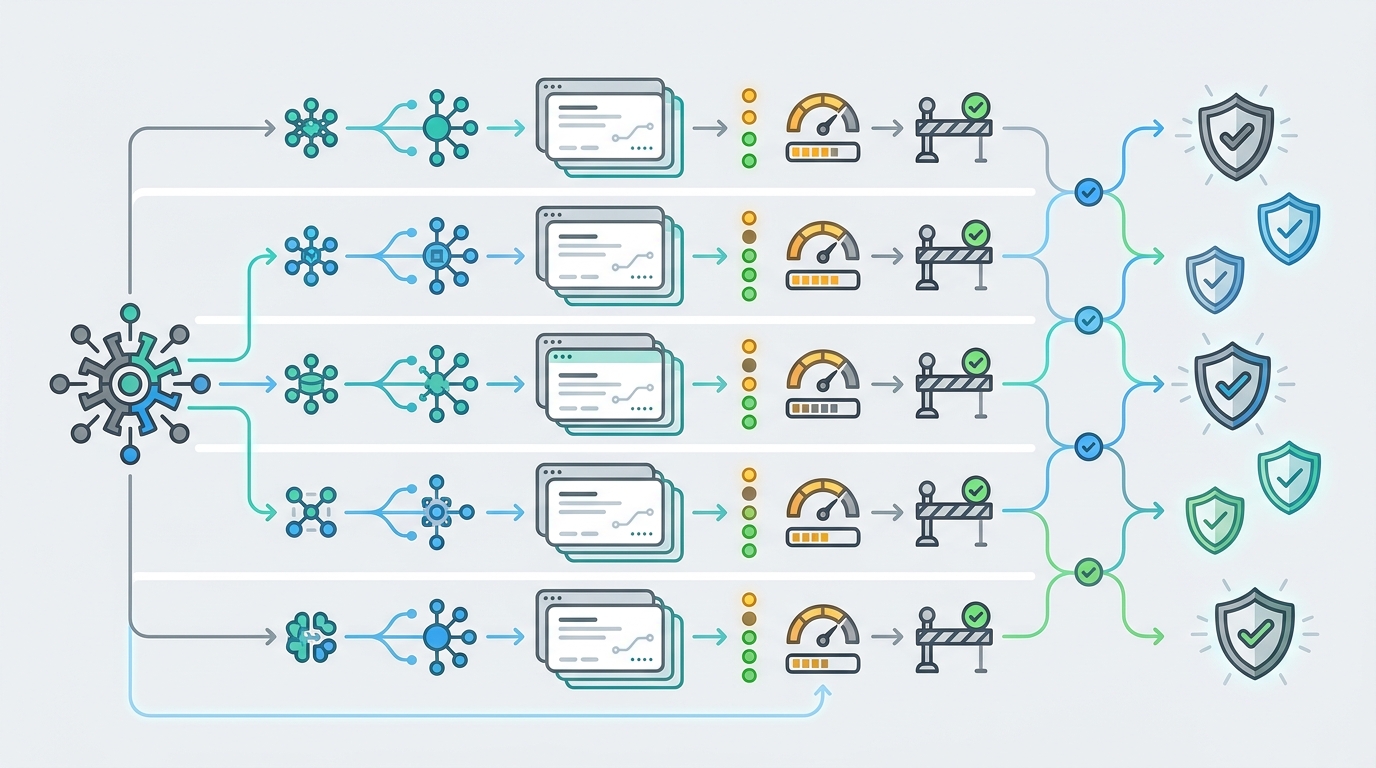
Um catálogo de modelos de IA só é útil quando ajuda uma equipe a tomar uma decisão de produção. Uma página cheia de nomes de modelos não basta. Os desenvolvedores precisam saber qual provedor é responsável pelo modelo, qual família de endpoints o aplicativo chamará, qual grupo ou camada de rota atenderá o tráfego, se a linha está disponível no momento e como o preço é medido antes que a primeira solicitação de um usuário real passe por ela.
