controle só é útil quando a equipe pode se responsabilizar pelas decisões e modos de falha. |
| Acesso ao provedor | Lista de modelos habilitados na conta, família de endpoints, catálogo de modelos atual e prova de rota no nível da solicitação. | Contas de provedores upstream, chaves de API do provedor, configurações de modelo, alvos de fallback e parâmetros específicos do provedor. | A propriedade do acesso impulsiona aquisições, resposta a incidentes, limites de taxa e rotação de chaves. |
| Roteamento e fallback | Alias de modelo selecionado, família de endpoints, status da rota, formato da resposta, formato do erro e expectativas de fallback. | Configuração do roteador, regra de balanceamento de carga, política de nova tentativa, cadeia de fallback, comportamento do cache e registro de falhas. | As alegações de roteamento precisam de prova no nível da solicitação antes que o tráfego de produção seja movido. |
| Orçamentos e cotas | Saldo pré-pago, controles de cota, controles de custo, análise de uso, registros de solicitações e caminho de escalonamento do proprietário. | Orçamento da chave virtual, orçamento da equipe, limites de taxa, regras de RPM/TPM, limites específicos do modelo e comportamento ao exceder o orçamento. | Uma cota só é útil se as equipes souberem se ela bloqueia, alerta, recorre a um fallback ou precisa de ação manual. |
| Logs e análises | Registros de solicitações, campos de modelo e token, visibilidade de custos, análise de uso, status da rota e necessidades de exportação. | Atualizações de gastos do banco de dados do proxy, callbacks de registro, integração de observabilidade externa, retenção e controles de acesso. | A depuração, a revisão financeira e a revisão de segurança dependem dos campos visíveis após uma solicitação. |
| Esforço de migração | Alteração da URL base compatível com OpenAI, chave de API Flatkey, mapeamento de alias de modelo, teste de fumaça, revisão de uso e diff de reversão. | Implantação do proxy, configuração do banco de dados, chave mestra, configuração do provedor, chaves virtuais, autenticação, roteamento, monitoramento e runbooks. | Uma pequena alteração no SDK pode ocultar um grande projeto de plataforma. |
| Proprietário das operações | Suporte do fornecedor, administrador do espaço de trabalho, proprietário do faturamento, proprietário da chave e proprietário da verificação de produção. | Plantão da plataforma, proprietário do banco de dados, proprietário do segredo, proprietário da atualização, proprietário da política e proprietário do escalonamento do provedor. | O caminho vencedor é aquele que sua organização pode operar de forma confiável. |
Quando um proxy LLM auto-hospedado é a melhor opção
Um proxy LLM auto-hospedado provavelmente é a melhor opção quando sua equipe de plataforma precisa de controle profundo sobre o caminho da solicitação. Isso inclui autenticação personalizada, política de roteamento personalizada, requisitos internos de gerenciador de segredos, implantação específica da região, controles de rede privada, callbacks de observabilidade personalizados, arquitetura rigorosa de residência de dados e regras de estorno interno que devem residir em sua plataforma.
A auto-hospedagem também é adequada quando a organização já possui capacidade operacional. Se sua equipe executa rotineiramente Postgres, Redis, Kubernetes ou serviços de contêiner, rotação de segredos, SSO, pipelines de registro, resposta a incidentes e janelas de atualização, a responsabilidade adicional pode ser aceitável. Nesse caso, o proxy se torna outro componente da plataforma, em vez de uma ferramenta isolada.
Finalmente, um proxy auto-hospedado pode ser a escolha certa quando o próprio gateway faz parte da arquitetura do seu produto. Se você precisa expor o acesso à IA a muitas equipes internas com chaves personalizadas, restrições de modelo personalizadas, orçamentos por equipe, expectativas de auditoria e política de roteamento controlada por seus próprios engenheiros, a configuração adicional pode trazer uma vantagem útil.
