Gateway de API de IA vs. gerenciamento de API não é uma lista de verificação genérica de recursos de gateway. O gerenciamento de API tradicional é criado para expor, proteger, publicar, versionar e observar APIs de aplicativos. O trabalho do gateway de API de IA começa quando a API é tráfego de modelo: cada solicitação pode carregar uma escolha de modelo, custo de token, conta de provedor, comportamento de streaming, formato de chamada de ferramenta, regra de fallback e registro financeiro.
Esta comparação foi verificada em 1º de julho de 2026, Ásia/Xangai, em relação à página inicial pública da Flatkey, página de preços, diretório de modelos, instantâneo da API de preços em tempo real, documentação do Azure API Management, documentação do Amazon API Gateway, documentação do Google Apigee e documentação do Cloudflare AI Gateway. Trate a terminologia do produto, as linhas de modelo, as famílias de endpoints e o comportamento de preços como evidências datadas. Verifique a linha de preços atual da Flatkey, o console do provedor e o comportamento do gateway antes de rotear o tráfego de produção.
Resposta Rápida: Gateway de API de IA vs. Gerenciamento de API
A versão curta de Gateway de API de IA vs. gerenciamento de API é esta: o gerenciamento de API governa as APIs como ativos de negócios e de plataforma reutilizáveis. Um gateway de API de IA governa o tráfego de modelos como um fluxo de trabalho de custo, roteamento, cota, registro e acesso ao provedor.
| Área de Decisão | Gerenciamento de API | Gateway de API de IA | O que muda para o tráfego de modelos |
|---|---|---|---|
| Superfície da API | APIs REST, HTTP, WebSocket e internas ou de parceiros expostas como produtos ou operações. | Endpoints de modelo, rotas de provedor, famílias de endpoints e clientes compatíveis com OpenAI. | A rota precisa saber qual modelo/provedor está atendendo a uma solicitação. |
| Unidade de custo | Solicitações, assinaturas, produtos, cotas, níveis ou alocação de custos de backend. | Tokens, imagens, segundos, família de endpoints, linha de modelo, nova tentativa, fallback e base de preço do provedor. | O setor financeiro precisa de comprovação de custos no nível do modelo e no nível da solicitação. |
| Roteamento | Encaminhar solicitações para serviços de backend e aplicar políticas, transformações, limitação de taxa e cache. | Roteamento por modelo, provedor, família de endpoints, disponibilidade, regra de fallback, fluxo de trabalho e barreira de proteção de custos. | Uma rota pode ser uma decisão de compra, não apenas uma decisão de rede. |
| Logs | Campos de status, latência, chamador, operação, política, gateway, backend e rastreamento. | Modelo, chave, rota, provedor, status, tipo de token, custo da solicitação, uso e tentativa de fallback. | A depuração e a revisão de faturas precisam da mesma trilha de evidências. |
| Migração | Publicar, usar proxy, versionar, transformar e documentar um contrato de API existente. | Alterar uma URL base, mapear aliases de modelo, testar o formato da resposta, verificar logs e manter a reversão pronta. | Uma pequena diferença no SDK ainda precisa de comprovação operacional. |
O gerenciamento de API não se torna obsoleto porque o tráfego de modelos de IA existe. Ele continua útil para produtos de API, portais de desenvolvedores, aplicação de políticas, arquitetura de rede e governança corporativa. A questão é onde a propriedade específica do modelo deve residir.
O que o Gerenciamento de API já cobre bem
As plataformas tradicionais de gerenciamento de API são fortes no ciclo de vida estável da API. A página de conceitos-chave do Azure API Management da Microsoft descreve o Gerenciamento de API como uma plataforma híbrida e multinuvem para APIs em todos os ambientes que suporta o ciclo de vida completo da API. Ela também descreve um gateway, plano de gerenciamento, portal do desenvolvedor, produtos, assinaturas, políticas, cotas, limitação de taxa, cache e observabilidade.
A visão geral do API Gateway da Amazon diz que o API Gateway é usado para criar, publicar, manter, monitorar e proteger APIs REST, HTTP e WebSocket em escala. A documentação introdutória do Google Apigee enquadra o Apigee em torno de proxies de API, produtos de API, políticas, segurança, análise, fluxos de trabalho de desenvolvedor e monetização.
Esse é o centro de gravidade correto quando seu principal problema é a governança do ciclo de vida da API:
- Publicação: empacotar APIs de backend como produtos e torná-las detectáveis.
