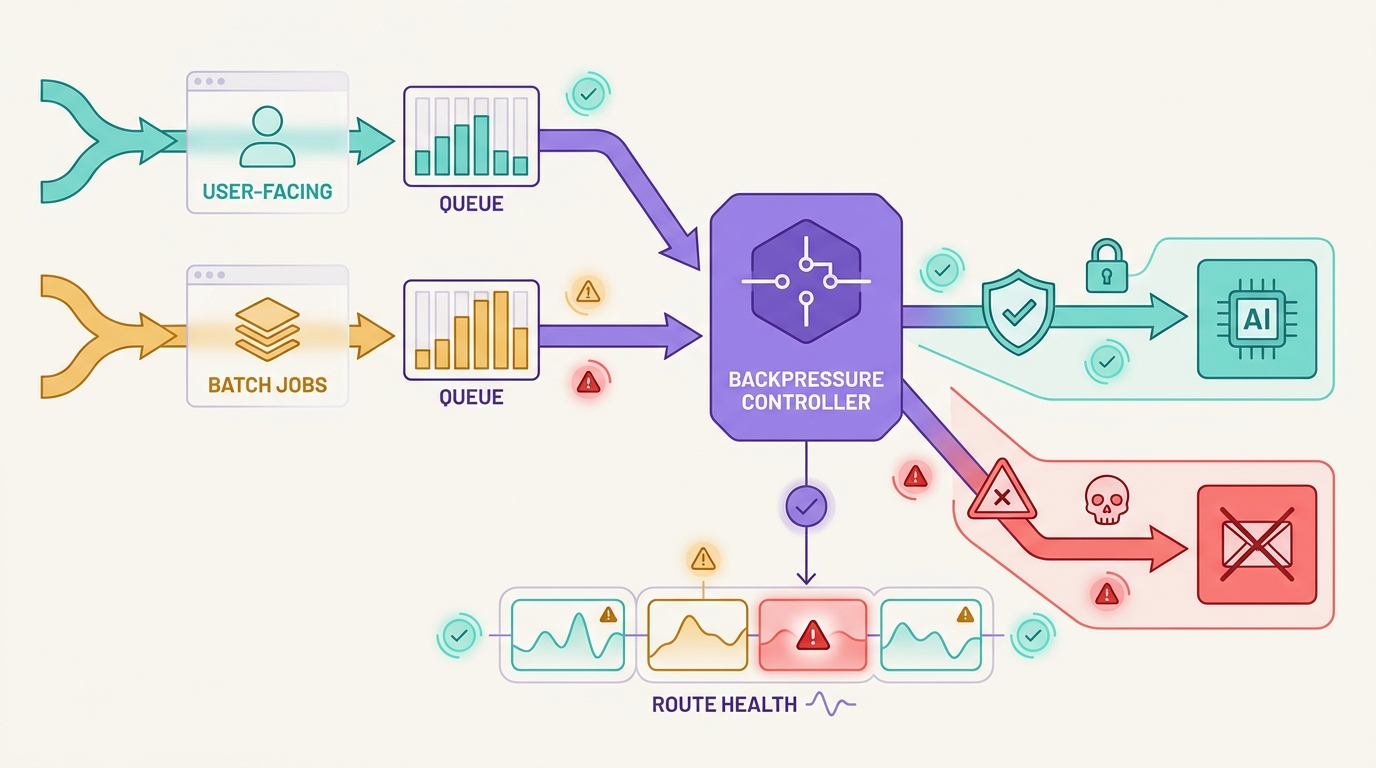
Les timeouts ne se résument pas à un seul chiffre. Une stratégie de timeout pour une API d'IA en production nécessite des budgets distincts pour la connexion, la lecture de la réponse, le streaming des événements de jetons, l'attente dans une file, les nouvelles tentatives sécurisées et la décision d'arrêter le repli. Si ces budgets sont mélangés, un fournisseur lent, un pool de connexions bloqué ou un flux à moitié ouvert peuvent tous apparaître comme le même incident.
