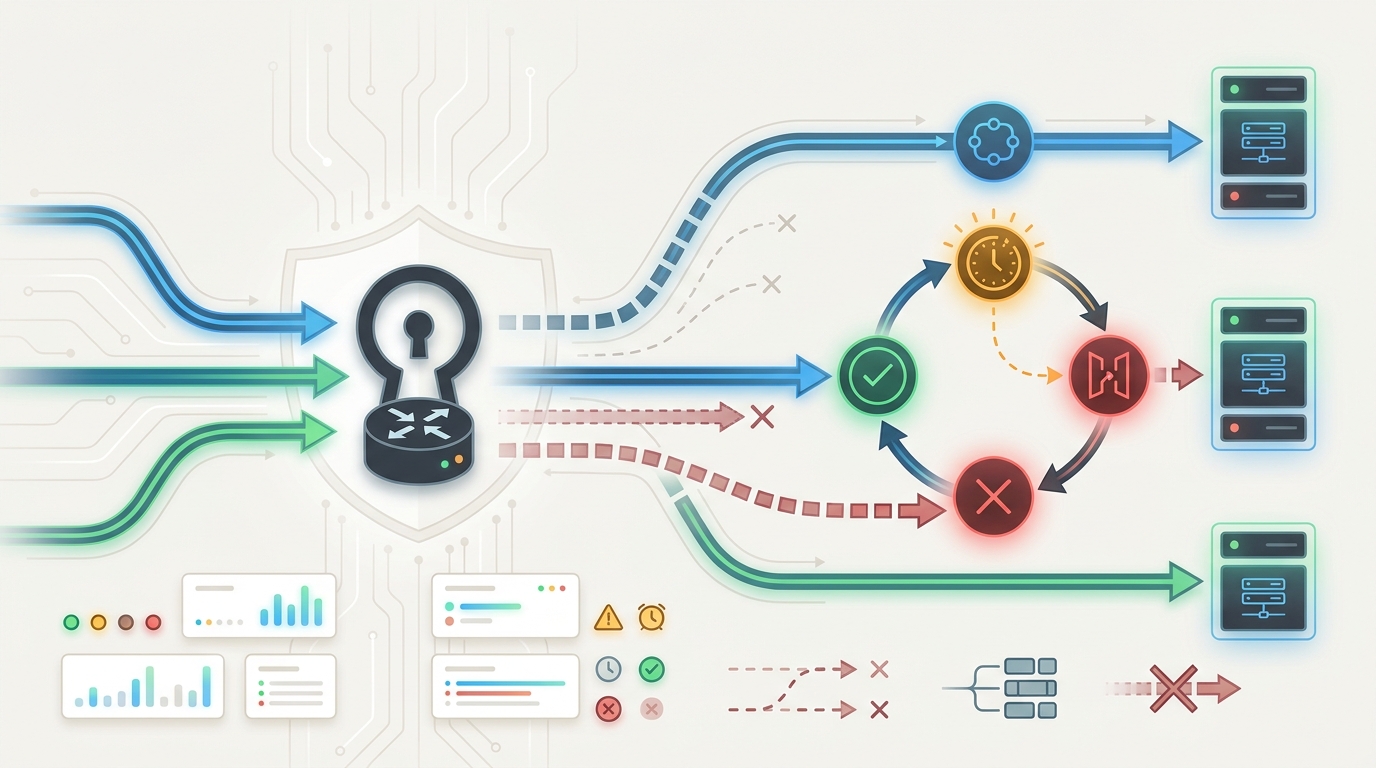
タイムアウトは単一の数値ではありません。本番環境のAI APIタイムアウト戦略には、接続、レスポンスの読み取り、トークンイベントのストリーミング、キューでの待機、安全なリトライ、そしてフォールバックをいつ停止すべきかを決定するための、それぞれ個別のバジェットが必要です。これらのバジェットが混在していると、遅いプロバイダー、ブロックされた接続プール、または半開きのストリームが、同じインシデントのように見えてしまう可能性があります。
AI APIタイムアウト戦略の目標は、障害を限定的かつ観測可能にすることです。ユーザー向けのチャットリクエストには、高速な初回トークンと厳格な停止が必要になる場合があります。バックグラウンドの調査タスクには、キューのデッドラインとポーリングが必要になる場合があります。スキーマ抽出ジョブでは、フォールバックする前に同じルートで1回のリトライが必要になる場合があります。各ワークフローには独自のバジェットが必要であり、すべてのタイムアウトはエンジニアリング、財務、プロダクトオーナーのために証拠を残さなければなりません。
Flatkeyは、モデルアクセス、ルーティング、請求、使用状況分析、および運用管理が単一のゲートウェイを介して処理されるため、タイムアウトポリシーのレビューが容易になり、この信頼性向上作業に適しています。以下のチェックリストをアプリケーションポリシーとして使用し、本番トラフィックを送信する前に、現在のFlatkeyのモデル行、エンドポイントファミリー、使用証拠、およびルートの動作を検証してください。
AI APIタイムアウト戦略のまとめ表
まず、各タイムアウトレイヤーに1人の所有者と1つの停止条件を割り当てます。
| タイムアウトレイヤー | 保護対象 | 開始バジェット | リトライ ルール | フォールバック ルール | ログに記録する証拠 |
|---|---|---|---|---|---|
| 接続 | DNS、TLS、ゲートウェイの到達可能性、ソケット設定 | 短時間、通常はリクエストバジェットより低い | リクエストボディが受け入れられなかった場合にのみリトライ | エンドポイントファミリーが同等な場合にのみバックアップルートを使用 | connect_ms、ルート、ホスト、エラークラス |
| プールまたはキューの取得 | ローカルワーカー、接続、またはレート制限スロットの待機 | インタラクティブな作業では非常に短い | むやみにリトライしない。まず同時実行数を減らす | モデルを変更する前にキューに入れるか、負荷を軽減する | queue age、pool wait、concurrency、owner |
| リクエスト/読み取り | リクエスト送信後のレスポンスボディの待機 | UXまたはジョブのデッドラインに関連 | 一時的な障害に対して1〜2回の限定的なリトライ | 出力コントラクトを維持するルートにのみフォールバック | request ID、status、read timeout、usage if present |
| ストリームの初回イベント | 最初のSSEまたはトークンイベントの待機 | 合計ストリームデッドラインより低い | ユーザーに見える出力が開始される前にリトライ | 部分的な出力がコミットされる前にのみフォールバック | first-event latency、requested model、served model |
| ストリームのアイドル | 出力開始後のストリームチャンク間のギャップ | 通常のイベント間ギャップに基づく | APIがサポートしている場合にのみ再開。それ以外はクリーンに停止 | 回答の途中でモデルを切り替えるのを避ける | last sequence、idle gap、partial output marker |