- Acesso: emitir chaves de assinatura, regras JWT, certificados, grupos e acesso ao portal do desenvolvedor.
- Política: aplicar limites de taxa, cotas, transformações, cache, validação de solicitações e regras de cabeçalho.
- Operações: monitorar solicitações, erros, latência, integridade do backend e comportamento da política.
- Governança: gerenciar versões de API, ambientes, propriedade, documentação e integração de consumidores.
Para o tráfego de API comum, esses controles geralmente respondem às perguntas mais importantes: quem pode chamar esta API, qual contrato é exposto, qual política se aplica, quanto tráfego é permitido e onde os operadores encontram falhas.
O que muda quando o tráfego é de modelo
A diferença entre gateway de API de IA e gerenciamento de API aparece quando a chamada de API também é uma compra de modelo, uma decisão de roteamento de modelo e um registro de uso. Uma resposta de API normal pode ter o preço de uma solicitação ou de um nível de serviço. Uma resposta de modelo pode ter o preço por tokens de entrada, tokens de saída, contagem de imagens, duração de áudio, segundos de vídeo, tokens em cache, tokens de raciocínio, tentativas de repetição ou unidades específicas do provedor.
Isso muda a superfície operacional de sete maneiras:
- A identidade do modelo importa: a mesma forma de rota pode chamar modelos GPT, Claude, Gemini, DeepSeek, de imagem, áudio ou vídeo com comportamento e unidades de custo diferentes.
- A propriedade do provedor importa: as equipes precisam saber se a solicitação usou credenciais diretas do provedor, credenciais do gateway ou uma rota de provedor gerenciada.
- O custo do token e da modalidade importa: o setor financeiro precisa do custo por modelo, tipo de token, família de endpoint, fluxo de trabalho, equipe e ambiente.
- O fallback importa: uma rota pode tentar outro provedor ou modelo, mas o log deve provar o que aconteceu e quando.
- O streaming importa: a saída parcial altera o comportamento de nova tentativa e fallback porque o usuário já pode ter visto os tokens.
- A ferramenta e a forma da resposta importam: os aplicativos podem depender de chamadas de ferramentas, saída estruturada, embeddings, imagens ou campos específicos do provedor.
- A propriedade da cota importa: limites de gateway, limites de taxa do provedor, saldo pré-pago e controles de gastos no nível da conta podem afetar um único fluxo de trabalho.
A documentação do AI Gateway da Cloudflare mostra a mudança claramente: a página destaca análise, registro, cache, limitação de taxa, novas tentativas, fallback de modelo, provedores suportados, tokens e visibilidade de custos. Essas são preocupações do tráfego de modelos, não apenas preocupações genéricas do ciclo de vida da API.
Matriz de decisão: Gateway de API de IA vs. Gerenciamento de API
Use esta matriz de gateway de API de IA vs. gerenciamento de API antes de adicionar outra camada ao tráfego de IA em produção.
| Pergunta | Adequação do Gerenciamento de API | Adequação do Gateway de API de IA | Evidência a ser solicitada |
|---|---|---|---|
| Estamos expondo uma API estável para desenvolvedores internos, parceiros ou públicos? | Alta adequação. Produtos de API, assinaturas, documentação, políticas e integração de desenvolvedores são fluxos de trabalho centrais do APIM. | Útil apenas se a API for uma rota de acesso a modelos ou um fluxo de trabalho de IA. | Catálogo de APIs, proprietário do produto, grupos de consumidores, política de autenticação e plano de versionamento. |
| Estamos roteando entre provedores de modelos? | Possível com política personalizada e lógica de backend, mas a semântica de provedor/modelo geralmente não é nativa. | Alta adequação. O gateway deve rastrear aliases de modelos, famílias de endpoints, rotas de provedores, fallback e status. | Prova de rota, lista de modelos, propriedade do provedor, log de fallback e comportamento de erro. |
| O setor financeiro precisa do custo do modelo no nível da solicitação? | O APIM pode mostrar o uso da solicitação, mas os detalhes de token e custo do provedor podem exigir integração personalizada. | Alta adequação quando os logs incluem uso do modelo, tipos de token, custo da solicitação, impacto no saldo e caminho da fatura. | Uma solicitação rastreada da chave do aplicativo ao uso do modelo até o registro de custo. |
