Every AI product eventually outgrows a single default model. A support bot, code reviewer, invoice extractor, image prompt helper, and internal research agent do not need the same latency target, context budget, reasoning depth, tool behavior, fallback rule, or approval trail. A model routing policy turns those tradeoffs into an operating contract instead of a pile of ad hoc model= strings.
The goal is not to choose one "best" model. The goal is to make model choice reviewable. A good model routing policy tells engineers which model class to use, when to spend more, when to optimize for latency, when to block fallback, and what evidence must exist before a workflow moves to production.
Flatkey matters in this discussion because routing is easier to govern when model access, keys, request logs, usage analytics, pricing review, and operational controls live in one place. Use the policy below as the design layer, then validate the current Flatkey model catalog and pricing page before production rollout.
Model routing policy design in one table
Start with workflow classes, not provider names. The table below is the practical first pass for a model routing policy.
| Workflow class | Primary route | Cost rule | Latency rule | Risk rule | Fallback rule | Required evidence |
|---|---|---|---|---|---|---|
| Fast classification | Small or low-reasoning text model | Lowest cost that passes evals | Tight p95 target | Low business risk | Safe to retry or downgrade | Accuracy sample, p95 latency, cost per 1,000 calls |
| Customer chat | Balanced model with tool support | Cap by conversation or account | Low p95 and stable streaming | Medium risk | Fallback only to models with tested tone and tool behavior | Conversation evals, refusal checks, tool-call success, transcript QA |
| Code and technical reasoning | Strong reasoning model | Spend more only on hard tasks | Looser latency budget | Medium to high risk | Fallback to reviewed peer route, not to a weak model | Task evals, diff correctness, tool trace, rollback path |
| Structured extraction | Model with schema support | Optimize per valid record | Batch or near-real-time | Medium risk | Retry with same or stricter route before fallback | Schema-valid rate, field accuracy, error taxonomy |
| Procurement or finance review | Pinned reviewed model route | Cost secondary to auditability | Async acceptable | High risk | No automatic fallback without approval | Source trace, model version, request log, reviewer sign-off |
| Background summarization | Lower-cost route or batch-friendly route | Minimize cost per accepted summary | Async | Low to medium risk | Fallback after retry budget is exhausted | Sample quality, retry rate, cached-token metrics |
This table is not the final policy. It is the decision surface. Each row needs measurable gates before it becomes production routing.
What a model routing policy must decide
A model routing policy is a written rule that maps a workflow to model capabilities, cost ceilings, latency SLOs, fallback behavior, and evidence requirements. It should answer six questions for every production workflow:
- What is the workflow trying to optimize: speed, quality, cost, reliability, safety, modality, context length, or auditability?
- Which capabilities are required: tool calling, structured output, long context, image input, streaming, low reasoning, high reasoning, or provider-specific endpoint support?
- What is the failure budget: retry, fallback, degrade, queue, ask a human, or stop?
- What can change automatically: provider, model size, reasoning effort, timeout, route group, or nothing?
- What must be logged: requested model, served model, route, status, usage units, cost, fallback attempt, and owner?
- What proof is needed before launch: eval score, latency sample, quota test, billing trace, security review, or procurement approval?
OpenAI's current GPT-5.5 guidance is useful here because it treats API configuration as part of model performance, not as an afterthought. The docs call out Responses API state handling, reasoning effort, verbosity, structured outputs, prompt caching, tool design, hosted tools, and state management as factors that affect intelligence, reliability, latency, and cost. That is exactly the kind of dimension a model routing policy should preserve.
Policy dimension 1: workflow risk
Risk is the first routing split because it controls how much automation is allowed.
Low-risk workflows can usually tolerate retries, cheaper routes, and broad fallback. Examples include internal tagging, lightweight summaries, draft suggestions, and non-critical classification. These are good candidates for aggressive cost controls because an occasional retry or review sample is acceptable.
Medium-risk workflows need stronger acceptance tests. Customer support, workflow automation, code suggestions, and sales-assist tools may not require human review every time, but they do require tone checks, tool-call checks, and route evidence when errors occur.