L'objectif d'une stratégie de timeout pour une API d'IA est de rendre les échecs limités et observables. Une requête de chat destinée à l'utilisateur peut nécessiter un premier jeton rapide et un arrêt brutal. Une tâche de recherche en arrière-plan peut nécessiter une échéance de file d'attente et un mécanisme de polling. Une tâche d'extraction de schéma peut nécessiter une nouvelle tentative sur la même route avant de se replier. Chaque workflow a besoin de son propre budget, et chaque timeout doit laisser des traces pour les équipes d'ingénierie, financières et les chefs de produit.
Flatkey est adapté à ce travail de fiabilité, car la politique de timeout est plus facile à examiner lorsque l'accès au modèle, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels sont gérés via une seule passerelle. Utilisez la liste de contrôle ci-dessous comme politique d'application, puis validez la ligne de modèle Flatkey actuelle, la famille de points de terminaison, les preuves d'utilisation et le comportement de la route avant d'envoyer du trafic de production.
Stratégie de timeout pour les API d'IA en un tableau
Commencez par attribuer un propriétaire et une condition d'arrêt à chaque couche de timeout.
| Couche de timeout | Ce qu'elle protège | Budget de départ | Règle de nouvelle tentative | Règle de repli | Preuves à journaliser |
|---|---|---|---|---|---|
| Connexion | DNS, TLS, accessibilité de la passerelle et configuration du socket | Court, généralement inférieur au budget de la requête | Nouvelle tentative uniquement si aucun corps de requête n'a été accepté | Utiliser la route de secours uniquement lorsque la famille de points de terminaison est équivalente | connect_ms, route, hôte, classe d'erreur |
| Acquisition de pool ou de file d'attente | Attente d'un worker local, d'une connexion ou d'un créneau de limitation de débit | Très court pour le travail interactif | Ne pas relancer aveuglément ; réduire d'abord la simultanéité | Mettre en file d'attente ou délester la charge avant de changer de modèle | âge de la file, attente du pool, simultanéité, propriétaire |
| Requête/lecture | Attente du corps de la réponse après l'envoi de la requête | Lié à l'UX ou à l'échéance de la tâche | Une ou deux nouvelles tentatives limitées pour les échecs transitoires | Repli uniquement vers une route qui préserve le contrat de sortie | ID de requête, statut, timeout de lecture, utilisation si présente |
| Premier événement du flux | Attente du premier événement SSE ou de jeton | Inférieur à l'échéance totale du flux | Nouvelle tentative avant le début de la sortie visible par l'utilisateur | Repli uniquement avant que la sortie partielle ne soit validée | latence du premier événement, modèle demandé, modèle servi |
| Inactivité du flux | Intervalle entre les morceaux du flux après le début de la sortie | Basé sur les intervalles normaux entre les événements | Reprendre uniquement si l'API le prend en charge ; sinon, arrêter proprement | Éviter de changer de modèle en cours de réponse | dernière séquence, intervalle d'inactivité, marqueur de sortie partielle |
| File d'attente en arrière-plan | Travail de longue durée en dehors de la requête de l'utilisateur | Échéance explicite et intervalle de polling | Interroger jusqu'à l'état terminal ou l'échéance | Escalader ou annuler avant de dupliquer le travail | ID de réponse/tâche, statut, âge de la file, motif d'annulation |
| Arrêt du repli | Empêcher les nouvelles tentatives de devenir un coût incontrôlé | Plafond strict de tentatives et de dépenses | Arrêter une fois le budget épuisé | Examen humain pour les changements de workflow à haut risque | tentatives, motif de repli, coût, propriétaire |
Ce tableau est le cœur de la stratégie de timeout pour les API d'IA. Les chiffres exacts doivent provenir du trafic réel, mais la séparation doit exister avant le premier incident en production.
Construire des budgets à partir de l'intention du workflow
Ne copiez pas une seule valeur de timeout pour toutes les fonctionnalités d'IA. Un timeout qui semble généreux pour une évaluation en arrière-plan peut être inacceptable dans un chat de support. Un timeout qui convient pour une réponse textuelle peut être trop court pour un workflow d'outil à contexte long. Rédigez la stratégie de timeout pour les API d'IA en fonction de l'intention du workflow :
- Le chat interactif nécessite un budget pour le premier événement, un budget de réponse total et un message utilisateur approprié lorsque le budget est épuisé.
