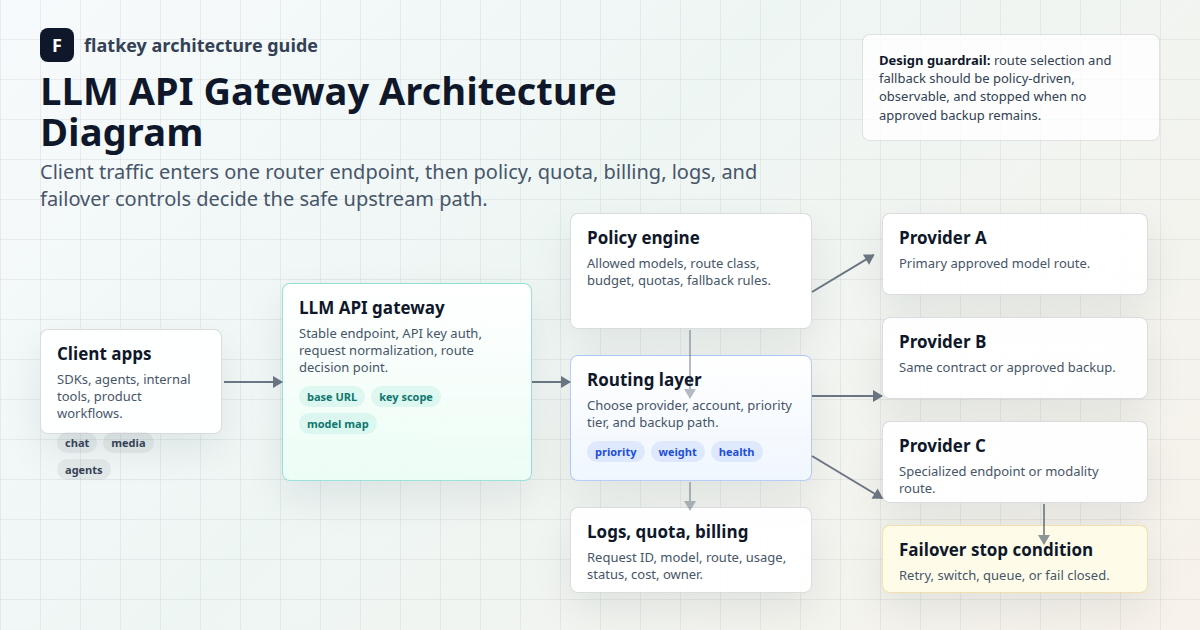
Todo produto de IA eventualmente supera um único modelo padrão. Um bot de suporte, revisor de código, extrator de faturas, assistente de prompt de imagem e agente de pesquisa interno não precisam do mesmo alvo de latência, orçamento de contexto, profundidade de raciocínio, comportamento de ferramenta, regra de fallback ou trilha de aprovação. Uma política de roteamento de modelos transforma essas compensações em um contrato operacional em vez de um amontoado de strings model= ad hoc.
O objetivo não é escolher um "melhor" modelo. O objetivo é tornar a escolha do modelo revisável. Uma boa política de roteamento de modelos informa aos engenheiros qual classe de modelo usar, quando gastar mais, quando otimizar para latência, quando bloquear o fallback e quais evidências devem existir antes que um fluxo de trabalho seja movido para a produção.
A Flatkey é importante nesta discussão porque o roteamento é mais fácil de governar quando o acesso ao modelo, chaves, logs de solicitação, análise de uso, revisão de preços e controles operacionais estão em um só lugar. Use a política abaixo como a camada de design e, em seguida, valide o catálogo de modelos e a página de preços atuais da Flatkey antes do lançamento em produção.
Design da política de roteamento de modelos em uma tabela
Comece com as classes de fluxo de trabalho, não com os nomes dos provedores. A tabela abaixo é a primeira versão prática para uma política de roteamento de modelos.
