Jedes KI-Produkt wächst irgendwann über ein einziges Standardmodell hinaus. Ein Support-Bot, ein Code-Reviewer, ein Rechnungsextraktor, ein Helfer für Bild-Prompts und ein interner Recherche-Agent benötigen nicht dasselbe Latenzziel, Kontextbudget, dieselbe logische Tiefe, dasselbe Tool-Verhalten, dieselbe Fallback-Regel oder denselben Genehmigungspfad. Eine Modell-Routing-Richtlinie verwandelt diese Kompromisse in einen Betriebsvertrag anstelle eines Haufens von Ad-hoc-model=-Strings.
Das Ziel ist nicht, ein „bestes“ Modell auszuwählen. Das Ziel ist es, die Modellwahl überprüfbar zu machen. Eine gute Modell-Routing-Richtlinie gibt Ingenieuren vor, welche Modellklasse sie verwenden sollen, wann sie mehr ausgeben, wann sie auf Latenz optimieren, wann sie Fallbacks blockieren sollen und welche Nachweise vorliegen müssen, bevor ein Workflow in die Produktion geht.
Flatkey ist in dieser Diskussion wichtig, da das Routing einfacher zu steuern ist, wenn Modellzugriff, Schlüssel, Anforderungsprotokolle, Nutzungsanalysen, Preisüberprüfungen und Betriebskontrollen an einem Ort zusammengefasst sind. Verwenden Sie die nachstehende Richtlinie als Designebene und validieren Sie dann den aktuellen Flatkey-Modellkatalog und die Preisseite vor der Einführung in die Produktion.
Design einer Modell-Routing-Richtlinie in einer Tabelle
Beginnen Sie mit Workflow-Klassen, nicht mit Anbieternamen. Die folgende Tabelle ist der erste praktische Entwurf für eine Modell-Routing-Richtlinie.
| Workflow-Klasse | Primäre Route | Kostenregel | Latenzregel | Risikoregel | Fallback-Regel | Erforderlicher Nachweis |
|---|---|---|---|---|---|---|
| Schnelle Klassifizierung | Kleines Textmodell oder Modell mit geringer logischer Tiefe | Niedrigste Kosten, die die Evals bestehen | Enges p95-Ziel | Geringes Geschäftsrisiko | Wiederholung oder Downgrade sicher | Genauigkeitsstichprobe, p95-Latenz, Kosten pro 1.000 Aufrufe |
| Kunden-Chat | Ausgewogenes Modell mit Tool-Unterstützung | Obergrenze pro Konversation oder Konto | Niedrige p95 und stabiles Streaming | Mittleres Risiko | Fallback nur auf Modelle mit getestetem Ton und Tool-Verhalten | Konversations-Evals, Verweigerungsprüfungen, Erfolg von Tool-Aufrufen, Transkript-QS |
| Code und technisches Schlussfolgern | Modell mit starker logischer Tiefe | Mehr ausgeben nur für schwierige Aufgaben | Großzügigeres Latenzbudget | Mittleres bis hohes Risiko | Fallback auf eine überprüfte Peer-Route, nicht auf ein schwaches Modell | Aufgaben-Evals, Diff-Korrektheit, Tool-Trace, Rollback-Pfad |
| Strukturierte Extraktion | Modell mit Schema-Unterstützung | Optimierung pro gültigem Datensatz | Batch oder nahezu Echtzeit | Mittleres Risiko | Wiederholung mit gleicher oder strengerer Route vor Fallback | Rate schema-valider Daten, Feldgenauigkeit, Fehlertaxonomie |
| Beschaffungs- oder Finanzprüfung | Festgelegte, überprüfte Modellroute | Kosten sind der Überprüfbarkeit untergeordnet | Asynchron akzeptabel | Hohes Risiko | Kein automatischer Fallback ohne Genehmigung | Quell-Trace, Modellversion, Anforderungsprotokoll, Freigabe durch Prüfer |
| Hintergrund-Zusammenfassung | Kostengünstigere oder Batch-freundliche Route | Minimierung der Kosten pro akzeptierter Zusammenfassung | Asynchron | Geringes bis mittleres Risiko | Fallback, nachdem das Wiederholungsbudget aufgebraucht ist | Stichprobenqualität, Wiederholungsrate, Metriken für zwischengespeicherte Token |
Diese Tabelle ist nicht die endgültige Richtlinie. Sie ist die Entscheidungsgrundlage. Jede Zeile benötigt messbare Kriterien, bevor sie zum Produktions-Routing wird.
