すべてのAI製品は、最終的には単一のデフォルトモデルでは対応できなくなります。サポートボット、コードレビュー担当者、請求書抽出ツール、画像プロンプトヘルパー、社内調査エージェントは、同じレイテンシー目標、コンテキスト予算、推論の深さ、ツール動作、フォールバックルール、承認経路を必要としません。モデルルーティングポリシーは、これらのトレードオフを、場当たり的なmodel=文字列の山ではなく、運用契約に変えます。
目標は、1つの「最良の」モデルを選ぶことではありません。目標は、モデルの選択をレビュー可能にすることです。優れたモデルルーティングポリシーは、エンジニアにどのモデルクラスを使用すべきか、いつより多くの費用をかけるべきか、いつレイテンシーを最適化すべきか、いつフォールバックをブロックすべきか、そしてワークフローを本番環境に移行する前にどのような証拠が必要かを示します。
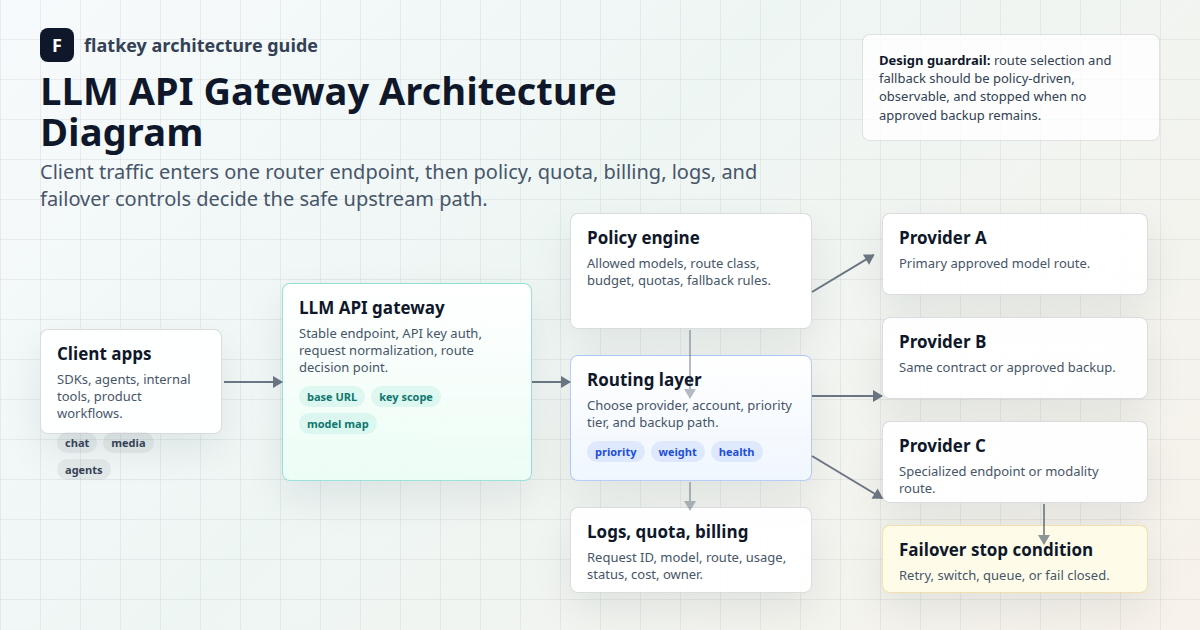
この議論においてFlatkeyが重要なのは、モデルアクセス、キー、リクエストログ、使用状況分析、価格レビュー、運用管理が1か所に集約されていると、ルーティングの管理が容易になるためです。以下のポリシーを設計レイヤーとして使用し、本番展開の前に現在のFlatkeyモデルカタログと価格ページを検証してください。
1つの表で見るモデルルーティングポリシーの設計
プロバイダー名ではなく、ワークフローのクラスから始めましょう。以下の表は、モデルルーティングポリシーの実践的な第一歩です。
| ワークフロークラス | プライマリルート | コストルール | レイテンシールール | リスクルール | フォールバックルール | 必要な証拠 |
|---|---|---|---|---|---|---|
| 高速分類 | 小規模または低推論のテキストモデル | 評価をパスする最低コスト | 厳格なp95目標 | 低いビジネスリスク | 再試行またはダウングレードしても安全 | 精度サンプル、p95レイテンシー、1,000コールあたりのコスト |
| 顧客チャット | ツールサポートを備えたバランスの取れたモデル | 会話またはアカウントごとの上限設定 | 低いp95と安定したストリーミング | 中程度のリスク | テスト済みのトーンとツール動作を持つモデルにのみフォールバック | 会話評価、拒否チェック、ツールコール成功、トランスクリプトQA |
| コードと技術的推論 | 強力な推論モデル | 困難なタスクにのみより多くの費用をかける | 緩やかなレイテンシー予算 | 中〜高リスク | 弱いモデルではなく、レビュー済みのピア(同等)ルートにフォールバック | タスク評価、差分の正当性、ツールトレース、ロールバックパス |
| 構造化抽出 | スキーマをサポートするモデル | 有効なレコードごとに最適化 | バッチまたはニアリアルタイム | 中程度のリスク | フォールバック前に同じまたはより厳格なルートで再試行 | スキーマ検証率、フィールド精度、エラー分類 |
| 調達または財務レビュー | 固定されたレビュー済みモデルルート | コストは監査可能性より優先度が低い | 非同期でも許容 | 高いリスク | 承認なしの自動フォールバックは不可 | ソース追跡、モデルバージョン、リクエストログ、レビュー担当者の承認 |
| バックグラウンドでの要約 | 低コストまたはバッチ処理に適したルート | 承認された要約あたりのコストを最小化 | 非同期 | 低〜中リスク | 再試行予算を使い果たした後にフォールバック | サンプル品質、再試行率、キャッシュされたトークンのメトリクス |
この表は最終的なポリシーではありません。これは意思決定の土台です。各行は、本番のルーティングになる前に、測定可能なゲートを必要とします。
モデルルーティングポリシーが決定すべきこと
モデルルーティングポリシーとは、ワークフローをモデルの能力、コスト上限、レイテンシーSLO、フォールバック動作、および証拠要件にマッピングする成文化されたルールです。すべての本番ワークフローについて、以下の6つの質問に答える必要があります。
- ワークフローが最適化しようとしているのは何か:速度、品質、コスト、信頼性、安全性、モダリティ、コンテキスト長、または監査可能性か?
- どの能力が必要か:ツール呼び出し、構造化出力、長いコンテキスト、画像入力、ストリーミング、低い推論能力、高い推論能力、またはプロバイダー固有のエンドポイントサポートか?
- 障害発生時の予算は何か:再試行、フォールバック、機能低下、キューイング、人間に尋ねる、または停止か?
