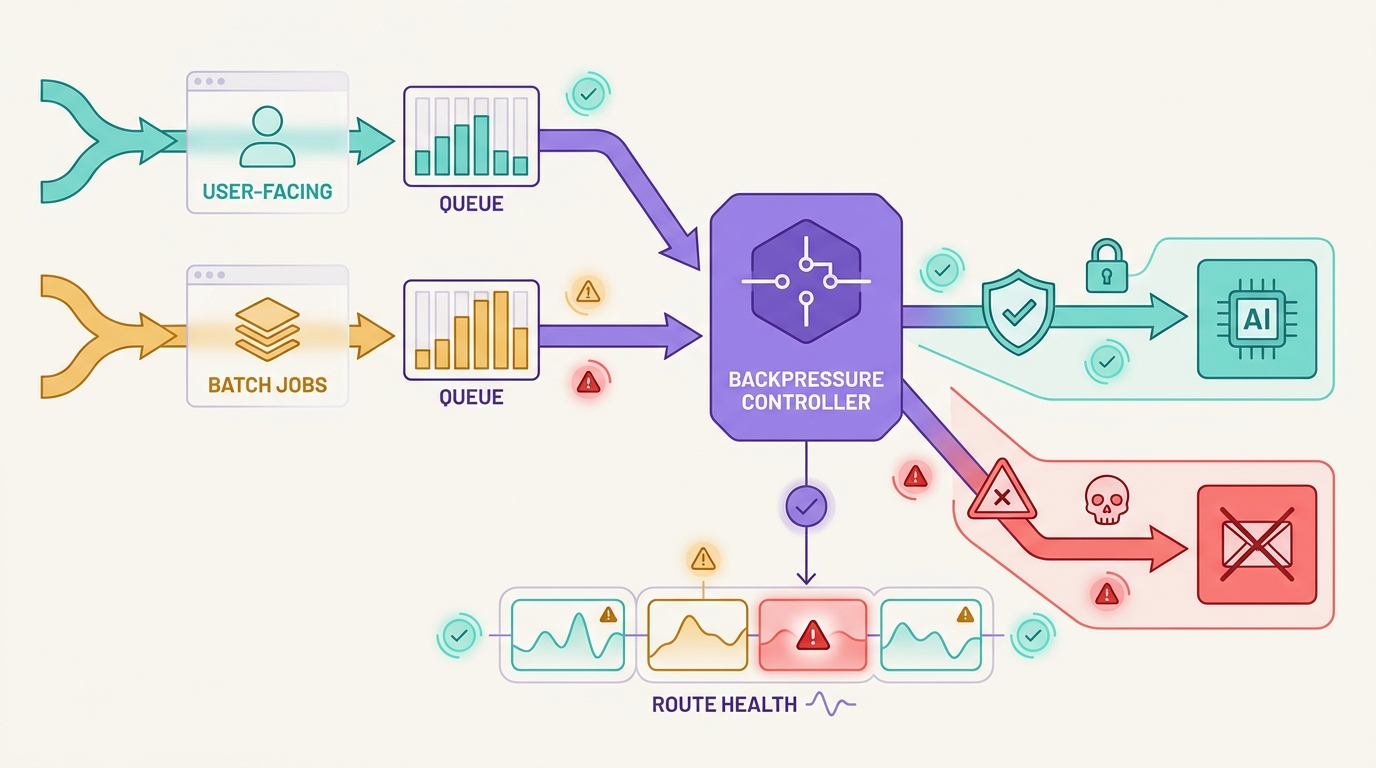
Eine KI-API-Warteschlangenstrategie ist nicht nur ein Muster für Hintergrundjobs. In produktiven KI-Systemen entscheidet die Warteschlange, ob benutzerorientierte Arbeit warten, wiederholt, auf eine Alternative zurückgreifen, Last abwerfen oder geschlossen fehlschlagen soll, wenn ein Modellanbieter langsamer wird oder eine Upstream-Route nicht verfügbar ist.
Das gefährliche Muster besteht darin, jede fehlgeschlagene Anfrage in eine einzige Wiederholungswarteschlange zu stellen und zu hoffen, dass die Kapazität zurückkehrt. Das kann zwar einen Worker-Prozess schützen, schadet aber dem Produkt: Chat-Benutzer warten zu lange, Streaming-Sitzungen können nicht sauber wieder aufgenommen werden, Batch-Jobs duplizieren teure Prompts und Fallback-Routen ändern das Modellverhalten ohne ausreichende Beweise.
