Chaque produit d'IA finit par dépasser le stade du modèle unique par défaut. Un bot de support, un réviseur de code, un extracteur de factures, un assistant de prompt d'image et un agent de recherche interne n'ont pas besoin des mêmes objectifs de latence, budget de contexte, profondeur de raisonnement, comportement des outils, règle de repli ou piste d'approbation. Une politique de routage de modèles transforme ces compromis en un contrat opérationnel plutôt qu'en un tas de chaînes model= ad hoc.
L'objectif n'est pas de choisir un seul « meilleur » modèle. L'objectif est de rendre le choix du modèle révisable. Une bonne politique de routage de modèles indique aux ingénieurs quelle classe de modèle utiliser, quand dépenser plus, quand optimiser la latence, quand bloquer le repli, et quelles preuves doivent exister avant qu'un flux de travail ne passe en production.
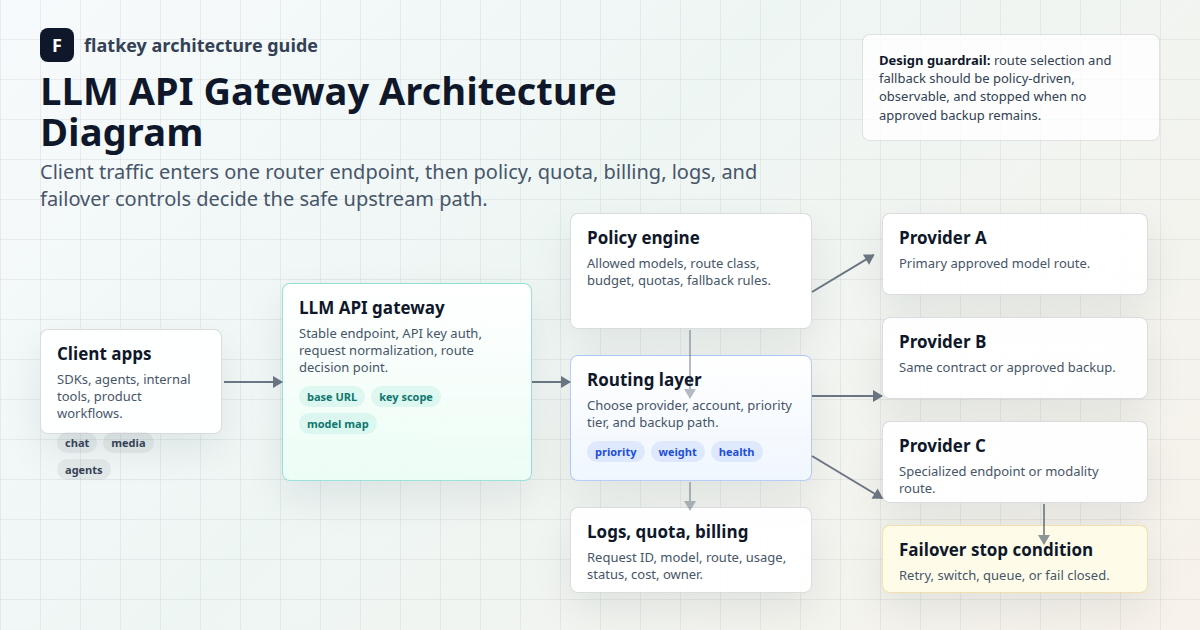
Flatkey est important dans cette discussion car le routage est plus facile à gouverner lorsque l'accès aux modèles, les clés, les journaux de requêtes, les analyses d'utilisation, l'examen des prix et les contrôles opérationnels se trouvent au même endroit. Utilisez la politique ci-dessous comme couche de conception, puis validez le catalogue de modèles et la page de tarification actuels de Flatkey avant le déploiement en production.
Conception d'une politique de routage de modèles dans un seul tableau
Commencez par les classes de flux de travail, pas par les noms de fournisseurs. Le tableau ci-dessous constitue la première ébauche pratique d'une politique de routage de modèles.