| Precisamos de aplicação de políticas para todas as APIs, não apenas para as de IA? | Alta adequação. A política de API centralizada e a governança do ciclo de vida são os pontos fortes do APIM. | Adequação limitada. Os gateways de IA não devem se tornar a única camada de gerenciamento de API da empresa. | Escopo da política, propriedade da API, inventário de tráfego não relacionado à IA e limites da plataforma. |
| Uma rota de modelo pode ser alterada sem churn de código? | O APIM pode abstrair backends, mas os IDs de modelo, as formas de resposta do SDK e as famílias de endpoints ainda precisam de testes específicos de IA. | Alta adequação quando os clientes podem manter uma URL base enquanto a seleção do modelo é movida para a rota ou configuração. | Diferença da URL base, mapa de alias de modelo, testes de fumaça, logs e instruções de reversão. |
| Quem é o proprietário das cotas e dos limites de gastos? | O APIM pode impor cotas de solicitação e limites de taxa para produtos e operações de API. | O gateway de IA deve adicionar cotas e revisão de gastos cientes do modelo entre provedores e modalidades. | Cota do gateway, limite do provedor, saldo pré-pago, caminho de alerta e escalonamento do proprietário. |
Mudanças na propriedade da conta
O gerenciamento de API geralmente começa com a propriedade do provedor da API e do consumidor da API. Quem é o proprietário do serviço de backend? Quem publica a API? Qual desenvolvedor, aplicativo, assinatura ou produto pode chamá-la?
O tráfego de modelos de IA adiciona a propriedade da conta do provedor. Uma equipe pode chamar OpenAI, Anthropic, Google, provedores de imagem, provedores de vídeo e provedores de modelos regionais no mesmo produto. Cada provedor pode ter sua própria organização, espaço de trabalho, projeto, chaves de API, caminho de faturamento, limites de taxa, escalonamento de suporte, aprovação de acesso ao modelo e logs.
Um gateway de API de IA deve reduzir a proliferação de contas do dia a dia sem fingir que a responsabilidade do provedor desaparece. A questão operacional duradoura não é "Temos um gateway?", mas sim "Qual sistema é a fonte de registro para a propriedade do provedor, propriedade da chave do aplicativo, uso da solicitação, revisão de custos e reversão?"
Mudanças no faturamento
O faturamento é onde a diferença entre gateway de API de IA vs. gerenciamento de API se torna visível fora da engenharia. O faturamento do gerenciamento de API geralmente se concentra em assinaturas, produtos, níveis, contagens de solicitações, alocação de custos de backend ou monetização. O tráfego de modelos introduz uma economia unitária que o setor financeiro não pode inferir apenas a partir dos códigos de status.
Para um fluxo de trabalho de IA, o setor financeiro pode perguntar:
- Qual modelo atendeu à solicitação?
- Qual provedor ou grupo de provedores foi usado?
- Quantas unidades de entrada, saída, em cache, de imagem, áudio ou vídeo foram consumidas?
- As novas tentativas ou o fallback geraram custo extra?
- Qual equipe, aplicativo, ambiente, cliente ou chave é responsável pelo gasto?
- Qual fatura, saldo pré-pago, pool de crédito ou cobrança direta do provedor o incluirá?
A página de preços da Flatkey, verificada para este artigo, descreve recargas pré-pagas, um único saldo, uso medido por modelo, tipo de token e logs de solicitação, análise de uso, controles de custo, suporte para faturamento e aquisições empresariais e uma única fatura para todos os provedores. O snapshot da API de preços da Flatkey ao vivo retornou 616 linhas de modelo com famílias de endpoints, incluindo openai, openai-response, anthropic, gemini e image-generation. Use esses fatos como prova datada de que a Flatkey publica evidências de modelos e endpoints, não como uma garantia de que uma linha, status ou preço específico permanecerá inalterado.
Mudanças no Roteamento
O roteamento de API tradicional responde para onde uma solicitação deve ir e qual política deve ser executada. O roteamento de modelo também responde que tipo de saída o produto produzirá, quanto custará e qual comportamento de fallback é permitido.
Para o tráfego de modelos, um registro de roteamento deve incluir pelo menos:
- Família de endpoints: conclusões de chat, respostas, mensagens, imagens, embeddings ou outro endpoint de modelo.
- Alias do modelo: o nome do modelo voltado para a aplicação e a linha real do provedor/modelo por trás dele.