| バックグラウンドキュー | ユーザーリクエスト外の長時間実行される作業 | 明示的なデッドラインとポーリング間隔 | 終端状態またはデッドラインまでポーリング | 重複作業の前にエスカレーションまたはキャンセル | response/job ID、status、queue age、cancel reason |
| フォールバックの停止 | リトライが暴走コストになるのを防ぐ | 厳格な試行回数と支出の上限 | バジェットを使い切ったら停止 | 高リスクのワークフロー変更に対する人間によるレビュー | attempts、fallback reason、cost、owner |
この表は、AI APIタイムアウト戦略の中核です。正確な数値は実際のトラフィックから導き出すべきですが、この分離は最初の本番インシデントが発生する前に存在しているべきです。
ワークフローの意図からバジェットを構築する
すべてのAI機能で1つのタイムアウト値をコピーしないでください。バックグラウンド評価では十分に感じられるタイムアウトも、サポートチャットでは許容できない場合があります。テキスト回答には問題ないタイムアウトも、長いコンテキストを持つツールワークフローには短すぎる可能性があります。AI APIタイムアウト戦略は、ワークフローの意図に基づいて作成します。
- インタラクティブチャットには、初回イベントバジェット、合計レスポンスバジェット、そしてバジェットを使い切った場合にユーザーに表示する丁寧なメッセージが必要です。
- ストリーミングUXには、初回イベントバジェットとアイドルバジェットが必要です。なぜなら、接続されているストリームがイベントの生成を停止するのは、遅い完全なレスポンスとは異なるからです。
- 構造化抽出には、一般的なリトライ ループではなく、スキーマの有効性に関するリトライバジェットが必要です。
- エージェント的またはツールを多用する作業には、キューのデッドライン、ツールコールのキャップ、キャンセルパス、およびポーリング記録が必要です。
- 財務、調達、またはコンプライアンスレビューには、保守的なフォールバックが必要です。なぜなら、モデルを変更するとリスク、コスト、証拠、または承認ステータスが変わる可能性があるからです。
公式SDKに対するOpenAIの現在のタイムアウトガイダンスによると、デフォルトのリクエストは10分後にタイムアウトし、PythonとJavaScriptの両SDKはtimeoutオプションを公開しています。そのデフォルト値を知っておくことは有用ですが、それがアプリケーションポリシーになるべきではありません。本番チームは、ユーザーエクスペリエンス、コスト、およびインシデント対応のために、より厳格なワークフローバジェットを依然として必要としています。
接続およびプールバジェットは迅速に失敗させるべき
接続バジェットは、「クライアントはリクエストを開始するのに十分な速さでゲートウェイまたはプロバイダーのエンドポイントに到達できるか?」という限定的な問いに答えます。通常、これは読み取りバジェットよりもはるかに短くすべきです。接続設定が失敗した場合、モデルは何も生成していないため、リトライの決定は、部分的なレスポンスの後にリトライするよりもリスクが低くなります。
HTTPXを使用しているPythonチームは、HTTPXが接続、読み取り、書き込み、およびプールのタイムアウトを分離しているため、これをクリーンに表現できます。OpenAI Python SDKもhttpx.Timeoutオブジェクトを受け入れるため、アプリケーションは接続バジェットと読み取りバジェットを分離しておくことができます。
import os
import httpx
from openai import OpenAI
client = OpenAI(
api_key=os.environ["FLATKEY_API_KEY"],
base_url="https://router.flatkey.ai/v1",
timeout=httpx.Timeout(
timeout=20.0,
connect=2.0,
read=10.0,
