Los timeouts no son un solo número. Una estrategia de timeouts para una API de IA en producción necesita límites separados para conectar, leer la respuesta, transmitir eventos de tokens, esperar en una cola, reintentar de forma segura y decidir cuándo debe detenerse el fallback. Si esos límites se mezclan, un proveedor lento, un pool de conexiones bloqueado o una transmisión semiabierta pueden parecer el mismo incidente.
El objetivo de una estrategia de timeouts para una API de IA es hacer que los fallos sean limitados y observables. Una solicitud de chat de cara al usuario puede necesitar un primer token rápido y una detención total. Una tarea de investigación en segundo plano puede necesitar una fecha límite de cola y sondeo (polling). Un trabajo de extracción de esquemas puede necesitar un reintento en la misma ruta antes de recurrir al fallback. Cada flujo de trabajo necesita su propio límite, y cada timeout debe dejar evidencia para los responsables de ingeniería, finanzas y producto.
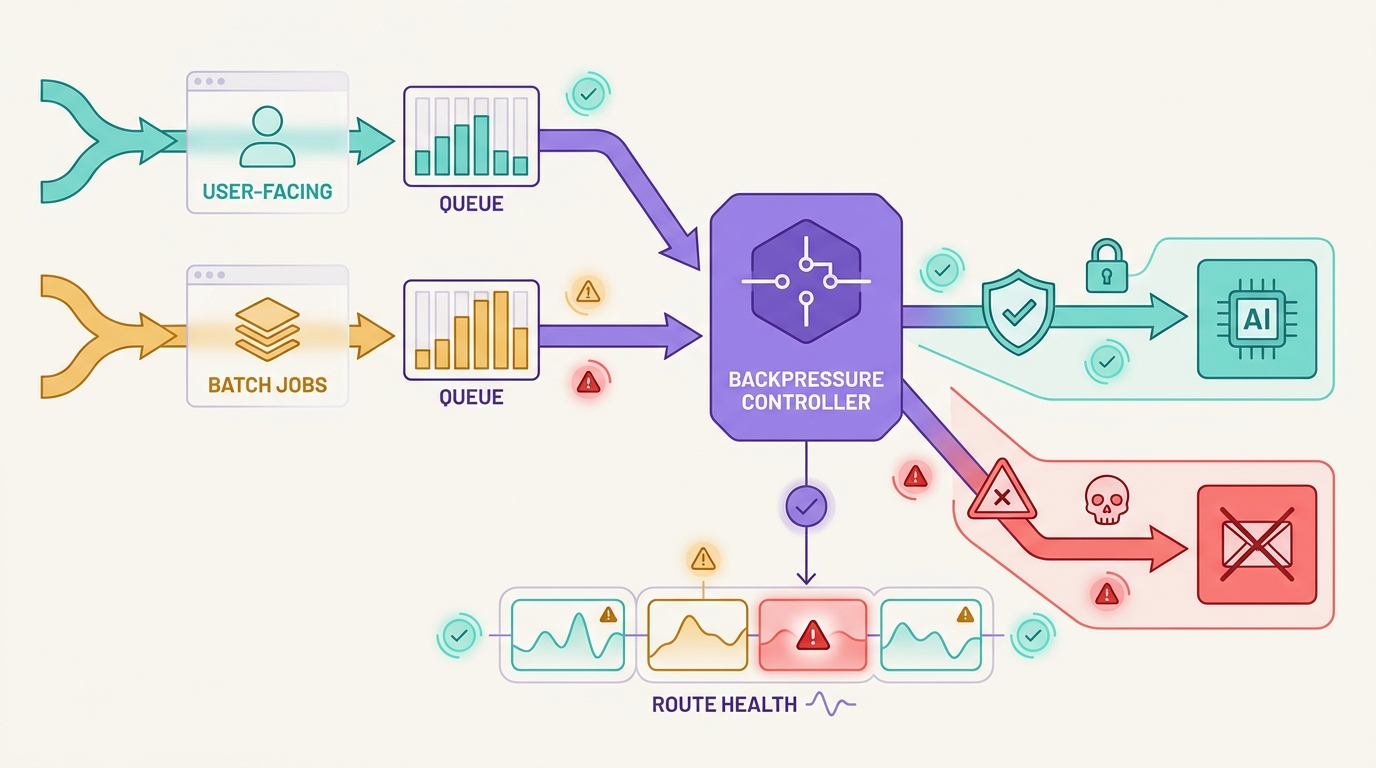
Flatkey se ajusta a este trabajo de fiabilidad porque la política de timeouts es más fácil de revisar cuando el acceso al modelo, el enrutamiento, la facturación, el análisis de uso y los controles operativos se gestionan a través de un único gateway. Utilice la siguiente lista de verificación como política de la aplicación, y luego valide la fila del modelo de Flatkey actual, la familia de endpoints, la evidencia de uso y el comportamiento de la ruta antes de enviar tráfico de producción.