Eine gute KI-API-Warteschlangenstrategie trennt die Arbeit vor dem Ausfall. Interaktive Anfragen erhalten kurze Budgets und klare Abbruchbedingungen. Batch-Arbeit erhält Idempotenz, Altersgrenzen für die Warteschlange und Wiederholungsregeln. Ein Fallback erfolgt nur, wenn der Ausgabevertrag weiterhin gültig ist. Flatkey passt zu diesem Betriebsmodell, da Teams den Modellzugriff, das Routing, die Abrechnung, die Nutzungsanalyse und die Betriebskontrollen in einer einzigen Gateway-Oberfläche behalten können, während sie den aktuellen Modellkatalog und die Anforderungsnachweise überprüfen.
KI-API-Warteschlangenstrategie in einer Tabelle
Verwenden Sie diese Tabelle als ersten Schritt bei der Entscheidung, was in eine Warteschlange gehört und was auf dem Anfragepfad bleiben sollte.
| Workflow | Warteschlangenentscheidung | Wiederholungsbudget | Fallback-Grenze | Abbruchbedingung |
|---|---|---|---|---|
| Kundenchat vor dem ersten Token | Kurzer Backoff oder für einige Sekunden in die Warteschlange stellen | 1 oder 2 Versuche innerhalb der Benutzerfrist | Nur zu einer genehmigten Route mit denselben Tools, demselben Schema und derselben Datengrenze | Kontrolliert fehlschlagen, wenn die Benutzerfrist abgelaufen ist |
| Kundenchat nach dem Streamen von Tokens | Nicht automatisch wiederholen | Normalerweise keine, da die Ausgabe bereits sichtbar ist | Routenänderungen mitten in der Antwort vermeiden | Den Stream mit einem kontrollierten Fehler und einer Anfrage-ID beenden |
| Support-Zusammenfassung im Hintergrund | In die Warteschlange stellen | Wiederholen bis zum maximalen Warteschlangenalter oder Wiederholungsbudget | Erlaubt, wenn Modellqualität und Kostenklasse genehmigt sind | In die Dead-Letter-Queue verschieben, wenn der Job veraltet oder nicht idempotent ist |
| Evaluierungs- oder Benchmark-Job | In die Warteschlange stellen und nach Modell/Anbieter-Schlüssel drosseln | Größeres Budget, aber begrenzt | Normalerweise kein Fallback, da die Ergebnisse vergleichbar sein müssen | Stoppen, wenn Routenänderungen den Durchlauf ungültig machen würden |
| Bild- oder Videogenerierung | In die Warteschlange stellen mit strikter Idempotenz | Geringe Anzahl von Versuchen aufgrund der Kosten | Fallback nur nach Genehmigung durch Benutzer oder Eigentümer | Stoppen, wenn eine doppelte Generierung ein Kosten- oder UX-Risiko schaffen würde |
| Finanz-, Rechts-, Beschaffungs- oder regulierte Überprüfung | Zur Überprüfung durch den Eigentümer in die Warteschlange stellen oder geschlossen fehlschlagen | Minimal | Nur mit ausdrücklicher Genehmigung | Geschlossen fehlschlagen bei Nichtübereinstimmung von Datengrenze, Kosten oder Genehmigung |
Das ist der Kern einer KI-API-Warteschlangenstrategie: Die Warteschlange ist eine Richtlinienebene, kein Ort, um jedes Upstream-Problem zu verbergen.
Zuerst das Anbietersignal klassifizieren
Das Einreihen in eine Warteschlange sollte mit der Fehlerklassifizierung beginnen. Offizielle Anbieterdokumentationen verwenden unterschiedliche Begriffe für ähnliche Bedingungen, daher sollte die Anwendung diese normalisieren, bevor eine Aktion ausgewählt wird.