- L'UX en streaming nécessite des budgets pour le premier événement et pour l'inactivité, car un flux connecté qui cesse de produire des événements est différent d'une réponse complète lente.
- L'extraction structurée nécessite un budget de nouvelle tentative pour la validité du schéma, et non une boucle de nouvelle tentative générique.
- Le travail agentique ou intensif en outils nécessite une échéance de file d'attente, un plafond d'appels d'outils, un chemin d'annulation et un enregistrement de polling.
- L'examen financier, d'approvisionnement ou de conformité nécessite un repli conservateur, car changer de modèle peut modifier le risque, le coût, les preuves ou le statut d'approbation.
Les directives actuelles d'OpenAI sur les timeouts pour les SDK officiels indiquent que les requêtes par défaut expirent après 10 minutes, et les SDK Python et JavaScript exposent tous deux une option timeout. Cette valeur par défaut est utile à connaître, mais elle ne doit pas devenir la politique de l'application. Les équipes de production ont toujours besoin de budgets de workflow plus stricts pour l'expérience utilisateur, les coûts et la réponse aux incidents.
Les budgets de connexion et de pool doivent échouer rapidement
Le budget de connexion répond à une question précise : le client peut-il atteindre la passerelle ou le point de terminaison du fournisseur assez rapidement pour démarrer la requête ? Il doit généralement être beaucoup plus court que le budget de lecture. Si la configuration de la connexion échoue, aucun modèle n'a rien généré, donc la décision de relancer est moins risquée qu'une nouvelle tentative après une réponse partielle.
Les équipes Python utilisant HTTPX peuvent exprimer cela clairement car HTTPX sépare les timeouts de connexion, de lecture, d'écriture et de pool. Le SDK Python d'OpenAI accepte également un objet httpx.Timeout, de sorte que l'application peut maintenir des budgets de connexion et de lecture distincts :
import os
import httpx
from openai import OpenAI
client = OpenAI(
api_key=os.environ["FLATKEY_API_KEY"],
base_url="https://router.flatkey.ai/v1",
timeout=httpx.Timeout(
timeout=20.0,
connect=2.0,
read=10.0,
write=10.0,
pool=1.0,
),
max_retries=1,
)L'important n'est pas les valeurs d'exemple. L'important est que la stratégie de timeout de l'API d'IA ne passe pas 20 secondes à découvrir qu'un socket ne peut pas être ouvert ou que le pool de connexions local est saturé.
Pour Node.js, le SDK JavaScript d'OpenAI expose une option timeout en millisecondes, et Node fournit également AbortSignal.timeout(delay) pour les API qui acceptent les signaux d'abandon. Utilisez ce modèle pour garder les délais d'application explicites au lieu de dépendre d'un appelant non borné.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.FLATKEY_API_KEY,
baseURL: "https://router.flatkey.ai/v1",
timeout: 20_000,
maxRetries: 1,
});Considérez les timeouts de connexion comme des signaux d'infrastructure. S'ils augmentent brusquement, inspectez le DNS, le TLS, l'accessibilité de la passerelle, les limites du pool, la saturation des workers locaux et la politique de sortie avant de changer de modèle.
Les budgets de lecture protègent les coûts et l'expérience utilisateur
Le budget de lecture est le temps maximum que l'application attendra pour la réponse après que la requête a été acceptée. C'est là que les charges de travail d'IA diffèrent des API JSON normales : le modèle peut être légitimement lent, la sortie peut être longue, ou le prompt peut déclencher l'utilisation d'outils. Un timeout de lecture doit donc être défini à partir de l'échéance du workflow, et non à partir d'une valeur par défaut de la bibliothèque.