write=10.0,
pool=1.0,
),
max_retries=1,
)重要なのはサンプル値ではありません。重要なのは、AI APIのタイムアウト戦略が、ソケットが開けないことやローカルの接続プールが飽和していることを発見するために20秒を費やさないようにすることです。
Node.jsの場合、OpenAI JavaScript SDKはミリ秒単位のtimeoutオプションを公開しており、Nodeはまた、アボートシグナルを受け入れるAPIのためにAbortSignal.timeout(delay)を提供しています。そのパターンを使用して、無制限の呼び出し元に依存するのではなく、アプリケーションのデッドラインを明示的に保ちます。
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.FLATKEY_API_KEY,
baseURL: "https://router.flatkey.ai/v1",
timeout: 20_000,
maxRetries: 1,
});接続タイムアウトはインフラストラクチャのシグナルとして扱います。急増した場合は、モデルを変更する前に、DNS、TLS、ゲートウェイの到達可能性、プール制限、ローカルワーカーの飽和、および出力ポリシーを検査してください。
読み取りバジェットはコストとユーザーエクスペリエンスを保護する
読み取りバジェットは、リクエストが受け入れられた後にアプリケーションがレスポンスを待つ最大時間です。これは、AIワークロードが通常のJSON APIと異なる点です。モデルが正当に遅い場合、出力が長い場合、またはプロンプトがツール作業をトリガーする場合があります。したがって、読み取りタイムアウトはライブラリのデフォルトからではなく、ワークフローのデッドラインから設定する必要があります。
以下のルールを使用してください。
| ワークフロー | 読み取りバジェットのルール | タイムアウト時の対処法 |
|---|---|---|
| チャットまたはサポート | ユーザーの忍耐とサービスのSLOからバジェットを設定 | 正常なタイムアウト状態を表示し、リクエストをログに記録し、ユーザーに見える出力の前にのみ再試行する |
| バッチ抽出 | ジョブのデッドラインとキューの容量からバジェットを設定 | 同じルートで一度再試行し、その後レビューのためにレコードにマークを付ける |
| コードまたは推論 | タスクの複雑さとツールの能力上限からバジェットを設定 | タスクが自然に長時間実行される場合は、バックグラウンドモードを検討する |
| 財務または調達 | レビューSLAからバジェットを設定 | サイレントにルートを変更するのではなく、停止してキューに入れる |
| 内部自動化 | 下流の依存関係のデッドラインからバジェットを設定 | 呼び出し元が補償できるように十分に早く失敗させる |
AI APIのタイムアウト戦略では、出力サイズ、ツール呼び出し、フォールバック試行にも上限を設けるべきです。再試行レイヤーが重複した作業を作成する場合、読み取りタイムアウトだけではコストを制御できません。
ストリーミングバジェットには2つのクロックが必要
ストリーミングはリクエストタイムアウトを増やすだけでは解決しません。ストリーム化されたAIレスポンスには、少なくとも2つのクロックがあります。
- 最初のイベントのタイムアウト:ユーザーが最初のストリームイベントまたはトークンを待つ時間。
- アイドルタイムアウト:ストリーミングが開始された後、アプリケーションが沈黙を許容する時間。
OpenAI APIのリファレンスでは、streamが有効な場合、ストリーミングはサーバー送信イベントとして記述されています。バックグラウンドレスポンスの場合、OpenAIはシーケンス番号付きのストリーミングも文書化しており、クライアントは位置を追跡し、サポートされている場合は再接続できます。この区別は重要です。APIがカーソルからストリームを再開できる場合、AI APIのタイムアウト戦略は、再開契約のないプレーンなストリームとは異なる方法で回復できます。