Was eine Modell-Routing-Richtlinie entscheiden muss
Eine Modell-Routing-Richtlinie ist eine schriftliche Regel, die einen Workflow den Modellfähigkeiten, Kostengrenzen, Latenz-SLOs, dem Fallback-Verhalten und den Nachweisanforderungen zuordnet. Sie sollte für jeden Produktions-Workflow sechs Fragen beantworten:
- Was versucht der Workflow zu optimieren: Geschwindigkeit, Qualität, Kosten, Zuverlässigkeit, Sicherheit, Modalität, Kontextlänge oder Überprüfbarkeit?
- Welche Fähigkeiten sind erforderlich: Tool-Aufrufe, strukturierte Ausgabe, langer Kontext, Bildeingabe, Streaming, geringe logische Tiefe, hohe logische Tiefe oder anbieterspezifische Endpunktunterstützung?
- Was ist das Fehlerbudget: Wiederholen, Fallback, Herabstufen, in die Warteschlange stellen, einen Menschen fragen oder anhalten?
- Was kann sich automatisch ändern: Anbieter, Modellgröße, logischer Aufwand, Timeout, Routengruppe oder nichts?
- Was muss protokolliert werden: angefordertes Modell, bereitgestelltes Modell, Route, Status, Nutzungseinheiten, Kosten, Fallback-Versuch und Eigentümer?
- Welcher Nachweis ist vor dem Start erforderlich: Eval-Score, Latenzstichprobe, Quotentest, Abrechnungs-Trace, Sicherheitsüberprüfung oder Beschaffungsgenehmigung?
Die aktuelle Anleitung von OpenAI zu GPT-5.5 ist hier nützlich, da sie die API-Konfiguration als Teil der Modellleistung und nicht als nachträgliche Überlegung behandelt. Die Dokumentation nennt die Zustandsverwaltung der Responses API, den logischen Aufwand, die Ausführlichkeit, strukturierte Ausgaben, das Prompt-Caching, das Tool-Design, gehostete Tools und die Zustandsverwaltung als Faktoren, die Intelligenz, Zuverlässigkeit, Latenz und Kosten beeinflussen. Das ist genau die Art von Dimension, die eine Modell-Routing-Richtlinie beibehalten sollte.
Richtliniendimension 1: Workflow-Risiko
Das Risiko ist die erste Routing-Aufteilung, da es steuert, wie viel Automatisierung zulässig ist.
Workflows mit geringem Risiko können in der Regel Wiederholungen, kostengünstigere Routen und einen breiten Fallback tolerieren. Beispiele hierfür sind internes Tagging, einfache Zusammenfassungen, Entwurfsvorschläge und unkritische Klassifizierungen. Dies sind gute Kandidaten für aggressive Kostenkontrollen, da eine gelegentliche Wiederholung oder eine Überprüfungsstichprobe akzeptabel ist.
Workflows mit mittlerem Risiko erfordern strengere Akzeptanztests. Kundensupport, Workflow-Automatisierung, Code-Vorschläge und Vertriebsunterstützungstools erfordern möglicherweise nicht jedes Mal eine menschliche Überprüfung, aber sie erfordern Tonprüfungen, Tool-Aufruf-Prüfungen und Routennachweise, wenn Fehler auftreten.
Workflows mit hohem Risiko sollten enger festgelegt werden. Beschaffungsprüfungen, rechtliche Zusammenfassungen, Finanzgenehmigungen, Sicherheitsentscheidungen und regulierte Workflows sollten nicht stillschweigend auf ein anderes Modell oder einen anderen Anbieter zurückgreifen, nur weil die primäre Route langsam ist. Die Modell-Routing-Richtlinie sollte eine explizite Genehmigung erfordern, bevor ein Fallback die Risikoposition ändert.
Die einfache Regel: Wenn ein Mensch nach einem schlechten Ergebnis fragen würde: „Welches Modell hat das eigentlich beantwortet?“, benötigt die Route eine stärkere Protokollierung und ein schwächeres automatisches Fallback.
Richtliniendimension 2: Latenz und Benutzererfahrung
Latenz gehört in die Richtlinie, da dasselbe Modell für einen asynchronen Workflow akzeptabel und für ein interaktives Produkt inakzeptabel sein kann.
