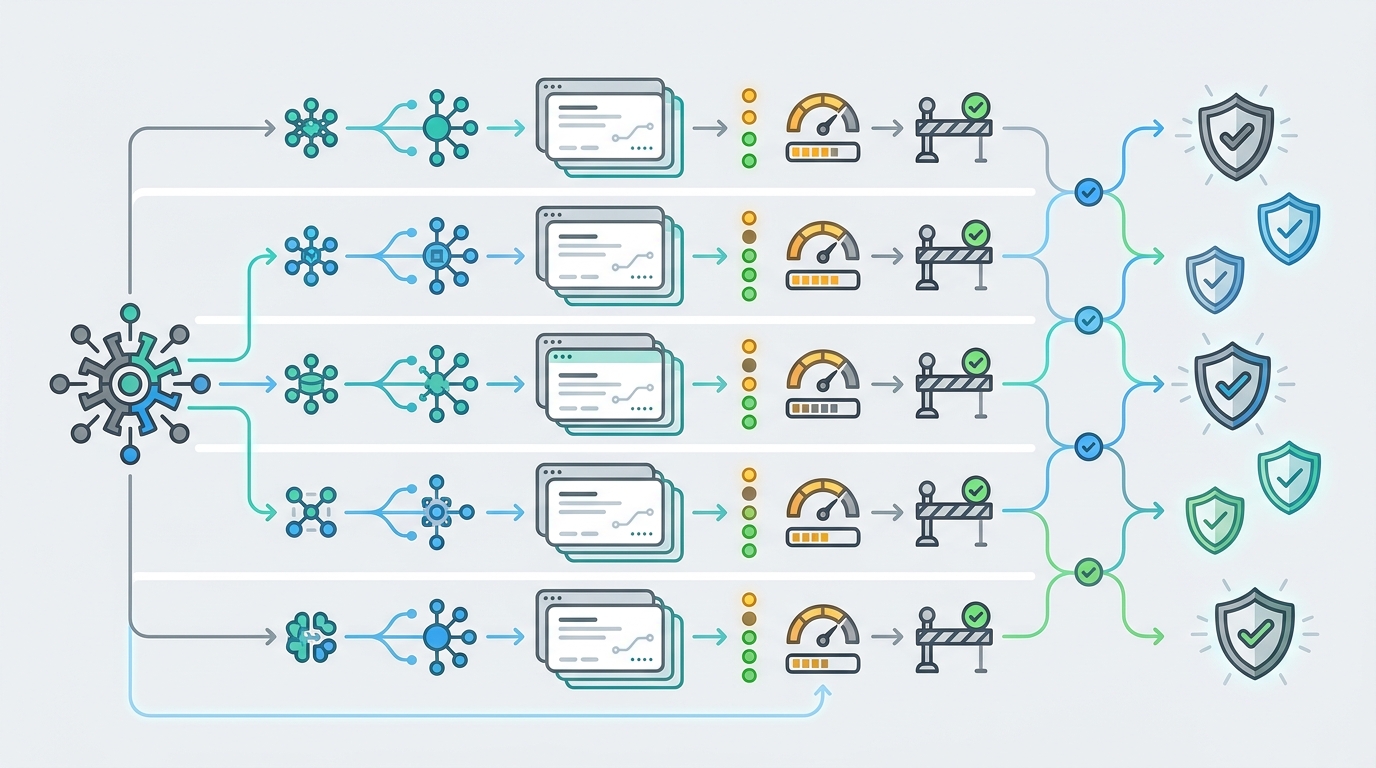
Un catálogo de modelos de IA solo es útil cuando ayuda a un equipo a tomar una decisión de producción. Una página llena de nombres de modelos no basta. Los desarrolladores necesitan saber qué proveedor es responsable del modelo, a qué familia de endpoints llamará la aplicación, qué grupo o nivel de ruta servirá el tráfico, si la fila está disponible actualmente y cómo se mide el precio antes de que pase por ella la primera solicitud de un usuario real.
Esta guía de catálogo de modelos de IA se verificó el June 24, 2026 frente a páginas públicas de Flatkey, la API de precios en vivo de Flatkey, investigación guardada de Ahrefs y documentación oficial de catálogos de modelos de Microsoft, Google, Vercel y OpenAI. Trata cada recuento de catálogo, estado, familia de endpoints y campo de precio como una instantánea de un momento concreto. Antes de enviar tráfico de producción, vuelve a abrir los precios de Flatkey, confirma la fila exacta del modelo y ejecuta una prueba de ruta de bajo riesgo.