| Classe de flux de travail | Route principale | Règle de coût | Règle de latence | Règle de risque | Règle de repli | Preuves requises |
|---|---|---|---|---|---|---|
| Classification rapide | Modèle de texte petit ou à faible raisonnement | Coût le plus bas qui passe les évaluations | Objectif p95 strict | Faible risque commercial | Sûr de réessayer ou de dégrader | Échantillon de précision, latence p95, coût pour 1 000 appels |
| Chat client | Modèle équilibré avec support d'outils | Plafond par conversation ou par compte | p95 faible et streaming stable | Risque moyen | Repli uniquement vers des modèles dont le ton et le comportement des outils ont été testés | Évaluations de conversation, vérifications de refus, succès des appels d'outils, QA des transcriptions |
| Code et raisonnement technique | Modèle à fort raisonnement | Dépenser plus uniquement sur les tâches difficiles | Budget de latence plus souple | Risque moyen à élevé | Repli vers une route homologue examinée, pas vers un modèle faible | Évaluations de tâches, exactitude des diffs, trace des outils, chemin de restauration |
| Extraction structurée | Modèle avec support de schéma | Optimiser par enregistrement valide | Par lots ou quasi-temps réel | Risque moyen | Réessayer avec une route identique ou plus stricte avant le repli | Taux de schémas valides, précision des champs, taxonomie des erreurs |
| Examen des achats ou des finances | Route de modèle examinée et épinglée | Coût secondaire par rapport à l'auditabilité | Asynchrone acceptable | Risque élevé | Pas de repli automatique sans approbation | Trace de la source, version du modèle, journal des requêtes, approbation du réviseur |
| Résumé en arrière-plan | Route à moindre coût ou compatible avec les lots | Minimiser le coût par résumé accepté | Asynchrone | Risque faible à moyen | Repli après épuisement du budget de nouvelles tentatives | Qualité de l'échantillon, taux de nouvelles tentatives, métriques des jetons mis en cache |
Ce tableau n'est pas la politique finale. C'est la surface de décision. Chaque ligne nécessite des portes mesurables avant de devenir un routage de production.
Ce qu'une politique de routage de modèles doit décider
Une politique de routage de modèles est une règle écrite qui associe un flux de travail à des capacités de modèle, des plafonds de coût, des SLO de latence, un comportement de repli et des exigences en matière de preuves. Elle doit répondre à six questions pour chaque flux de travail de production :
- Qu'est-ce que le flux de travail essaie d'optimiser : la vitesse, la qualité, le coût, la fiabilité, la sécurité, la modalité, la longueur du contexte ou l'auditabilité ?
- Quelles capacités sont requises : appel d'outils, sortie structurée, contexte long, entrée d'image, streaming, raisonnement faible, raisonnement élevé ou support de points de terminaison spécifiques au fournisseur ?
- Quel est le budget d'échec : réessayer, se replier, dégrader, mettre en file d'attente, demander à un humain ou arrêter ?
- Qu'est-ce qui peut changer automatiquement : le fournisseur, la taille du modèle, l'effort de raisonnement, le délai d'attente, le groupe de routes ou rien ?
- Que faut-il journaliser : le modèle demandé, le modèle servi, la route, le statut, les unités d'utilisation, le coût, la tentative de repli et le propriétaire ?
- Quelle preuve est nécessaire avant le lancement : score d'évaluation, échantillon de latence, test de quota, trace de facturation, examen de sécurité ou approbation des achats ?
Les directives actuelles de OpenAI pour GPT-5.5 sont utiles ici car elles traitent la configuration de l'API comme faisant partie de la performance du modèle, et non comme une réflexion après coup. La documentation mentionne la gestion de l'état de l'API Responses, l'effort de raisonnement, la verbosité, les sorties structurées, la mise en cache des prompts, la conception des outils, les outils hébergés et la gestion de l'état comme des facteurs qui affectent l'intelligence, la fiabilité, la latence et le coût. C'est exactement le type de dimension qu'une politique de routage de modèles devrait préserver.
Dimension de la politique 1 : risque du flux de travail
Le risque est la première division de routage car il contrôle le degré d'automatisation autorisé.
Les flux de travail à faible risque peuvent généralement tolérer les nouvelles tentatives, les routes moins chères et un repli large. Les exemples incluent l'étiquetage interne, les résumés légers, les suggestions de brouillons et la classification non critique. Ce sont de bons candidats pour des contrôles de coûts agressifs car une nouvelle tentative occasionnelle ou un échantillon pour examen est acceptable.
Les flux de travail à risque moyen nécessitent des tests d'acceptation plus stricts. Le support client, l'automatisation des flux de travail, les suggestions de code et les outils d'aide à la vente peuvent ne pas nécessiter un examen humain à chaque fois, mais ils exigent des vérifications de ton, des vérifications d'appels d'outils et des preuves de route lorsque des erreurs se produisent.
Les flux de travail à haut risque doivent être épinglés plus étroitement. Les examens d'achats, les résumés juridiques, les approbations financières, les décisions de sécurité et les flux de travail réglementés ne devraient pas se replier silencieusement sur un modèle ou un fournisseur différent simplement parce que la route principale est lente. La politique de routage de modèles devrait exiger une approbation explicite avant que le repli ne modifie la posture de risque.
