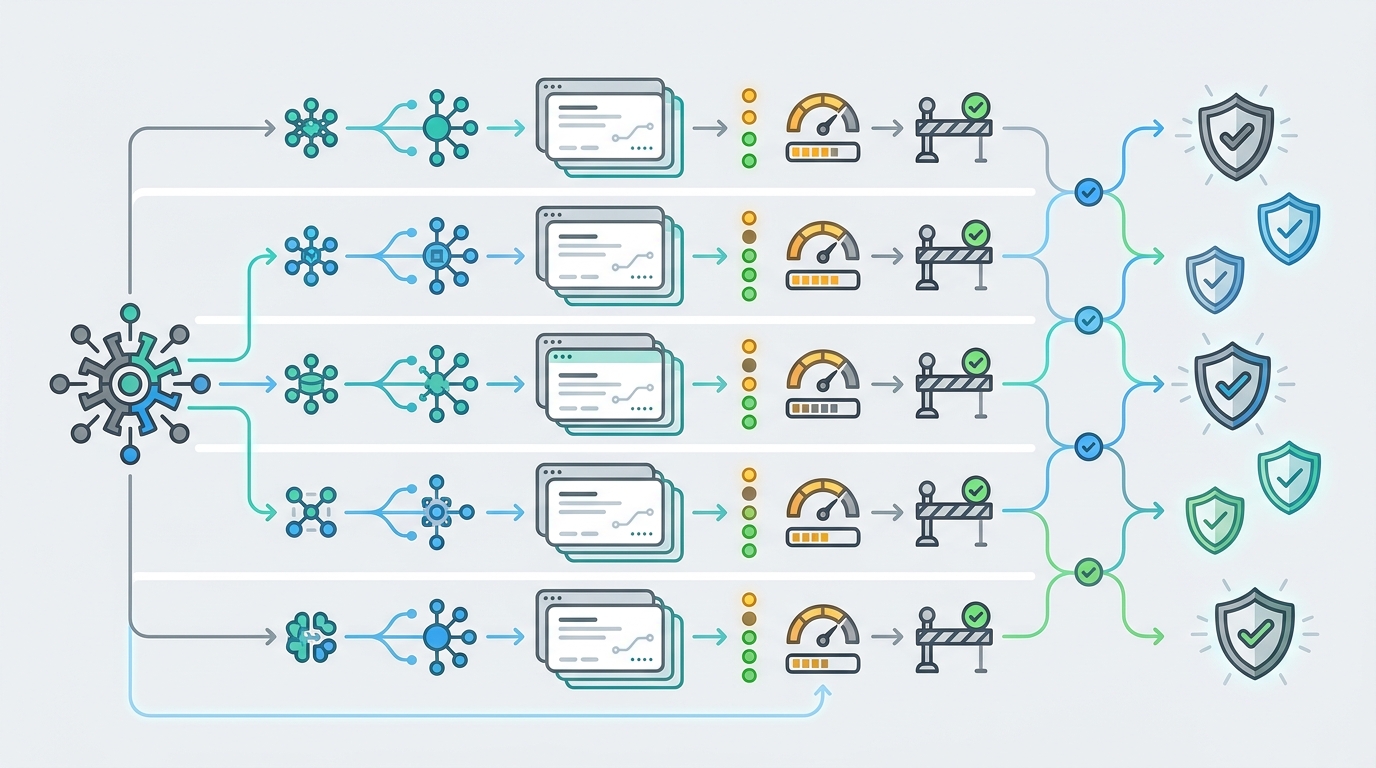
只有当 AI 模型目录能帮助团队做出生产决策时,它才真正有用。只有一页模型名称还不够。开发者需要知道哪个提供商拥有该模型、应用将调用哪个端点系列、哪个分组或路由层级会承载流量、该行当前是否可用,以及在第一个真实用户请求通过它之前,价格是如何计量的。
这份 AI 模型目录指南已于 June 24, 2026 根据 Flatkey 公开页面、实时 Flatkey pricing API、已保存的 Ahrefs 研究,以及 Microsoft、Google、Vercel 和 OpenAI 的官方模型目录文档进行核对。请将每一个目录数量、状态、端点系列和价格字段都视为某个时间点的快照。在生产流量到来之前,请重新打开 Flatkey pricing,确认准确的模型行,并运行一次低风险路由测试。
实际目标很简单:把模型浏览变成可重复的评审流程。如果你的团队能从同一条 AI 模型目录记录中读出提供商、端点、分组、状态、价格和负责人,那么工程、财务、支持和采购就更容易批准模型决策。
快速回答:如何解读 AI 模型目录
请从左到右读取 AI 模型目录:先看提供商,其次是端点,第三是分组,第四是状态,第五是价格,最后进行路由测试。这个顺序可以避免团队选择一个名称看起来很有吸引力、但无法通过应用实际使用的端点、分组或预算策略安全调用的模型。
| 目录字段 | 它告诉你什么 | 需要做出的决策 | Flatkey 检查 |
|---|---|---|---|
| 提供商 | 谁提供或托管该模型路由。 | 这个提供商能否满足你的功能、风险和支持预期? | 确认供应商记录以及任何提供商特定的行备注。 |
| 模型 ID | 你的应用将请求的准确字符串。 | 应用能否使用这个 ID,而不受别名漂移或过期文档影响? | 从 /pricing 复制模型行,而不是凭记忆填写。 |
| 端点系列 | 协议形态:聊天、responses、图像生成、视频、Gemini、Anthropic 或其他路由。 | 当前 SDK、请求体、流式模式和响应解析器是否匹配? | 更改 base URL 前,先检查受支持的端点系列。 |
| 分组 | 承载请求的路由层级或资源池。 | 哪个分组应处理预发、生产、回退或成本敏感型流量? | 上线前比较准确的分组标签和分组比例。 |
| 状态 | 最新目录检查是否正常、不受官方支持或尚未解析。 | 这一行应接收生产流量、冒烟测试,还是不接收流量? | 在状态与请求测试一致前,不要把可见行视为可用。 |
| 计价单位 | 使用量如何计费:输入、输出、缓存、图像、视频、秒,或固定作业式单位。 | 应使用哪种预算公式和配额? | 分别审查 token 类字段和非 token 价格字段。 |
| 路由测试 | 该模型是否适用于准确的功能路径。 | 工程、财务和支持能否接受结果? | 运行一次预发请求,然后检查使用量、成本、状态和日志。 |
当前 Flatkey AI 模型目录快照
本文使用的实时 Flatkey pricing API 快照在 June 24, 2026 返回了 success: true。它暴露了 637 个目录行、23 条供应商记录、五个可用分组标签,以及六个端点系列。响应中的顶层定价版本为 a42d372ccf0b5dd13ecf71203521f9d2。
| 快照字段 | June 24, 2026 的值 | 如何使用它 |
|---|---|---|
| 目录行总数 | 637 | 将 AI 模型目录作为行级来源,而不是静态提供商列表。 |