Utilisez ces règles :
| Workflow | Règle de budget de lecture | Que faire en cas de timeout |
|---|---|---|
| Chat ou support | Budget basé sur la patience de l'utilisateur et le SLO du service | Afficher un état de timeout élégant, journaliser la requête, ne réessayer qu'avant une sortie visible par l'utilisateur |
| Extraction par lots | Budget basé sur l'échéance de la tâche et la capacité de la file d'attente | Réessayer une fois la même route, puis marquer l'enregistrement pour examen |
| Code ou raisonnement | Budget basé sur la complexité de la tâche et les limites des outils | Envisager le mode arrière-plan si la tâche est naturellement longue |
| Finance ou approvisionnement | Budget basé sur le SLA de révision | Arrêter et mettre en file d'attente plutôt que de changer de route silencieusement |
| Automatisation interne | Budget basé sur l'échéance de la dépendance en aval | Échouer assez tôt pour que l'appelant puisse compenser |
La stratégie de timeout de l'API d'IA doit également plafonner la taille de la sortie, les appels d'outils et les tentatives de repli. Un timeout de lecture seul ne contrôle pas les coûts si la couche de nouvelle tentative crée un travail en double.
Les budgets de streaming nécessitent deux horloges
Le streaming n'est pas résolu en augmentant le timeout de la requête. Une réponse d'IA en streaming a au moins deux horloges :
- Timeout du premier événement : combien de temps l'utilisateur attend avant le premier événement de flux ou jeton.
- Timeout d'inactivité : combien de temps l'application tolère le silence après le début du streaming.
Les références de l'API OpenAI décrivent le streaming comme des événements envoyés par le serveur (server-sent events) lorsque stream est activé. Pour les réponses en arrière-plan, OpenAI documente également le streaming avec des numéros de séquence afin qu'un client puisse suivre la position et se reconnecter lorsque cela est pris en charge. Cette distinction est importante : si l'API peut reprendre un flux à partir d'un curseur, la stratégie de timeout de l'API d'IA peut récupérer différemment que pour un flux simple sans contrat de reprise.
Ne changez pas de modèle après une sortie partielle visible par l'utilisateur, à moins que le produit ne soit conçu pour cela. Une réponse de repli qui commence au milieu d'une réponse précédente est généralement pire qu'un message d'échec clair. Pour le chat en streaming, journalisez :
| Champ | Pourquoi c'est important |
|---|---|
time_to_first_event_ms | Sépare la latence de démarrage du modèle du temps de complétion total |
last_event_at | Indique où le flux est devenu inactif |
sequence_number ou curseur | Permet une reprise sûre lorsque l'API le prend en charge |
partial_output_committed | Empêche une nouvelle tentative non sécurisée après une sortie visible |
requested_model et served_model | Indique si le routage ou le repli a modifié le comportement |
finish_reason ou événement terminal | Distingue le succès des flux abandonnés |
Associez cette page au guide Flatkey sur la fiabilité des API d'IA en streaming lorsque le principal mode de défaillance est la forme des SSE, les déconnexions du client ou la gestion des sorties partielles.
Les budgets de file d'attente doivent être en dehors de la requête utilisateur
Certaines tâches d'IA ne sont pas de bonnes requêtes synchrones. La recherche en plusieurs étapes, les longs workflows d'outils, l'examen de documents volumineux et la génération de médias complexes peuvent durer plus longtemps qu'une requête web ne devrait rester ouverte. La politique de timeout devrait déplacer ces charges de travail dans un mode de file d'attente ou d'arrière-plan au lieu de faire attendre l'utilisateur sur une seule connexion fragile.
La documentation du mode arrière-plan d'OpenAI décrit des réponses asynchrones qui peuvent être interrogées (polled) pendant qu'elles sont en queued ou in_progress, annulées si nécessaire, et diffusées en streaming depuis le mode arrière-plan lorsqu'elles sont créées de cette manière. C'est le bon modèle mental pour les longues tâches d'IA, même lorsque l'implémentation du fournisseur ou de la passerelle diffère : la requête de l'utilisateur crée une tâche durable, et l'application applique une échéance de file d'attente, une cadence d'interrogation, une règle d'annulation et une politique de conservation des résultats.