El objetivo práctico es sencillo: convertir la exploración de modelos en una revisión repetible. Si tu equipo puede leer proveedor, endpoint, grupo, estado, precio y responsable desde el mismo registro del catálogo de modelos de IA, la decisión sobre el modelo se vuelve más fácil de aprobar para ingeniería, finanzas, soporte y compras.
Respuesta rápida: cómo leer un catálogo de modelos de IA
Lee un catálogo de modelos de IA de izquierda a derecha: primero proveedor, segundo endpoint, tercero grupo, cuarto estado, quinto precio y por último prueba de ruta. Ese orden evita que los equipos elijan un nombre de modelo que parece atractivo pero que no puede llamarse de forma segura mediante el endpoint, el grupo o la política de presupuesto que la aplicación usa realmente.
| Campo del catálogo | Qué te indica | Decisión que debes tomar | Comprobación en Flatkey |
|---|---|---|---|
| Proveedor | Quién suministra o aloja la ruta del modelo. | ¿Puede este proveedor cumplir tus expectativas de funcionalidad, riesgo y soporte? | Confirma el registro del proveedor y cualquier nota de fila específica del proveedor. |
| ID del modelo | La cadena exacta que solicitará tu aplicación. | ¿Puede la aplicación usar este ID sin desviaciones de alias ni documentación obsoleta? | Copia la fila del modelo desde /pricing, no de memoria. |
| Familia de endpoints | La forma del protocolo: chat, responses, generación de imágenes, video, Gemini, Anthropic u otra ruta. | ¿Encajan el SDK actual, el cuerpo de la solicitud, el modo de streaming y el parser de respuestas? | Comprueba la familia de endpoints admitida antes de cambiar la URL base. |
| Grupo | El nivel de ruta o pool de recursos que atiende la solicitud. | ¿Qué grupo debe gestionar staging, producción, fallback o tráfico sensible al coste? | Compara la etiqueta exacta del grupo y la proporción del grupo antes del lanzamiento. |
| Estado | Si la comprobación más reciente del catálogo es correcta, no compatible o no resuelta. | ¿Debe esta fila recibir tráfico de producción, una prueba rápida o ningún tráfico? | No trates una fila visible como disponible hasta que el estado y una prueba de solicitud coincidan. |
| Unidad de precio | Cómo se cobra el uso: entrada, salida, caché, imagen, video, segundo o unidad fija tipo job. | ¿Qué fórmula de presupuesto y qué cuota deben aplicarse? | Revisa por separado los campos de estilo token y los campos de precio que no son tokens. |
| Prueba de ruta | Si el modelo funciona para la ruta exacta de la funcionalidad. | ¿Pueden ingeniería, finanzas y soporte aceptar el resultado? | Ejecuta una solicitud en staging y luego revisa uso, coste, estado y registros. |
Instantánea actual del catálogo de modelos de IA de Flatkey
La instantánea de la API de precios en vivo de Flatkey usada para este artículo devolvió success: true el June 24, 2026. Expuso 637 filas de catálogo, 23 registros de proveedores, cinco etiquetas de grupo utilizables y seis familias de endpoints. La versión de precios de nivel superior en la respuesta fue a42d372ccf0b5dd13ecf71203521f9d2.
| Campo de la instantánea | Valor del June 24, 2026 | Cómo usarlo |
|---|---|---|
| Total de filas del catálogo | 637 | Usa el catálogo de modelos de IA como una fuente a nivel de fila, no como una lista estática de proveedores. |
| Registros de proveedores | 23 | La identidad del proveedor importa para soporte, cumplimiento y decisiones de fallback. |
| Familias de endpoints | openai, gemini, image-generation, anthropic, openai-response, openai-video |
La familia de endpoints te indica si el formato de solicitud actual puede funcionar. |
| Estados de disponibilidad | available, official_unsupported, unknown_failure |
El estado debe guiar el control de tráfico y la prioridad de las pruebas rápidas. |
| Filas disponibles | 132 | Aún requieren una prueba de ruta para tu endpoint, grupo, prompt y cuota. |
| Filas oficialmente no compatibles | 37 | No las uses en producción sin un estado verificado más reciente. |
| Filas con fallo desconocido | 468 | Trátalas como no resueltas hasta comprobar la ruta, la cuenta, el origen upstream o la evidencia de estado. |
La página de inicio pública de Flatkey posiciona el producto en torno a una clave de API, la URL base compatible con OpenAI https://router.flatkey.ai/v1, precios claros, facturación unificada y un panel único para claves, uso y enrutamiento. Esas afirmaciones hacen que el catálogo de modelos de IA sea útil operativamente, pero no eliminan la necesidad de verificar la fila específica que llamará tu producto.