- Rota do provedor: se o tráfego usa acesso gerenciado por gateway ou uma conta de provedor direta.
- Regra de fallback: qual modelo ou provedor pode ser tentado em seguida e sob quais condições de falha.
- Teste de compatibilidade: streaming, chamadas de ferramentas, formato JSON, saída de imagem, tempo limite e formato de erro.
- Caminho de rollback: a URL base antiga, o ID do modelo, o proprietário da chave de API e o proprietário da configuração.
Essa é a razão pela qual uma simples mudança na URL base ainda pode precisar de um plano de validação sério. A diferença no código pode ser pequena; a decisão operacional não é.
Mudanças no Registro de Logs
Os logs de gerenciamento de API ajudam os operadores a inspecionar o status da solicitação, a latência, a identidade do chamador, o comportamento do backend e as falhas de política. Os logs do gateway de API de IA precisam conectar essa mesma trilha operacional ao uso e custo do modelo.
Um log de tráfego de IA útil deve ajudar a responder a perguntas tanto de incidentes quanto financeiras:
| Campo do Log | Por que é importante para o tráfego de modelos |
|---|---|
| Chave do gateway ou rótulo do aplicativo | Conecta gastos e incidentes a um proprietário sem expor segredos brutos. |
| Modelo e rota do provedor | Mostra o que realmente serviu a resposta, não apenas o que o aplicativo solicitou. |
| Família de endpoints | Separa chat, respostas, mensagens, imagens, embeddings e outras formas de custo. |
| Uso de token ou modalidade | Explica a base de custo e ajuda a detectar prompts ou saídas incomuns. |
| Tentativa de fallback | Prova se uma nova tentativa ou rota secundária mudou o provedor, modelo, latência ou custo. |
| Status e classe de erro | Separa casos de autenticação, cota, modelo indisponível, erro do provedor e tempo limite do cliente. |
Se esses campos estiverem divididos entre consoles de provedores, logs de aplicativos, exportações de faturamento e logs de gateway, a equipe deve decidir qual registro prevalece durante um incidente ou revisão de fatura.
Mudanças em Cotas e Limites
As cotas de gerenciamento de API geralmente controlam o volume de solicitações por assinatura, produto, API, operação, chamador ou janela de tempo. O tráfego de IA precisa desses controles, mas também precisa de limites cientes do modelo.
Os limites comuns de tráfego de modelos incluem:
- Gasto máximo por chave, equipe, cliente ou ambiente.
- Máximo de solicitações por minuto e tokens por minuto.
- Limites separados para famílias de modelos caros, rotas de imagem/vídeo ou trabalhos em lote.
- Limites da conta do provedor que ainda podem ser aplicados por trás de um gateway.
- Saldo pré-pago, aprovação de fatura ou limites de aquisição.
- Mecanismos de proteção de fallback que impedem que uma rota barata se torne silenciosamente uma rota cara.
O plano de controle deve tornar esses limites revisáveis antes do lançamento. Um limite que ninguém consegue vincular a um modelo, chave, proprietário e caminho de fatura é difícil de confiar.
Mudanças no Esforço de Migração
As migrações de gerenciamento de API geralmente envolvem a importação de especificações, a construção de proxies, a aplicação de políticas, a publicação de documentos e a integração de consumidores. As migrações de gateway de IA são frequentemente descritas como "mudar a URL base". Isso pode ser verdade para um cliente compatível com OpenAI, mas não é um plano de migração completo.
Use esta lista de verificação de migração de gateway de API de IA vs. gerenciamento de API para rotas de modelo:
- Registre o provedor atual, ID do modelo, família de endpoints, URL base, proprietário da chave, tempo limite, nova tentativa e comportamento de fallback.
- Confirme a URL base do gateway de destino e o alias do modelo na conta atual, não em anotações antigas.
- Execute um pequeno conjunto de prompts que cubra saídas normais, saídas longas, streaming, chamadas de ferramentas, saídas estruturadas e erros esperados.
- Compare o formato da resposta, os campos de uso, os códigos de status e o comportamento de tempo limite.
- Verifique se os logs de solicitação mostram o modelo, a rota, o rótulo da chave, o status, o uso de token ou modalidade e os campos de custo que o financeiro precisa.
- Defina uma cota conservadora ou um limite de gastos para a primeira fatia de produção.
- Mantenha a chave do provedor antigo, a URL base e o ID do modelo prontos para rollback até que a rota esteja estável.