Quando o Flatkey deve estar na lista de opções
O Flatkey deve estar na lista de opções quando a equipe deseja um gateway de API de IA gerenciado em vez de um projeto de operações de gateway. Os casos de uso mais fortes são fluxos de trabalho de produtos com vários modelos, automação interna, agentes, ferramentas de codificação e projetos-piloto revisados pelo financeiro, onde as principais perguntas são: qual chave enviou a solicitação, qual modelo a atendeu, quanto custou, onde está o registro e quem aprova a próxima etapa de uso?
O Flatkey também é relevante quando o caminho de migração é compatível com a OpenAI. Em vez de implantar um proxy, provisionar um banco de dados, definir uma chave mestra, configurar provedores upstream, emitir chaves virtuais e conectar logs antes que um desenvolvedor possa testar um fluxo de trabalho, o piloto do Flatkey pode começar com uma URL base, chave de API, alias de modelo, teste de solicitação, revisão de uso e nota de reversão.
O comprador ainda deve verificar o estado atual da conta. Antes da produção, verifique a URL base do console Flatkey, a família de endpoints, o alias de modelo selecionado, a linha de preços do modelo, as permissões da conta, os registros de solicitações, os campos de custo, o comportamento da cota, o proprietário do saldo e o caminho de suporte. A afirmação útil não é que um serviço gerenciado remove todo o trabalho de revisão. É que o trabalho de revisão começa mais perto do fluxo de trabalho de IA e mais longe da montagem do gateway.
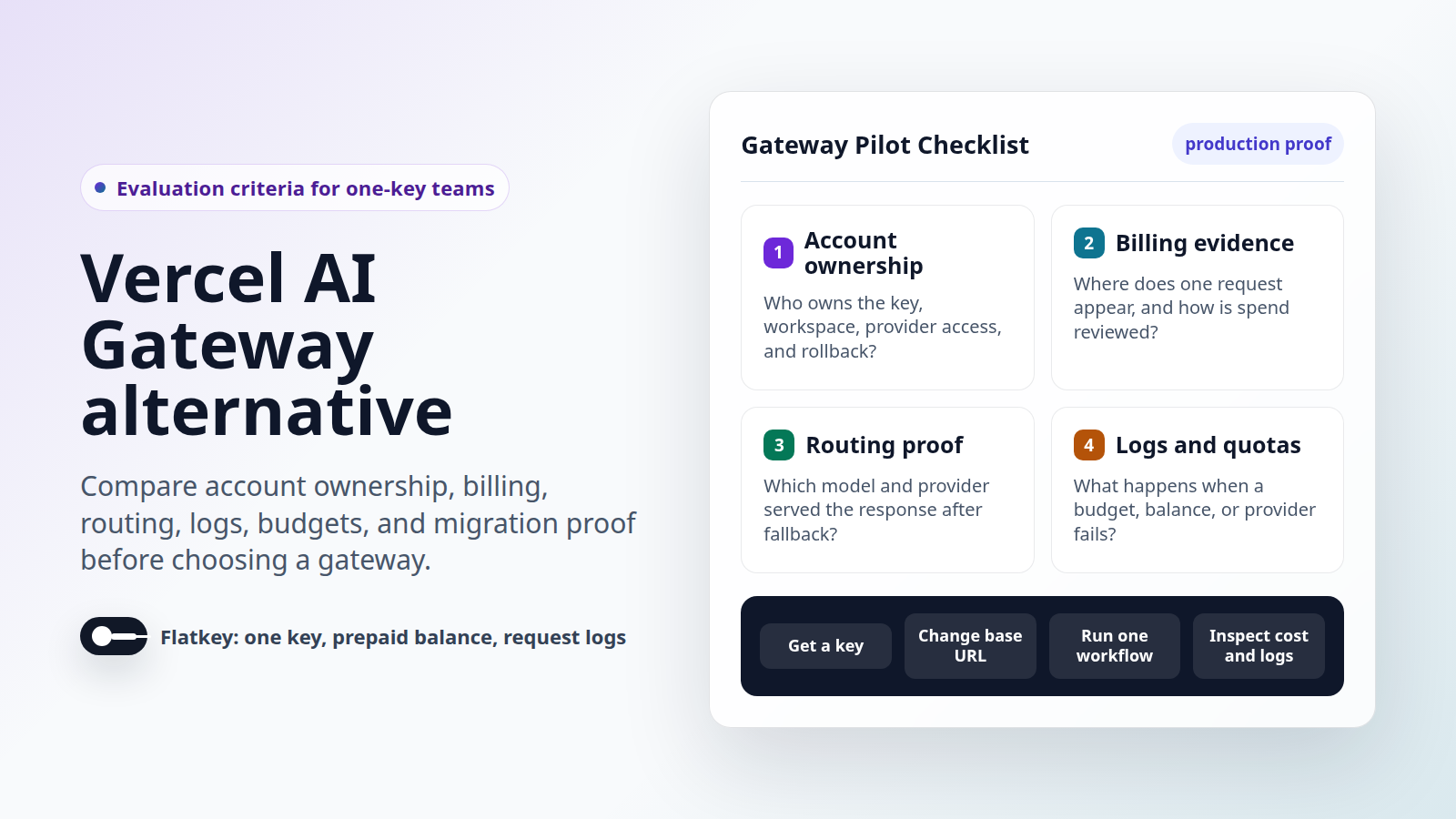
Lista de verificação do piloto para o mesmo fluxo de trabalho
Use esta lista de verificação antes de escolher um gateway de API de IA gerenciado ou um proxy LLM auto-hospedado. Ela mantém a decisão baseada em evidências que desenvolvedores, proprietários de plataforma, finanças e aquisições podem inspecionar.
- Nomeie um fluxo de trabalho. Escolha um agente de suporte, assistente de codificação, trabalho em lote, fluxo de trabalho de imagem/vídeo ou caminho de automação interna. Não avalie todo o patrimônio de modelos de uma só vez.