Este guia de catálogo de modelos de IA foi verificado em June 24, 2026 com base nas páginas públicas da Flatkey, na API de preços ativa da Flatkey, em pesquisas salvas do Ahrefs e na documentação oficial de catálogos de modelos da Microsoft, Google, Vercel e OpenAI. Trate cada contagem de catálogo, status, família de endpoint e campo de preço como um retrato em um ponto específico no tempo. Antes do tráfego de produção, reabra Flatkey pricing, confirme a linha exata do modelo e execute um teste de rota de baixo risco.
O objetivo prático é simples: transformar a navegação por modelos em uma revisão repetível. Se sua equipe consegue ler provedor, endpoint, grupo, status, preço e responsável no mesmo registro do catálogo de modelos de IA, a decisão sobre o modelo fica mais fácil para engenharia, finanças, suporte e compras aprovarem.
Resposta rápida: como ler um catálogo de modelos de IA
Leia um catálogo de modelos de IA da esquerda para a direita: primeiro provedor, depois endpoint, grupo em terceiro, status em quarto, preço em quinto e teste de rota por último. Essa ordem evita que as equipes escolham um nome de modelo que parece atraente, mas que não pode ser chamado com segurança pelo endpoint, grupo ou política de orçamento que a aplicação realmente usa.
| Campo do catálogo | O que ele informa | Decisão a tomar | Verificação na Flatkey |
|---|---|---|---|
| Provedor | Quem fornece ou hospeda a rota do modelo. | Esse provedor consegue atender às suas expectativas de funcionalidade, risco e suporte? | Confirme o registro do fornecedor e quaisquer observações específicas do provedor na linha. |
| ID do modelo | A string exata que seu aplicativo solicitará. | O aplicativo consegue usar esse ID sem desvio de alias ou documentação desatualizada? | Copie a linha do modelo de /pricing, não de memória. |
| Família de endpoints | O formato do protocolo: chat, responses, geração de imagem, vídeo, Gemini, Anthropic ou outra rota. | O SDK atual, o corpo da solicitação, o modo de streaming e o parser de resposta são compatíveis? | Verifique a família de endpoints compatível antes de alterar a URL base. |
| Grupo | A camada de rota ou pool de recursos que atende à solicitação. | Qual grupo deve lidar com staging, produção, fallback ou tráfego sensível a custo? | Compare o rótulo exato do grupo e a proporção do grupo antes do lançamento. |
| Status | Se a verificação mais recente do catálogo está limpa, sem suporte ou não resolvida. | Esta linha deve receber tráfego de produção, um teste smoke ou nenhum tráfego? | Não trate uma linha visível como disponível até que o status e um teste de solicitação concordem. |
| Unidade de preço | Como o uso é cobrado: entrada, saída, cache, imagem, vídeo, segundo ou unidade fixa no estilo de job. | Qual fórmula de orçamento e cota deve ser aplicada? | Revise separadamente os campos no estilo de tokens e os campos de preço que não são baseados em tokens. |
| Teste de rota | Se o modelo funciona para o caminho exato da funcionalidade. | Engenharia, finanças e suporte podem aceitar o resultado? | Execute uma solicitação em staging e depois inspecione uso, custo, status e logs. |
Retrato atual do catálogo de modelos de IA da Flatkey
O retrato da API de preços ativa da Flatkey usado neste artigo retornou success: true em June 24, 2026. Ele expôs 637 linhas de catálogo, 23 registros de fornecedores, cinco rótulos de grupo utilizáveis e seis famílias de endpoints. A versão de preços de nível superior na resposta era a42d372ccf0b5dd13ecf71203521f9d2.
| Campo do retrato | Valor em June 24, 2026 | Como usá-lo |
|---|---|---|
| Total de linhas do catálogo | 637 | Use o catálogo de modelos de IA como uma fonte em nível de linha, não como uma lista estática de provedores. |
| Registros de fornecedores | 23 | A identidade do provedor importa para decisões de suporte, conformidade e fallback. |
| Famílias de endpoints | openai, gemini, image-generation, anthropic, openai-response, openai-video |
A família de endpoints indica se o formato atual da solicitação pode funcionar. |
| Status de disponibilidade | available, official_unsupported, unknown_failure |
O status deve orientar o controle de tráfego e a prioridade dos testes smoke. |
| Linhas disponíveis | 132 | Ainda exigem um teste de rota para seu endpoint, grupo, prompt e cota. |
| Linhas oficialmente sem suporte | 37 | Não as use em produção sem um status verificado mais recente. |
| Linhas com falha desconhecida | 468 | Trate-as como não resolvidas até que evidências de rota, conta, upstream ou status sejam verificadas. |
A página inicial pública da Flatkey posiciona o produto em torno de uma única chave de API, da URL base compatível com OpenAI https://router.flatkey.ai/v1, preços claros, cobrança unificada e um único dashboard para chaves, uso e roteamento. Essas promessas tornam o catálogo de modelos de IA operacionalmente útil, mas não eliminam a necessidade de verificar a linha específica que seu produto chamará.