| 供应商记录 | 23 | 提供商身份会影响支持、合规和回退决策。 |
| 端点系列 | openai, gemini, image-generation, anthropic, openai-response, openai-video |
端点系列会告诉你当前请求格式是否可行。 |
| 可用性状态 | available, official_unsupported, unknown_failure |
状态应驱动流量准入和冒烟测试优先级。 |
| 可用行 | 132 | 仍然需要针对你的端点、分组、提示词和配额进行路由测试。 |
| 官方不支持行 | 37 | 除非有更新且已验证的状态,否则不要将这些用于生产。 |
| 未知失败行 | 468 | 在检查路由、账号、上游或状态证据之前,将其视为未解析。 |
Flatkey 的公开主页围绕一个 API key、OpenAI 兼容的 base URL https://router.flatkey.ai/v1、清晰定价、统一账单,以及一个用于密钥、使用量和路由的仪表盘来定位产品。这些主张让 AI 模型目录具备了运营价值,但并不能免除你验证产品将要调用的具体行的必要性。
先读提供商,再读模型名称
模型名称会在供应商、网关、文档和别名之间流转。提供商身份是第一个稳定字段。它告诉你谁提供模型路由、可能涉及哪个账号或上游、支持预期来自哪里,以及该模型应归入直接提供商方案、网关路由,还是受限评估路径。
官方云目录也认真对待同一个问题。Microsoft Foundry Models 将 Azure 销售的模型与合作伙伴和社区模型区分开,并告诉客户在选择模型前审查模型说明、模型卡、文档和法律条款。Google Model Garden 允许团队按模型集合和提供商筛选,然后打开模型卡获取更多细节。对任何 AI 模型目录来说,经验都是一样的:提供商不是装饰信息,而是运营契约的一部分。
评估 Flatkey 时,请记录:
- 提供商或供应商:与该行关联的供应商记录。
- 模型行:Flatkey pricing 中可见的准确模型 ID。
- 负责人:请求该模型的团队、功能、客户或预算负责人。
- 选择理由:质量、成本、延迟、模态、上下文、工具使用、图像、视频或回退行为。
- 替代路由:如果提供商行状态发生变化,应用应使用什么。
把端点当作契约来读,而不是标签
端点系列会告诉你的应用应预期什么样的请求和响应形态。出现在 openai 端点系列下的模型,可能适合 OpenAI 兼容的 SDK 流程。出现在 anthropic、gemini、image-generation、openai-response 或 openai-video 下的模型,可能需要不同的请求体、解析器、流式行为、文件处理路径或使用量解释方式。
这就是为什么有用的 AI 模型目录应与迁移计划一起阅读。如果你的应用已经使用 OpenAI 兼容客户端,请从 OpenAI-compatible API migration 工作流开始:在预发环境中更改 base URL,保持模型 ID 明确,运行一个小请求,检查响应,然后审查日志和成本。不要假设每个模型行都支持每一种端点风格。
| 端点系列 | 需要检查什么 | 常见失败模式 |
|---|---|---|
openai |
Base URL、模型 ID、messages 格式、流式传输、工具调用、JSON mode、使用量字段。 | SDK 调用在语法上成功,但使用的模型行并不支持该功能。 |