- Documente quais controles no nível do provedor ainda exigem propriedade direta da conta do provedor.
Combine este fluxo de trabalho com a lista de verificação do gateway de API de IA empresarial quando a segurança, as aquisições ou o financeiro precisarem de um pacote de evidências mais robusto.
Quando o Gerenciamento de API Ainda é a Melhor Camada
Escolha o gerenciamento de API como a camada principal quando o trabalho for mais amplo do que o acesso ao modelo:
- Você precisa de um portal do desenvolvedor, produtos de API, assinaturas e integração de consumidores.
- Você está governando muitas APIs que não são de IA entre equipes, ambientes, parceiros ou regiões.
- Você precisa de controles de política de API corporativa, como validação de JWT, certificados, transformações, limitação de taxa (throttling), cache e versionamento em um nível geral de plataforma de API.
- Sua principal evidência é a governança do ciclo de vida da API, não o custo do modelo, o roteamento do modelo ou a proliferação de contas de provedores.
- Sua organização já possui APIM como o perímetro padrão para APIs públicas, de parceiros e internas.
Algumas equipes devem executar ambas as camadas: gerenciamento de API para governança do ciclo de vida de APIs corporativas e um gateway de API de IA por trás ou ao lado dele para roteamento específico de modelos e evidências de custo.
Quando um Gateway de API de IA é a Melhor Camada
Escolha um gateway de API de IA como a camada principal quando o problema for específico do modelo:
- As equipes estão lidando com várias contas de provedores, chaves, faturas e catálogos de modelos.
- Os desenvolvedores querem uma URL base compatível com OpenAI enquanto avaliam vários provedores de modelos.
- O setor financeiro precisa de dados de uso por modelo, tipo de token, registro de solicitações e caminho da fatura.
- Os engenheiros de plataforma precisam de roteamento centralizado, fallback, cota e evidências de acesso a modelos.
- O setor de compras deseja uma superfície menor de acesso e faturamento para o uso de modelos de IA.
- Os proprietários de aplicativos precisam de um caminho de migração pronto para reversão (rollback) entre modelos e famílias de endpoints.
A página inicial pública da Flatkey, verificada para este artigo, posiciona a Flatkey como um gateway de API para equipes de IA em produção e afirma que unifica o acesso a modelos, roteamento, faturamento, análise de uso e controles operacionais. É por isso que a Flatkey pertence a esta discussão de gateway de API de IA vs. gerenciamento de API: ela não está tentando ser um catálogo de API corporativo de propósito geral. Ela está focada no acesso a modelos, chaves de gateway, roteamento, revisão de uso, faturamento e controles operacionais para o tráfego de IA.