Leia os provedores antes de ler os nomes dos modelos
Nomes de modelos circulam por fornecedores, gateways, documentação e aliases. A identidade do provedor é o primeiro campo estabilizador. Ela informa quem fornece a rota do modelo, qual conta ou upstream pode estar envolvido, de onde vêm as expectativas de suporte e se o modelo pertence a um plano direto do provedor, a uma rota de gateway ou a um caminho de avaliação restrito.
Catálogos oficiais de nuvem levam o mesmo problema a sério. Microsoft Foundry Models separa modelos vendidos pelo Azure de modelos de parceiros e da comunidade, e orienta os clientes a revisar descrições de modelos, model cards, documentação e termos legais antes de selecionar um modelo. Google Model Garden permite que as equipes filtrem por coleções de modelos e provedores, depois abram model cards para obter mais detalhes. A lição para qualquer catálogo de modelos de IA é a mesma: provedor não é decoração; faz parte do contrato operacional.
Para avaliação da Flatkey, anote:
- Provedor ou fornecedor: o registro de fornecedor associado à linha.
- Linha do modelo: o ID exato do modelo visível em Flatkey pricing.
- Responsável: a equipe, funcionalidade, cliente ou responsável pelo orçamento que está solicitando o modelo.
- Motivo da seleção: qualidade, custo, latência, modalidade, contexto, uso de ferramentas, imagem, vídeo ou comportamento de fallback.
- Rota de substituição: o que o aplicativo deve usar se a linha do provedor mudar de status.
Leia endpoints como contratos, não como rótulos
Uma família de endpoints informa ao seu aplicativo qual formato de solicitação e resposta esperar. Um modelo que aparece sob uma família de endpoints openai pode se encaixar em um fluxo de SDK compatível com OpenAI. Um modelo que aparece sob anthropic, gemini, image-generation, openai-response ou openai-video pode exigir um corpo de solicitação, parser, comportamento de streaming, caminho de manipulação de arquivos ou interpretação de uso diferente.
Por isso, um catálogo de modelos de IA útil deve ser lido junto com o plano de migração. Se seu aplicativo já usa um cliente compatível com OpenAI, comece pelo fluxo de trabalho de migração de API compatível com OpenAI: altere a URL base em staging, mantenha o ID do modelo explícito, execute uma pequena solicitação, inspecione a resposta e depois revise logs e custo. Não presuma que toda linha de modelo oferece suporte a todo estilo de endpoint.
| Família de endpoints | O que verificar | Modo comum de falha |
|---|---|---|
openai |
URL base, ID do modelo, formato de mensagens, streaming, chamadas de ferramenta, modo JSON, campos de uso. | A chamada do SDK é bem-sucedida na sintaxe, mas usa uma linha de modelo que não oferece suporte à funcionalidade. |
openai-response |
Corpo de solicitação no estilo Responses, parsing de saída, comportamento de ferramentas, entrada multimodal. | Suposições de chat completions vazam para um fluxo de trabalho no estilo Responses. |
anthropic |
Formato da solicitação de mensagens, manipulação de prompt de sistema, comportamento de entrada de imagem, campos de uso. | Um corpo no estilo OpenAI é enviado a uma rota no estilo Anthropic sem adaptação. |
gemini |
Formato de solicitação Gemini, entrada multimodal, configurações de segurança, parsing de resposta. | A seleção do modelo ignora diferenças de funcionalidade ou resposta específicas do provedor. |
image-generation |
Regras de imagem de entrada, tamanho de saída, qualidade, moderação, formato e contagem de resultados aceita. | Orçar por contagem de solicitações oculta custos de qualidade de imagem e novas tentativas. |
openai-video |
Duração, proporção, estado de job assíncrono, polling, tratamento de falhas e unidade de uso. | Jobs de vídeo são tratados como chamadas de texto síncronas e baratas. |
Leia grupos como política de rota e custo
Em um gateway unificado, um grupo não é apenas um rótulo. Ele pode representar uma camada de rota, pool de recursos, caminho de conta ou política de preços. O retrato da Flatkey de June 24 expôs rótulos de grupo utilizáveis, incluindo Economy, Standard, Claude Economy, Claude Official e Seedance2.0 Official. A resposta também incluiu descrições de grupo e proporções de grupo.