openai-response |
Responses 风格请求体、输出解析、工具行为、多模态输入。 | Chat completions 假设泄漏到 Responses 风格工作流中。 |
anthropic |
Messages 请求形态、system prompt 处理、图像输入行为、使用量字段。 | OpenAI 风格的 body 在没有适配的情况下被发送到 Anthropic 风格路由。 |
gemini |
Gemini 请求形态、多模态输入、安全设置、响应解析。 | 模型选择忽略了提供商特定的功能或响应差异。 |
image-generation |
输入图像规则、输出尺寸、质量、审核、格式,以及可接受的结果数量。 | 按请求数做预算会掩盖图像质量和重试成本。 |
openai-video |
时长、宽高比、异步作业状态、轮询、失败处理,以及使用量单位。 | 视频作业被当作廉价的同步文本调用来处理。 |
将分组作为路由和成本策略来读
在统一网关中,分组不只是标签。它可以代表路由层级、资源池、账号路径或定价策略。June 24 的 Flatkey 快照暴露了可用分组标签,包括 Economy、Standard、Claude Economy、Claude Official 和 Seedance2.0 Official。响应还包含了分组说明和分组比例。
阅读 AI 模型目录时,分组可以回答模型名称无法回答的问题:
- 预发应使用哪个分组?低风险路由可能足以满足集成测试。
- 生产应使用哪个分组?生产可能需要不同的提供商路径、成本画像或支持预期。
- 回退应使用哪个分组?回退路由必须兼容质量、延迟和预算要求。
- 财务应审查哪个分组?分组级比例可能会改变同一个模型名称的实际成本。
- 采购应批准哪个分组?直接或官方路由可能比经济型路由需要不同的证据。
安全的习惯是在模型决策中记录分组,而不只是模型 ID。在一个分组中看起来合理的模型行,在另一个分组中可能具有不同的成本或运营路径。
比较模型行之前,先按单位读价格
价格字段很容易被误读,因为不同模型系列会暴露不同单位。文本模型通常会区分输入、缓存输入和输出。图像和视频行可能会增加质量设置、生成媒体单位、作业时长或固定 model-price 风格字段。例如,OpenAI 的公开定价页面会按每 1M tokens 分别列出其模型的输入、缓存输入和输出价格。Google Model Garden 提到,开源模型使用可能涉及调优和部署计算费用。Microsoft Foundry 提到,无服务器部署通常按 API 输入和输出计费,通常以 tokens 计量,而托管计算使用虚拟机核心小时计费。
进行 Flatkey AI 模型目录评审时,请先区分价格形态,再比较模型行:
| 价格形态 | 需要检查的字段 | 预算问题 |
|---|---|---|
| Token 风格文本 | model_ratio, completion_ratio, cache_ratio |
该功能会更多花费在提示词、输出、缓存上下文还是重试上? |
| 多模态聊天 | 端点系列、输入 tokens、输出 tokens、图像/视频输入、缓存行为。 | 非文本输入是否正在改变实际成本? |
| 图像生成 | 模型行、端点系列、输出设置、重试次数、接受的图像数量。 | 在失败和编辑之后,一张被接受的图像成本是多少? |
| 视频生成 | 模型行、时长、质量、作业状态、重试策略,以及存在时的 model_price。 |
配额能否在预算事故发生前阻止昂贵作业? |