Lee los proveedores antes de leer los nombres de modelos
Los nombres de modelos se mueven entre proveedores, gateways, documentación y alias. La identidad del proveedor es el primer campo estabilizador. Te indica quién suministra la ruta del modelo, qué cuenta u origen upstream puede estar implicado, de dónde vienen las expectativas de soporte y si el modelo pertenece a un plan directo con el proveedor, una ruta de gateway o una ruta de evaluación restringida.
Los catálogos oficiales en la nube se toman en serio el mismo problema. Microsoft Foundry Models separa los modelos vendidos por Azure de los modelos de partners y de la comunidad, y pide a los clientes revisar descripciones de modelos, model cards, documentación y términos legales antes de seleccionar un modelo. Google Model Garden permite a los equipos filtrar por colecciones de modelos y proveedores, y luego abrir model cards para más detalle. La lección para cualquier catálogo de modelos de IA es la misma: el proveedor no es decoración; forma parte del contrato operativo.
Para evaluar en Flatkey, anota:
- Proveedor o vendor: el registro de proveedor asociado con la fila.
- Fila del modelo: el ID exacto del modelo visible en los precios de Flatkey.
- Responsable: el equipo, funcionalidad, cliente o responsable de presupuesto que solicita el modelo.
- Motivo de selección: calidad, coste, latencia, modalidad, contexto, uso de herramientas, imagen, video o comportamiento de fallback.
- Ruta de reemplazo: qué debe usar la aplicación si la fila del proveedor cambia de estado.
Lee los endpoints como contratos, no como etiquetas
Una familia de endpoints le indica a tu aplicación qué forma de solicitud y respuesta debe esperar. Un modelo que aparece bajo una familia de endpoints openai puede encajar en un flujo de SDK compatible con OpenAI. Un modelo que aparece bajo anthropic, gemini, image-generation, openai-response u openai-video puede necesitar un cuerpo de solicitud, parser, comportamiento de streaming, ruta de gestión de archivos o interpretación de uso diferentes.
Por eso un catálogo de modelos de IA útil debe leerse junto con el plan de migración. Si tu aplicación ya usa un cliente compatible con OpenAI, empieza con el flujo de trabajo de migración de API compatible con OpenAI: cambia la URL base en staging, mantén explícito el ID del modelo, ejecuta una solicitud pequeña, inspecciona la respuesta y luego revisa registros y coste. No asumas que cada fila de modelo admite cada estilo de endpoint.
| Familia de endpoints | Qué comprobar | Modo de fallo común |
|---|---|---|
openai |
URL base, ID del modelo, formato de mensajes, streaming, llamadas a herramientas, modo JSON, campos de uso. | La llamada del SDK funciona sintácticamente, pero usa una fila de modelo que no admite la funcionalidad. |
openai-response |
Cuerpo de solicitud estilo Responses, análisis de salida, comportamiento de herramientas, entrada multimodal. | Las suposiciones de chat completions se filtran en un flujo de trabajo estilo Responses. |
anthropic |
Forma de solicitud de mensajes, manejo del prompt de sistema, comportamiento de entrada de imagen, campos de uso. | Se envía un cuerpo estilo OpenAI a una ruta estilo Anthropic sin adaptación. |
gemini |
Forma de solicitud de Gemini, entrada multimodal, ajustes de seguridad, análisis de respuesta. | La selección del modelo ignora diferencias de funcionalidad o respuesta específicas del proveedor. |
image-generation |
Reglas de imagen de entrada, tamaño de salida, calidad, moderación, formato y número de resultados aceptados. | Presupuestar por número de solicitudes oculta los costes de calidad de imagen y reintentos. |
openai-video |
Duración, aspecto, estado de job asíncrono, polling, gestión de fallos y unidad de uso. | Los jobs de video se tratan como llamadas de texto síncronas y baratas. |
Lee los grupos como política de ruta y coste
En un gateway unificado, un grupo no es solo una etiqueta. Puede representar un nivel de ruta, un pool de recursos, una ruta de cuenta o una política de precios. La instantánea de Flatkey del June 24 expuso etiquetas de grupo utilizables, incluidas Economy, Standard, Claude Economy, Claude Official y Seedance2.0 Official. La respuesta también incluía descripciones de grupos y proporciones de grupos.