High-risk workflows should be pinned more tightly. Procurement reviews, legal summaries, finance approvals, security decisions, and regulated workflows should not silently fall back to a different model or provider just because the primary route is slow. The model routing policy should require explicit approval before fallback changes the risk posture.
The simple rule: if a human would ask "which model actually answered this?" after a bad outcome, the route needs stronger logging and weaker automatic fallback.
Policy dimension 2: latency and user experience
Latency belongs in the policy because the same model can be acceptable for an async workflow and unacceptable for an interactive product.
For interactive chat, set p50, p95, timeout, and streaming expectations. If time-to-first-token matters, measure it separately from total completion time. For background tasks, define maximum queue time and completion deadline instead.
Do not set a vague rule like "use the fast model." Write the model routing policy as a testable target:
workflow: support_chat_triage
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
timeout_ms: 10000
fallback:
on_timeout: use_reviewed_balanced_route
on_schema_error: retry_same_route_once
on_safety_or_policy_error: stop_and_escalateOpenAI's prompt caching docs are another reminder that latency is not only model selection. Stable prompt prefixes, consistent cache keys, and cache-hit monitoring can materially change latency and input-token cost for repeated workloads. If caching is part of the plan, make it a policy requirement and log cached-token metrics.
Policy dimension 3: cost ceilings
Cost controls should be expressed per workflow outcome, not only per token. A cheap route that fails often can cost more than a stronger route that succeeds on the first attempt.
Use three cost limits:
| Limit | Example | Why it matters |
|---|---|---|
| Per request | Maximum cost for one request, image, video job, or turn | Prevents a single call from surprising finance |
| Per workflow | Maximum cost for a completed ticket, extraction, answer, or document | Accounts for retries and fallback |
| Per owner | Budget by app, team, customer, environment, or key | Keeps spend tied to accountability |
Flatkey's pricing page is useful during this stage because it gives teams a current model and pricing review path, while the product surface emphasizes usage metering, request logs, usage analytics, and cost controls. Before production routing, check the current /pricing page and confirm the model row, endpoint family, and usage unit for the actual workflow.
Policy dimension 4: capability fit
Model routing policy design should start from required capabilities. Price and latency only matter after the route can do the job.
For each workflow, score these capabilities:
| Capability | Route question | Acceptance test |
|---|---|---|
| Tool use | Does the route call required tools correctly? | Tool-call success rate and argument validation |
| Structured output | Does the route satisfy the schema? | Valid JSON/schema rate plus field-level accuracy |
| Long context | Does the route preserve instructions and relevant context? | Long-document eval with expected citations or fields |
| Vision or files | Does the route handle the actual input modality? | Real sample set with size and format coverage |
| Streaming | Does the route preserve event shape and recovery behavior? | SSE/streaming smoke test and timeout handling |
| Safety behavior | Does the route refuse or escalate correctly? | Red-team prompts and refusal/override checks |
OpenAI's Structured Outputs docs recommend schema-backed output when the application needs reliable structure. For a routing policy, that means a route that cannot satisfy the output contract should not be used for structured extraction just because it is cheaper.
Policy dimension 5: fallback boundaries
Fallback is not automatically good. It can rescue uptime, but it can also change behavior, context handling, price, data boundary, tool support, or output shape.
Write fallback rules as explicit transitions:
workflow: invoice_extraction
primary_route: extraction_schema_route
allowed_fallbacks:
- extraction_schema_route_backup
blocked_fallbacks:
- general_chat_route
- creative_writing_route
fallback_triggers:
retry_same_route_once:
- transient_5xx
- rate_limit
stop_and_queue:
- schema_invalid_after_retry
- unsupported_file_type
- compliance_flag
evidence:
log_requested_model: true
log_served_model: true
log_fallback_reason: true
log_usage_units: trueA mature model routing policy separates retry from fallback. Retry means "try the same contract again." Fallback means "change the route." That change should be visible in logs and accepted by the workflow owner.