Un budget de file d'attente doit définir :
| Champ de la file d'attente | Question de politique |
|---|---|
| Âge maximum de la file d'attente | Combien de temps la tâche peut-elle attendre avant de devenir obsolète ? |
| Intervalle d'interrogation | À quelle fréquence l'application doit-elle vérifier l'état sans créer de charge excessive ? |
| Règle d'annulation | Qui peut annuler, et qu'advient-il du travail partiel ? |
| Protection contre les doublons | Comment empêcher une nouvelle tentative de créer deux fois la même tâche coûteuse ? |
| Notification de l'utilisateur | L'utilisateur voit-il l'état en attente, échoué, annulé ou terminé ? |
| Propriétaire du coût | Quelle clé, équipe, client ou workflow est propriétaire de la dépense ? |
C'est là qu'une stratégie de timeout pour les API d'IA devient une politique opérationnelle, et pas seulement un paramètre du SDK.
Budget de nouvelle tentative avant budget de repli
La nouvelle tentative (retry) et le repli (fallback) sont des actions différentes. Une nouvelle tentative répète le même contrat. Un repli modifie l'itinéraire, le modèle, le fournisseur, la capacité, le coût ou la surface de preuve.
Les fichiers README des SDK Python et JavaScript d'OpenAI indiquent que les erreurs de connexion, les timeouts de requête 408, les conflits 409, les limites de taux 429 et les erreurs de serveur font l'objet de deux nouvelles tentatives par défaut avec un backoff exponentiel court. C'est un comportement utile du SDK, mais il peut surprendre les équipes qui ajoutent leurs propres nouvelles tentatives de passerelle, de file d'attente et de tâche par-dessus. Comptez chaque couche.
Utilisez un budget de nouvelle tentative comme celui-ci :
workflow: support_chat_answer
timeouts:
connect_ms: 2000
first_event_ms: 5000
stream_idle_ms: 20000
total_ms: 30000
retry:
sdk_max_retries: 1
gateway_max_retries: 1
retry_only_before_partial_output: true
fallback:
allowed_before_first_event:
- reviewed_support_backup_route
blocked_after_partial_output: true
stop_when:
- schema_contract_changes
- tool_support_missing
- cost_cap_exceeded
- data_boundary_changes
evidence:
required:
- workflow
- owner_key
- requested_model
- served_model
- timeout_layer
- retry_attempt
- fallback_reason
- usage_unitsPour une évaluation plus approfondie du repli, utilisez le guide Flatkey sur l'évaluation du repli de modèle. Pour un comportement spécifique aux nouvelles tentatives, utilisez le guide Flatkey sur la stratégie de nouvelle tentative pour les API d'IA.
Les champs d'observabilité déterminent si le timeout est débogable
Un timeout sans preuve n'est qu'une plainte. La stratégie de timeout pour les API d'IA doit exiger suffisamment de champs pour répondre à ce qui a échoué, qui en était propriétaire, si le modèle a généré quelque chose et combien la tentative a coûté.
| Champ de preuve | Pourquoi il a sa place dans la politique de timeout |
|---|---|
| Nom du workflow | Lie le timeout à une surface de produit |
| Clé du propriétaire, équipe, client ou environnement | Attribue la propriété des dépenses et des incidents |
| Couche de timeout | Sépare les arrêts de connexion, de pool, de lecture, d'inactivité du flux, de file d'attente et de repli |
| Modèle demandé et modèle servi | Expose les changements d'itinéraire et le repli |
| Famille de points de terminaison | Sépare le chat, les réponses, Anthropic, Gemini, l'image, la vidéo et d'autres formes |
| ID de la requête ou ID de la réponse/tâche | Permet la corrélation entre le fournisseur, la passerelle et l'application |
| Nombre de nouvelles tentatives et raison du repli | Empêche l'amplification cachée des nouvelles tentatives |
| Unités d'utilisation et signal de coût | Aide le service financier à examiner le travail en double ou abandonné |
| Indicateur de sortie partielle | Protège les utilisateurs contre les réponses dupliquées en streaming |
Le site public actuel de Flatkey positionne le produit autour de l'accès unifié aux modèles, du routage, de la facturation, de l'analyse de l'utilisation et des contrôles opérationnels. La page de tarification actuelle est le parcours d'examen pour les options d'accès aux modèles, de routage et de facturation, et l'instantané de l'API de tarification du 3 juillet 2026 a exposé des familles de points de terminaison incluant openai, anthropic, gemini, image-generation, openai-video, et video. Considérez-les comme des preuves datées, et non comme des affirmations de disponibilité permanente. Validez toujours le catalogue actuel et effectuez un petit test d'itinéraire avant le déploiement en production.