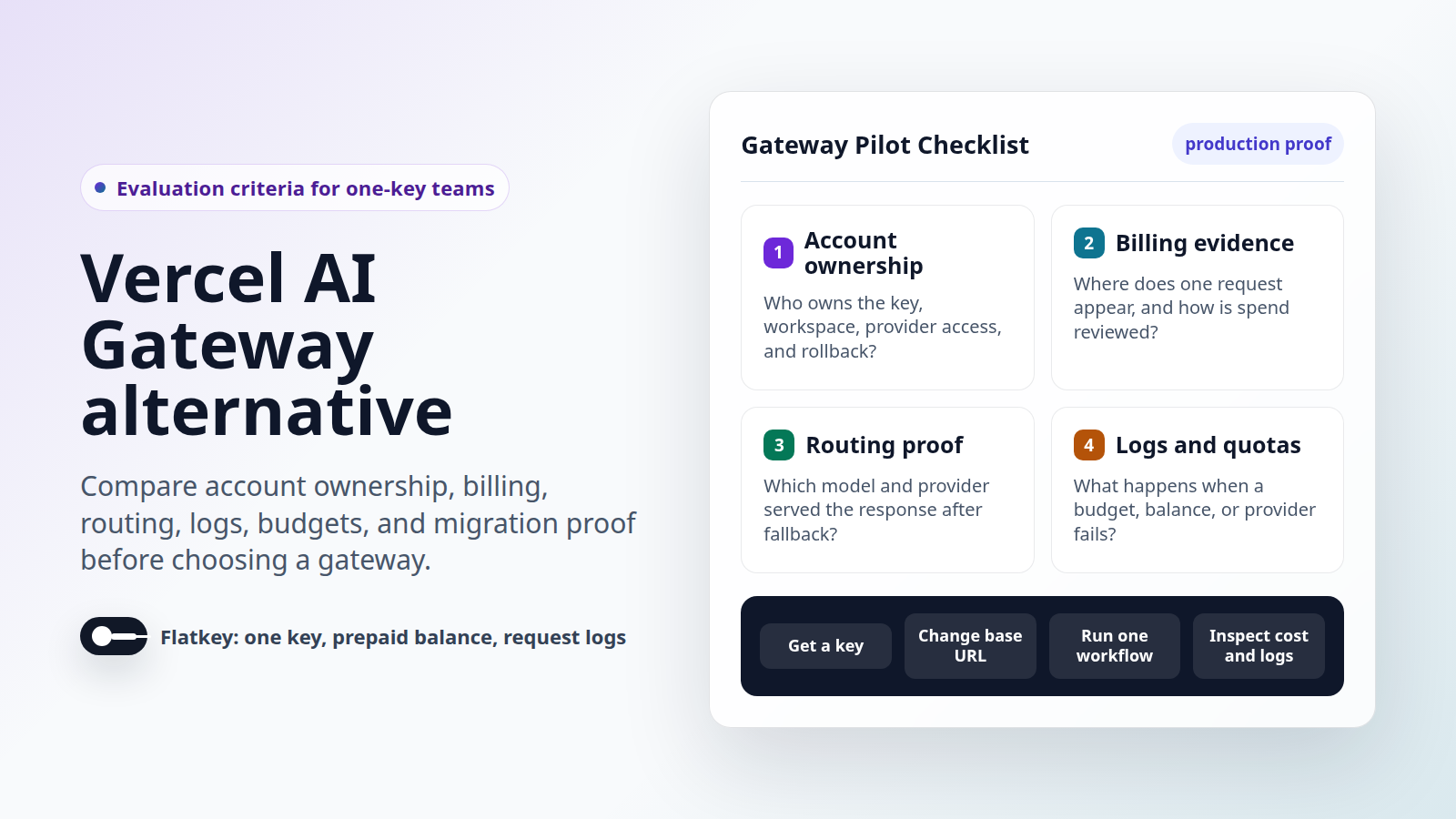
Fluxo de Trabalho de Validação da Flatkey
Use um piloto medido antes de mover o tráfego de modelos de produção para qualquer gateway.
- Escolha um fluxo de trabalho de IA, como chat de suporte, chamadas de agente de codificação, sumarização em lote, geração de imagens ou uma automação interna.
- Abra os preços da Flatkey e confirme a linha do modelo atual, a família de endpoints, o status de disponibilidade e a unidade de preço para esse fluxo de trabalho.
- Crie uma chave com escopo definido para a rota piloto.
- Aponte um cliente de teste (staging) compatível com OpenAI para a URL base da Flatkey mostrada no console atual.
- Execute o conjunto de prompts e capture o formato da resposta, a expectativa de latência, o status, o uso e o comportamento de erro.
- Confirme se os registros de solicitações e as análises de uso mostram os campos que a engenharia e o financeiro precisam.
- Defina uma cota, um proprietário e um caminho de reversão (rollback) antes de expandir o tráfego.
- Mantenha evidências diretas do provedor para contratos, solicitações de cota, logs nativos ou casos de suporte que ainda exigem a propriedade do provedor.
Se você estiver comparando opções de gateway, leia os guias de alternativas ao OpenRouter e alternativas ao LiteLLM para entender as diferenças sobre propriedade da conta, faturamento, logs, cotas, migração e as vantagens e desvantagens entre soluções gerenciadas e auto-hospedadas.
Modelo de Registro de Decisão
Use este modelo quando uma equipe de plataforma precisar de um registro de decisão durável sobre gateway de API de IA vs. gerenciamento de API.
Registro de decisão do gateway de tráfego de IA
Carga de trabalho:
Proprietário:
Ambiente:
Camada primária: Gerenciamento de API, gateway de API de IA ou ambos
Rota de gerenciamento de API atual:
Conta do provedor atual:
URL base atual:
Gateway/URL base de destino:
Família de endpoints:
Aliases de modelo:
Rotas do provedor:
Fonte de registro para faturamento:
Fonte de registro para uso:
Proprietário da fatura:
Proprietário da cota:
Política de fallback:
Testes de streaming/chamada de ferramenta:
Evidência nativa do provedor necessária:
Proprietário do rollback:
Data de revisão:
Não armazene chaves de API brutas no registro de decisão. Armazene rótulos de chaves, proprietários, datas de rotação e instruções de reversão (rollback).