| Classe do fluxo de trabalho | Rota primária | Regra de custo | Regra de latência | Regra de risco | Regra de fallback | Evidência necessária |
|---|---|---|---|---|---|---|
| Classificação rápida | Modelo de texto pequeno ou de baixo raciocínio | Custo mais baixo que passa nas avaliações | Alvo p95 restrito | Baixo risco de negócio | Seguro para tentar novamente ou fazer downgrade | Amostra de precisão, latência p95, custo por 1.000 chamadas |
| Chat com cliente | Modelo balanceado com suporte a ferramentas | Limite por conversa ou conta | p95 baixo e streaming estável | Risco médio | Fallback apenas para modelos com tom e comportamento de ferramenta testados | Avaliações de conversas, verificações de recusa, sucesso na chamada de ferramenta, QA de transcrição |
| Código e raciocínio técnico | Modelo de raciocínio forte | Gastar mais apenas em tarefas difíceis | Orçamento de latência mais flexível | Risco médio a alto | Fallback para rota de par revisada, não para um modelo fraco | Avaliações de tarefas, correção de diff, rastreamento de ferramenta, caminho de rollback |
| Extração estruturada | Modelo com suporte a esquema | Otimizar por registro válido | Em lote ou quase em tempo real | Risco médio | Tentar novamente com a mesma rota ou uma mais restrita antes do fallback | Taxa de esquema válido, precisão de campo, taxonomia de erros |
| Revisão de compras ou finanças | Rota de modelo revisada e fixada | Custo secundário à auditabilidade | Assíncrono aceitável | Alto risco | Sem fallback automático sem aprovação | Rastreamento de origem, versão do modelo, log de solicitação, aprovação do revisor |
| Resumo em segundo plano | Rota de menor custo ou amigável para lotes | Minimizar custo por resumo aceito | Assíncrono | Risco baixo a médio | Fallback após o esgotamento do orçamento de tentativas | Qualidade da amostra, taxa de tentativas, métricas de token em cache |
Esta tabela não é a política final. É a superfície de decisão. Cada linha precisa de portões mensuráveis antes de se tornar um roteamento de produção.
O que uma política de roteamento de modelos deve decidir
Uma política de roteamento de modelos é uma regra escrita que mapeia um fluxo de trabalho para capacidades do modelo, tetos de custo, SLOs de latência, comportamento de fallback e requisitos de evidência. Ela deve responder a seis perguntas para cada fluxo de trabalho de produção:
- O que o fluxo de trabalho está tentando otimizar: velocidade, qualidade, custo, confiabilidade, segurança, modalidade, comprimento do contexto ou auditabilidade?
- Quais capacidades são necessárias: chamada de ferramenta, saída estruturada, contexto longo, entrada de imagem, streaming, baixo raciocínio, alto raciocínio ou suporte a endpoint específico do provedor?
- Qual é o orçamento de falha: tentar novamente, fallback, degradar, enfileirar, perguntar a um humano ou parar?
- O que pode mudar automaticamente: provedor, tamanho do modelo, esforço de raciocínio, tempo limite, grupo de rotas ou nada?
- O que deve ser registrado: modelo solicitado, modelo servido, rota, status, unidades de uso, custo, tentativa de fallback e proprietário?
- Que prova é necessária antes do lançamento: pontuação de avaliação, amostra de latência, teste de cota, rastreamento de faturamento, revisão de segurança ou aprovação de compras?
A orientação atual do GPT-5.5 da OpenAI é útil aqui porque trata a configuração da API como parte do desempenho do modelo, não como uma reflexão tardia. A documentação destaca o manuseio de estado da API de Respostas, esforço de raciocínio, verbosidade, saídas estruturadas, cache de prompt, design de ferramentas, ferramentas hospedadas e gerenciamento de estado como fatores que afetam a inteligência, confiabilidade, latência e custo. Esse é exatamente o tipo de dimensão que uma política de roteamento de modelos deve preservar.
Dimensão da política 1: risco do fluxo de trabalho
O risco é a primeira divisão de roteamento porque controla quanta automação é permitida.
Fluxos de trabalho de baixo risco geralmente podem tolerar novas tentativas, rotas mais baratas e fallback amplo. Exemplos incluem marcação interna, resumos leves, sugestões de rascunho e classificação não crítica. Estes são bons candidatos para controles de custo agressivos porque uma nova tentativa ocasional ou uma amostra de revisão é aceitável.
Fluxos de trabalho de risco médio precisam de testes de aceitação mais rigorosos. Suporte ao cliente, automação de fluxo de trabalho, sugestões de código e ferramentas de assistência de vendas podem não exigir revisão humana todas as vezes, mas exigem verificações de tom, verificações de chamada de ferramenta e evidências de rota quando ocorrem erros.