Policy dimension 6: observability and billing evidence
Routing without evidence is guesswork. Your policy should define the fields that every production request must expose.
| Evidence field | Why it belongs in the policy |
|---|---|
| Workflow name | Connects spend and errors to a business process |
| App, team, key, or customer owner | Enables chargeback and incident ownership |
| Requested model and served model | Shows whether fallback or route substitution happened |
| Endpoint family | Separates chat, responses, image, video, Anthropic, Gemini, and other route shapes |
| Status and error class | Distinguishes provider errors, gateway errors, policy stops, and validation errors |
| Usage units | Lets finance reconcile text, cache, image, audio, and video usage |
| Cost or balance impact | Converts engineering traces into reviewable spend |
| Fallback reason | Explains why the policy changed route |
Flatkey's current public positioning fits this evidence need: one gateway for model access, routing, billing, usage analytics, and operational controls. For this article, the live pricing API check on July 2, 2026 returned success: true and exposed endpoint families including openai, openai-response, anthropic, gemini, image-generation, openai-video, and video. Treat that as dated source evidence, not a promise that every route, model row, or price unit will remain unchanged.
A practical model routing policy template
Use this template as the first version of your internal routing standard.
policy_name: customer_support_v1
owner:
team: support_platform
approver: product_and_finance
workflow:
description: classify, answer, and escalate support requests
environment: production
data_sensitivity: customer_content
route_selection:
primary_route: balanced_support_route
required_capabilities:
- tool_calling
- structured_outputs
- streaming
blocked_routes:
- experimental_models
- unreviewed_provider_routes
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
cost:
max_cost_per_conversation: approved_budget
owner_key: support_platform_prod
risk:
human_review_required_when:
- refund_exception
- legal_or_policy_question
- confidence_below_threshold
fallback:
retry_same_route_once:
- transient_error
- rate_limit
fallback_to_backup_route:
- primary_route_unavailable
stop_without_fallback:
- safety_refusal
- schema_invalid_after_retry
- unapproved_data_region
evidence:
required_logs:
- workflow
- requested_model
- served_model
- endpoint_family
- route_status
- usage_units
- cost_or_balance
- fallback_reason
acceptance_tests:
min_eval_pass_rate: 0.95
max_schema_error_rate: 0.01
max_unreviewed_fallback_rate: 0The exact route names will differ by team. The important part is that the policy makes model choice, fallback, cost, latency, and proof reviewable.
Acceptance tests before production
Do not ship a model routing policy without running tests that simulate normal and failed paths.
- Run a golden dataset through the primary route and record quality, schema validity, latency, and usage.
- Trigger a rate-limit or transient-error path and verify retry behavior.
- Trigger a schema failure and confirm the policy retries, stops, or escalates as written.
- Trigger a blocked fallback and confirm the gateway does not silently change route.
- Compare requested model, served model, endpoint family, and usage units in logs.
- Check whether finance can reconcile the same sample requests to cost, prepaid balance, invoice, or export rows.
- Run a rollback test that pins the previous route or disables fallback.
