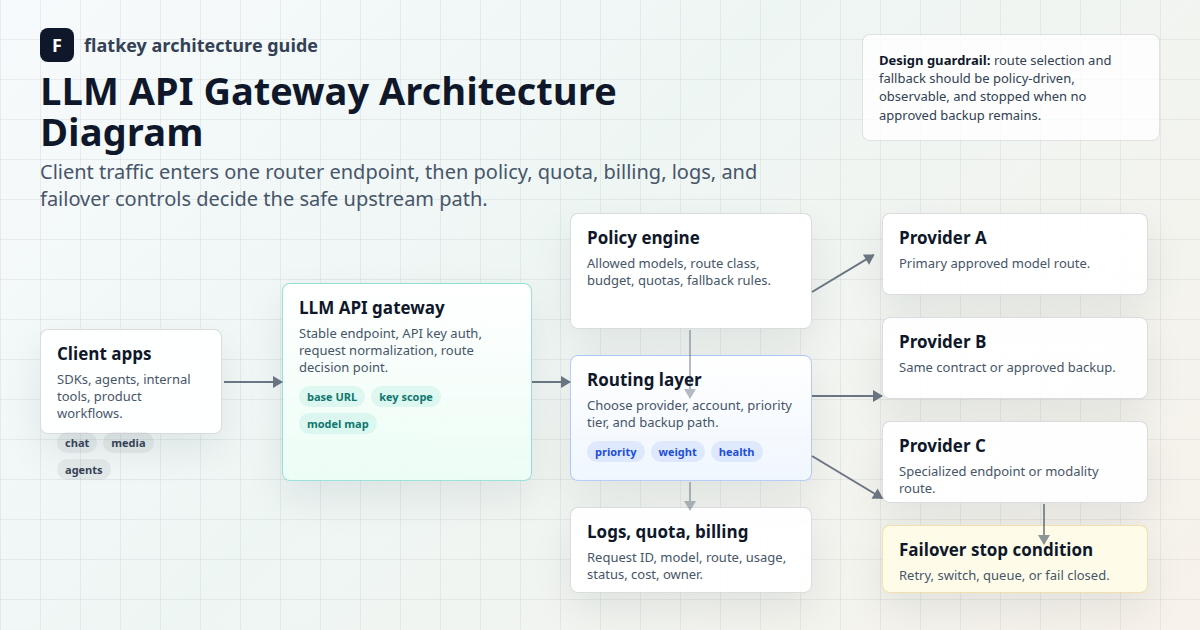
Todo producto de IA acaba superando el uso de un único modelo por defecto. Un bot de soporte, un revisor de código, un extractor de facturas, un asistente de prompts de imágenes y un agente de investigación interno no necesitan el mismo objetivo de latencia, presupuesto de contexto, profundidad de razonamiento, comportamiento de las herramientas, regla de fallback o rastro de aprobación. Una política de enrutamiento de modelos convierte esas concesiones en un contrato operativo en lugar de un montón de cadenas model= ad hoc.
El objetivo no es elegir un único modelo "óptimo". El objetivo es que la elección del modelo sea revisable. Una buena política de enrutamiento de modelos indica a los ingenieros qué clase de modelo usar, cuándo gastar más, cuándo optimizar la latencia, cuándo bloquear el fallback y qué evidencia debe existir antes de que un flujo de trabajo pase a producción.
Flatkey es importante en este debate porque el enrutamiento es más fácil de gobernar cuando el acceso a los modelos, las claves, los registros de solicitudes, los análisis de uso, la revisión de precios y los controles operativos se encuentran en un solo lugar. Utilice la política que se describe a continuación como capa de diseño y, a continuación, valide el catálogo de modelos y la página de precios actuales de Flatkey antes del despliegue en producción.
Diseño de la política de enrutamiento de modelos en una tabla
Empiece con las clases de flujos de trabajo, no con los nombres de los proveedores. La siguiente tabla es el primer borrador práctico para una política de enrutamiento de modelos.