Estrategia de timeouts para API de IA en una tabla
Comience por asignar un responsable y una condición de detención a cada capa de timeout.
| Capa de timeout | Qué protege | Límite inicial | Regla de reintento | Regla de fallback | Evidencia a registrar |
|---|---|---|---|---|---|
| Conexión | DNS, TLS, accesibilidad del gateway y configuración del socket | Corto, generalmente inferior al límite de la solicitud | Reintentar solo si no se aceptó el cuerpo de la solicitud | Usar ruta de respaldo solo cuando la familia de endpoints es equivalente | connect_ms, ruta, host, clase de error |
| Adquisición de pool o cola | Espera de un worker local, conexión o espacio en el límite de velocidad | Muy corto para trabajo interactivo | No reintentar a ciegas; reducir primero la concurrencia | Encolar o descargar trabajo antes de cambiar de modelo | antigüedad en cola, espera de pool, concurrencia, responsable |
| Solicitud/lectura | Espera del cuerpo de la respuesta después de enviar la solicitud | Vinculado a la UX o a la fecha límite del trabajo | Uno o dos reintentos limitados para fallos transitorios | Fallback solo a una ruta que preserve el contrato de salida | ID de solicitud, estado, timeout de lectura, uso si está presente |
| Primer evento de la transmisión | Espera del primer evento SSE o de token | Inferior a la fecha límite total de la transmisión | Reintentar antes de que comience la salida visible para el usuario | Fallback solo antes de que se confirme la salida parcial | latencia del primer evento, modelo solicitado, modelo servido |
| Inactividad de la transmisión | Intervalo entre fragmentos de la transmisión después de que comience la salida | Basado en los intervalos normales entre eventos | Reanudar solo cuando la API lo admita; de lo contrario, detenerse limpiamente | Evitar cambiar de modelo a mitad de la respuesta | última secuencia, intervalo de inactividad, marcador de salida parcial |
| Cola en segundo plano | Trabajo de larga duración fuera de la solicitud del usuario | Fecha límite explícita e intervalo de sondeo | Sondear hasta el estado terminal o la fecha límite | Escalar o cancelar antes de duplicar el trabajo | ID de respuesta/trabajo, estado, antigüedad en cola, motivo de cancelación |
| Detención del fallback | Evitar que los reintentos se conviertan en un coste descontrolado | Límite estricto de intentos y de gasto | Detenerse después de agotar el límite | Revisión humana para cambios de flujo de trabajo de alto riesgo | intentos, motivo del fallback, coste, responsable |
Esta tabla es el núcleo de la estrategia de timeouts para la API de IA. Las cifras exactas deben provenir del tráfico real, pero la separación debe existir antes del primer incidente en producción.
Construir límites a partir de la intención del flujo de trabajo
No copie un único valor de timeout para todas las funciones de IA. Un timeout que parece generoso para una evaluación en segundo plano puede ser inaceptable en un chat de soporte. Un timeout que está bien para una respuesta de texto puede ser demasiado corto para un flujo de trabajo de herramientas de contexto largo. Escriba la estrategia de timeouts para la API de IA en torno a la intención del flujo de trabajo:
- El chat interactivo necesita un límite para el primer evento, un límite de respuesta total y un mensaje amable para el usuario cuando se agota el límite.