| 分组调整路由 | 分组标签、分组比例、生产路由、回退路由。 | 团队比较的是实际会使用的分组吗? |
如需更深入的成本工作流,请在入围模型行后使用 AI model pricing comparison 指南。这份 AI 模型目录指南帮助你先判断哪些行值得做价格分析。
在生产流量前读取状态
可见的目录行并不等同于可用于生产的路由。在 June 24 的 Flatkey 快照中,637 行里只有 132 行的最新可用性状态为 available。其余行分布在 official_unsupported 和 unknown_failure 之间。这并不表示每个未解析行都永久不可用;它表示该行在承载用户流量之前,需要当前路由证据。
将状态作为准入门槛:
- Available:针对你的准确端点、分组、请求体和提示词形态运行一次预发冒烟测试。
- Official unsupported:除非更新来源证明状态已改变,否则不要启动生产流量。
- Unknown failure:调查问题是否来自上游状态、账号权限、路由配置、区域、配额或瞬时失败。
- 没有明确状态:在仪表盘或 API 测试产生证据之前,将该行视为未获批准。
- 状态已变化:更新模型决策记录,并在重新路由用户前通知负责人。
状态字段也是财务控制。一个回退路由如果悄悄从干净的低成本行移到未解析或更昂贵的行,可能会把模型实验变成事故。在每一次 AI 模型目录评审中,请把状态、分组和价格放在一起看。
用于目录评审的 Flatkey 工作流
当团队请求在一个 key 后添加或更换模型时,请使用这个工作流。
- 打开当前目录:从 Flatkey pricing 开始,并复制准确的行。
- 记录提供商和分组:不要只用模型名称来批准某一行。
- 确认端点系列:将路由与你的 SDK、请求体、流式计划和解析器匹配。
- 检查状态:只有在状态和实时请求一致之后,才路由生产流量。
- 分类计价单位:token、缓存、图像、视频、时长、固定价格,或分组调整路由。
- 运行低风险测试:通过
https://router.flatkey.ai/v1或相关路由系列发送预发请求。 - 审查使用量和成本:在仪表盘中检查模型、使用量、成本、状态和路由证据。
- 设置配额和负责人:将该行连接到 key、预算负责人、限制、告警和回滚路由。
- 保存决策:把目录行、日期、状态、分组、价格字段、测试结果和负责人签核保存在一起。
这也是工程与财务之间清晰的交接点。工程证明路由可用。财务证明单位和负责人合理。支持证明当客户询问功能为何变化时,可以解释这项模型决策。
模板:AI 模型目录评审记录
为每一个进入预发或生产的模型行保留一条紧凑记录。这会把 AI 模型目录浏览变成一种运营习惯。
AI 模型目录评审记录
评审日期:
请求人:
功能或工作流:
环境:development / staging / production / batch / customer-facing
模型行:
提供商或供应商:
端点系列:
分组:
可用性状态:
价格字段:
预期单位:input tokens / output tokens / cached input / image / video / duration / fixed job
路由测试:
请求路径:
SDK 或客户端:
响应接受:yes / no
使用量可见:yes / no
成本可见:yes / no
已关联配额:yes / no
负责人:
预算负责人:
支持负责人:
回退路由:
回滚条件:
下次评审日期:
常见 AI 模型目录错误