製品がそのように設計されていない限り、ユーザーに見える部分的な出力の後にモデルを切り替えないでください。前の回答の途中から始まるフォールバックの回答は、通常、クリーンな失敗メッセージよりも悪いです。ストリーム化されたチャットでは、以下をログに記録します。
| フィールド | 重要である理由 |
|---|---|
time_to_first_event_ms | モデルの開始レイテンシと総完了時間を分離する |
last_event_at | ストリームがアイドル状態になった場所を示す |
sequence_numberまたはカーソル | APIがサポートしている場合に安全な再開を可能にする |
partial_output_committed | 可視出力後の安全でない再試行を防ぐ |
requested_modelおよびserved_model | ルーティングまたはフォールバックが動作を変更したかどうかを示す |
finish_reasonまたはターミナルイベント | 成功と放棄されたストリームを区別する |
主な障害モードがSSEの形状、クライアントの切断、または部分的な出力処理である場合は、このページをFlatkeyのストリーミングAI APIの信頼性に関するガイドと組み合わせてください。
キューバジェットはユーザーリクエストの外部に属する
一部のAIタスクは、同期リクエストには適していません。複数ステップの研究、長いツールワークフロー、大規模なドキュメントレビュー、複雑なメディア生成は、Webリクエストが開いたままにしておくべき時間よりも長く実行される可能性があります。タイムアウトポリシーは、ユーザーを1つの脆弱な接続で待たせるのではなく、これらのワークロードをキューまたはバックグラウンドモードに移動させるべきです。
OpenAIのバックグラウンドモードのドキュメントでは、queuedまたはin_progressの間にポーリングでき、必要に応じてキャンセルでき、そのように作成された場合はバックグラウンドモードからストリーミングできる非同期レスポンスについて説明しています。これは、プロバイダーやゲートウェイの実装が異なる場合でも、長時間のAI作業に対する正しいメンタルモデルです。ユーザーリクエストは永続的なジョブを作成し、アプリケーションはキューのデッドライン、ポーリング頻度、キャンセルルール、および結果保持ポリシーを適用します。
キューバジェットは以下を定義する必要があります。
| キューのフィールド | ポリシーに関する質問 |
|---|---|
| 最大キュー保持期間 | ジョブが古くなるまでどのくらいの時間待機できますか? |
| ポーリング間隔 | 過剰な負荷をかけずに、アプリはどのくらいの頻度でステータスを確認すべきですか? |
| キャンセルルール | 誰がキャンセルでき、部分的な作業はどうなりますか? |
| 重複ガード | リトライによって同じ高コストのジョブが2回作成されるのをどのように防ぎますか? |
| ユーザー通知 | ユーザーには保留中、失敗、キャンセル、完了が表示されますか? |
| コスト所有者 | どのキー、チーム、顧客、またはワークフローが支出を所有しますか? |
ここで、AI APIタイムアウト戦略は単なるSDKの設定ではなく、運用ポリシーとなります。
フォールバックバジェットの前のリトライバジェット
リトライとフォールバックは異なるアクションです。リトライは同じ契約を繰り返します。フォールバックはルート、モデル、プロバイダー、機能、コスト、またはエビデンスのサーフェスを変更します。
OpenAIのPythonおよびJavaScript SDKのreadmeには、接続エラー、408リクエストタイムアウト、409コンフリクト、429レート制限、およびサーバーエラーは、デフォルトで短い指数バックオフで2回リトライされると記載されています。これは便利なSDKの動作ですが、独自のゲートウェイリトライ、キューリトライ、およびジョブリトライをその上に追加するチームを驚かせる可能性があります。すべてのレイヤーを数えてください。