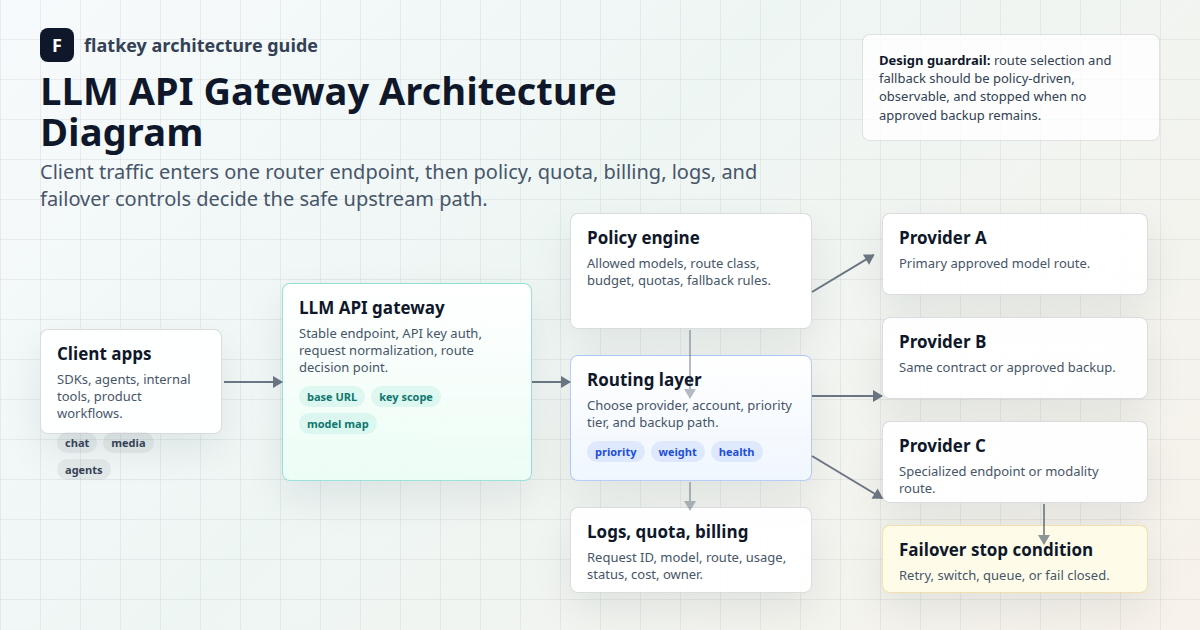
For deeper gateway architecture context, pair this checklist with the Flatkey guides on AI API gateways, LLM API gateway architecture, and AI API load balancing and failover.
Where Flatkey fits
Flatkey should not replace the policy. It should make the policy easier to enforce and review.
Use Flatkey when the team wants one key for connected AI models, a current pricing and model catalog review path, usage visibility, request-level evidence, quotas, and a simpler billing conversation than scattered provider accounts. The model routing policy still needs owners, acceptance tests, route constraints, fallback rules, and rollback plans.
A practical Flatkey proof run looks like this:
- Pick one production-like workflow and one owner key.
- Confirm the current model row and endpoint family on Flatkey pricing.
- Send normal, streaming, structured, and controlled-failure requests if the workflow uses them.
- Review request logs for requested model, served model, status, usage units, and fallback evidence.
- Confirm quota behavior and cost or balance review with the workflow owner.
- Move only the tested route to production, then expand the policy row by row.
This keeps the model routing policy grounded in real evidence instead of an architecture diagram.
FAQ
What is a model routing policy?
A model routing policy is a written rule that maps each AI workflow to an approved model route, capability requirements, cost ceiling, latency target, fallback behavior, and evidence checklist.
Why not route every request to the strongest model?
The strongest route is often slower and more expensive than a workflow needs. A model routing policy lets low-risk workflows use efficient routes while preserving stronger routes for hard reasoning, sensitive decisions, or high-value work.
When should fallback be blocked?
Block fallback when a route change could alter data handling, compliance posture, output schema, tool behavior, user-facing quality, or billing ownership. In those cases, queue, retry, or escalate instead of silently changing model route.
How often should teams update a model routing policy?
Review it whenever model catalogs, pricing units, endpoint behavior, risk requirements, or eval results change. At minimum, review active production policies quarterly and after any major model migration.
What is the first metric to watch?
Watch cost per accepted outcome, not only cost per token. Then pair it with p95 latency, fallback rate, schema-valid rate, and request-level billing evidence.
How does Flatkey help with model routing policy design?
Flatkey can provide one gateway surface for model access, pricing review, routing, usage analytics, request logs, quotas, and billing review. That gives teams a practical place to validate whether the model routing policy is behaving as written.
Start with Flatkey pricing, choose one workflow, then get a key and run a small proof that checks route behavior, logs, quotas, cost, fallback, and rollback before production rollout.