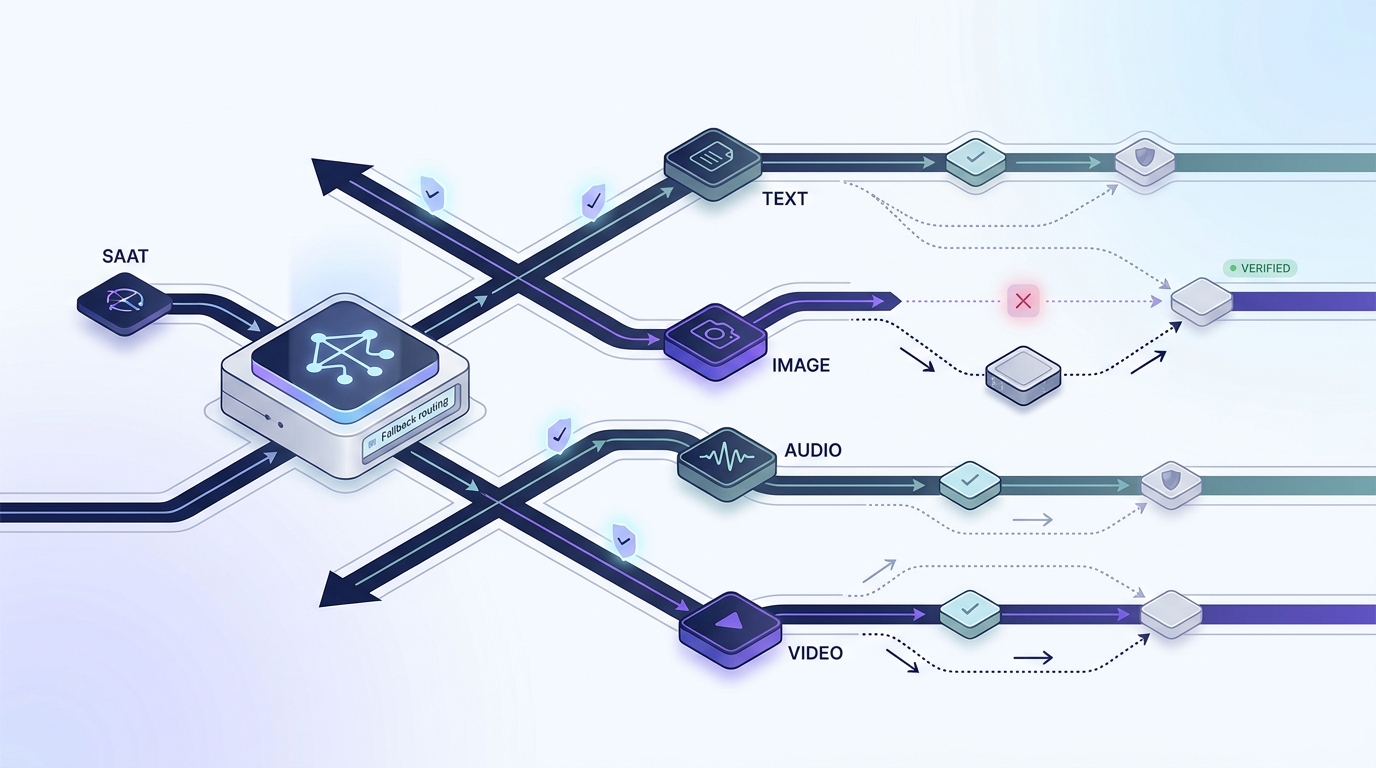
GPT Image 2 API access through Flatkey should start with a model-row check, not a copied code block. OpenAI documents gpt-image-2 as a current image generation model, and Flatkey's June 17, 2026 pricing snapshot lists GPT image-family rows. The useful question for a production team is narrower: which row will your app call, which endpoint shape does that row expose, what pricing unit should finance review, and what request checks should pass before traffic moves through the router?
This guide walks through those checks for teams that want one Flatkey key, the OpenAI-compatible base URL https://router.flatkey.ai/v1, usage logs, and pricing review in one place. Treat every code sample below as a template. The article uses official OpenAI docs, a dated Flatkey catalog snapshot, and CMS/public-route checks, but it does not claim that a live Flatkey GPT Image 2 API inference test was run.
Quick Answer: What To Verify Before Using GPT Image 2 API Through Flatkey
If you are evaluating the GPT Image 2 API through Flatkey, verify these items in this order:
- Open Flatkey pricing and search for the exact model row, such as
gpt-image-2oropenai/gpt-image-2. - Confirm the supported endpoint type for that row. In the June 17, 2026 snapshot, the main
gpt-image-2rows exposedopenai, while older GPT image rows also exposedimage-generation. - Check the availability status. The GPT Image 2 rows in the snapshot showed
unknown_failure, so production usage needs a current dashboard check and a small smoke test. - Compare pricing units before launch. Flatkey showed token-ratio style fields for one row and a request-priced-looking
model_pricefield for another row, so do not assume one unit across every GPT Image 2 API route. - Match your request body to the confirmed route: Images API style, Responses API style, or a Flatkey-supported OpenAI-compatible wrapper.