Al leer un catálogo de modelos de IA, los grupos responden preguntas que un nombre de modelo no puede:
- ¿Qué grupo debe usar staging? Una ruta de bajo riesgo puede bastar para pruebas de integración.
- ¿Qué grupo debe usar producción? Producción puede necesitar una ruta de proveedor, un perfil de coste o una expectativa de soporte diferentes.
- ¿Qué grupo debe usar fallback? Una ruta de fallback debe ser compatible con los requisitos de calidad, latencia y presupuesto.
- ¿Qué grupo debe revisar finanzas? Las proporciones a nivel de grupo pueden cambiar el coste efectivo para el mismo nombre de modelo.
- ¿Qué grupo debe aprobar compras? Una ruta directa u oficial puede requerir evidencias distintas a las de una ruta económica.
El hábito seguro es registrar el grupo en la decisión del modelo, no solo el ID del modelo. Una fila de modelo que parecía razonable en un grupo puede tener un coste o una ruta operativa diferentes en otro grupo.
Lee los precios por unidad antes de comparar filas
Los campos de precio son fáciles de malinterpretar porque distintas familias de modelos exponen distintas unidades. Los modelos de texto suelen separar entrada, entrada en caché y salida. Las filas de imagen y video pueden añadir ajustes de calidad, unidades de medios generados, duración del job o campos de estilo precio fijo del modelo. La página pública de precios de OpenAI, por ejemplo, separa precios de entrada, entrada en caché y salida por 1M tokens para sus modelos. Google Model Garden señala que el uso de modelos open source puede implicar cargos de cómputo por ajuste y despliegue. Microsoft Foundry indica que los despliegues serverless suelen facturarse por entradas y salidas de API, a menudo en tokens, mientras que el cómputo gestionado usa horas de núcleo de máquina virtual.
Para una revisión del catálogo de modelos de IA de Flatkey, separa las formas de precio antes de comparar filas:
| Forma de precio | Campos que revisar | Pregunta de presupuesto |
|---|---|---|
| Texto estilo token | model_ratio, completion_ratio, cache_ratio |
¿La funcionalidad gastará más en prompts, salidas, contexto en caché o reintentos? |
| Chat multimodal | Familia de endpoints, tokens de entrada, tokens de salida, entradas de imagen/video, comportamiento de caché. | ¿Las entradas que no son texto cambian el coste efectivo? |
| Generación de imágenes | Fila del modelo, familia de endpoints, ajustes de salida, número de reintentos, número de imágenes aceptadas. | ¿Cuánto cuesta una imagen aceptada después de fallos y ediciones? |
| Generación de video | Fila del modelo, duración, calidad, estado del job, política de reintentos, model_price si está presente. |
¿Puede la cuota detener jobs costosos antes de un incidente de presupuesto? |
| Ruta ajustada por grupo | Etiqueta de grupo, proporción de grupo, ruta de producción, ruta de fallback. | ¿El equipo está comparando el grupo que realmente usará? |
Para un flujo de trabajo de coste más profundo, usa la guía de comparación de precios de modelos de IA después de preseleccionar filas. Esta guía de catálogo de modelos de IA te ayuda a decidir qué filas merecen análisis de precios en primer lugar.
Lee el estado antes del tráfico de producción
Una fila visible del catálogo no es lo mismo que una ruta lista para producción. En la instantánea de Flatkey del June 24, solo 132 de 637 filas tenían available como estado de disponibilidad más reciente. Las filas restantes se dividían entre official_unsupported y unknown_failure. Eso no significa que cada fila no resuelta sea permanentemente inutilizable; significa que la fila necesita evidencia actual de ruta antes de transportar tráfico de usuarios.