| Clase de flujo de trabajo | Ruta principal | Regla de costo | Regla de latencia | Regla de riesgo | Regla de fallback | Evidencia requerida |
|---|---|---|---|---|---|---|
| Clasificación rápida | Modelo de texto pequeño o de bajo razonamiento | El costo más bajo que supere las evaluaciones | Objetivo p95 estricto | Bajo riesgo empresarial | Seguro para reintentar o degradar | Muestra de precisión, latencia p95, costo por cada 1000 llamadas |
| Chat con clientes | Modelo equilibrado con soporte para herramientas | Límite por conversación o cuenta | p95 bajo y streaming estable | Riesgo medio | Fallback solo a modelos con tono y comportamiento de herramientas probados | Evaluaciones de conversación, comprobaciones de rechazo, éxito de llamadas a herramientas, control de calidad de transcripciones |
| Código y razonamiento técnico | Modelo de razonamiento potente | Gastar más solo en tareas difíciles | Presupuesto de latencia más flexible | Riesgo medio a alto | Fallback a una ruta homóloga revisada, no a un modelo débil | Evaluaciones de tareas, corrección de diff, seguimiento de herramientas, ruta de reversión |
| Extracción estructurada | Modelo con soporte para esquemas | Optimizar por registro válido | Por lotes o casi en tiempo real | Riesgo medio | Reintentar con una ruta igual o más estricta antes del fallback | Tasa de esquemas válidos, precisión de campo, taxonomía de errores |
| Revisión de adquisiciones o finanzas | Ruta de modelo revisada y fijada | Costo secundario a la auditabilidad | Asíncrono aceptable | Riesgo alto | Sin fallback automático sin aprobación | Seguimiento de origen, versión del modelo, registro de solicitudes, aprobación del revisor |
| Resumen en segundo plano | Ruta de menor costo o compatible con lotes | Minimizar el costo por resumen aceptado | Asíncrono | Riesgo bajo a medio | Fallback después de agotar el presupuesto de reintentos | Calidad de la muestra, tasa de reintentos, métricas de tokens en caché |
Esta tabla no es la política final. Es la superficie de decisión. Cada fila necesita puertas medibles antes de convertirse en enrutamiento de producción.
Qué debe decidir una política de enrutamiento de modelos
Una política de enrutamiento de modelos es una regla escrita que asigna un flujo de trabajo a las capacidades del modelo, los límites de costo, los SLO de latencia, el comportamiento de fallback y los requisitos de evidencia. Debe responder a seis preguntas para cada flujo de trabajo de producción:
- ¿Qué intenta optimizar el flujo de trabajo: velocidad, calidad, costo, fiabilidad, seguridad, modalidad, longitud del contexto o auditabilidad?
- ¿Qué capacidades se requieren: llamada a herramientas, salida estructurada, contexto largo, entrada de imágenes, streaming, razonamiento bajo, razonamiento alto o soporte de endpoints específicos del proveedor?
- ¿Cuál es el presupuesto para fallos: reintentar, fallback, degradar, encolar, preguntar a un humano o detenerse?
- ¿Qué puede cambiar automáticamente: proveedor, tamaño del modelo, esfuerzo de razonamiento, tiempo de espera, grupo de rutas o nada?
- ¿Qué debe registrarse: modelo solicitado, modelo servido, ruta, estado, unidades de uso, costo, intento de fallback y propietario?
- ¿Qué prueba se necesita antes del lanzamiento: puntuación de evaluación, muestra de latencia, prueba de cuota, seguimiento de facturación, revisión de seguridad o aprobación de adquisiciones?
La guía actual de GPT-5.5 de OpenAI es útil aquí porque trata la configuración de la API como parte del rendimiento del modelo, no como una ocurrencia tardía. La documentación destaca el manejo del estado de la API de respuestas, el esfuerzo de razonamiento, la verbosidad, las salidas estructuradas, el almacenamiento en caché de prompts, el diseño de herramientas, las herramientas alojadas y la gestión de estado como factores que afectan la inteligencia, la fiabilidad, la latencia y el costo. Ese es exactamente el tipo de dimensión que una política de enrutamiento de modelos debe preservar.
Dimensión de la política 1: riesgo del flujo de trabajo
El riesgo es la primera división del enrutamiento porque controla cuánta automatización se permite.
Los flujos de trabajo de bajo riesgo suelen tolerar reintentos, rutas más baratas y un fallback amplio. Algunos ejemplos son el etiquetado interno, los resúmenes ligeros, las sugerencias de borradores y la clasificación no crítica. Estos son buenos candidatos para controles de costos agresivos porque un reintento ocasional o una muestra de revisión es aceptable.
Los flujos de trabajo de riesgo medio necesitan pruebas de aceptación más estrictas. El soporte al cliente, la automatización de flujos de trabajo, las sugerencias de código y las herramientas de asistencia de ventas pueden no requerir una revisión humana cada vez, pero sí requieren comprobaciones de tono, comprobaciones de llamadas a herramientas y evidencia de la ruta cuando se producen errores.