OpenAI trennt die Anfragengeschwindigkeit von der Erschöpfung von Kontingenten oder Abrechnungen. Die Fehlerdokumentation beschreibt 429-Ratenbegrenzungsfehler für zu schnelles Senden von Anfragen, separate 429-Fälle für Kontingente oder Abrechnungen, 500-Serverfehler, 503-Überlastung und eine 503-Verlangsamungsbedingung bei plötzlichen Verkehrsanstiegen. Die Anleitung zur Ratenbegrenzung von OpenAI empfiehlt außerdem einen zufälligen exponentiellen Backoff und warnt davor, dass auch erfolglose Anfragen zu den Limits pro Minute zählen.
Anthropic dokumentiert Ratenbegrenzungen über Anfrage- und Token-Dimensionen hinweg, mit 429-Antworten und retry-after-Anleitungen. Die Fehlerdokumentation trennt auch rate_limit_error von overloaded_error, wobei Überlastung auf HTTP 529 abgebildet wird. Diese Unterscheidung ist wichtig, da eine lokale Warteschlange Ihren Datenverkehr verlangsamen kann, aber die Anbieterkapazität nicht durch aggressives Wiederholen wiederherstellen kann.
Die Fehlerbehebung für Gemini bildet 429 auf RESOURCE_EXHAUSTED ab und weist Teams an, zu überprüfen, ob sie Ratenbegrenzungen, Limits der kostenlosen Stufe oder tägliche Limits erreicht haben, bevor sie es erneut versuchen. Die Dokumentation zur Ratenbegrenzung von Gemini beschreibt auch Dimensionen wie Anfragen pro Minute, Tokens pro Minute, Anfragen pro Tag und ausgabenbasierte Limits.
Normalisieren Sie diese Signale in eine interne Form:
| Feld | Beispielwerte | Verwendung in der Warteschlange |
|---|---|---|
http_status | 429, 500, 503, 529 | Trennt zwischen Geschwindigkeitssteuerung, Serverausfall und Überlastung |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | Verhindert, dass Kontingent- und Ausgabenprobleme als vorübergehend behandelt und wiederholt werden |
retry_after_ms | Vom Header abgeleitete Verzögerung oder null | Legt die früheste Freigabezeit für in die Warteschlange gestellte Arbeit fest |
limit_dimension | Anfragen, Eingabe-Tokens, Ausgabe-Tokens, tägliche Anfragen, Ausgaben | Teilt dem System mit, was gedrosselt werden soll |
route_key | Anbieter, Modell, Endpunktfamilie, Eigentümerschlüssel | Gruppiert den Verkehr für Gegendruck |
visibility_state | vor dem ersten Token, nach Teilausgabe, nur im Hintergrund | Verhindert die unsichere Wiederholung von für den Benutzer sichtbarer Arbeit |
Ohne diese Ebene wird eine KI-API-Warteschlangenstrategie zum Ratespiel.
Benutzerorientierte von Batch-Lanes trennen
Benutzerorientierter Verkehr und Batch-Verkehr sollten nicht dieselbe Warteschlangenrichtlinie teilen. Sie können die Infrastruktur gemeinsam nutzen, benötigen aber unterschiedliche Budgets.
Interaktive Workflows sollten eine kurze Zulassungswarteschlange haben. Wenn das System die Anfrage nicht innerhalb der Produktfrist starten kann, sollte es einen kontrollierten Fehler zurückgeben, anstatt den Benutzer hinter einem langen Anbieter-Ausfall warten zu lassen. Ein Benutzer, der auf Chat, Programmierunterstützung, Suche oder Support-Triage wartet, benötigt in der Regel jetzt eine klare Antwort und nicht erst zehn Minuten später eine erfolgreiche Rückmeldung.
Batch-Workflows können länger warten, aber nur mit einem maximalen Warteschlangenalter. Zusammenfassungen, Extraktionen, Anreicherungen, Auswertungen und geplante Automatisierungen sollten ein max_queue_age_ms-Feld enthalten, damit veraltete Arbeit verfallen kann, anstatt nach Verstreichen des geschäftlichen Moments erneut abgespielt zu werden.