- Congele a rota atual. Registre o provedor atual, proprietário da chave, modelo, endpoint, formato da solicitação, comportamento de nova tentativa, uso médio e proprietário da reversão.
- Mapeie a propriedade da conta. Para o Flatkey, identifique o espaço de trabalho, o proprietário da chave de API, o proprietário do saldo, o alias do modelo, o grupo de provedores e os revisores do log de solicitações. Para auto-hospedagem, identifique o proprietário do proxy, as contas do provedor, o proprietário do banco de dados, o proprietário do segredo, o proprietário da chave virtual e o proprietário de plantão.
- Execute uma solicitação mínima. Capture o status, o formato da resposta, o modelo usado, os campos de uso, o formato do erro, a latência e se a solicitação aparece no log esperado.
- Execute um teste de orçamento. Confirme o escopo do limite, a janela de redefinição, o comportamento de aplicação, o caminho do alerta e quem age quando o limite é atingido.
- Execute um teste de faturamento. Confirme a unidade de custo, a fonte do preço, o custo da solicitação, o impacto no saldo ou na fatura do provedor, o caminho da fatura e o proprietário da revisão financeira.
- Execute um teste de falha. Simule modelo inválido, falha de autenticação, limite de taxa upstream, erro do provedor, orçamento esgotado e fallback. Registre o que acontece e quem é notificado.
- Escreva a nota de aprovação/reprovação. Inclua a diferença exata de código, a diferença de variável de ambiente, a prova de rota, a prova de log, a prova de faturamento, o mapa de proprietários e o caminho de reversão.
Modelo de custo: não compare apenas as taxas do fornecedor
A comparação de custos é onde as equipes geralmente criam a planilha errada. Um proxy auto-hospedado pode parecer mais barato se o único item for o software do gateway. Um modelo justo também inclui computação, banco de dados, cache, observabilidade, revisão de segurança, tempo de configuração de engenharia, plantão, tratamento de incidentes, atualizações e administração da conta do provedor. Se esses custos já forem absorvidos por uma equipe de plataforma, a auto-hospedagem ainda pode ser eficiente. Se forem um trabalho novo, devem ser contabilizados.