Los flujos de trabajo de alto riesgo deben estar fijados de forma más estricta. Las revisiones de adquisiciones, los resúmenes legales, las aprobaciones financieras, las decisiones de seguridad y los flujos de trabajo regulados no deberían recurrir silenciosamente a un modelo o proveedor diferente solo porque la ruta principal sea lenta. La política de enrutamiento de modelos debe requerir una aprobación explícita antes de que el fallback cambie la postura de riesgo.
La regla simple: si un humano preguntara "¿qué modelo respondió realmente a esto?" después de un mal resultado, la ruta necesita un registro más sólido y un fallback automático más débil.
Dimensión de la política 2: latencia y experiencia del usuario
La latencia pertenece a la política porque el mismo modelo puede ser aceptable para un flujo de trabajo asíncrono e inaceptable para un producto interactivo.
Para el chat interactivo, establece las expectativas de p50, p95, tiempo de espera y streaming. Si el tiempo hasta el primer token es importante, mídelo por separado del tiempo total de finalización. Para las tareas en segundo plano, define en su lugar el tiempo máximo de cola y el plazo de finalización.
No establezcas una regla vaga como "usar el modelo rápido". Escribe la política de enrutamiento de modelos como un objetivo comprobable:
workflow: support_chat_triage
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
timeout_ms: 10000
fallback:
on_timeout: use_reviewed_balanced_route
on_schema_error: retry_same_route_once
on_safety_or_policy_error: stop_and_escalateLos documentos de almacenamiento en caché de prompts de OpenAI son otro recordatorio de que la latencia no es solo la selección del modelo. Los prefijos de prompt estables, las claves de caché consistentes y el monitoreo de aciertos de caché pueden cambiar materialmente la latencia y el costo de los tokens de entrada para cargas de trabajo repetidas. Si el almacenamiento en caché es parte del plan, conviértelo en un requisito de la política y registra las métricas de tokens almacenados en caché.
Dimensión de la política 3: límites de costo
Los controles de costos deben expresarse por resultado del flujo de trabajo, no solo por token. Una ruta barata que falla a menudo puede costar más que una ruta más robusta que tiene éxito en el primer intento.
Usa tres límites de costo:
| Límite | Ejemplo | Por qué es importante |
|---|---|---|
| Por solicitud | Costo máximo para una solicitud, trabajo de imagen, video o turno | Evita que una sola llamada sorprenda a finanzas |
| Por flujo de trabajo | Costo máximo para un ticket completado, extracción, respuesta o documento | Tiene en cuenta los reintentos y el fallback |
| Por propietario | Presupuesto por aplicación, equipo, cliente, entorno o clave | Mantiene el gasto vinculado a la responsabilidad |
La página de precios de Flatkey es útil durante esta etapa porque proporciona a los equipos una ruta de revisión de modelos y precios actuales, mientras que la superficie del producto enfatiza la medición del uso, los registros de solicitudes, el análisis de uso y los controles de costos. Antes del enrutamiento de producción, verifica la página /pricing actual y confirma la fila del modelo, la familia de endpoints y la unidad de uso para el flujo de trabajo real.
Dimensión de la política 4: adecuación de la capacidad
El diseño de la política de enrutamiento de modelos debe comenzar a partir de las capacidades requeridas. El precio y la latencia solo importan después de que la ruta pueda hacer el trabajo.
Para cada flujo de trabajo, califica estas capacidades:
| Capacidad | Pregunta de la ruta | Prueba de aceptación |
|---|---|---|
| Uso de herramientas | ¿La ruta llama a las herramientas requeridas correctamente? | Tasa de éxito de llamadas a herramientas y validación de argumentos |
| Salida estructurada | ¿La ruta satisface el esquema? | Tasa de JSON/esquema válido más precisión a nivel de campo |
| Contexto largo | ¿La ruta preserva las instrucciones y el contexto relevante? | Evaluación de documentos largos con citas o campos esperados |
| Visión o archivos | ¿La ruta maneja la modalidad de entrada real? | Conjunto de muestras reales con cobertura de tamaño y formato |
| Streaming | ¿La ruta preserva la forma del evento y el comportamiento de recuperación? | Prueba de humo de SSE/streaming y manejo de timeouts |
| Comportamiento de seguridad | ¿La ruta rechaza o escala correctamente? | Prompts de equipo rojo y verificaciones de rechazo/anulación |
Los documentos de Salidas Estructuradas de OpenAI recomiendan una salida respaldada por un esquema cuando la aplicación necesita una estructura confiable. Para una política de enrutamiento, eso significa que una ruta que no puede satisfacer el contrato de salida no debe usarse para la extracción estructurada solo porque es más barata.