- La UX de transmisión (streaming) necesita límites para el primer evento y para la inactividad, porque una transmisión conectada que deja de producir eventos es diferente de una respuesta completa lenta.
- La extracción estructurada necesita un límite de reintentos para la validez del esquema, no un bucle de reintentos genérico.
- El trabajo agéntico o con muchas herramientas necesita una fecha límite de cola, un límite de llamadas a herramientas, una ruta de cancelación y un registro de sondeo.
- La revisión de finanzas, adquisiciones o cumplimiento necesita un fallback conservador porque cambiar el modelo puede cambiar el riesgo, el coste, la evidencia o el estado de aprobación.
La guía actual de timeouts de OpenAI para los SDK oficiales dice que las solicitudes por defecto expiran después de 10 minutos, y tanto el SDK de Python como el de JavaScript exponen una opción de timeout. Es útil conocer ese valor por defecto, pero no debería convertirse en la política de la aplicación. Los equipos de producción siguen necesitando límites de flujo de trabajo más estrictos para la experiencia del usuario, el coste y la respuesta a incidentes.
Los límites de conexión y de pool deben fallar rápidamente
El límite de conexión responde a una pregunta específica: ¿puede el cliente alcanzar el endpoint del gateway o del proveedor lo suficientemente rápido como para iniciar la solicitud? Normalmente debería ser mucho más corto que el límite de lectura. Si la configuración de la conexión falla, ningún modelo ha generado nada, por lo que la decisión de reintentar tiene menos riesgo que reintentar después de una respuesta parcial.
Los equipos de Python que usan HTTPX pueden expresar esto de forma clara porque HTTPX separa los timeouts de conexión, lectura, escritura y pool. El SDK de Python de OpenAI también acepta un objeto httpx.Timeout, por lo que la aplicación puede mantener separados los límites de conexión y lectura:
import os
import httpx
from openai import OpenAI
client = OpenAI(
api_key=os.environ["FLATKEY_API_KEY"],
base_url="https://router.flatkey.ai/v1",
timeout=httpx.Timeout(
timeout=20.0,
connect=2.0,
read=10.0,
write=10.0,
pool=1.0,
),
max_retries=1,
)La parte importante no son los valores de ejemplo. La parte importante es que la estrategia de timeouts para la API de IA no dedique 20 segundos a descubrir que no se puede abrir un socket o que el pool de conexiones local está saturado.
Para Node.js, el SDK de JavaScript de OpenAI expone una opción timeout en milisegundos, y Node también proporciona AbortSignal.timeout(delay) para las API que aceptan señales de anulación. Utilice ese patrón para mantener los plazos de la aplicación explícitos en lugar de depender de un llamador sin límites.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.FLATKEY_API_KEY,
baseURL: "https://router.flatkey.ai/v1",
timeout: 20_000,
maxRetries: 1,
});Trate los timeouts de conexión como señales de la infraestructura. Si aumentan bruscamente, inspeccione el DNS, TLS, la accesibilidad de la puerta de enlace, los límites del pool, la saturación de los workers locales y la política de egreso antes de cambiar el modelo.
Los límites de lectura protegen el costo y la experiencia del usuario
El límite de lectura es el tiempo máximo que la aplicación esperará la respuesta después de que se acepte la solicitud. Aquí es donde las cargas de trabajo de IA difieren de las API JSON normales: el modelo puede ser válidamente lento, la salida puede ser larga o el prompt puede desencadenar el trabajo de una herramienta. Por lo tanto, un timeout de lectura debe establecerse a partir del plazo del flujo de trabajo, no a partir de un valor predeterminado de la biblioteca.