Fluxos de trabalho de alto risco devem ser fixados com mais rigor. Revisões de compras, resumos jurídicos, aprovações financeiras, decisões de segurança e fluxos de trabalho regulamentados não devem recorrer silenciosamente a um modelo ou provedor diferente apenas porque a rota primária está lenta. A política de roteamento de modelos deve exigir aprovação explícita antes que o fallback altere a postura de risco.
A regra simples: se um humano perguntasse "qual modelo realmente respondeu a isso?" após um resultado ruim, a rota precisa de um registro mais robusto e um fallback automático mais fraco.
Dimensão da política 2: latência e experiência do usuário
A latência pertence à política porque o mesmo modelo pode ser aceitável para um fluxo de trabalho assíncrono e inaceitável para um produto interativo.
Para chat interativo, defina as expectativas de p50, p95, tempo limite e streaming. Se o tempo para o primeiro token for importante, meça-o separadamente do tempo total de conclusão. Para tarefas em segundo plano, defina o tempo máximo de fila e o prazo de conclusão.
Não defina uma regra vaga como "use o modelo rápido." Escreva a política de roteamento de modelos como um alvo testável:
workflow: support_chat_triage
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
timeout_ms: 10000
fallback:
on_timeout: use_reviewed_balanced_route
on_schema_error: retry_same_route_once
on_safety_or_policy_error: stop_and_escalateA documentação de cache de prompts da OpenAI é outro lembrete de que a latência não se resume apenas à seleção do modelo. Prefixos de prompt estáveis, chaves de cache consistentes e monitoramento de acertos de cache podem alterar materialmente a latência e o custo de tokens de entrada para cargas de trabalho repetidas. Se o cache fizer parte do plano, torne-o um requisito da política e registre as métricas de tokens em cache.
Dimensão da política 3: tetos de custo
Os controles de custo devem ser expressos por resultado do fluxo de trabalho, não apenas por token. Uma rota barata que falha com frequência pode custar mais do que uma rota mais robusta que tem sucesso na primeira tentativa.
Use três limites de custo:
| Limite | Exemplo | Por que é importante |
|---|---|---|
| Por solicitação | Custo máximo para uma solicitação, trabalho de imagem, vídeo ou turno | Evita que uma única chamada surpreenda o financeiro |
| Por fluxo de trabalho | Custo máximo para um ticket concluído, extração, resposta ou documento | Leva em conta novas tentativas e fallback |
| Por proprietário | Orçamento por aplicativo, equipe, cliente, ambiente ou chave | Mantém os gastos vinculados à responsabilidade |
A página de preços da Flatkey é útil nesta fase porque oferece às equipes um caminho de revisão de modelos e preços atuais, enquanto a superfície do produto enfatiza a medição de uso, logs de solicitações, análise de uso e controles de custo. Antes do roteamento de produção, verifique a página /pricing atual e confirme a linha do modelo, a família de endpoints e a unidade de uso para o fluxo de trabalho real.
Dimensão da política 4: adequação da capacidade
O design da política de roteamento de modelos deve começar pelas capacidades necessárias. Preço e latência só importam depois que a rota puder realizar o trabalho.
Para cada fluxo de trabalho, pontue estas capacidades:
| Capacidade | Pergunta da rota | Teste de aceitação |
|---|---|---|
| Uso de ferramentas | A rota chama as ferramentas necessárias corretamente? | Taxa de sucesso na chamada de ferramentas e validação de argumentos |
| Saída estruturada | A rota satisfaz o esquema? | Taxa de JSON/esquema válido mais precisão em nível de campo |
| Contexto longo | A rota preserva as instruções e o contexto relevante? | Avaliação de documento longo com citações ou campos esperados |
| Visão ou arquivos | A rota lida com a modalidade de entrada real? | Conjunto de amostras reais com cobertura de tamanho e formato |
| Streaming | A rota preserva a forma do evento e o comportamento de recuperação? | Teste de fumaça de SSE/streaming e tratamento de tempo limite |
| Comportamento de segurança | A rota recusa ou escala corretamente? | Prompts de red-team e verificações de recusa/substituição |
A documentação de Saídas Estruturadas da OpenAI recomenda saídas baseadas em esquema quando a aplicação precisa de uma estrutura confiável. Para uma política de roteamento, isso significa que uma rota que não pode satisfazer o contrato de saída não deve ser usada para extração estruturada apenas por ser mais barata.