- Log model ID, endpoint path, quality, output size, output format, input image count, retry count, usage, and final cost per accepted asset.
That sequence matters because the GPT Image 2 API is not just a model name. It is a combination of model ID, endpoint, request parameters, account entitlement, routing status, and billing unit.
What OpenAI Documents For GPT Image 2 API
OpenAI's image guide says GPT Image models can use text and image inputs to create new images or edit existing ones, and it describes gpt-image-2 as a state-of-the-art image generation model with strong instruction following and contextual awareness. The guide also says teams can generate or edit images with either the Images API or the Responses API.
For the Images API path, the create-image reference documents POST /images/generations. It includes parameters that matter for production request checks: prompt, background, moderation, output_format, quality, size, stream, and n. It also states that GPT image models return base64-encoded images rather than temporary image URLs.
| OpenAI Check | Why It Matters For Flatkey | Production Action |
|---|---|---|
model |
The direct OpenAI model ID may not be the same string as a routed catalog row. | Write down the exact Flatkey row and the model string in your request. |
POST /images/generations |
This is the official Images API generation path, but Flatkey endpoint support is row-specific. | Use this route through Flatkey only after the dashboard shows Images API support for the selected row. |
background and output_format |
Transparent output requires a compatible format such as PNG or WebP. | Validate the output format before creating design workflows that depend on alpha. |
quality and size |
These are major cost and latency levers for GPT Image 2 API workloads. | Separate draft, preview, and final-render settings in product logic. |
| Base64 response handling | GPT image models return image bytes, not long-lived hosted URLs. | Store the image yourself, attach metadata, and avoid relying on a provider URL. |
Flatkey Catalog Snapshot For GPT Image 2
On June 17, 2026, the Flatkey public pricing API returned pricing version a42d372ccf0b5dd13ecf71203521f9d2 and 638 model rows. The GPT image-family summary included gpt-image-2, openai/gpt-image-2, gpt-image-2-all, gpt-image-1.5, gpt-image-1-mini, and gpt-image-1.
| Flatkey Row | Groups | Endpoint Types In Snapshot | Pricing Fields Seen | Status In Snapshot | How To Use This Evidence |
|---|---|---|---|---|---|
gpt-image-2 |
Economy, Standard | openai |
model_ratio: 3.325, completion_ratio: 6, cache_ratio: 0.251127819549 |
unknown_failure |
Use as dated catalog proof only; verify current row status before production GPT Image 2 API traffic. |
openai/gpt-image-2 |
Standard | openai |
quota_type: 1, model_price: 0.063 |
unknown_failure |
Do not copy the number without confirming the current unit and dashboard label. |
gpt-image-2-all |
Standard | openai |
model_ratio: 37.5, completion_ratio: 2 |
unknown_failure |
Check whether this is a bundle, alias, or internal routing row before using it in code. |
gpt-image-1.5 and gpt-image-1-mini |
Standard | image-generation, openai |
Ratio-style pricing fields | unknown_failure |
Useful comparison rows, but not a substitute for the selected GPT Image 2 API row. |
The public pricing page also exposes endpoint families such as image-generation with path /v1/images/generations, openai with path /v1/chat/completions, and openai-response with path /v1/responses. The important detail is that endpoint families exist at the platform level, while support is still row-specific. For the GPT Image 2 API, confirm the row before writing the request.
Request Checks For GPT Image 2 API
Use this checklist before any routed GPT Image 2 API rollout. It is deliberately operational because pricing mistakes usually come from request shape, not from misunderstanding a single headline rate.
| Check | Pass Condition | Failure Mode | Where To Verify |
|---|---|---|---|
| Model row | The Flatkey dashboard row matches the model string in code. | App calls a legacy, alias, or bundle row by accident. | Flatkey pricing and model catalog. |
| Endpoint path | The route path matches the row's supported endpoint type. | Images API body is sent to a chat-compatible row, or the reverse. | Flatkey row support plus OpenAI API reference. |
| Availability | Dashboard status is clean, and a tiny request succeeds. | Catalog row exists but upstream or account access fails. | Flatkey dashboard, response status, and logs. |
| Pricing unit | Finance knows whether the row is token-ratio, request-priced, or another unit. | Budget uses per-token assumptions for a per-request row. | Flatkey pricing and usage dashboard. |
| Prompt and image inputs | Prompt length, image references, masks, and retries are logged. | Input images and retries create hidden cost. | Application telemetry and provider usage fields. |
| Output settings | Quality, size, background, format, and compression are controlled. | Every preview is generated as a final asset. | Request body and product defaults. |
Template: Direct OpenAI Images API Request
The direct provider template is useful as a baseline when comparing Flatkey route behavior. Confirm current OpenAI account access and model availability before running it.