Ao ler um catálogo de modelos de IA, os grupos respondem a perguntas que um nome de modelo não consegue responder:
- Qual grupo o staging deve usar? Uma rota de baixo risco pode ser suficiente para testes de integração.
- Qual grupo a produção deve usar? A produção pode precisar de um caminho de provedor, perfil de custo ou expectativa de suporte diferente.
- Qual grupo o fallback deve usar? Uma rota de fallback precisa ser compatível com requisitos de qualidade, latência e orçamento.
- Qual grupo finanças deve revisar? Proporções em nível de grupo podem alterar o custo efetivo para o mesmo nome de modelo.
- Qual grupo compras deve aprovar? Uma rota direta ou oficial pode exigir evidências diferentes de uma rota econômica.
O hábito seguro é registrar o grupo na decisão sobre o modelo, não apenas o ID do modelo. Uma linha de modelo que parecia razoável em um grupo pode ter um custo ou caminho operacional diferente em outro grupo.
Leia preços por unidade antes de comparar linhas
Campos de preço são fáceis de interpretar mal porque diferentes famílias de modelos expõem unidades diferentes. Modelos de texto frequentemente separam entrada, entrada em cache e saída. Linhas de imagem e vídeo podem adicionar configurações de qualidade, unidades de mídia gerada, duração de job ou campos fixos no estilo de preço do modelo. A página pública de preços da OpenAI, por exemplo, separa preços de entrada, entrada em cache e saída por 1M tokens para seus modelos. Google Model Garden observa que o uso de modelos de código aberto pode envolver cobranças de computação para tuning e implantação. Microsoft Foundry observa que implantações serverless normalmente são cobradas por entradas e saídas de API, muitas vezes em tokens, enquanto computação gerenciada usa horas de núcleo de máquina virtual.
Para uma revisão do catálogo de modelos de IA da Flatkey, separe os formatos de preço antes de comparar linhas:
| Formato de preço | Campos a inspecionar | Pergunta de orçamento |
|---|---|---|
| Texto no estilo de tokens | model_ratio, completion_ratio, cache_ratio |
A funcionalidade gastará mais com prompts, saídas, contexto em cache ou novas tentativas? |
| Chat multimodal | Família de endpoint, tokens de entrada, tokens de saída, entradas de imagem/vídeo, comportamento de cache. | Entradas que não são texto estão alterando o custo efetivo? |
| Geração de imagem | Linha do modelo, família de endpoint, configurações de saída, contagem de novas tentativas, contagem de imagens aceita. | Quanto custa uma imagem aceita após falhas e edições? |
| Geração de vídeo | Linha do modelo, duração, qualidade, estado do job, política de novas tentativas, model_price se presente. |
A cota consegue interromper jobs caros antes de um incidente de orçamento? |
| Rota ajustada por grupo | Rótulo do grupo, proporção do grupo, rota de produção, rota de fallback. | A equipe está comparando o grupo que realmente usará? |
Para um fluxo de trabalho de custo mais aprofundado, use o guia de comparação de preços de modelos de IA depois de pré-selecionar linhas. Este guia de catálogo de modelos de IA ajuda você a decidir quais linhas merecem análise de preços em primeiro lugar.
Leia o status antes do tráfego de produção
Uma linha visível no catálogo não é o mesmo que uma rota pronta para produção. No retrato da Flatkey de June 24, apenas 132 de 637 linhas tinham available como o status de disponibilidade mais recente. As linhas restantes estavam divididas entre official_unsupported e unknown_failure. Isso não significa que toda linha não resolvida seja permanentemente inutilizável; significa que a linha precisa de evidências atuais de rota antes de carregar tráfego de usuários.