Utilice estas reglas:
| Flujo de trabajo | Regla del límite de lectura | Qué hacer en caso de timeout |
|---|---|---|
| Chat o soporte | Límite basado en la paciencia del usuario y el SLO del servicio | Mostrar un estado de timeout elegante, registrar la solicitud, reintentar solo antes de la salida visible para el usuario |
| Extracción por lotes | Límite basado en el plazo del trabajo y la capacidad de la cola | Reintentar la misma ruta una vez, luego marcar el registro para su revisión |
| Código o razonamiento | Límite basado en la complejidad de la tarea y los topes de las herramientas | Considere el modo en segundo plano si la tarea es naturalmente larga |
| Finanzas o adquisiciones | Límite basado en el SLA de revisión | Detener y encolar en lugar de cambiar de ruta silenciosamente |
| Automatización interna | Límite basado en el plazo de la dependencia descendente | Fallar lo suficientemente pronto para que el llamador pueda compensar |
La estrategia de timeouts para la API de IA también debe limitar el tamaño de la salida, las llamadas a herramientas y los intentos de fallback. Un timeout de lectura por sí solo no controla el costo si la capa de reintentos crea trabajo duplicado.
Los límites para la transmisión necesitan dos relojes
La transmisión no se soluciona aumentando el timeout de la solicitud. Una respuesta de IA transmitida tiene al menos dos relojes:
- Timeout del primer evento: cuánto tiempo espera el usuario antes del primer evento de transmisión o token.
- Timeout de inactividad: cuánto tiempo tolera la aplicación el silencio después de que ha comenzado la transmisión.
Las referencias de la API de OpenAI describen la transmisión como eventos enviados por el servidor (server-sent events) cuando stream está habilitado. Para las respuestas en segundo plano, OpenAI también documenta la transmisión con números de secuencia para que un cliente pueda rastrear la posición y reconectarse cuando sea compatible. Esa distinción es importante: si la API puede reanudar una transmisión desde un cursor, la estrategia de timeouts para la API de IA puede recuperarse de manera diferente a como lo haría para una transmisión simple sin contrato de reanudación.
No cambie de modelo después de una salida parcial visible para el usuario a menos que el producto esté diseñado para ello. Una respuesta de fallback que comienza a la mitad de una respuesta anterior suele ser peor que un mensaje de error limpio. Para el chat transmitido, registre:
| Campo | Por qué es importante |
|---|---|
time_to_first_event_ms | Separa la latencia de inicio del modelo del tiempo total de finalización |
last_event_at | Muestra dónde la transmisión quedó inactiva |
sequence_number o cursor | Permite una reanudación segura cuando la API lo admite |
partial_output_committed | Evita un reintento inseguro después de una salida visible |
requested_model y served_model | Muestra si el enrutamiento o el fallback cambiaron el comportamiento |
finish_reason o evento terminal | Distingue el éxito de las transmisiones abandonadas |
Combine esta página con la guía de Flatkey sobre la fiabilidad de la transmisión de API de IA cuando el principal modo de fallo sea la forma de los SSE, las desconexiones del cliente o el manejo de salidas parciales.
Los límites de encolamiento pertenecen fuera de la solicitud del usuario
Algunas tareas de IA no son buenas solicitudes síncronas. La investigación de varios pasos, los flujos de trabajo de herramientas largos, la revisión de documentos grandes y la generación de medios complejos pueden durar más de lo que una solicitud web debería permanecer abierta. La política de timeouts debería mover estas cargas de trabajo a un modo encolado o en segundo plano en lugar de hacer que el usuario espere en una única conexión frágil.
La documentación del modo en segundo plano de OpenAI describe respuestas asíncronas que pueden ser consultadas mientras están queued o in_progress, canceladas cuando sea necesario y transmitidas desde el modo en segundo plano si se crearon de esa manera. Ese es el modelo mental correcto para el trabajo de IA largo, incluso cuando la implementación del proveedor o de la puerta de enlace difiere: la solicitud del usuario crea un trabajo duradero, y la aplicación aplica un plazo de cola, una cadencia de sondeo, una regla de cancelación y una política de retención de resultados.