このようなリトライバジェットを使用します:
workflow: support_chat_answer
timeouts:
connect_ms: 2000
first_event_ms: 5000
stream_idle_ms: 20000
total_ms: 30000
retry:
sdk_max_retries: 1
gateway_max_retries: 1
retry_only_before_partial_output: true
fallback:
allowed_before_first_event:
- reviewed_support_backup_route
blocked_after_partial_output: true
stop_when:
- schema_contract_changes
- tool_support_missing
- cost_cap_exceeded
- data_boundary_changes
evidence:
required:
- workflow
- owner_key
- requested_model
- served_model
- timeout_layer
- retry_attempt
- fallback_reason
- usage_unitsより詳細なフォールバック評価パスについては、モデルフォールバック評価に関するFlatkeyのガイドを使用してください。リトライ固有の動作については、AI APIリトライ戦略に関するFlatkeyのガイドを使用してください。
可観測性フィールドがタイムアウトがデバッグ可能かどうかを決定する
エビデンスのないタイムアウトは単なる苦情です。AI APIタイムアウト戦略では、何が失敗したか、誰がそれを所有していたか、モデルが何かを生成したか、そして試行にどれくらいのコストがかかったかに答えるのに十分なフィールドを要求すべきです。
| エビデンスフィールド | タイムアウトポリシーに含める理由 |
|---|---|
| ワークフロー名 | タイムアウトを製品サーフェスにリンクする |
| 所有者キー、チーム、顧客、または環境 | 支出とインシデントの所有権を割り当てる |
| タイムアウトレイヤー | 接続、プール、読み取り、ストリームアイドル、キュー、およびフォールバック停止を分離する |
| リクエストされたモデルと提供されたモデル | ルート変更とフォールバックを公開する |
| エンドポイントファミリー | チャット、レスポンス、Anthropic、Gemini、画像、動画、その他の形状を分離する |
| リクエストIDまたはレスポンス/ジョブID | プロバイダー、ゲートウェイ、アプリの相関を可能にする |
| リトライ回数とフォールバック理由 | 隠れたリトライの増幅を防ぐ |
| 使用量単位とコストシグナル | 財務部門が重複または放棄された作業をレビューするのに役立つ |
| 部分出力フラグ | ストリームされた回答の重複からユーザーを保護する |
Flatkeyの現在の公開サイトは、統合されたモデルアクセス、ルーティング、請求、使用状況分析、および運用管理を中心に製品を位置付けています。現在の価格ページは、モデルアクセス、ルーティング、および請求オプションのレビューパスであり、2026年7月3日の価格APIスナップショットでは、openai、anthropic、gemini、image-generation、openai-video、およびvideoを含むエンドポイントファミリーが公開されました。これらは日付の入った証明点として扱い、永続的な可用性の主張とは見なさないでください。本番展開の前に、必ず現在のカタログを検証し、小規模なルートテストを実行してください。
実践的な展開計画