Usa el estado como una puerta de control:
- Disponible: ejecuta una prueba rápida en staging para tu endpoint, grupo, cuerpo de solicitud y forma de prompt exactos.
- Oficialmente no compatible: no lances tráfico de producción a menos que una fuente más reciente demuestre que el estado cambió.
- Fallo desconocido: investiga si el problema es estado upstream, permiso de cuenta, configuración de ruta, región, cuota o fallo transitorio.
- Sin estado claro: trata la fila como no aprobada hasta que una prueba en panel o API genere evidencia.
- Estado cambiado: actualiza el registro de decisión del modelo y notifica al responsable antes de redirigir usuarios.
El campo de estado también es un control financiero. Una ruta de fallback que se mueve silenciosamente de una fila limpia de bajo coste a una fila no resuelta o más cara puede convertir un experimento de modelo en un incidente. Mantén estado, grupo y precio juntos en cada revisión del catálogo de modelos de IA.
Un flujo de trabajo de Flatkey para revisar el catálogo
Usa este flujo cuando un equipo solicite añadir o cambiar un modelo detrás de una clave.
- Abre el catálogo actual: empieza desde los precios de Flatkey y copia la fila exacta.
- Registra proveedor y grupo: no apruebes una fila usando solo el nombre del modelo.
- Confirma la familia de endpoints: haz coincidir la ruta con tu SDK, cuerpo de solicitud, plan de streaming y parser.
- Comprueba el estado: enruta tráfico de producción solo después de que el estado y una solicitud en vivo coincidan.
- Clasifica la unidad de precio: token, caché, imagen, video, duración, precio fijo o ruta ajustada por grupo.
- Ejecuta una prueba de bajo riesgo: envía una solicitud en staging mediante
https://router.flatkey.ai/v1o la familia de ruta relevante. - Revisa uso y coste: inspecciona el panel para obtener evidencia de modelo, uso, coste, estado y enrutamiento.
- Define cuota y responsable: conecta la fila con una clave, responsable de presupuesto, límite, alerta y ruta de rollback.
- Guarda la decisión: conserva juntos la fila del catálogo, fecha, estado, grupo, campos de precio, resultado de prueba y aprobación del responsable.
Este también es el traspaso claro entre ingeniería y finanzas. Ingeniería demuestra que la ruta funciona. Finanzas demuestra que la unidad y el responsable tienen sentido. Soporte demuestra que la decisión sobre el modelo puede explicarse cuando un cliente pregunta por qué cambió una funcionalidad.
Plantilla: registro de revisión del catálogo de modelos de IA
Mantén un registro compacto para cada fila de modelo que llegue a staging o producción. Esto convierte la exploración del catálogo de modelos de IA en un hábito operativo.
Registro de revisión del catálogo de modelos de IA
Fecha de revisión:
Solicitante:
Funcionalidad o flujo de trabajo:
Entorno: development / staging / production / batch / customer-facing
Fila del modelo:
Proveedor o vendor:
Familia de endpoints:
Grupo:
Estado de disponibilidad:
Campos de precio:
Unidad esperada: input tokens / output tokens / cached input / image / video / duration / fixed job
Prueba de ruta:
Ruta de solicitud:
SDK o cliente:
Respuesta aceptada: sí / no
Uso visible: sí / no
Coste visible: sí / no
Cuota asociada: sí / no
Responsable:
Responsable de presupuesto:
Responsable de soporte:
Ruta de fallback:
Condición de rollback:
Próxima fecha de revisión:
Errores comunes en catálogos de modelos de IA
| Error | Por qué crea riesgo | Mejor revisión |
|---|---|---|
| Elegir solo por nombre del modelo | Los alias, proveedores, familias de endpoints y grupos pueden diferir. | Aprueba la fila exacta: proveedor, endpoint, grupo, estado, precio, responsable. |
| Asumir que compatible con OpenAI significa que todas las funcionalidades funcionan | El uso de herramientas, streaming, imágenes, video y formatos de respuesta pueden variar según la ruta. | Ejecuta una prueba rápida a nivel de funcionalidad antes del lanzamiento. |
| Ignorar las etiquetas de grupo | El mismo nombre de modelo puede tener distinto coste o comportamiento de ruta según el grupo. | Registra el grupo de producción y compara las proporciones de grupo. |
| Tratar un estado no resuelto como inofensivo | Los fallos desconocidos pueden ocultar problemas de ruta, permisos, upstream o cuenta. | Bloquea el tráfico hasta que el estado y la evidencia de solicitud estén limpios. |
| Comparar precios sin unidades | Los tokens de entrada, tokens de salida, tokens en caché, imágenes y jobs de video no se presupuestan de la misma manera. | Clasifica la unidad de precio antes de usar una tabla de comparación. |
Cuándo ayuda más un catálogo unificado de modelos de IA
Un catálogo de modelos de IA unificado ayuda más cuando tu producto ya abarca más de un proveedor, modalidad o responsable operativo. Un prototipo de un solo proveedor suele poder empezar desde una página de documentación oficial. Un producto de IA en producción normalmente necesita una vista más duradera: GPT, Claude, Gemini, DeepSeek, Qwen, modelos de imagen, modelos de video, grupos de enrutamiento, estado, cuotas, uso y coste en un único ciclo de revisión.