Legen Sie für interaktiven Chat Erwartungen für p50, p95, Timeout und Streaming fest. Wenn die Zeit bis zum ersten Token (time-to-first-token) wichtig ist, messen Sie diese separat von der gesamten Abschlusszeit. Definieren Sie stattdessen für Hintergrundaufgaben eine maximale Warteschlangenzeit und eine Frist für den Abschluss.
Legen Sie keine vage Regel wie „das schnelle Modell verwenden“ fest. Schreiben Sie die Modell-Routing-Richtlinie als testbares Ziel:
workflow: support_chat_triage
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
timeout_ms: 10000
fallback:
on_timeout: use_reviewed_balanced_route
on_schema_error: retry_same_route_once
on_safety_or_policy_error: stop_and_escalateDie Dokumentation von OpenAI zum Prompt-Caching erinnert daran, dass Latenz nicht nur von der Modellauswahl abhängt. Stabile Prompt-Präfixe, konsistente Cache-Schlüssel und die Überwachung von Cache-Treffern können die Latenz und die Kosten für Eingabe-Token bei wiederholten Arbeitslasten erheblich verändern. Wenn Caching Teil des Plans ist, machen Sie es zu einer Richtlinienanforderung und protokollieren Sie Metriken für zwischengespeicherte Token.
Richtliniendimension 3: Kostenobergrenzen
Kostenkontrollen sollten pro Workflow-Ergebnis ausgedrückt werden, nicht nur pro Token. Eine günstige Route, die oft fehlschlägt, kann mehr kosten als eine stärkere Route, die beim ersten Versuch erfolgreich ist.
Verwenden Sie drei Kostenlimits:
| Limit | Beispiel | Warum es wichtig ist |
|---|---|---|
| Pro Anfrage | Maximale Kosten für eine Anfrage, einen Bild-, einen Video-Job oder einen Durchgang | Verhindert, dass ein einzelner Aufruf die Finanzabteilung überrascht |
| Pro Workflow | Maximale Kosten für ein abgeschlossenes Ticket, eine Extraktion, eine Antwort oder ein Dokument | Berücksichtigt Wiederholungsversuche und Fallback |
| Pro Eigentümer | Budget nach App, Team, Kunde, Umgebung oder Schlüssel | Hält die Ausgaben an die Verantwortlichkeit gebunden |
Die Preisseite von Flatkey ist in dieser Phase nützlich, da sie Teams einen aktuellen Pfad zur Überprüfung von Modellen und Preisen bietet, während die Produktoberfläche die Nutzungsmessung, Anforderungsprotokolle, Nutzungsanalysen und Kostenkontrollen hervorhebt. Überprüfen Sie vor dem produktiven Routing die aktuelle /pricing-Seite und bestätigen Sie die Modellzeile, die Endpunktfamilie und die Nutzungseinheit für den tatsächlichen Workflow.
Richtliniendimension 4: Passende Fähigkeiten
Das Design von Modell-Routing-Richtlinien sollte bei den erforderlichen Fähigkeiten beginnen. Preis und Latenz sind erst dann von Bedeutung, wenn die Route die Aufgabe erfüllen kann.
Bewerten Sie für jeden Workflow diese Fähigkeiten:
| Fähigkeit | Frage zur Route | Akzeptanztest |
|---|---|---|
| Tool-Nutzung | Ruft die Route die erforderlichen Tools korrekt auf? | Erfolgsrate der Tool-Aufrufe und Argumentvalidierung |
| Strukturierte Ausgabe | Erfüllt die Route das Schema? | Rate gültiger JSON/Schemata plus Genauigkeit auf Feldebene |
| Langer Kontext | Behält die Route Anweisungen und relevanten Kontext bei? | Evaluierung langer Dokumente mit erwarteten Zitaten oder Feldern |
| Vision oder Dateien | Verarbeitet die Route die tatsächliche Eingabemodalität? | Reales Musterset mit Abdeckung von Größe und Format |
| Streaming | Behält die Route die Ereignisform und das Wiederherstellungsverhalten bei? | SSE/Streaming-Smoke-Test und Timeout-Behandlung |
| Sicherheitsverhalten | Verweigert oder eskaliert die Route korrekt? | Red-Team-Prompts und Überprüfungen von Verweigerung/Überschreibung |
Die Dokumentation von OpenAI zu strukturierten Ausgaben empfiehlt eine schemagestützte Ausgabe, wenn die Anwendung eine zuverlässige Struktur benötigt. Für eine Routing-Richtlinie bedeutet dies, dass eine Route, die den Ausgabevertrag nicht erfüllen kann, nicht für die strukturierte Extraktion verwendet werden sollte, nur weil sie billiger ist.