Die minimalen Warteschlangen-Lanes sind:
| Lane | Verwendung für | Standardfrage für den Eigentümer |
|---|---|---|
interactive_admission | Anfragen, die noch keine sichtbare Ausgabe gestartet haben | Wie lange kann der Benutzer warten, bevor das Produkt mit einem kontrollierten Fehler antworten sollte? |
stream_recovery | Streams, die unterbrochen wurden, bevor ein Token gesendet wurde | Kann die Anfrage neu gestartet werden, ohne sichtbare Ausgaben oder Nebenwirkungen von Tools zu duplizieren? |
background_retry | Offline-Jobs, die sicher wiederholt werden können | Was ist das maximale Alter, die maximale Anzahl an Versuchen und der Idempotenzschlüssel? |
owner_review | Jobs, die durch Ausgaben, Kontingente, Genehmigungen oder Datengrenzen blockiert sind | Wer muss die Wiederholung oder den Fallback genehmigen? |
dead_letter | Jobs, deren sichere Wiederholungsrichtlinie ausgeschöpft ist | Welcher Nachweis ist erforderlich, bevor ein Mensch die Wiederholung durchführt? |
Dieses Lane-Design schützt benutzerorientierte Arbeit bei Anbieter-Ausfällen, da der Batch-Backlog nicht die gesamte Kapazität verbrauchen kann, gerade wenn Benutzer versuchen, sich zu erholen.
Retry-After als Freigabezeitpunkt verwenden
Das HTTP-Feld Retry-After kann eine Verzögerung in Sekunden oder ein HTTP-Datum sein. Queue-Worker sollten es nicht als Grund behandeln, innerhalb eines Request-Handlers zu schlafen. Wandeln Sie es in eine Bereitschaftszeit um, speichern Sie es im Job und geben Sie den Job erst frei, wenn sowohl der Hinweis des Anbieters als auch das Workflow-Budget einen weiteren Versuch zulassen.
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}Dieser Helfer hält die Anbieteranweisungen aus dem „Hot Path“ heraus. Der Request-Handler kann zurückkehren, die Warteschlange kann den Job halten, bis er bereit ist, und die Beobachtbarkeit kann zeigen, ob das System den Wartehinweis des Anbieters beachtet hat.
Gegendruck kommt vor Fallback
Fallback ist nicht das erste Werkzeug zum Leeren der Warteschlange. Es ändert etwas an der Arbeit: Modell, Anbieter, Kosten, Latenz, Werkzeugverhalten, Kontextfenster, Datengrenze oder Ausgabequalität. Während eines Ausfalls kann ein automatischer Fallback die Warteschlange gesünder erscheinen lassen, während er stillschweigend das Produktverhalten ändert.
Wenden Sie zuerst Gegendruck an:
- Pausieren Sie neue, nicht dringende Jobs für den betroffenen
route_key. - Verringern Sie die Worker-Parallelität für den betroffenen Anbieter, das Modell, die Endpunktfamilie, den Kunden oder den Eigentümerschlüssel.
- Geben Sie Jobs gemäß
ready_atfrei, nicht nur nach FIFO. - Werfen Sie Arbeit mit niedriger Priorität ab, bevor sie interaktive Kapazitäten blockiert.
- Führen Sie einen Fallback nur durch, wenn der Vertrag noch gültig ist.
Hier verbindet sich eine KI-API-Warteschlangenstrategie mit Ihrer umfassenderen KI-API-Wiederholungsstrategie. Wiederholungen behandeln begrenzte Versuche. Warteschlangen absorbieren die Nachfrage. Gegendruck verlangsamt die Quelle. Fallback ändert die Route erst, nachdem diese Kontrollen den benutzerorientierten Pfad geschützt haben.
Warteschlangenfelder, die Ausfälle debugfähig machen
Eine Warteschlange, die nur Prompt und Modell speichert, ist schwer zu betreiben. Fügen Sie die Felder hinzu, die beantworten, warum der Job wartet, wem er gehört und was als Nächstes sicher getan werden kann.