- 自動的に変更できるものは何か:プロバイダー、モデルサイズ、推論の労力、タイムアウト、ルートグループ、または何もないか?
- 何をログに記録する必要があるか:リクエストされたモデル、提供されたモデル、ルート、ステータス、使用単位、コスト、フォールバックの試行、および所有者か?
- ローンチ前にどのような証明が必要か:評価スコア、レイテンシーサンプル、クォータテスト、請求追跡、セキュリティレビュー、または調達承認か?
OpenAIの現在のGPT-5.5ガイダンスは、API設定を後付けではなくモデルのパフォーマンスの一部として扱っているため、ここで役立ちます。ドキュメントでは、Responses APIの状態処理、推論の労力、冗長性、構造化出力、プロンプトのキャッシュ、ツール設計、ホストされたツール、および状態管理が、インテリジェンス、信頼性、レイテンシー、コストに影響を与える要因として挙げられています。これこそが、モデルルーティングポリシーが維持すべき側面です。
ポリシーの側面1:ワークフローのリスク
リスクは、許可される自動化の量を制御するため、最初のルーティングの分岐点となります。
低リスクのワークフローは、通常、再試行、より安価なルート、および広範なフォールバックを許容できます。例としては、社内でのタグ付け、軽量な要約、下書きの提案、重要でない分類などが挙げられます。これらは、時折の再試行やレビューサンプルが許容されるため、積極的なコスト管理の良い候補となります。
中リスクのワークフローには、より強力な受け入れテストが必要です。カスタマーサポート、ワークフローの自動化、コードの提案、営業支援ツールなどは、毎回人間のレビューを必要としないかもしれませんが、エラーが発生した場合には、トーンのチェック、ツールコールのチェック、およびルートの証拠が必要となります。
高リスクのワークフローは、より厳密に固定する必要があります。調達レビュー、法的要約、財務承認、セキュリティ決定、および規制対象のワークフローは、プライマリルートが遅いという理由だけで、別のモデルやプロバイダーにサイレントにフォールバックすべきではありません。モデルルーティングポリシーは、フォールバックがリスク態勢を変更する前に、明示的な承認を要求すべきです。
単純なルールは次のとおりです。悪い結果が出た後で人間が「これに実際に答えたのはどのモデルか?」と尋ねるような場合、そのルートにはより強力なロギングと、より弱い自動フォールバックが必要です。
ポリシーの側面2:レイテンシーとユーザーエクスペリエンス
レイテンシーがポリシーに含まれるべき理由は、同じモデルでも非同期ワークフローでは許容できても、インタラクティブな製品では許容できない場合があるからです。
インタラクティブなチャットでは、p50、p95、タイムアウト、ストリーミングの期待値を設定します。最初のトークンまでの時間(time-to-first-token)が重要であれば、総完了時間とは別に測定します。バックグラウンドタスクでは、代わりに最大キュー時間と完了期限を定義します。
「高速なモデルを使用する」のような曖昧なルールを設定しないでください。モデルルーティングポリシーは、テスト可能なターゲットとして記述します。
workflow: support_chat_triage
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
timeout_ms: 10000
fallback:
on_timeout: use_reviewed_balanced_route
on_schema_error: retry_same_route_once
on_safety_or_policy_error: stop_and_escalateOpenAIのプロンプトキャッシュに関するドキュメントは、レイテンシーがモデル選択だけの問題ではないことを改めて示しています。安定したプロンプトプレフィックス、一貫したキャッシュキー、キャッシュヒットの監視は、繰り返し行われるワークロードのレイテンシーと入力トークンコストを大幅に改善できます。キャッシュが計画の一部である場合は、それをポリシー要件とし、キャッシュされたトークンのメトリクスをログに記録します。
ポリシーの側面3:コスト上限
コスト管理は、トークンごとだけでなく、ワークフローの成果ごとに表現する必要があります。頻繁に失敗する安価なルートは、最初の試行で成功するより強力なルートよりもコストが高くつく可能性があります。
3つのコスト制限を使用します。
| 制限 | 例 | 重要性 |
|---|---|---|
| リクエストごと | 1つのリクエスト、画像、動画ジョブ、またはターンあたりの最大コスト | 1回の呼び出しで財務部門を驚かせることを防ぐ |