Erros Comuns
- Usar o gerenciamento de API como o único registro de custo de modelo: a contagem de solicitações não é suficiente quando os custos de token, modelo, fallback e modalidade são importantes.
- Usar um gateway de IA como um catálogo de API completo: o roteamento de modelos não substitui a governança do ciclo de vida de APIs corporativas para todas as APIs.
- Ignorar as contas dos provedores: contratos diretos com provedores, cotas, logs, suporte e termos de dados ainda podem ser importantes.
- Pular testes de formato de resposta: ser compatível com OpenAI não garante que todos os modelos suportem as mesmas ferramentas, comportamento de streaming ou saída estruturada.
- Não separar a cota do gateway da cota do provedor: ambas podem afetar o tráfego de produção.
- Considerar uma única fatura como a única fonte da verdade: algumas cargas de trabalho ainda precisam de evidências de faturamento ou aquisição no nível do provedor.
FAQ
Qual é a diferença entre um gateway de API de IA e o gerenciamento de API?
O gerenciamento de API governa o ciclo de vida da API: publicação, segurança, documentação, versionamento, monitoramento e aplicação de políticas a APIs. Um gateway de API de IA governa o tráfego de modelos: roteamento de modelos, acesso a provedores, uso de tokens e modalidades, registros de solicitações, cotas, fallback, faturamento e migração entre provedores de modelos.
Um gateway de API de IA substitui o gerenciamento de API?
Não. Na discussão gateway de API de IA vs. gerenciamento de API, a resposta prática geralmente é ambos. O gerenciamento de API pode continuar sendo a camada de governança de API corporativa, enquanto um gateway de API de IA lida com roteamento específico de modelos, logs, cotas, faturamento e evidências de acesso a provedores.
Quando uma equipe deve usar o gerenciamento de API para o tráfego de IA?
Use o gerenciamento de API quando os endpoints de IA fizerem parte de um produto de API mais amplo, portal do desenvolvedor, API de parceiro ou programa de política empresarial. Adicione controles de gateway específicos de IA quando a equipe também precisar de roteamento de modelo, atribuição de custos, fallback e revisão de conta de provedor.
Quando uma equipe deve usar um gateway de API de IA?
Use um gateway de API de IA quando a equipe precisar de um padrão de chave, um URL base, roteamento de modelo, logs de uso, revisão de custos de token ou modalidade, cotas, fallback e um caminho de faturamento mais simples entre vários provedores de modelo.
Como o Flatkey se encaixa na decisão de gateway de API de IA vs. gerenciamento de API?
O Flatkey se encaixa no lado da decisão do gateway de API de IA. Suas páginas públicas descrevem um gateway de API para equipes de IA de produção, acesso a modelos, roteamento, faturamento, análise de uso, controles operacionais, recargas pré-pagas, logs de solicitação, controles de custos e uma única fatura para todos os provedores. Valide as linhas de modelo e os preços atuais em preços antes da implementação.
O que os compradores devem solicitar durante a avaliação?
Peça o rastreamento de uma solicitação desde a chave do aplicativo até a rota do modelo, provedor, família de endpoints, status, campos de uso, registro de custo, comportamento da cota e caminho da fatura. Essa prova é mais útil do que uma lista genérica de recursos.
Recomendação Final
A decisão certa entre gateway de API de IA vs. gerenciamento de API começa com o tráfego. Se o tráfego for um produto de API estável com consumidores, assinaturas, políticas, documentação e governança do ciclo de vida, o gerenciamento de API é a camada principal. Se o tráfego for de acesso a modelos com roteamento de provedor, custo de token, logs, cotas, fallback, faturas e migração de URL base, um gateway de API de IA é a camada principal de operações de modelo.
Para muitas equipes de produção, a resposta não é uma ou outra. Mantenha o gerenciamento de API para a governança de API empresarial e use o Flatkey onde o tráfego de modelos precisa de uma chave, roteamento de modelo, logs de solicitação, controles de custos e um fluxo de trabalho de faturamento único.
Obtenha uma chave: comece com o cadastro no Flatkey, depois use a página de preços para verificar a linha do modelo e a família de endpoints para o seu primeiro teste de gateway.