| Feld | Erforderliche Regel |
|---|---|
job_id | Stabiler Bezeichner für Nachverfolgung und Wiederholung |
idempotency_key | Abgeleitet aus Workflow, Benutzer oder Eigentümer, Input-Hash und Ziel der Nebenwirkung |
workflow | Produktoberfläche wie Chat, Support-Zusammenfassung, Rechnungsprüfung oder Evaluierung |
owner_key | Team, Kunde, Projekt oder Umgebung, verantwortlich für Kosten und Kapazität |
route_key | Anbieter, Modell, Endpunktfamilie und Gateway-Route |
requested_model und served_model | Zeigt an, ob Routing oder Fallback das Verhalten geändert haben |
attempt und max_attempts | Verhindert unendliche Wiederholungsversuche |
created_at, ready_at, expires_at | Steuert das Alter der Warteschlange und den Zeitpunkt der Freigabe |
retry_after_ms | Behält die Warteanweisung des Anbieters bei |
fallback_allowed | Verweist auf eine genehmigte Fallback-Richtlinie, keine boolesche Vermutung |
partial_output_committed | Blockiert unsichere Wiederholung von Streams und Nebenwirkungen von Tools |
last_error_type | Hält Anbieterfehler nach Wiederholungsversuchen sichtbar |
estimated_cost und usage_units | Macht doppelte Arbeit für Finanzen und Betreiber sichtbar |
Flatkey-Benutzer sollten diese Felder mit den Gateway-Nachweisen abgleichen: angefordertes Modell, bereitgestelltes Modell, Endpunkttyp, Eigentümerschlüssel, Nutzungseinheiten und Routenergebnis. Die aktuelle öffentliche Website von Flatkey positioniert das Produkt als ein Gateway für Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und Betriebskontrollen. Der Snapshot der Preisgestaltungs-API vom 3. Juli 2026 lieferte 45 Modellzeilen, fünf Anbieter-IDs und unterstützte Endpunkttypen wie openai, anthropic, gemini und image-generation. Behandeln Sie diese Fakten als veraltete Nachweise und überprüfen Sie dann den aktuellen Katalog unter Preise, bevor Sie die Produktionsrichtlinie ändern.
Dead-Letter-Queues benötigen Wiederholungsregeln
Dead-Letter-Queues sind nur dann nützlich, wenn sie eine blinde Wiederholung verhindern. Ein fehlgeschlagener KI-Job kann einen großen Prompt, einen Tool-Plan, eine Kundenaktion oder eine teure Bild-/Videoanfrage enthalten. Eine Wiederholung ohne Kontext kann Nebenwirkungen oder Ausgaben duplizieren.
Erstellen Sie einen Dead-Letter-Eintrag, wenn eine dieser Bedingungen eintritt:
- Der Job hat
max_attemptsüberschritten. - Der Job hat
max_queue_age_msüberschritten. - Das Anbietersignal zeigt einen Fehler bei Kontingent, Ausgaben, Berechtigung oder Datengrenze an.
- Der Fallback-Vertrag erhält die Modellfähigkeit, das Tool-Verhalten, das Schema oder den Genehmigungsstatus nicht aufrecht.
- Der Job ist nicht idempotent oder hat bereits eine Teilausgabe übermittelt.
Fordern Sie diese Felder vor der Wiederholung an:
| Wiederholungsfeld | Warum es wichtig ist |
|---|---|
replay_owner | Weist die Verantwortung für Kosten und Kundenauswirkungen zu |
replay_reason | Trennt die Wiederherstellung des Anbieters von Produktfehlern, Kontingentänderungen oder Eigentümer-Overrides |
route_override | Zeigt an, ob die Wiederholung dasselbe Modell oder ein genehmigtes Fallback verwendet |
idempotency_result | Beweist, dass die Wiederholung keine externen Nebenwirkungen dupliziert |
cost_reviewed | Verhindert, dass eine in der Warteschlange befindliche Wiederholung zu einer überraschenden Rechnung wird |
Eine KI-API-Warteschlangenstrategie sollte die Wiederholung langweilig machen: Jede Wiederholung hat einen Eigentümer, einen Grund, eine Route und eine Stoppbedingung.
Streaming-Workflows benötigen eine andere Grenze
Streaming ändert die Warteschlangenentscheidung. Vor dem ersten Token kann die Anfrage oft wiederholt, kurz in die Warteschlange gestellt oder auf ein Fallback zurückgegriffen werden. Nach dem ersten Token kann eine Wiederholung sichtbare Ausgaben duplizieren, Tools erneut ausführen oder zwei Modellverhalten in einer Antwort zusammenfügen.