Un límite de encolamiento debería definir:
| Campo de la cola | Pregunta de la política |
|---|---|
| Antigüedad máxima de la cola | ¿Cuánto tiempo puede esperar el trabajo antes de que se considere obsoleto? |
| Intervalo de sondeo | ¿Con qué frecuencia debe la aplicación comprobar el estado sin crear una carga excesiva? |
| Regla de cancelación | ¿Quién puede cancelar y qué sucede con el trabajo parcial? |
| Protección contra duplicados | ¿Cómo se evita que un reintento cree el mismo trabajo costoso dos veces? |
| Notificación al usuario | ¿El usuario ve los estados pendiente, fallido, cancelado o completado? |
| Propietario del costo | ¿Qué clave, equipo, cliente o flujo de trabajo es el propietario del gasto? |
Aquí es donde una estrategia de timeouts para API de IA se convierte en una política de operaciones, no solo en una configuración del SDK.
Límite de reintentos antes del límite de fallback
El reintento y el fallback son acciones diferentes. Un reintento repite el mismo contrato. Un fallback cambia la ruta, el modelo, el proveedor, la capacidad, el costo o la superficie de evidencia.
Los archivos README de los SDK de Python y JavaScript de OpenAI indican que los errores de conexión, los timeouts de solicitud 408, los conflictos 409, los límites de tasa 429 y los errores del servidor se reintentan dos veces por defecto con un breve backoff exponencial. Este es un comportamiento útil del SDK, pero puede sorprender a los equipos que añaden sus propios reintentos de puerta de enlace, de cola y de trabajo por encima. Cuente cada capa.
Use un límite de reintentos como este:
workflow: support_chat_answer
timeouts:
connect_ms: 2000
first_event_ms: 5000
stream_idle_ms: 20000
total_ms: 30000
retry:
sdk_max_retries: 1
gateway_max_retries: 1
retry_only_before_partial_output: true
fallback:
allowed_before_first_event:
- reviewed_support_backup_route
blocked_after_partial_output: true
stop_when:
- schema_contract_changes
- tool_support_missing
- cost_cap_exceeded
- data_boundary_changes
evidence:
required:
- workflow
- owner_key
- requested_model
- served_model
- timeout_layer
- retry_attempt
- fallback_reason
- usage_unitsPara una ruta de evaluación de fallback más profunda, use la guía de Flatkey sobre la evaluación de fallback de modelos. Para un comportamiento específico de reintentos, use la guía de Flatkey sobre la estrategia de reintentos para API de IA.
Los campos de observabilidad deciden si el timeout es depurable
Un timeout sin evidencia es solo una queja. La estrategia de timeouts para API de IA debe requerir suficientes campos para responder qué falló, quién era el propietario, si el modelo generó algo y cuánto costó el intento.
| Campo de evidencia | Por qué pertenece a la política de timeouts |
|---|---|
| Nombre del flujo de trabajo | Vincula el timeout a una superficie del producto |
| Clave del propietario, equipo, cliente o entorno | Asigna la propiedad del gasto y del incidente |
| Capa del timeout | Separa las paradas de conexión, pool, lectura, inactividad de transmisión, cola y fallback |
| Modelo solicitado y modelo servido | Expone los cambios de ruta y el fallback |
| Familia de endpoints | Separa chat, respuestas, Anthropic, Gemini, imagen, video y otras formas |
| ID de solicitud o ID de respuesta/trabajo | Permite la correlación entre el proveedor, la puerta de enlace y la aplicación |
| Recuento de reintentos y motivo del fallback | Evita la amplificación oculta de reintentos |
| Unidades de uso y señal de costo | Ayuda al departamento financiero a revisar el trabajo duplicado o abandonado |
| Indicador de salida parcial | Protege a los usuarios de respuestas duplicadas transmitidas por streaming |
El sitio público actual de Flatkey posiciona el producto en torno al acceso unificado a modelos, enrutamiento, facturación, análisis de uso y controles operativos. La página de precios actual es la ruta de revisión para las opciones de acceso a modelos, enrutamiento y facturación, y la instantánea de la API de precios del 3 de julio de 2026 expuso familias de endpoints que incluyen openai, anthropic, gemini, image-generation, openai-video y video. Trate esos puntos como pruebas fechadas, no como afirmaciones de disponibilidad permanente. Valide siempre el catálogo actual y realice una pequeña prueba de ruta antes del despliegue en producción.