| ワークフローごと | 完了したチケット、抽出、回答、またはドキュメントあたりの最大コスト | 再試行とフォールバックを考慮に入れる |
| 所有者ごと | アプリ、チーム、顧客、環境、またはキーごとの予算 | 支出を説明責任と結びつける |
Flatkeyの料金ページはこの段階で役立ちます。なぜなら、チームに最新のモデルと料金のレビューパスを提供し、製品のインターフェースでは使用量の計測、リクエストログ、使用状況分析、コスト管理が重視されているからです。本番環境でのルーティングの前に、現在の/pricingページを確認し、実際のワークフローのモデル行、エンドポイントファミリー、および使用単位を確認してください。
ポリシーの側面4:機能の適合性
モデルルーティングポリシーの設計は、必要な機能から始めるべきです。価格とレイテンシーは、ルートがその仕事をこなせるようになって初めて重要になります。
各ワークフローについて、これらの機能を評価します。
| 機能 | ルートに関する質問 | 受け入れテスト |
|---|---|---|
| ツールの使用 | ルートは必要なツールを正しく呼び出すか? | ツール呼び出しの成功率と引数の検証 |
| 構造化出力 | ルートはスキーマを満たしているか? | 有効なJSON/スキーマ率とフィールドレベルの精度 |
| 長いコンテキスト | ルートは指示と関連コンテキストを保持するか? | 期待される引用やフィールドを含む長文ドキュメントの評価 |
| 画像またはファイル | ルートは実際の入力モダリティを処理できるか? | サイズとフォーマットを網羅した実際のサンプルセット |
| ストリーミング | ルートはイベントの形状と回復動作を保持するか? | SSE/ストリーミングのスモークテストとタイムアウト処理 |
| 安全性の振る舞い | ルートは正しく拒否またはエスカレーションするか? | レッドチームのプロンプトと拒否/オーバーライドのチェック |
OpenAIの構造化出力に関するドキュメントでは、アプリケーションが信頼性の高い構造を必要とする場合に、スキーマに基づいた出力を推奨しています。ルーティングポリシーにおいては、出力コントラクトを満たせないルートは、単に安価であるという理由だけで構造化抽出に使用すべきではないことを意味します。
ポリシーの側面5:フォールバックの境界
フォールバックは自動的に良いものとは限りません。稼働時間を救うことはできますが、振る舞い、コンテキスト処理、価格、データ境界、ツールサポート、または出力形式を変更してしまう可能性もあります。
フォールバックのルールは、明示的な遷移として記述します。
workflow: invoice_extraction
primary_route: extraction_schema_route
allowed_fallbacks:
- extraction_schema_route_backup
blocked_fallbacks:
- general_chat_route
- creative_writing_route
fallback_triggers:
retry_same_route_once:
- transient_5xx
- rate_limit
stop_and_queue:
- schema_invalid_after_retry
- unsupported_file_type
- compliance_flag
evidence:
log_requested_model: true
log_served_model: true
log_fallback_reason: true
log_usage_units: true成熟したモデルルーティングポリシーは、再試行とフォールバックを区別します。再試行は「同じコントラクトをもう一度試す」ことを意味します。フォールバックは「ルートを変更する」ことを意味します。その変更はログで確認でき、ワークフローの所有者によって受け入れられるべきです。
ポリシーの側面6:可観測性と課金のエビデンス
エビデンスのないルーティングは当て推量です。ポリシーでは、すべての本番リクエストが公開しなければならないフィールドを定義する必要があります。
| 証拠フィールド | ポリシーに含める理由 |
|---|---|
| ワークフロー名 | 支出とエラーをビジネスプロセスに結び付ける |
| アプリ、チーム、キー、または顧客の所有者 | チャージバックとインシデントの所有権を有効にする |
| リクエストされたモデルと提供されたモデル | フォールバックまたはルートの代替が発生したかどうかを示す |