# Template only: direct OpenAI Images API baseline
curl https://api.openai.com/v1/images/generations \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-2",
"prompt": "Create a clean product concept image for a usage dashboard.",
"size": "1536x1024",
"quality": "medium",
"output_format": "png"
}'
For a baseline GPT Image 2 API test, keep the first prompt simple, avoid reference images, use one output, and record response status, latency, output size, and any usage fields returned by the endpoint.
Template: Flatkey Route Check
Flatkey's public positioning centers on one key and an OpenAI-compatible base URL. For text routes, the public homepage shows https://router.flatkey.ai/v1/chat/completions. For GPT Image 2 API routing, do not assume the image path is enabled for the selected row. First check whether the row exposes image-generation, openai, openai-response, or another route in your dashboard.
# Template only: use this shape only if your Flatkey row confirms image-generation support
curl https://router.flatkey.ai/v1/images/generations \
-H "Authorization: Bearer $FLATKEY_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-2",
"prompt": "Create a clean product concept image for a usage dashboard.",
"size": "1536x1024",
"quality": "medium",
"output_format": "png"
}'
// Template only: centralize the base URL, then inject the confirmed path.
const FLATKEY_BASE_URL = "https://router.flatkey.ai/v1";
async function createImageThroughConfirmedRoute({ path, apiKey, body }) {
const response = await fetch(`${FLATKEY_BASE_URL}${path}`, {
method: "POST",
headers: {
Authorization: `Bearer ${apiKey}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
if (!response.ok) {
throw new Error(`Flatkey route check failed: ${response.status}`);
}
return response.json();
}
// Example only after dashboard confirmation:
await createImageThroughConfirmedRoute({
path: "/images/generations",
apiKey: process.env.FLATKEY_API_KEY,
body: {
model: "gpt-image-2",
prompt: "Create a clean product concept image for a usage dashboard.",
size: "1536x1024",
quality: "medium",
output_format: "png"
}
});
If the current Flatkey row still exposes only openai, ask product or support which request shape is supported for that GPT Image 2 API row before shipping. A catalog row and an endpoint path are both required; one without the other is not a production integration.
Pricing Checks To Run In Flatkey
For this article, the safest pricing guidance is procedural: verify the current row in Flatkey pricing, compare it with OpenAI's current image pricing page, then confirm actual routed usage in logs. The June 17 Flatkey snapshot proves the catalog had GPT image rows, but the row fields used different pricing representations. That is enough to build a pricing review workflow, not enough to publish a permanent price claim.
| Pricing Question | What To Record | Why It Matters |
|---|---|---|
| Which row is selected? | Exact model name, group, quota type, and endpoint type. | Multiple GPT image-family rows can appear in the same catalog. |
| What unit is displayed? | Token ratio, request price, per-output unit, or dashboard-specific label. | Mixing units causes budget errors even when the model name is right. |
| What settings change cost? | Quality, size, prompt length, image inputs, output format, retries, and batch behavior. | The same GPT Image 2 API feature can have preview and final-render cost tiers. |
| What does Flatkey log? | Request count, status, usage, cost, model row, and failure reason. | Logs prove whether routed usage matches the estimate. |
Teams comparing image budgets should also read OpenAI Image API Pricing and AI Model Pricing Comparison. Those pieces cover broader token, image, and video cost mechanics; this page focuses on the Flatkey-specific GPT Image 2 API route checks.
Smoke Test Plan Before Production Traffic
Run a small validation sequence after the dashboard row, endpoint, and pricing unit are confirmed:
- Send one direct OpenAI baseline request if your team has direct OpenAI access.
- Send one Flatkey request through the confirmed endpoint and model row.
- Compare response shape, output format, output bytes, failure messages, and latency.
- Check Flatkey usage logs for model row, request count, usage, and cost.
- Repeat with the exact production settings: quality, size, background, output format, and any input images.
- Set retry limits and stop conditions before exposing the feature to users.
- Keep a rollback path to the prior image workflow or direct provider route.
This is the same operational discipline described in the OpenAI-compatible API migration guide: change the route deliberately, map the model ID, run a small smoke test, and use logs before scaling.
When Flatkey Is The Right GPT Image 2 API Path
Flatkey is a good fit when your image feature is part of a broader multimodal stack. A product may use text models for prompt rewriting, GPT image models for asset creation, vision-capable models for review, and other providers for fallback or cost control. One key, one pricing surface, and one usage dashboard make that workflow easier to audit than separate provider accounts.
Flatkey is not a reason to skip provider-level checks. For the GPT Image 2 API, the row status, endpoint support, and request body must line up before production traffic. The June 17 snapshot showed catalog presence, not a clean availability result.
Final GPT Image 2 API Checklist
- Primary model row selected in Flatkey pricing.
- Endpoint support confirmed for the selected row.
- Pricing unit and current dashboard label reviewed.
- Small Flatkey route test completed with the production request shape.
- Usage logs checked for row, status, tokens or request units, and cost.
- Retry limits, quota limits, and rollout guardrails configured.
- Rollback route documented.
The safest way to adopt the GPT Image 2 API through Flatkey is to treat model access, endpoint support, and pricing as one validation loop. View Pricing to check the current Flatkey GPT image rows before moving real image traffic.