La règle est simple : si un humain se demandait « quel modèle a réellement répondu à cela ? » après un mauvais résultat, la route nécessite une journalisation plus robuste et un repli automatique plus faible.
Dimension de la politique 2 : latence et expérience utilisateur
La latence fait partie de la politique car le même modèle peut être acceptable pour un flux de travail asynchrone et inacceptable pour un produit interactif.
Pour le chat interactif, définissez les attentes en matière de p50, p95, de délai d'attente et de streaming. Si le temps jusqu'au premier jeton est important, mesurez-le séparément du temps de complétion total. Pour les tâches en arrière-plan, définissez plutôt un temps de file d'attente maximal et une date limite de complétion.
Ne définissez pas de règle vague comme « utiliser le modèle rapide ». Rédigez la politique de routage de modèles comme une cible testable :
workflow: support_chat_triage
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
timeout_ms: 10000
fallback:
on_timeout: use_reviewed_balanced_route
on_schema_error: retry_same_route_once
on_safety_or_policy_error: stop_and_escalateLa documentation d'OpenAI sur la mise en cache des invites rappelle que la latence ne se limite pas à la sélection du modèle. Des préfixes d'invite stables, des clés de cache cohérentes et une surveillance des correspondances de cache peuvent modifier considérablement la latence et le coût des jetons d'entrée pour les charges de travail répétées. Si la mise en cache fait partie du plan, faites-en une exigence de la politique et journalisez les métriques des jetons mis en cache.
Dimension de la politique 3 : plafonds de coûts
Les contrôles de coûts doivent être exprimés par résultat de flux de travail, et non seulement par jeton. Une route bon marché qui échoue souvent peut coûter plus cher qu'une route plus robuste qui réussit du premier coup.
Utilisez trois limites de coût :
| Limite | Exemple | Pourquoi c'est important |
|---|---|---|
| Par requête | Coût maximum pour une requête, une tâche d'image, de vidéo ou un tour | Empêche un appel unique de surprendre le service financier |
| Par flux de travail | Coût maximum pour un ticket, une extraction, une réponse ou un document terminé | Prend en compte les nouvelles tentatives et le repli |
| Par propriétaire | Budget par application, équipe, client, environnement ou clé | Maintient les dépenses liées à la responsabilité |
La page de tarification de Flatkey est utile à ce stade car elle offre aux équipes un modèle actuel et un chemin de révision des prix, tandis que la surface du produit met l'accent sur la mesure de l'utilisation, les journaux de requêtes, les analyses d'utilisation et les contrôles de coûts. Avant le routage en production, consultez la page /pricing actuelle et confirmez la ligne du modèle, la famille de points de terminaison et l'unité d'utilisation pour le flux de travail réel.
Dimension de la politique 4 : adéquation des capacités
La conception de la politique de routage de modèles doit commencer par les capacités requises. Le prix et la latence n'ont d'importance qu'une fois que la route peut effectuer le travail.
Pour chaque flux de travail, évaluez ces capacités :
| Capacité | Question sur la route | Test d'acceptation |
|---|---|---|
| Utilisation d'outils | La route appelle-t-elle correctement les outils requis ? | Taux de réussite des appels d'outils et validation des arguments |
| Sortie structurée | La route respecte-t-elle le schéma ? | Taux de JSON/schéma valide plus précision au niveau du champ |
| Contexte long | La route préserve-t-elle les instructions et le contexte pertinent ? | Évaluation de documents longs avec les citations ou les champs attendus |
| Vision ou fichiers | La route gère-t-elle la modalité d'entrée réelle ? | Ensemble d'échantillons réels avec couverture de taille et de format |
| Streaming | La route préserve-t-elle la forme de l'événement et le comportement de récupération ? | Test de fumée SSE/streaming et gestion des délais d'attente |
| Comportement de sécurité | La route refuse-t-elle ou escalade-t-elle correctement ? | Invites de l'équipe rouge et vérifications de refus/contournement |
La documentation d'OpenAI sur les sorties structurées recommande une sortie basée sur un schéma lorsque l'application a besoin d'une structure fiable. Pour une politique de routage, cela signifie qu'une route qui ne peut pas respecter le contrat de sortie ne doit pas être utilisée pour l'extraction structurée simplement parce qu'elle est moins chère.