Use o status como um gate:
- Disponível: execute um teste smoke em staging para seu endpoint, grupo, corpo de solicitação e formato de prompt exatos.
- Oficialmente sem suporte: não lance tráfego de produção a menos que uma fonte mais recente comprove que o status mudou.
- Falha desconhecida: investigue se o problema é status upstream, permissão de conta, configuração de rota, região, cota ou falha transitória.
- Sem status claro: trate a linha como não aprovada até que um dashboard ou teste de API crie evidências.
- Status alterado: atualize o registro de decisão do modelo e notifique o responsável antes de redirecionar usuários.
O campo de status também é um controle financeiro. Uma rota de fallback que sai silenciosamente de uma linha limpa e de baixo custo para uma linha não resolvida ou mais cara pode transformar um experimento com modelo em um incidente. Mantenha status, grupo e preço juntos em toda revisão de catálogo de modelos de IA.
Um fluxo de trabalho da Flatkey para revisão de catálogo
Use este fluxo de trabalho quando uma equipe pedir para adicionar ou alterar um modelo por trás de uma única chave.
- Abra o catálogo atual: comece em Flatkey pricing e copie a linha exata.
- Registre provedor e grupo: não aprove uma linha usando apenas o nome do modelo.
- Confirme a família de endpoints: associe a rota ao seu SDK, corpo de solicitação, plano de streaming e parser.
- Verifique o status: direcione tráfego de produção somente depois que o status e uma solicitação ativa concordarem.
- Classifique a unidade de preço: token, cache, imagem, vídeo, duração, preço fixo ou rota ajustada por grupo.
- Execute um teste de baixo risco: envie uma solicitação de staging por
https://router.flatkey.ai/v1ou pela família de rota relevante. - Revise uso e custo: inspecione o dashboard em busca de evidências de modelo, uso, custo, status e roteamento.
- Defina cota e responsável: conecte a linha a uma chave, responsável pelo orçamento, limite, alerta e rota de rollback.
- Salve a decisão: mantenha juntos a linha do catálogo, data, status, grupo, campos de preço, resultado do teste e aprovação do responsável.
Este também é o repasse claro entre engenharia e finanças. A engenharia comprova que a rota funciona. Finanças comprova que a unidade e o responsável fazem sentido. O suporte comprova que a decisão sobre o modelo pode ser explicada quando um cliente pergunta por que uma funcionalidade mudou.
Modelo: registro de revisão de catálogo de modelos de IA
Mantenha um registro compacto para cada linha de modelo que chega a staging ou produção. Isso transforma a navegação pelo catálogo de modelos de IA em um hábito operacional.
Registro de revisão do catálogo de modelos de IA
Data da revisão:
Solicitante:
Funcionalidade ou fluxo de trabalho:
Ambiente: desenvolvimento / staging / production / batch / voltado ao cliente
Linha do modelo:
Provedor ou fornecedor:
Família de endpoints:
Grupo:
Status de disponibilidade:
Campos de preço:
Unidade esperada: tokens de entrada / tokens de saída / entrada em cache / imagem / vídeo / duração / job fixo
Teste de rota:
Caminho da solicitação:
SDK ou cliente:
Resposta aceita: yes / no
Uso visível: yes / no
Custo visível: yes / no
Cota anexada: yes / no
Responsável:
Responsável pelo orçamento:
Responsável pelo suporte:
Rota de fallback:
Condição de rollback:
Data da próxima revisão:
Erros comuns em catálogos de modelos de IA
| Erro | Por que cria risco | Revisão melhor |
|---|---|---|
| Escolher apenas pelo nome do modelo | Aliases, provedores, famílias de endpoints e grupos podem diferir. | Aprove a linha exata: provedor, endpoint, grupo, status, preço, responsável. |
| Presumir que compatível com OpenAI significa que toda funcionalidade funciona | Uso de ferramentas, streaming, imagens, vídeo e formatos de resposta podem variar por rota. | Execute um teste smoke em nível de funcionalidade antes do lançamento. |
| Ignorar rótulos de grupo | O mesmo nome de modelo pode ter custo ou comportamento de rota diferente por grupo. | Registre o grupo de produção e compare as proporções de grupo. |
| Tratar status não resolvido como inofensivo | Falhas desconhecidas podem ocultar problemas de rota, permissão, upstream ou conta. | Bloqueie o tráfego até que o status e as evidências de solicitação estejam limpos. |
| Comparar preços sem unidades | Tokens de entrada, tokens de saída, tokens em cache, imagens e jobs de vídeo não são orçados da mesma forma. | Classifique a unidade de preço antes de usar uma tabela de comparação. |
Quando um catálogo unificado de modelos de IA mais ajuda
Um catálogo de modelos de IA unificado ajuda mais quando seu produto já abrange mais de um provedor, modalidade ou responsável operacional. Um protótipo de provedor único muitas vezes pode começar por uma página oficial de documentação. Um produto de IA em produção geralmente precisa de uma visão mais durável: GPT, Claude, Gemini, DeepSeek, Qwen, modelos de imagem, modelos de vídeo, grupos de roteamento, status, cotas, uso e custo em um único ciclo de revisão.