Verwenden Sie eine Stream-Grenzregel:
| Stream-Status | Warteschlangenverhalten |
|---|---|
| Anfrage akzeptiert, kein Token gesendet | Wiederholung oder Einreihung in die Warteschlange innerhalb einer kurzen Benutzerfrist |
| Erstes Token gesendet, keine Tool-Nebenwirkung | Bevorzugen Sie eine kontrollierte Stream-Beendigung mit Anfrage-ID |
| Tool-Aufruf ausgegeben oder Nebenwirkung gestartet | Fail-Closed und Beweise für den Vorfall aufbewahren |
| Stream-Leerlauf-Timeout vor sichtbarer Ausgabe | Wiederholen, wenn Idempotenz und Frist es zulassen |
| Anbieterausfall nach teilweiser Antwort | Kein automatisches Fallback in dieselbe Antwort |
Für eine ausführlichere Begleitrichtlinie, siehe Zuverlässigkeit von Streaming-KI-APIs. Warteschlangen können den Zulassungspfad schützen, sollten aber nicht so tun, als ob eine teilweise Streaming-Ausgabe dasselbe wie ein neuer Hintergrundjob wäre.
Fallback-Verträge für in der Warteschlange befindliche Arbeit
Ein in der Warteschlange befindlicher Job kann nur dann auf ein Fallback zurückgreifen, wenn der Vertrag noch gültig ist. Wenden Sie dieselbe Disziplin an, die Sie in einer Checkliste zur Evaluierung von Modell-Fallbacks verwenden würden, und fügen Sie dann den genehmigten Vertrag der Warteschlangenrichtlinie hinzu.
| Vertragsbereich | Erforderliche Frage |
|---|---|
| Endpunktform | Unterstützt das Fallback dieselbe Form für Chat, Antworten, Nachrichten, Bilder, Videos oder Tool-Aufrufe? |
| Ausgabevertrag | Bleiben JSON-Schema, Tool-Aufrufverhalten, Sicherheitsbehandlung und Streaming-Anforderungen erhalten? |
| Qualitätsklasse | Ist das Fallback-Modell für diesen Workflow genehmigt? |
| Kostenobergrenze | Könnte das Fallback das Budget überschreiten, das die Warteschlange ausgelöst hat? |
| Datengrenze | Behält die Route die Einschränkungen bezüglich Anbieter, Lieferant, Region und Beschaffung bei? |
| Beobachtbarkeit | Zeigen die Protokolle das angeforderte Modell, das bereitgestellte Modell, den Grund für das Fallback, das Alter der Warteschlange und die Nutzung an? |
Wenn eine Antwort unbekannt ist, sollte die Warteschlange anhalten oder den Job zur Überprüfung durch den Eigentümer verschieben. Eine Warteschlange, die während eines Anbieterausfalls stillschweigend die Route ändert, kann ein sichtbares Zuverlässigkeitsproblem gegen ein verstecktes Korrektheitsproblem eintauschen.
Eine praktische Richtlinienvorlage
Beginnen Sie mit einer Richtliniendatei, bevor Sie Warteschlangen-Worker in die Produktion einbinden. Die folgenden Zahlen sind Beispiele; passen Sie sie mit Verkehrs- und Vorfalldaten an.
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatchDiese Vorlage macht die Warteschlangenrichtlinie überprüfbar. Produkt-, Plattform-, Finanz- und Beschaffungsteams können genau sehen, welche Arbeit wartet, welche Arbeit die Route ändert und welche Arbeit stoppt.
Rollout-Checkliste
Verwenden Sie diese Checkliste für die KI-API-Warteschlangenstrategie, wenn Sie Warteschlangensteuerungen zu einer Produktionsroute hinzufügen:
- Wählen Sie einen Workflow aus und benennen Sie den Product Owner.
- Definieren Sie die Benutzer-Deadline und das maximale Alter der Hintergrund-Warteschlange.
- Normalisieren Sie Anbieterfehler in eine einzige interne Form für Warteschlangenentscheidungen.
- Parsen Sie
Retry-Afterinready_at. - Fügen Sie Idempotenzschlüssel hinzu, bevor Sie die Wiederholung aktivieren.
- Teilen Sie interaktive, Hintergrund-, Eigentümerprüfungs- und Dead-Letter-Lanes auf.
- Wenden Sie Gegendruck nach Routenschlüssel an, bevor Sie das Fallback aktivieren.
- Hängen Sie Fallback-Verträge an Warteschlangenrichtlinien an, nicht an den Worker-Code.