| エンドポイントファミリー | チャット、レスポンス、画像、動画、Anthropic、Gemini、その他のルート形状を分離する |
| ステータスとエラークラス | プロバイダーエラー、ゲートウェイエラー、ポリシーによる停止、検証エラーを区別する |
| 使用量単位 | 財務部門がテキスト、キャッシュ、画像、音声、動画の使用量を照合できるようにする |
| コストまたは残高への影響 | エンジニアリングトレースをレビュー可能な支出に変換する |
| フォールバックの理由 | ポリシーがルートを変更した理由を説明する |
Flatkeyの現在のパブリックポジショニングは、この証拠のニーズに適合しています。つまり、モデルアクセス、ルーティング、請求、使用状況分析、および運用管理のための単一のゲートウェイです。この記事では、2026年7月2日のライブ価格APIチェックでsuccess: trueが返され、openai、openai-response、anthropic、gemini、image-generation、openai-video、videoなどのエンドポイントファミリーが公開されました。これは日付の古いソース証拠として扱い、すべてのルート、モデル行、または価格単位が変更されないことを約束するものではありません。
実用的なモデルルーティングポリシーのテンプレート
このテンプレートを、社内ルーティング標準の最初のバージョンとして使用してください。
policy_name: customer_support_v1
owner:
team: support_platform
approver: product_and_finance
workflow:
description: サポートリクエストの分類、回答、エスカレーション
environment: production
data_sensitivity: customer_content
route_selection:
primary_route: balanced_support_route
required_capabilities:
- tool_calling
- structured_outputs
- streaming
blocked_routes:
- experimental_models
- unreviewed_provider_routes
latency:
p95_first_token_ms: 1200
p95_complete_ms: 7000
cost:
max_cost_per_conversation: approved_budget
owner_key: support_platform_prod
risk:
human_review_required_when:
- refund_exception
- legal_or_policy_question
- confidence_below_threshold
fallback:
retry_same_route_once:
- transient_error
- rate_limit
fallback_to_backup_route:
- primary_route_unavailable
stop_without_fallback:
- safety_refusal
- schema_invalid_after_retry
- unapproved_data_region
evidence:
required_logs:
- workflow
- requested_model
- served_model
- endpoint_family
- route_status
- usage_units
- cost_or_balance
- fallback_reason
acceptance_tests:
min_eval_pass_rate: 0.95
max_schema_error_rate: 0.01
max_unreviewed_fallback_rate: 0正確なルート名はチームによって異なります。重要なのは、ポリシーによってモデルの選択、フォールバック、コスト、レイテンシー、および証明がレビュー可能になることです。
本番環境に移行する前の受け入れテスト
通常パスと障害パスをシミュレートするテストを実行せずに、モデルルーティングポリシーをリリースしないでください。
- ゴールデンデータセットをプライマリルートで実行し、品質、スキーマの有効性、レイテンシー、使用量を記録します。
- レート制限または一時的なエラーパスをトリガーし、再試行の動作を検証します。