A Flatkey foi projetada para equipes que querem uma única chave de API, uma única URL base compatível, preços e cobrança unificados e um único dashboard para chaves, uso e roteamento. A revisão de catálogo é onde esse valor se torna concreto. Você pode comparar linhas, escolher uma rota, testar o endpoint, anexar cota e manter evidências de uso em um único caminho operacional, em vez de espalhar a decisão por portais de provedores e planilhas.
O próximo passo correto não é confiar cegamente em uma linha. Comece pela página atual de preços de modelos, copie o modelo e o grupo exatos, teste a rota em staging e depois obtenha uma chave quando estiver pronto para avaliar o fluxo de trabalho na sua própria aplicação.
FAQ
O que é um catálogo de modelos de IA?
Um catálogo de modelos de IA é uma lista pesquisável de linhas de modelos com contexto suficiente para escolher, testar e operar um modelo. Um catálogo útil deve expor provedor, ID do modelo, família de endpoints, grupo ou camada de rota, status de disponibilidade, unidade de preço e evidências de documentação ou dashboard.
Por que o provedor importa em um catálogo de modelos de IA?
A identidade do provedor informa quem fornece ou hospeda a rota, quais termos e expectativas de suporte podem se aplicar e qual revisão de fallback ou compras é necessária. O nome do modelo sozinho não basta para aprovação em produção.
Como devo comparar famílias de endpoints?
Compare famílias de endpoints por formato de solicitação, compatibilidade com SDK, comportamento de streaming, suporte a ferramentas, entrada multimodal, parsing de resposta e campos de uso. Uma linha que funciona para chat pode não funcionar para solicitações de imagem, vídeo, Gemini, Anthropic ou no estilo Responses.
O que é um grupo de modelos?
Um grupo de modelos é um rótulo de rota ou recurso que pode afetar custo, caminho upstream, expectativa de suporte ou comportamento de fallback. Na Flatkey, leia o grupo junto com o ID do modelo e os campos de preço antes de aprovar uma rota.
Com que frequência as equipes devem reverificar um catálogo de modelos de IA?
Reverifique antes de cada lançamento em produção, troca de modelo, alteração de fallback, grande revisão de preços ou acompanhamento de incidente. Catálogos de modelos de IA mudam rapidamente, então retratos datados não devem ser tratados como garantias permanentes de disponibilidade ou preço.
Etapa final de revisão do catálogo
Antes que uma linha de modelo chegue à produção, atribua um responsável a cada campo no registro do catálogo de modelos de IA. Engenharia é responsável pela adequação do endpoint e pelo teste de rota. Finanças é responsável pela unidade de preço e pelo orçamento. Suporte é responsável pelo impacto voltado ao cliente. Plataforma é responsável por cota, fallback e rollback. É assim que um catálogo se torna infraestrutura, em vez de um menu de modelos.
Para executar a versão da Flatkey dessa revisão, abra Flatkey pricing, selecione uma linha de modelo, confirme provedor, endpoint, grupo, status e unidade de preço, depois obtenha uma chave e teste a rota antes de escalar o tráfego.