- Blockieren Sie die automatische Wiederholung nach teilweiser Streaming-Ausgabe oder externen Nebeneffekten.
- Protokollieren Sie das Alter der Warteschlange, die Anzahl der Versuche, den Grund für das Fallback, das angeforderte Modell, das bereitgestellte Modell, die Nutzungseinheiten und die geschätzten Kosten.
- Testen Sie 429, 503, 529, Netzwerk-Timeout, Quotenerschöpfung, langes
Retry-Afterund teilweise Streaming-Fehler. - Überprüfen Sie die Flatkey-Nutzung und die Routen-Nachweise, bevor Sie die Richtlinie auf den nächsten Workflow ausweiten.
Die beste KI-API-Warteschlangenstrategie macht Ausfälle weniger dramatisch. Benutzer erhalten klare Fristen. Stapelverarbeitungsaufträge warten, ohne die Kosten zu verdoppeln. Fallbacks bleiben innerhalb genehmigter Verträge. Betreiber erhalten Nachweise anstelle eines Backlogs von mysteriösen Jobs.
Beginnen Sie mit den aktuellen Flatkey-Preisen und dem Modellkatalog, wählen Sie einen Workflow aus, holen Sie sich einen Schlüssel und testen Sie Ihre KI-API-Warteschlangenstrategie, bevor Sie Produktionsverkehr darüber leiten.
FAQ
Was ist eine KI-API-Warteschlangenstrategie?
Eine KI-API-Warteschlangenstrategie ist die Richtlinie, die entscheidet, ob Modellanfragen bei Ratenbegrenzungen, Überlastung, Ausfällen und Anbieterfehlern erneut versucht werden, in einer Warteschlange warten, auf eine andere genehmigte Route zurückfallen, Last abwerfen oder geschlossen fehlschlagen sollen.
Sollten benutzerorientierte KI-Anfragen in eine Warteschlange gestellt werden?
Nur kurz. Benutzerorientierte Anfragen benötigen strikte Fristen. Stellen Sie sie in die Warteschlange, bevor die sichtbare Ausgabe beginnt, aber geben Sie einen kontrollierten Fehler zurück, wenn die Wartezeit in der Warteschlange oder das Retry-After des Anbieters die Produktfrist überschreitet.
Wie unterscheidet sich das Einreihen in eine Warteschlange vom Wiederholen?
Wiederholen (Retrying) wiederholt eine Anfrage nach einer begrenzten Verzögerung. Einreihen in eine Warteschlange (Queueing) nimmt Arbeit in eine verwaltete Lane mit Freigabezeit, Eigentümerschaft, maximalem Alter, Idempotenz, Priorität und Wiederholungsregeln auf. Eine gute KI-API-Warteschlangenstrategie verwendet beides, verwechselt sie aber nicht.
Wann sollten in die Warteschlange eingereihte KI-Jobs auf ein anderes Modell zurückfallen?
Nur wenn die Fallback-Route die Endpunktform, das Schema, das Tool-Verhalten, die Datengrenze, die Qualitätsklasse und die Kostenobergrenze beibehält. Wenn der Fallback-Vertrag unbekannt ist, verschieben Sie den Job zur Überprüfung durch den Eigentümer oder lassen Sie ihn geschlossen fehlschlagen.
Was sollte in eine Dead-Letter-Warteschlange kommen?
Jobs, die die Budgets für Versuche oder das Alter der Warteschlange überschreiten, auf Quoten- oder Ausgabenfehler stoßen, Fallback-Verträge verletzen, keine Idempotenz aufweisen oder bereits eine Teilausgabe committet haben, sollten mit genügend Nachweisen für eine sichere manuelle Wiederholung in die Dead-Letter-Warteschlange verschoben werden.
Wie hilft Flatkey bei der KI-API-Warteschlangenstrategie?
Flatkey bietet Teams eine einzige Gateway-Oberfläche für den Zugriff auf verbundene Modelle, Routing, Abrechnung, Nutzungsanalysen und operative Kontrollen. Verwenden Sie es, um Warteschlangenentscheidungen an das angeforderte Modell, das bereitgestellte Modell, den Endpunkttyp, den Besitzerschlüssel, das Routenergebnis und den Nutzungsnachweis zu binden.