Dimension de la politique 5 : limites de repli
Le repli n'est pas automatiquement une bonne chose. Il peut sauver la disponibilité, mais il peut aussi modifier le comportement, la gestion du contexte, le prix, les limites des données, le support des outils ou la forme de la sortie.
Rédigez les règles de repli comme des transitions explicites :
workflow: invoice_extraction
primary_route: extraction_schema_route
allowed_fallbacks:
- extraction_schema_route_backup
blocked_fallbacks:
- general_chat_route
- creative_writing_route
fallback_triggers:
retry_same_route_once:
- transient_5xx
- rate_limit
stop_and_queue:
- schema_invalid_after_retry
- unsupported_file_type
- compliance_flag
evidence:
log_requested_model: true
log_served_model: true
log_fallback_reason: true
log_usage_units: trueUne politique de routage de modèles mature sépare la nouvelle tentative du repli. La nouvelle tentative signifie « essayer à nouveau le même contrat ». Le repli signifie « changer de route ». Ce changement doit être visible dans les journaux et accepté par le propriétaire du flux de travail.
Dimension de la politique 6 : observabilité et preuves de facturation
Le routage sans preuves relève de la conjecture. Votre politique doit définir les champs que chaque requête de production doit exposer.
| Champ de preuve | Pourquoi il doit figurer dans la politique |
|---|---|
| Nom du flux de travail | Relie les dépenses et les erreurs à un processus métier |
| Application, équipe, clé ou propriétaire client | Permet la refacturation et la responsabilité des incidents |
| Modèle demandé et modèle servi | Indique si un repli ou une substitution de route a eu lieu |
| Famille de points de terminaison | Sépare les formes de routes de chat, de réponses, d'images, de vidéos, Anthropic, Gemini et autres |
| Statut et classe d'erreur | Distingue les erreurs de fournisseur, les erreurs de passerelle, les arrêts de politique et les erreurs de validation |
| Unités d'utilisation | Permet au service financier de rapprocher l'utilisation du texte, du cache, des images, de l'audio et de la vidéo |
| Coût ou impact sur le solde | Convertit les traces d'ingénierie en dépenses vérifiables |
| Raison du repli | Explique pourquoi la politique a changé de route |
Le positionnement public actuel de Flatkey répond à ce besoin de preuves : une passerelle unique pour l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. Pour cet article, la vérification de l'API de tarification en direct le 2 juillet 2026 a renvoyé success: true et a exposé des familles de points de terminaison, notamment openai, openai-response, anthropic, gemini, image-generation, openai-video et video. Considérez cela comme une preuve source datée, et non comme une promesse que chaque route, ligne de modèle ou unité de prix restera inchangée.
Un modèle pratique de politique de routage de modèles
Utilisez ce modèle comme première version de votre norme de routage interne.
policy_name: customer_support_v1
owner:
team: support_platform
approver: product_and_finance
workflow:
description: classer, répondre et escalader les demandes de support
environment: production
data_sensitivity: customer_content
route_selection:
primary_route: balanced_support_route
required_capabilities:
- tool_calling
- structured_outputs
- streaming
blocked_routes:
- experimental_models
- unreviewed_provider_routes
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
cost:
max_cost_per_conversation: approved_budget
owner_key: support_platform_prod
risk:
human_review_required_when:
- refund_exception
- legal_or_policy_question
- confidence_below_threshold
fallback:
retry_same_route_once:
- transient_error
- rate_limit
fallback_to_backup_route:
- primary_route_unavailable
stop_without_fallback:
- safety_refusal
- schema_invalid_after_retry
- unapproved_data_region
evidence:
required_logs:
- workflow
- requested_model
- served_model
- endpoint_family
- route_status
- usage_units
- cost_or_balance
- fallback_reason
acceptance_tests:
min_eval_pass_rate: 0.95
max_schema_error_rate: 0.01
max_unreviewed_fallback_rate: 0Les noms exacts des routes différeront d'une équipe à l'autre. L'important est que la politique rende le choix du modèle, le repli, le coût, la latence et les preuves vérifiables.
Tests d'acceptation avant la mise en production
Ne mettez pas en production une politique de routage de modèles sans effectuer des tests qui simulent les chemins normaux et les échecs.
- Exécutez un jeu de données de référence (golden dataset) sur la route principale et enregistrez la qualité, la validité du schéma, la latence et l'utilisation.
- Déclenchez un chemin de limitation de débit ou d'erreur transitoire et vérifiez le comportement de nouvelle tentative.
- Déclenchez un échec de schéma et confirmez que la politique effectue une nouvelle tentative, s'arrête ou escalade comme prévu.