AI APIタイムアウト戦略を追加または改訂する際には、この展開シーケンスを使用してください:
- 1つのワークフローを選択し、所有者を指名します。
- 接続、プール、読み取り、ストリーム初回イベント、ストリームアイドル、キュー、リトライ、およびフォールバックのバジェットを選択します。
- 重複するリトライレイヤーを無効にするか、合計試行回数が明確になるように下げます。
- ルートの動作を変更する前に、タイムアウトレイヤーのロギングを追加します。
- 通常、低速、レート制限、ストリーム、および制御された失敗のテストケースを実行します。
- 部分的な出力が重複する前にリトライが停止することを確認します。
- フォールバックが必要なツール、スキーマ、データ境界、およびコストの期待値を維持することを確認します。
- Flatkeyでリクエストログ、使用量単位、およびコストのエビデンスを確認します。
- テスト済みのワークフローのみを本番環境に移行します。
- 1つのグローバルなタイムアウトポリシーを宣言するのではなく、次のワークフローに対して繰り返します。
最高のAI APIタイムアウト戦略は、テストできるほど小さく、停止できるほど厳格です。タイムアウトを退屈なものにするべきです。つまり、1つのレイヤーが失敗し、リトライバジェットは明確で、フォールバックは承認された契約内に留まるか停止し、ログには何が起こったかが示されます。
よくある質問
AI APIタイムアウト戦略とは何ですか?
AI APIタイムアウト戦略とは、接続設定、リクエスト/読み取り時間、ストリーミングの初回イベント、ストリーミングのアイドルギャップ、バックグラウンドキュー、リトライ、フォールバック、および可観測性に対して個別のバジェットを設定するワークフローレベルのポリシーです。
なぜSDKのデフォルトタイムアウトを使用しないのですか?
SDKのデフォルトは、広範なセーフティレールです。本番アプリケーションでは、ユーザーエクスペリエンス、コスト、リトライ動作、ワークフローのリスクに基づいて、より厳しいバジェットが必要です。OpenAIの公式SDKはタイムアウト設定を公開しているため、チームはワークフロー固有の制限を設定できます。
すべてのタイムアウトでフォールバックをトリガーすべきですか?
いいえ。接続タイムアウトは、リトライしたり、迂回させたりしても安全な場合があります。ユーザーに表示される部分的な出力後のストリームアイドルタイムアウトは、通常、クリーンに停止する必要があります。財務やコンプライアンスのワークフローでは、自動フォールバックの代わりに、キューイングや人によるレビューが必要になる場合があります。
AIリクエストは何回リトライすべきですか?
すべてのリトライレイヤー(SDK、ゲートウェイ、ワーカー、キュー、アプリケーション)を一緒にカウントします。合計を少なく保ち、各試行をログに記録し、リトライによって重複したコストや一貫性のないユーザー表示出力が作成される前に停止します。
チームが最初に測定すべきことは何ですか?
レイヤーごとのタイムアウト率、最初のイベントまでの時間、ストリームのアイドル障害、リトライ増幅、フォールバック率、承認された結果あたりのコスト、未解決のキューの経過時間から始めます。これらのメトリクスは、タイムアウトポリシーがワークフローを保護しているのか、それともインシデントを隠しているのかを示します。
Flatkeyはタイムアウト操作にどのように役立ちますか?
Flatkeyは、接続されたモデルへのアクセス、ルーティング、請求、使用状況分析、および運用管理のための単一のゲートウェイサーフェスをチームに提供します。これを使用して、現在のモデルとエンドポイントパスを確認し、リクエストの証拠を観察し、タイムアウト、リトライ、フォールバック、およびコストの決定を1つの所有者キーに関連付けます。
まずFlatkeyの料金を確認し、ワークフローを1つ選択してから、キーを取得し、本番トラフィックをルーティングする前にタイムアウトバジェットをテストします。