Dimensión de la política 5: límites del fallback
El fallback no es automáticamente bueno. Puede rescatar el tiempo de actividad, pero también puede cambiar el comportamiento, el manejo del contexto, el precio, los límites de los datos, el soporte de herramientas o la forma de la salida.
Escribe las reglas de fallback como transiciones explícitas:
workflow: invoice_extraction
primary_route: extraction_schema_route
allowed_fallbacks:
- extraction_schema_route_backup
blocked_fallbacks:
- general_chat_route
- creative_writing_route
fallback_triggers:
retry_same_route_once:
- transient_5xx
- rate_limit
stop_and_queue:
- schema_invalid_after_retry
- unsupported_file_type
- compliance_flag
evidence:
log_requested_model: true
log_served_model: true
log_fallback_reason: true
log_usage_units: trueUna política de enrutamiento de modelos madura separa el reintento del fallback. Reintento significa "intentar el mismo contrato de nuevo". Fallback significa "cambiar la ruta". Ese cambio debe ser visible en los registros y aceptado por el propietario del flujo de trabajo.
Dimensión de la política 6: observabilidad y evidencia de facturación
El enrutamiento sin evidencia es una conjetura. Tu política debe definir los campos que cada solicitud de producción debe exponer.
| Campo de evidencia | Por qué pertenece a la política |
|---|---|
| Nombre del flujo de trabajo | Conecta el gasto y los errores con un proceso de negocio |
| Propietario de la aplicación, equipo, clave o cliente | Permite la atribución de contracargos e incidentes |
| Modelo solicitado y modelo servido | Muestra si ocurrió un fallback o una sustitución de ruta |
| Familia de endpoints | Separa chat, respuestas, imagen, video, Anthropic, Gemini y otras formas de ruta |
| Estado y clase de error | Distingue entre errores del proveedor, errores del gateway, detenciones por política y errores de validación |
| Unidades de uso | Permite a finanzas conciliar el uso de texto, caché, imagen, audio y video |
| Costo o impacto en el saldo | Convierte los seguimientos de ingeniería en gastos revisables |
| Motivo del fallback | Explica por qué la política cambió de ruta |
El posicionamiento público actual de Flatkey se ajusta a esta necesidad de evidencia: un gateway para el acceso a modelos, enrutamiento, facturación, análisis de uso y controles operativos. Para este artículo, la verificación de la API de precios en tiempo real el 2 de julio de 2026 devolvió success: true y expuso familias de endpoints que incluyen openai, openai-response, anthropic, gemini, image-generation, openai-video y video. Considere esto como evidencia de una fuente fechada, no como una promesa de que cada ruta, fila de modelo o unidad de precio permanecerá sin cambios.
Una plantilla práctica de política de enrutamiento de modelos
Utilice esta plantilla como la primera versión de su estándar de enrutamiento interno.
policy_name: customer_support_v1
owner:
team: support_platform
approver: product_and_finance
workflow:
description: clasificar, responder y escalar solicitudes de soporte
environment: production
data_sensitivity: customer_content
route_selection:
primary_route: balanced_support_route
required_capabilities:
- tool_calling
- structured_outputs
- streaming
blocked_routes:
- experimental_models
- unreviewed_provider_routes
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
cost:
max_cost_per_conversation: approved_budget
owner_key: support_platform_prod
risk:
human_review_required_when:
- refund_exception
- legal_or_policy_question
- confidence_below_threshold
fallback:
retry_same_route_once:
- transient_error
- rate_limit
fallback_to_backup_route:
- primary_route_unavailable
stop_without_fallback:
- safety_refusal
- schema_invalid_after_retry
- unapproved_data_region
evidence:
required_logs:
- workflow
- requested_model
- served_model
- endpoint_family
- route_status
- usage_units
- cost_or_balance
- fallback_reason
acceptance_tests:
min_eval_pass_rate: 0.95
max_schema_error_rate: 0.01
max_unreviewed_fallback_rate: 0Los nombres exactos de las rutas diferirán según el equipo. La parte importante es que la política hace que la elección del modelo, el fallback, el costo, la latencia y la prueba sean revisables.
Pruebas de aceptación antes de la producción
No implemente una política de enrutamiento de modelos sin ejecutar pruebas que simulen rutas normales y de fallo.
- Ejecute un conjunto de datos de referencia (golden dataset) a través de la ruta principal y registre la calidad, la validez del esquema, la latencia y el uso.
- Active una ruta de límite de velocidad o de error transitorio y verifique el comportamiento de reintento.