Richtliniendimension 5: Fallback-Grenzen
Fallback ist nicht automatisch gut. Es kann die Betriebszeit retten, aber es kann auch das Verhalten, die Kontextbehandlung, den Preis, die Datengrenze, die Tool-Unterstützung oder die Ausgabeform ändern.
Schreiben Sie Fallback-Regeln als explizite Übergänge:
workflow: invoice_extraction
primary_route: extraction_schema_route
allowed_fallbacks:
- extraction_schema_route_backup
blocked_fallbacks:
- general_chat_route
- creative_writing_route
fallback_triggers:
retry_same_route_once:
- transient_5xx
- rate_limit
stop_and_queue:
- schema_invalid_after_retry
- unsupported_file_type
- compliance_flag
evidence:
log_requested_model: true
log_served_model: true
log_fallback_reason: true
log_usage_units: trueEine ausgereifte Modell-Routing-Richtlinie trennt zwischen Wiederholung (Retry) und Fallback. Wiederholung bedeutet „denselben Vertrag erneut versuchen“. Fallback bedeutet „die Route ändern“. Diese Änderung sollte in den Protokollen sichtbar und vom Workflow-Eigentümer akzeptiert sein.
Richtliniendimension 6: Beobachtbarkeit und Abrechnungsnachweise
Routing ohne Nachweise ist Rätselraten. Ihre Richtlinie sollte die Felder definieren, die jede Produktionsanfrage offenlegen muss.
| Nachweisfeld | Warum es in die Richtlinie gehört |
|---|---|
| Workflow-Name | Verbindet Ausgaben und Fehler mit einem Geschäftsprozess |
| App-, Team-, Schlüssel- oder Kundeneigentümer | Ermöglicht Rückbuchungen und die Zuständigkeit für Vorfälle |
| Angefordertes Modell und bereitgestelltes Modell | Zeigt an, ob ein Fallback oder eine Routen-Substitution stattgefunden hat |
| Endpunktfamilie | Trennt Chat, Antworten, Bild, Video, Anthropic, Gemini und andere Routenformen |
| Status- und Fehlerklasse | Unterscheidet zwischen Anbieterfehlern, Gateway-Fehlern, Richtlinien-Stopps und Validierungsfehlern |
| Nutzungseinheiten | Ermöglicht der Finanzabteilung den Abgleich der Nutzung von Text, Cache, Bild, Audio und Video |
| Kosten- oder Guthabenauswirkung | Wandelt technische Traces in überprüfbare Ausgaben um |
| Fallback-Grund | Erklärt, warum die Richtlinie die Route geändert hat |
Die aktuelle öffentliche Positionierung von Flatkey passt zu diesem Nachweisbedarf: ein Gateway für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und Betriebskontrollen. Für diesen Artikel lieferte die Live-Preis-API-Prüfung am 2. Juli 2026 success: true zurück und legte Endpunktfamilien wie openai, openai-response, anthropic, gemini, image-generation, openai-video und video offen. Betrachten Sie dies als veralteten Quellennachweis und nicht als Versprechen, dass jede Route, Modellzeile oder Preiseinheit unverändert bleibt.
Eine praktische Vorlage für eine Modell-Routing-Richtlinie
Verwenden Sie diese Vorlage als erste Version Ihres internen Routing-Standards.
policy_name: customer_support_v1
owner:
team: support_platform
approver: product_and_finance
workflow:
description: Klassifizieren, Beantworten und Eskalieren von Supportanfragen
environment: production
data_sensitivity: customer_content
route_selection:
primary_route: balanced_support_route
required_capabilities:
- tool_calling
- structured_outputs
- streaming
blocked_routes:
- experimental_models
- unreviewed_provider_routes
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
cost:
max_cost_per_conversation: approved_budget
owner_key: support_platform_prod
risk:
human_review_required_when:
- refund_exception
- legal_or_policy_question
- confidence_below_threshold
fallback:
retry_same_route_once:
- transient_error
- rate_limit
fallback_to_backup_route:
- primary_route_unavailable
stop_without_fallback:
- safety_refusal
- schema_invalid_after_retry
- unapproved_data_region
evidence:
required_logs:
- workflow
- requested_model
- served_model
- endpoint_family
- route_status
- usage_units
- cost_or_balance
- fallback_reason
acceptance_tests:
min_eval_pass_rate: 0.95
max_schema_error_rate: 0.01
max_unreviewed_fallback_rate: 0Die genauen Routennamen werden sich je nach Team unterscheiden. Wichtig ist, dass die Richtlinie die Modellwahl, das Fallback, die Kosten, die Latenz und den Nachweis überprüfbar macht.