Dimensão da política 5: limites de fallback
O fallback não é automaticamente bom. Ele pode salvar o tempo de atividade, mas também pode alterar o comportamento, o tratamento do contexto, o preço, os limites de dados, o suporte a ferramentas ou a forma da saída.
Escreva as regras de fallback como transições explícitas:
workflow: invoice_extraction
primary_route: extraction_schema_route
allowed_fallbacks:
- extraction_schema_route_backup
blocked_fallbacks:
- general_chat_route
- creative_writing_route
fallback_triggers:
retry_same_route_once:
- transient_5xx
- rate_limit
stop_and_queue:
- schema_invalid_after_retry
- unsupported_file_type
- compliance_flag
evidence:
log_requested_model: true
log_served_model: true
log_fallback_reason: true
log_usage_units: trueUma política de roteamento de modelos madura separa a nova tentativa do fallback. Nova tentativa significa "tentar o mesmo contrato novamente." Fallback significa "mudar a rota." Essa mudança deve ser visível nos logs e aceita pelo proprietário do fluxo de trabalho.
Dimensão da política 6: observabilidade e evidências de faturamento
Roteamento sem evidências é adivinhação. Sua política deve definir os campos que toda solicitação de produção deve expor.
| Campo de evidência | Por que pertence à política |
|---|---|
| Nome do fluxo de trabalho | Conecta gastos e erros a um processo de negócio |
| Proprietário do aplicativo, equipe, chave ou cliente | Permite estorno e atribuição de incidentes |
| Modelo solicitado e modelo servido | Mostra se ocorreu fallback ou substituição de rota |
| Família de endpoints | Separa chat, respostas, imagem, vídeo, Anthropic, Gemini e outras formas de rota |
| Status e classe de erro | Distingue erros do provedor, erros do gateway, paradas de política e erros de validação |
| Unidades de uso | Permite que o financeiro reconcilie o uso de texto, cache, imagem, áudio e vídeo |
| Custo ou impacto no saldo | Converte rastreamentos de engenharia em gastos revisáveis |
| Motivo do fallback | Explica por que a política mudou de rota |
O posicionamento público atual da Flatkey atende a essa necessidade de evidência: um gateway para acesso a modelos, roteamento, faturamento, análise de uso e controles operacionais. Para este artigo, a verificação da API de preços em tempo real em 2 de julho de 2026 retornou success: true e expôs famílias de endpoints, incluindo openai, openai-response, anthropic, gemini, image-generation, openai-video e video. Trate isso como uma evidência de fonte datada, não como uma promessa de que cada rota, linha de modelo ou unidade de preço permanecerá inalterada.
Um modelo prático de política de roteamento de modelos
Use este modelo como a primeira versão do seu padrão de roteamento interno.
policy_name: customer_support_v1
owner:
team: support_platform
approver: product_and_finance
workflow:
description: classificar, responder e escalar solicitações de suporte
environment: production
data_sensitivity: customer_content
route_selection:
primary_route: balanced_support_route
required_capabilities:
- tool_calling
- structured_outputs
- streaming
blocked_routes:
- experimental_models
- unreviewed_provider_routes
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
cost:
max_cost_per_conversation: approved_budget
owner_key: support_platform_prod
risk:
human_review_required_when:
- refund_exception
- legal_or_policy_question
- confidence_below_threshold
fallback:
retry_same_route_once:
- transient_error
- rate_limit
fallback_to_backup_route:
- primary_route_unavailable
stop_without_fallback:
- safety_refusal
- schema_invalid_after_retry
- unapproved_data_region
evidence:
required_logs:
- workflow
- requested_model
- served_model
- endpoint_family
- route_status
- usage_units
- cost_or_balance
- fallback_reason
acceptance_tests:
min_eval_pass_rate: 0.95
max_schema_error_rate: 0.01
max_unreviewed_fallback_rate: 0Os nomes exatos das rotas variarão por equipe. O importante é que a política torna a escolha do modelo, o fallback, o custo, a latência e a comprovação revisáveis.
Testes de aceitação antes da produção
Não envie uma política de roteamento de modelos sem executar testes que simulem caminhos normais e de falha.
- Execute um conjunto de dados de referência (golden dataset) pela rota principal e registre a qualidade, validade do esquema, latência e uso.
- Acione um caminho de limite de taxa ou erro transitório e verifique o comportamento de nova tentativa.