Um gateway de API de IA gerenciado tem um formato de custo diferente. O comprador deve inspecionar os preços dos modelos, o saldo pré-pago, o custo do log de solicitações, o comportamento da fatura e quaisquer termos específicos da conta. O valor não é apenas um item de linha mais baixo. É reduzir o número de sistemas que uma equipe deve montar antes que as finanças e as operações possam confiar no fluxo de trabalho.
Se você também estiver comparando produtos de gateway nomeados, use o mesmo padrão de evidência. Os guias de alternativas ao OpenRouter, alternativas ao LiteLLM e a lista de verificação do gateway de API de IA empresarial todos se concentram na propriedade da conta, faturamento, prova de roteamento, logs, cotas, esforço de migração e evidência operacional. Use a página de preços do Flatkey para o acesso ao modelo atual e a página de faturamento, e então obtenha uma chave quando estiver pronto para executar um piloto medido.
FAQ
O que é um gateway de API de IA gerenciado?
Um gateway de API de IA gerenciado é uma camada de acesso hospedada para o tráfego de modelos de IA. Ele normalmente oferece às equipes uma superfície de API compartilhada, roteamento de modelos, visibilidade de uso, fluxo de trabalho de faturamento e controles operacionais sem exigir que o comprador implante e opere a infraestrutura do gateway por conta própria.
Um proxy LLM auto-hospedado é mais barato que um gateway de API de IA gerenciado?
Às vezes, mas apenas se sua equipe puder absorver a infraestrutura e o trabalho. A auto-hospedagem pode reduzir a dependência de um fornecedor de gateway e aumentar o controle, mas adiciona trabalho de implantação, banco de dados, gerenciamento de segredos, observabilidade, atualizações e plantão. Um gateway de API de IA gerenciado empacota mais desse trabalho no serviço.
A auto-hospedagem oferece mais controle?
Sim. Um proxy auto-hospedado geralmente oferece controle mais profundo sobre credenciais de provedor, política de roteamento, chaves virtuais, orçamentos, logs e integrações. A contrapartida é que sua equipe é dona desses controles em produção. Mais controle é valioso quando você também tem as pessoas e o processo para operá-lo.
O Flatkey pode substituir todos os casos de uso de proxy auto-hospedado?
Não. O Flatkey deve ser avaliado como um modelo operacional alternativo, não como um clone de todos os proxies. Se seus requisitos incluem topologia de implantação personalizada, rede apenas interna, plugins de autenticação personalizados ou lógica de roteamento proprietária, a auto-hospedagem pode ser a melhor opção. Se sua prioridade é o acesso gerenciado a vários modelos com evidências de faturamento e uso, avalie o Flatkey.
Como o setor financeiro deve avaliar a escolha?
O setor financeiro deve solicitar um fluxo de trabalho concreto e rastreá-lo desde a solicitação até a fatura. Confirme as solicitações mensais esperadas, a combinação de modelos, os tipos de token, as novas tentativas, os fallbacks, o comportamento da cota, o caminho da fatura, o impacto no saldo ou na fatura do provedor, o acesso ao log e o proprietário da aprovação. Uma lista de recursos não é suficiente.
O que os desenvolvedores devem testar antes da migração?
Os desenvolvedores devem testar o URL base exato, a chave de API, o alias do modelo, a família de endpoints, o comportamento de streaming, o comportamento da ferramenta, o formato do erro, o comportamento de timeout, os campos de uso e o caminho de reversão. Uma solicitação de chat bem-sucedida não prova que todo o fluxo de trabalho está pronto para produção.
Regra de decisão final
Escolha um proxy LLM auto-hospedado quando a camada de gateway for uma infraestrutura estratégica que sua equipe de plataforma deseja possuir. Escolha um gateway de API de IA gerenciado quando sua equipe desejar uma única chave, acesso compatível com OpenAI, preços de modelo publicados, saldo pré-pago, análise de uso, logs de solicitação, controles de custo e um caminho mais rápido para validar fluxos de trabalho de modelo.
Para testar o Flatkey nesse modelo operacional gerenciado, consulte os preços e o acesso aos modelos atuais, obtenha uma chave e execute um fluxo de trabalho medido antes de mover um tráfego mais amplo.