Abnahmetests vor der Produktion
Veröffentlichen Sie keine Modell-Routing-Richtlinie, ohne Tests durchzuführen, die normale und fehlgeschlagene Pfade simulieren.
- Führen Sie einen Golden Dataset durch die primäre Route aus und zeichnen Sie Qualität, Schemagültigkeit, Latenz und Nutzung auf.
- Lösen Sie einen Rate-Limit- oder einen transienten Fehlerpfad aus und überprüfen Sie das Wiederholungsverhalten.
- Lösen Sie einen Schemafehler aus und bestätigen Sie, dass die Richtlinie wie beschrieben Wiederholungsversuche unternimmt, stoppt oder eskaliert.
- Lösen Sie ein blockiertes Fallback aus und bestätigen Sie, dass das Gateway die Route nicht stillschweigend ändert.
- Vergleichen Sie das angeforderte Modell, das bereitgestellte Modell, die Endpunktfamilie und die Nutzungseinheiten in den Protokollen.
- Prüfen Sie, ob die Finanzabteilung dieselben Beispielanfragen mit Kosten, Prepaid-Guthaben, Rechnungen oder Exportzeilen abgleichen kann.
- Führen Sie einen Rollback-Test durch, der die vorherige Route festschreibt oder das Fallback deaktiviert.
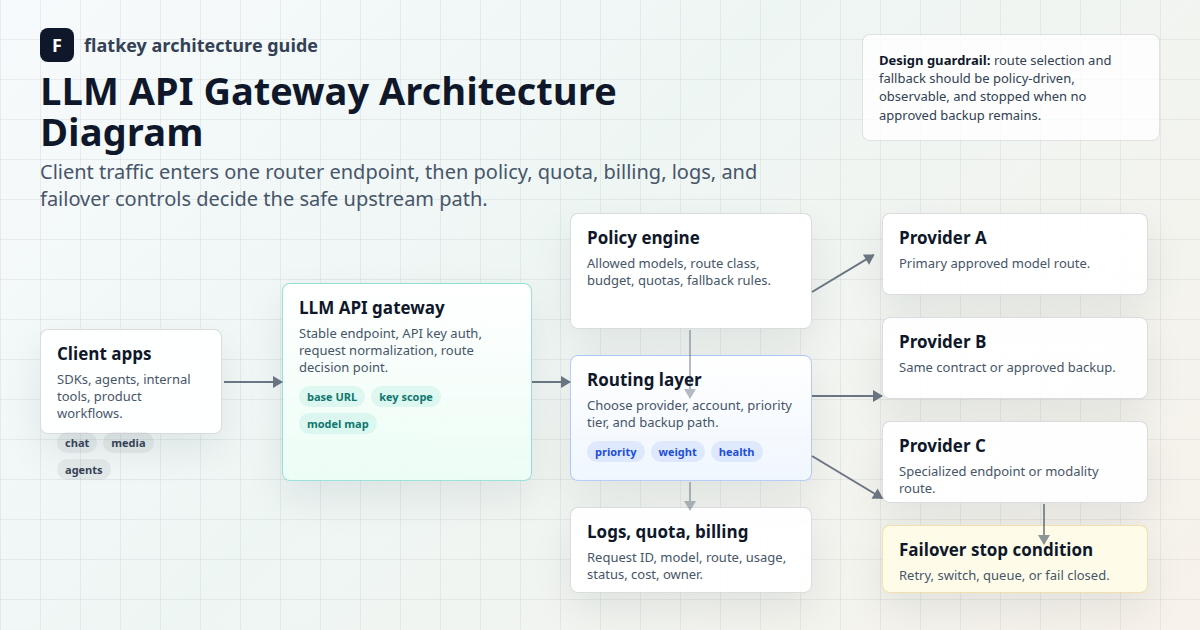
Für einen tieferen Einblick in die Gateway-Architektur kombinieren Sie diese Checkliste mit den Flatkey-Leitfäden zu KI-API-Gateways, LLM-API-Gateway-Architektur und KI-API-Lastverteilung und Failover.
Wo Flatkey ins Spiel kommt
Flatkey sollte die Richtlinie nicht ersetzen. Es sollte die Durchsetzung und Überprüfung der Richtlinie erleichtern.