- スキーマ障害をトリガーし、ポリシーが記述どおりに再試行、停止、またはエスカレーションすることを確認します。
- ブロックされたフォールバックをトリガーし、ゲートウェイがサイレントにルートを変更しないことを確認します。
- ログで、リクエストされたモデル、提供されたモデル、エンドポイントファミリー、使用量単位を比較します。
- 財務部門が同じサンプルリクエストをコスト、前払い残高、請求書、またはエクスポート行と照合できるかどうかを確認します。
- 以前のルートを固定するか、フォールバックを無効にするロールバックテストを実行します。
ゲートウェイアーキテクチャのより深いコンテキストについては、このチェックリストをAI APIゲートウェイ、LLM APIゲートウェイアーキテクチャ、およびAI APIのロードバランシングとフェイルオーバーに関するFlatkeyのガイドと併せて参照してください。
Flatkeyが適合する場面
Flatkeyはポリシーを置き換えるべきではありません。ポリシーの施行とレビューを容易にするためのものです。
チームが、接続されたAIモデル用の単一キー、最新の価格設定とモデルカタログのレビューパス、使用状況の可視性、リクエストレベルの証拠、クォータ、そして散在するプロバイダーアカウントよりも簡単な請求に関する対話を求めている場合にFlatkeyを使用します。モデルルーティングポリシーには、依然として所有者、受け入れテスト、ルート制約、フォールバックルール、およびロールバック計画が必要です。
Flatkeyの実用的な検証実行は次のようになります。
- 本番環境に近いワークフローと所有者キーを1つ選択します。
- Flatkeyの価格設定で現在のモデル行とエンドポイントファミリーを確認します。
- ワークフローが使用する場合は、通常、ストリーミング、構造化、および制御された障害リクエストを送信します。
- リクエストログで、リクエストされたモデル、提供されたモデル、ステータス、使用量単位、およびフォールバックの証拠を確認します。
- ワークフローの所有者とクォータの動作、コストまたは残高のレビューを確認します。
- テスト済みのルートのみを本番環境に移行し、その後ポリシーを行ごとに拡張します。
これにより、モデルルーティングポリシーはアーキテクチャ図ではなく、実際の証拠に基づいたものになります。
よくある質問
モデルルーティングポリシーとは何ですか?
モデルルーティングポリシーとは、各AIワークフローを、承認されたモデルルート、機能要件、コスト上限、レイテンシー目標、フォールバック動作、および証拠チェックリストにマッピングする、文書化されたルールです。
なぜすべてのリクエストを最強のモデルにルーティングしないのですか?
最強のルートは、多くの場合、ワークフローが必要とするよりも遅く、高価です。モデルルーティングポリシーにより、低リスクのワークフローは効率的なルートを使用でき、一方で、高度な推論、機密性の高い意思決定、または価値の高い作業のために、より強力なルートを保持できます。
フォールバックはいつブロックすべきですか?
ルートの変更がデータ処理、コンプライアンス体制、出力スキーマ、ツールの動作、ユーザー向けの品質、または請求所有権を変更する可能性がある場合は、フォールバックをブロックします。そのような場合は、モデルルートをサイレントに変更するのではなく、キューに入れる、再試行する、またはエスカレーションします。
チームはどのくらいの頻度でモデルルーティングポリシーを更新すべきですか?
モデルカタログ、価格単位、エンドポイントの動作、リスク要件、または評価結果が変更されるたびに見直してください。少なくとも、アクティブな本番ポリシーは四半期ごと、および主要なモデル移行後に見直してください。
最初に注目すべきメトリクスは何ですか?
トークンあたりのコストだけでなく、承認された結果あたりのコストに注目してください。次に、それをp95レイテンシー、フォールバック率、スキーマ有効率、およびリクエストレベルの請求証拠と組み合わせます。
Flatkeyはモデルルーティングポリシーの設計にどのように役立ちますか?
Flatkeyは、モデルアクセス、価格レビュー、ルーティング、使用状況分析、リクエストログ、クォータ、および請求レビューのための単一のゲートウェイサーフェスを提供できます。これにより、チームはモデルルーティングポリシーが記述どおりに動作しているかどうかを検証するための実用的な場所を得ることができます。
まずFlatkeyの価格から始め、ワークフローを1つ選択し、次にキーを取得して、本番環境への展開前に、ルートの動作、ログ、クォータ、コスト、フォールバック、およびロールバックをチェックする小規模な実証を行います。