| 错误 | 为什么会带来风险 | 更好的评审方式 |
|---|---|---|
| 只按模型名称选择 | 别名、提供商、端点系列和分组都可能不同。 | 批准准确的行:提供商、端点、分组、状态、价格、负责人。 |
| 假设 OpenAI-compatible 意味着所有功能都可用 | 工具使用、流式传输、图像、视频和响应格式可能因路由而异。 | 上线前运行一次功能级冒烟测试。 |
| 忽略分组标签 | 同一个模型名称可能因分组而具有不同的成本或路由行为。 | 记录生产分组并比较分组比例。 |
| 把未解析状态视为无害 | 未知失败可能隐藏路由、权限、上游或账号问题。 | 在状态和请求证据都清晰前,先阻断流量。 |
| 不看单位就比较价格 | 输入 tokens、输出 tokens、缓存 tokens、图像和视频作业不能用同一种预算方式处理。 | 在使用对比表之前,先分类计价单位。 |
统一 AI 模型目录什么时候最有帮助
当你的产品已经跨越多个提供商、模态或运营负责人时,统一 AI 模型目录最有帮助。单一提供商原型通常可以从一个官方文档页面开始。生产 AI 产品通常需要更持久的视图:GPT、Claude、Gemini、DeepSeek、Qwen、图像模型、视频模型、路由分组、状态、配额、使用量和成本,都在一个评审循环中。
Flatkey 面向希望使用一个 API key、一个兼容 base URL、统一定价和账单,以及一个用于密钥、使用量和路由的仪表盘的团队。目录评审正是这种价值变得具体的地方。你可以比较模型行、选择路由、测试端点、附加配额,并将使用量证据保存在一个运营路径中,而不是把决策分散到提供商门户和电子表格里。
正确的下一步不是盲目信任某一行。请从当前 model pricing page 开始,复制准确的模型和分组,在预发环境中测试路由,然后在准备好在自己的应用中评估该工作流时 get a key。
FAQ
什么是 AI 模型目录?
AI 模型目录是一个可搜索的模型行列表,包含足够上下文来选择、测试和运营模型。有用的目录应暴露提供商、模型 ID、端点系列、分组或路由层级、可用性状态、计价单位,以及文档或仪表盘证据。
为什么提供商在 AI 模型目录中很重要?
提供商身份会告诉你谁提供或托管路由、可能适用哪些条款和支持预期,以及需要哪些回退或采购审查。仅凭模型名称不足以获得生产批准。
我应该如何比较端点系列?
请按请求形态、SDK 兼容性、流式行为、工具支持、多模态输入、响应解析和使用量字段来比较端点系列。适用于聊天的行,可能不适用于图像、视频、Gemini、Anthropic 或 Responses 风格请求。
什么是模型分组?
模型分组是一个路由或资源标签,可能影响成本、上游路径、支持预期或回退行为。在 Flatkey 中,批准路由前,请将分组与模型 ID 和价格字段一起阅读。
团队应多久重新检查一次 AI 模型目录?
在每次生产发布、模型替换、回退变更、重大价格审查或事故复盘前都应重新检查。AI 模型目录变化很快,因此不应将带日期的快照视为永久可用性或价格保证。
最终目录评审步骤
在模型行进入生产前,请为 AI 模型目录记录中的每个字段指定负责人。工程负责端点匹配和路由测试。财务负责价格单位和预算。支持负责面向客户的影响。平台负责配额、回退和回滚。这样,目录才会从模型菜单变成基础设施。
要运行 Flatkey 版本的评审,请打开 Flatkey pricing,选择一个模型行,确认提供商、端点、分组、状态和价格单位,然后 get a key 并在扩大流量前测试路由。