- Acione uma falha de esquema e confirme se a política tenta novamente, para ou escala conforme escrito.
- Acione um fallback bloqueado e confirme se o gateway não altera a rota silenciosamente.
- Compare o modelo solicitado, o modelo servido, a família de endpoints e as unidades de uso nos logs.
- Verifique se o financeiro pode reconciliar as mesmas solicitações de amostra com o custo, saldo pré-pago, fatura ou linhas de exportação.
- Execute um teste de reversão (rollback) que fixe a rota anterior ou desative o fallback.
Para um contexto mais aprofundado sobre a arquitetura de gateway, combine esta lista de verificação com os guias da Flatkey sobre gateways de API de IA, arquitetura de gateway de API de LLM e balanceamento de carga e failover de API de IA.
Onde a Flatkey se encaixa
A Flatkey não deve substituir a política. Ela deve facilitar a aplicação e a revisão da política.
Use a Flatkey quando a equipe desejar uma única chave para modelos de IA conectados, um caminho de revisão do catálogo de modelos e preços atuais, visibilidade de uso, evidências em nível de solicitação, cotas e uma conversa de faturamento mais simples do que contas de provedores dispersas. A política de roteamento de modelos ainda precisa de proprietários, testes de aceitação, restrições de rota, regras de fallback e planos de reversão.
Uma execução de prova prática da Flatkey se parece com isto:
- Escolha um fluxo de trabalho semelhante ao de produção e uma chave de proprietário.
- Confirme a linha do modelo atual e a família de endpoints nos preços da Flatkey.
- Envie solicitações normais, de streaming, estruturadas e de falha controlada se o fluxo de trabalho as utilizar.
- Revise os logs de solicitação para o modelo solicitado, modelo servido, status, unidades de uso e evidência de fallback.
- Confirme o comportamento da cota e a revisão de custo ou saldo com o proprietário do fluxo de trabalho.
- Mova apenas a rota testada para a produção e, em seguida, expanda a política linha por linha.
Isso mantém a política de roteamento de modelos baseada em evidências reais, em vez de um diagrama de arquitetura.
FAQ
O que é uma política de roteamento de modelos?
Uma política de roteamento de modelos é uma regra escrita que mapeia cada fluxo de trabalho de IA para uma rota de modelo aprovada, requisitos de capacidade, teto de custo, meta de latência, comportamento de fallback e uma lista de verificação de evidências.
Por que não rotear todas as solicitações para o modelo mais forte?
A rota mais forte é frequentemente mais lenta e mais cara do que um fluxo de trabalho necessita. Uma política de roteamento de modelos permite que fluxos de trabalho de baixo risco usem rotas eficientes, enquanto preserva rotas mais fortes para raciocínio complexo, decisões sensíveis ou trabalho de alto valor.
Quando o fallback deve ser bloqueado?
Bloqueie o fallback quando uma mudança de rota puder alterar o manuseio de dados, a postura de conformidade, o esquema de saída, o comportamento da ferramenta, a qualidade voltada para o usuário ou a propriedade do faturamento. Nesses casos, coloque em fila, tente novamente ou escale em vez de alterar silenciosamente a rota do modelo.
Com que frequência as equipes devem atualizar uma política de roteamento de modelos?
Revise-a sempre que os catálogos de modelos, as unidades de precificação, o comportamento do endpoint, os requisitos de risco ou os resultados de avaliação mudarem. No mínimo, revise as políticas de produção ativas trimestralmente e após qualquer migração importante de modelo.
Qual é a primeira métrica a ser observada?
Observe o custo por resultado aceito, não apenas o custo por token. Em seguida, combine-o com a latência p95, a taxa de fallback, a taxa de esquema válido e a evidência de faturamento no nível da solicitação.
Como o Flatkey ajuda no design da política de roteamento de modelos?
O Flatkey pode fornecer uma única superfície de gateway para acesso a modelos, revisão de preços, roteamento, análise de uso, logs de solicitações, cotas e revisão de faturamento. Isso dá às equipes um lugar prático para validar se a política de roteamento de modelos está se comportando conforme o escrito.
Comece com os preços do Flatkey, escolha um fluxo de trabalho, depois obtenha uma chave e execute uma pequena prova que verifique o comportamento da rota, logs, cotas, custo, fallback e reversão antes do lançamento em produção.