Verwenden Sie Flatkey, wenn das Team einen einzigen Schlüssel für verbundene KI-Modelle, einen aktuellen Überprüfungspfad für Preise und Modellkataloge, Einblick in die Nutzung, Nachweise auf Anfrageebene, Kontingente und eine einfachere Abrechnung als bei verstreuten Anbieterkonten wünscht. Die Modell-Routing-Richtlinie benötigt weiterhin Eigentümer, Abnahmetests, Routenbeschränkungen, Fallback-Regeln und Rollback-Pläne.
Ein praktischer Flatkey-Testlauf sieht wie folgt aus:
- Wählen Sie einen produktionsähnlichen Workflow und einen Eigentümerschlüssel aus.
- Bestätigen Sie die aktuelle Modellzeile und Endpunktfamilie auf der Flatkey-Preisseite.
- Senden Sie normale, Streaming-, strukturierte und kontrollierte Fehleranfragen, falls der Workflow diese verwendet.
- Überprüfen Sie die Anforderungsprotokolle auf das angeforderte Modell, das bereitgestellte Modell, den Status, die Nutzungseinheiten und den Fallback-Nachweis.
- Bestätigen Sie das Kontingentverhalten und die Kosten- oder Guthabenprüfung mit dem Workflow-Eigentümer.
- Verschieben Sie nur die getestete Route in die Produktion und erweitern Sie dann die Richtlinie Zeile für Zeile.
Dadurch bleibt die Modell-Routing-Richtlinie auf realen Nachweisen und nicht auf einem Architekturdiagramm verankert.
FAQ
Was ist eine Modell-Routing-Richtlinie?
Eine Modell-Routing-Richtlinie ist eine schriftliche Regel, die jeden KI-Workflow einer genehmigten Modellroute, Fähigkeitsanforderungen, einer Kostengrenze, einem Latenzziel, einem Fallback-Verhalten und einer Nachweis-Checkliste zuordnet.
Warum nicht jede Anfrage an das leistungsstärkste Modell weiterleiten?
Die stärkste Route ist oft langsamer und teurer, als es für einen Workflow erforderlich ist. Eine Modell-Routing-Richtlinie ermöglicht es Workflows mit geringem Risiko, effiziente Routen zu nutzen, während stärkere Routen für komplexe Schlussfolgerungen, sensible Entscheidungen oder hochwertige Arbeit beibehalten werden.
Wann sollte ein Fallback blockiert werden?
Blockieren Sie das Fallback, wenn eine Routenänderung die Datenverarbeitung, den Compliance-Status, das Ausgabeschema, das Tool-Verhalten, die für den Benutzer sichtbare Qualität oder die Zuständigkeit für die Abrechnung ändern könnte. In diesen Fällen stellen Sie die Anfrage in eine Warteschlange, versuchen Sie es erneut oder eskalieren Sie, anstatt die Modellroute stillschweigend zu ändern.
Wie oft sollten Teams eine Modell-Routing-Richtlinie aktualisieren?
Überprüfen Sie sie immer dann, wenn sich Modellkataloge, Preiseinheiten, Endpunktverhalten, Risikoanforderungen oder Evaluierungsergebnisse ändern. Überprüfen Sie aktive Produktionsrichtlinien mindestens vierteljährlich und nach jeder größeren Modellmigration.
Was ist die erste Metrik, die man beobachten sollte?
Beobachten Sie die Kosten pro akzeptiertem Ergebnis, nicht nur die Kosten pro Token. Kombinieren Sie diese dann mit der p95-Latenz, der Fallback-Rate, der Rate schema-valider Antworten und den Abrechnungsnachweisen auf Anfrageebene.
Wie hilft Flatkey beim Design von Modell-Routing-Richtlinien?
Flatkey kann eine einzige Gateway-Oberfläche für Modellzugriff, Preisüberprüfung, Routing, Nutzungsanalysen, Anforderungsprotokolle, Kontingente und Abrechnungsprüfung bereitstellen. Das gibt Teams einen praktischen Ort, um zu überprüfen, ob sich die Modell-Routing-Richtlinie wie geschrieben verhält.
Beginnen Sie mit den Flatkey-Preisen, wählen Sie einen Workflow, holen Sie sich dann einen Schlüssel und führen Sie einen kleinen Proof-of-Concept durch, der das Routenverhalten, Protokolle, Kontingente, Kosten, Fallback und Rollback überprüft, bevor Sie in die Produktion gehen.