- Déclenchez un repli bloqué et confirmez que la passerelle ne change pas de route silencieusement.
- Comparez le modèle demandé, le modèle servi, la famille de points de terminaison et les unités d'utilisation dans les journaux.
- Vérifiez si le service financier peut rapprocher les mêmes requêtes d'échantillon avec le coût, le solde prépayé, la facture ou les lignes d'exportation.
- Exécutez un test de restauration (rollback) qui épingle la route précédente ou désactive le repli.
Pour un contexte plus approfondi sur l'architecture de la passerelle, associez cette liste de contrôle aux guides Flatkey sur les passerelles d'API d'IA, l'architecture des passerelles d'API LLM et l'équilibrage de charge et le basculement des API d'IA.
Le rôle de Flatkey
Flatkey ne doit pas remplacer la politique. Il doit rendre la politique plus facile à appliquer et à vérifier.
Utilisez Flatkey lorsque l'équipe souhaite une clé unique pour les modèles d'IA connectés, un chemin de révision du catalogue de modèles et de la tarification actuelle, une visibilité sur l'utilisation, des preuves au niveau de la requête, des quotas et une conversation de facturation plus simple que des comptes de fournisseurs dispersés. La politique de routage de modèles nécessite toujours des propriétaires, des tests d'acceptation, des contraintes de route, des règles de repli et des plans de restauration.
Une exécution de preuve pratique avec Flatkey ressemble à ceci :
- Choisissez un flux de travail de type production et une clé de propriétaire.
- Confirmez la ligne de modèle et la famille de points de terminaison actuelles sur la page de tarification de Flatkey.
- Envoyez des requêtes normales, en streaming, structurées et d'échec contrôlé si le flux de travail les utilise.
- Examinez les journaux de requêtes pour le modèle demandé, le modèle servi, le statut, les unités d'utilisation et les preuves de repli.
- Confirmez le comportement des quotas et l'examen des coûts ou du solde avec le propriétaire du flux de travail.
- Ne déplacez que la route testée en production, puis développez la politique ligne par ligne.
Cela permet de fonder la politique de routage de modèles sur des preuves réelles plutôt que sur un diagramme d'architecture.
FAQ
Qu'est-ce qu'une politique de routage de modèles ?
Une politique de routage de modèles est une règle écrite qui associe chaque flux de travail d'IA à une route de modèle approuvée, des exigences de capacité, un plafond de coût, un objectif de latence, un comportement de repli et une liste de contrôle des preuves.
Pourquoi ne pas router chaque requête vers le modèle le plus puissant ?
La route la plus performante est souvent plus lente et plus coûteuse que ce dont un flux de travail a besoin. Une politique de routage de modèles permet aux flux de travail à faible risque d'utiliser des routes efficaces tout en préservant des routes plus performantes pour les raisonnements complexes, les décisions sensibles ou les tâches à haute valeur ajoutée.
Quand le repli (fallback) doit-il être bloqué ?
Bloquez le repli lorsqu'un changement de route pourrait modifier le traitement des données, la posture de conformité, le schéma de sortie, le comportement des outils, la qualité perçue par l'utilisateur ou la responsabilité de la facturation. Dans ces cas, mettez en file d'attente, réessayez ou escaladez au lieu de changer silencieusement de route de modèle.
À quelle fréquence les équipes doivent-elles mettre à jour une politique de routage de modèles ?
Révisez-la chaque fois que les catalogues de modèles, les unités de tarification, le comportement des points de terminaison, les exigences en matière de risque ou les résultats d'évaluation changent. Au minimum, examinez les politiques de production actives tous les trimestres et après toute migration de modèle majeure.
Quelle est la première métrique à surveiller ?
Surveillez le coût par résultat accepté, et pas seulement le coût par jeton. Associez-le ensuite à la latence p95, au taux de repli, au taux de schémas valides et aux preuves de facturation au niveau de la requête.
Comment Flatkey aide-t-il à la conception d'une politique de routage de modèles ?
Flatkey peut fournir une surface de passerelle unique pour l'accès aux modèles, l'examen des prix, le routage, l'analyse de l'utilisation, les journaux de requêtes, les quotas et l'examen de la facturation. Cela donne aux équipes un endroit pratique pour valider si la politique de routage de modèles se comporte comme prévu.
Commencez par la tarification de Flatkey, choisissez un flux de travail, puis obtenez une clé et exécutez une petite preuve de concept qui vérifie le comportement de la route, les journaux, les quotas, le coût, le repli et la restauration avant le déploiement en production.