Flatkey está diseñado para equipos que quieren una clave de API, una URL base compatible, precios y facturación unificados, y un panel único para claves, uso y enrutamiento. La revisión del catálogo es donde ese valor se vuelve concreto. Puedes comparar filas, elegir una ruta, probar el endpoint, asociar cuota y mantener evidencia de uso en una sola ruta operativa en lugar de repartir la decisión entre portales de proveedores y hojas de cálculo.
El siguiente paso correcto no es confiar ciegamente en una fila. Empieza con la página actual de precios de modelos, copia el modelo y el grupo exactos, prueba la ruta en staging y luego obtén una clave cuando estés listo para evaluar el flujo en tu propia aplicación.
Preguntas frecuentes
¿Qué es un catálogo de modelos de IA?
Un catálogo de modelos de IA es una lista consultable de filas de modelos con suficiente contexto para elegir, probar y operar un modelo. Un catálogo útil debe exponer proveedor, ID del modelo, familia de endpoints, grupo o nivel de ruta, estado de disponibilidad, unidad de precio y evidencia de documentación o panel.
¿Por qué importa el proveedor en un catálogo de modelos de IA?
La identidad del proveedor te indica quién suministra o aloja la ruta, qué términos y expectativas de soporte pueden aplicarse, y qué revisión de fallback o compras se necesita. El nombre del modelo por sí solo no basta para la aprobación de producción.
¿Cómo debo comparar familias de endpoints?
Compara las familias de endpoints por forma de solicitud, compatibilidad con SDK, comportamiento de streaming, soporte de herramientas, entrada multimodal, análisis de respuesta y campos de uso. Una fila que funciona para chat puede no funcionar para solicitudes de imagen, video, Gemini, Anthropic o estilo Responses.
¿Qué es un grupo de modelos?
Un grupo de modelos es una etiqueta de ruta o recurso que puede afectar al coste, la ruta upstream, la expectativa de soporte o el comportamiento de fallback. En Flatkey, lee el grupo junto con el ID del modelo y los campos de precio antes de aprobar una ruta.
¿Con qué frecuencia deben los equipos volver a comprobar un catálogo de modelos de IA?
Vuelve a comprobarlo antes de cada lanzamiento a producción, cambio de modelo, cambio de fallback, revisión importante de precios o seguimiento de incidentes. Los catálogos de modelos de IA cambian rápidamente, por lo que las instantáneas fechadas no deben tratarse como garantías permanentes de disponibilidad o precios.
Paso final de revisión del catálogo
Antes de que una fila de modelo llegue a producción, asigna un responsable a cada campo del registro del catálogo de modelos de IA. Ingeniería es responsable del encaje del endpoint y las pruebas de ruta. Finanzas es responsable de la unidad de precio y el presupuesto. Soporte es responsable del impacto de cara al cliente. Plataforma es responsable de la cuota, el fallback y el rollback. Así es como un catálogo se convierte en infraestructura en lugar de un menú de modelos.
Para ejecutar la versión de Flatkey de la revisión, abre los precios de Flatkey, selecciona una fila de modelo, confirma proveedor, endpoint, grupo, estado y unidad de precio, luego obtén una clave y prueba la ruta antes de escalar el tráfico.