Un plan de déploiement pratique
Utilisez cette séquence de déploiement lors de l'ajout ou de la révision d'une stratégie de timeout pour les API d'IA :
- Choisissez un workflow et nommez le propriétaire.
- Choisissez les budgets de connexion, de pool, de lecture, de premier événement de flux, d'inactivité de flux, de file d'attente, de nouvelle tentative et de repli.
- Désactivez les couches de nouvelle tentative en double ou réduisez-les pour que le nombre total de tentatives soit clair.
- Ajoutez la journalisation de la couche de timeout avant de modifier le comportement de l'itinéraire.
- Exécutez des cas de test normaux, lents, à débit limité, en streaming et à défaillance contrôlée.
- Confirmez que les nouvelles tentatives s'arrêtent avant que la sortie partielle ne soit dupliquée.
- Confirmez que le repli préserve les outils, le schéma, la limite des données et les attentes en matière de coûts requis.
- Examinez les journaux de requêtes, les unités d'utilisation et les preuves de coût dans Flatkey.
- Ne mettez en production que le workflow testé.
- Répétez pour le workflow suivant au lieu de déclarer une politique de timeout globale unique.
La meilleure stratégie de timeout pour les API d'IA est suffisamment petite pour être testée et suffisamment stricte pour s'arrêter. Elle devrait rendre un timeout ennuyeux : une couche a échoué, le budget de nouvelle tentative était clair, le repli est resté dans le contrat approuvé ou s'est arrêté, et les journaux montrent ce qui s'est passé.
FAQ
Qu'est-ce qu'une stratégie de timeout pour les API d'IA ?
Une stratégie de timeout pour les API d'IA est une politique au niveau du workflow qui définit des budgets distincts pour l'établissement de la connexion, le temps de requête/lecture, le premier événement de streaming, les interruptions d'inactivité du streaming, les files d'attente en arrière-plan, les nouvelles tentatives, le repli et l'observabilité.
Pourquoi ne pas utiliser le timeout par défaut du SDK ?
Les valeurs par défaut des SDK sont des garde-fous généraux. Les applications de production nécessitent des budgets plus stricts basés sur l'expérience utilisateur, le coût, le comportement des nouvelles tentatives et le risque du workflow. Les SDK officiels d'OpenAI exposent les paramètres de timeout, afin que les équipes puissent définir des limites spécifiques à chaque workflow.
Chaque timeout doit-il déclencher un mécanisme de repli ?
Non. Un timeout de connexion peut être relancé ou contourné en toute sécurité. Un timeout d'inactivité du flux après une sortie partielle visible par l'utilisateur devrait généralement s'arrêter proprement. Un workflow financier ou de conformité peut nécessiter une mise en file d'attente ou une révision humaine au lieu d'un repli automatique.
Combien de nouvelles tentatives une requête d'IA devrait-elle avoir ?
Comptez toutes les couches de nouvelles tentatives ensemble : SDK, passerelle, worker, file d'attente et application. Gardez le total faible, consignez chaque tentative et arrêtez avant que les nouvelles tentatives ne créent des coûts en double ou une sortie incohérente visible par l'utilisateur.
Que devraient mesurer les équipes en premier ?
Commencez par le taux de timeouts par couche, le temps jusqu'au premier événement, les échecs d'inactivité du flux, l'amplification des nouvelles tentatives, le taux de repli, le coût par résultat accepté et l'âge de la file d'attente non résolue. Ces métriques montrent si la politique de timeout protège le workflow ou masque l'incident.
Comment Flatkey aide-t-il avec les opérations de timeout ?
Flatkey offre aux équipes une surface de passerelle unique pour l'accès aux modèles connectés, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. Utilisez-la pour examiner le modèle actuel et le chemin du point de terminaison, observer les preuves des requêtes et maintenir les décisions de timeout, de nouvelle tentative, de repli et de coût liées à une seule clé propriétaire.
Commencez par les tarifs de Flatkey, choisissez un workflow, puis obtenez une clé et testez le budget de timeout avant d'y acheminer le trafic de production.