- Provoque un fallo de esquema y confirme que la política reintenta, se detiene o escala según lo escrito.
- Active un fallback bloqueado y confirme que el gateway no cambia de ruta silenciosamente.
- Compare el modelo solicitado, el modelo servido, la familia de endpoints y las unidades de uso en los registros.
- Verifique si el departamento de finanzas puede conciliar las mismas solicitudes de muestra con el costo, el saldo prepago, la factura o las filas de exportación.
- Ejecute una prueba de reversión (rollback) que fije la ruta anterior o deshabilite el fallback.
Para un contexto más profundo sobre la arquitectura de gateways, combine esta lista de verificación con las guías de Flatkey sobre gateways de API de IA, arquitectura de gateways de API de LLM y balanceo de carga y conmutación por error de API de IA.
Dónde encaja Flatkey
Flatkey no debe reemplazar la política. Debe hacer que la política sea más fácil de aplicar y revisar.
Use Flatkey cuando el equipo quiera una única clave para los modelos de IA conectados, una ruta de revisión del catálogo de modelos y precios actuales, visibilidad del uso, evidencia a nivel de solicitud, cuotas y una conversación de facturación más simple que con cuentas de proveedores dispersas. La política de enrutamiento de modelos todavía necesita propietarios, pruebas de aceptación, restricciones de ruta, reglas de fallback y planes de reversión.
Una prueba de concepto práctica de Flatkey se ve así:
- Elija un flujo de trabajo similar al de producción y una clave de propietario.
- Confirme la fila del modelo actual y la familia de endpoints en los precios de Flatkey.
- Envíe solicitudes normales, de streaming, estructuradas y de fallo controlado si el flujo de trabajo las utiliza.
- Revise los registros de solicitudes para el modelo solicitado, el modelo servido, el estado, las unidades de uso y la evidencia de fallback.
- Confirme el comportamiento de la cuota y la revisión del costo o saldo con el propietario del flujo de trabajo.
- Mueva solo la ruta probada a producción, luego expanda la política fila por fila.
Esto mantiene la política de enrutamiento de modelos basada en evidencia real en lugar de en un diagrama de arquitectura.
Preguntas frecuentes
¿Qué es una política de enrutamiento de modelos?
Una política de enrutamiento de modelos es una regla escrita que asigna cada flujo de trabajo de IA a una ruta de modelo aprobada, requisitos de capacidad, techo de costo, objetivo de latencia, comportamiento de fallback y una lista de verificación de evidencia.
¿Por qué no enrutar cada solicitud al modelo más potente?
La ruta más potente suele ser más lenta y costosa de lo que un flujo de trabajo necesita. Una política de enrutamiento de modelos permite que los flujos de trabajo de bajo riesgo utilicen rutas eficientes, al tiempo que se conservan rutas más potentes para el razonamiento complejo, las decisiones delicadas o el trabajo de alto valor.
¿Cuándo se debe bloquear el fallback?
Bloquee el fallback cuando un cambio de ruta pueda alterar el manejo de datos, la postura de cumplimiento, el esquema de salida, el comportamiento de la herramienta, la calidad de cara al usuario o la propiedad de la facturación. En esos casos, ponga en cola, reintente o escale en lugar de cambiar silenciosamente la ruta del modelo.
¿Con qué frecuencia deben los equipos actualizar una política de enrutamiento de modelos?
Revísela cada vez que cambien los catálogos de modelos, las unidades de precios, el comportamiento de los endpoints, los requisitos de riesgo o los resultados de las evaluaciones. Como mínimo, revise las políticas de producción activas trimestralmente y después de cualquier migración importante de modelos.
¿Cuál es la primera métrica que se debe observar?
Observe el costo por resultado aceptado, no solo el costo por token. Luego, combínelo con la latencia p95, la tasa de fallback, la tasa de esquemas válidos y la evidencia de facturación a nivel de solicitud.
¿Cómo ayuda Flatkey con el diseño de políticas de enrutamiento de modelos?
Flatkey puede proporcionar una única superficie de gateway para el acceso a modelos, la revisión de precios, el enrutamiento, el análisis de uso, los registros de solicitudes, las cuotas y la revisión de la facturación. Esto proporciona a los equipos un lugar práctico para validar si la política de enrutamiento de modelos se está comportando según lo escrito.
Comience con los precios de Flatkey, elija un flujo de trabajo, luego obtenga una clave y ejecute una pequeña prueba que verifique el comportamiento de la ruta, los registros, las cuotas, el costo, el fallback y el rollback antes del despliegue en producción.