Un plan de despliegue práctico
Use esta secuencia de despliegue al añadir o revisar una estrategia de timeouts para API de IA:
- Elija un flujo de trabajo y nombre al propietario.
- Elija los límites para conectar, pool, leer, primer evento de transmisión, inactividad de transmisión, cola, reintento y fallback.
- Desactive las capas de reintento duplicadas o redúzcalas para que el recuento total de intentos sea claro.
- Añada el registro de la capa de timeout antes de cambiar el comportamiento de la ruta.
- Ejecute casos de prueba normales, lentos, con límite de tasa, transmitidos y con fallos controlados.
- Confirme que los reintentos se detienen antes de que se duplique la salida parcial.
- Confirme que el fallback preserva las herramientas, el esquema, los límites de datos y las expectativas de costo requeridos.
- Revise los registros de solicitudes, las unidades de uso y la evidencia de costos en Flatkey.
- Mueva solo el flujo de trabajo probado a producción.
- Repita para el siguiente flujo de trabajo en lugar de declarar una política de timeouts global.
La mejor estrategia de timeouts para API de IA es lo suficientemente pequeña como para probarla y lo suficientemente estricta como para detenerse. Debería hacer que un timeout sea aburrido: una capa falló, el límite de reintentos estaba claro, el fallback se mantuvo dentro del contrato aprobado o se detuvo, y los registros muestran lo que sucedió.
Preguntas frecuentes
¿Qué es una estrategia de timeouts para API de IA?
Una estrategia de timeouts para API de IA es una política a nivel de flujo de trabajo que establece límites separados para la configuración de la conexión, el tiempo de solicitud/lectura, el primer evento de transmisión, las pausas de inactividad en la transmisión, las colas en segundo plano, los reintentos, el fallback y la observabilidad.
¿Por qué no usar el timeout por defecto del SDK?
Los valores predeterminados de los SDK son medidas de seguridad amplias. Las aplicaciones de producción necesitan límites más estrictos basados en la experiencia del usuario, el costo, el comportamiento de reintento y el riesgo del flujo de trabajo. Los SDK oficiales de OpenAI exponen la configuración de timeouts, por lo que los equipos pueden establecer límites específicos para cada flujo de trabajo.
¿Debería cada timeout activar un fallback?
No. Un timeout de conexión puede ser seguro para reintentar o redirigir. Un timeout de inactividad de la transmisión después de una salida parcial visible para el usuario generalmente debería detenerse limpiamente. Un flujo de trabajo de finanzas o cumplimiento normativo puede requerir encolamiento o revisión humana en lugar de un fallback automático.
¿Cuántos reintentos debería tener una solicitud de IA?
Cuente todas las capas de reintento juntas: SDK, gateway, worker, cola y aplicación. Mantenga el total bajo, registre cada intento y deténgase antes de que los reintentos creen costos duplicados o una salida inconsistente visible para el usuario.
¿Qué deberían medir los equipos primero?
Comience con la tasa de timeouts por capa, el tiempo hasta el primer evento, las fallas de inactividad de la transmisión, la amplificación de reintentos, la tasa de fallback, el costo por resultado aceptado y la antigüedad de la cola sin resolver. Esas métricas muestran si la política de timeouts está protegiendo el flujo de trabajo u ocultando el incidente.
¿Cómo ayuda Flatkey con las operaciones de timeout?
Flatkey ofrece a los equipos una única superficie de gateway para el acceso a modelos conectados, enrutamiento, facturación, análisis de uso y controles operativos. Úselo para revisar el modelo actual y la ruta del endpoint, observar la evidencia de la solicitud y mantener las decisiones de timeout, reintento, fallback y costo vinculadas a una única clave de propietario.
Comience con los precios de Flatkey, elija un flujo de trabajo, luego obtenga una clave y pruebe el límite de timeout antes de enrutar el tráfico de producción a través de él.