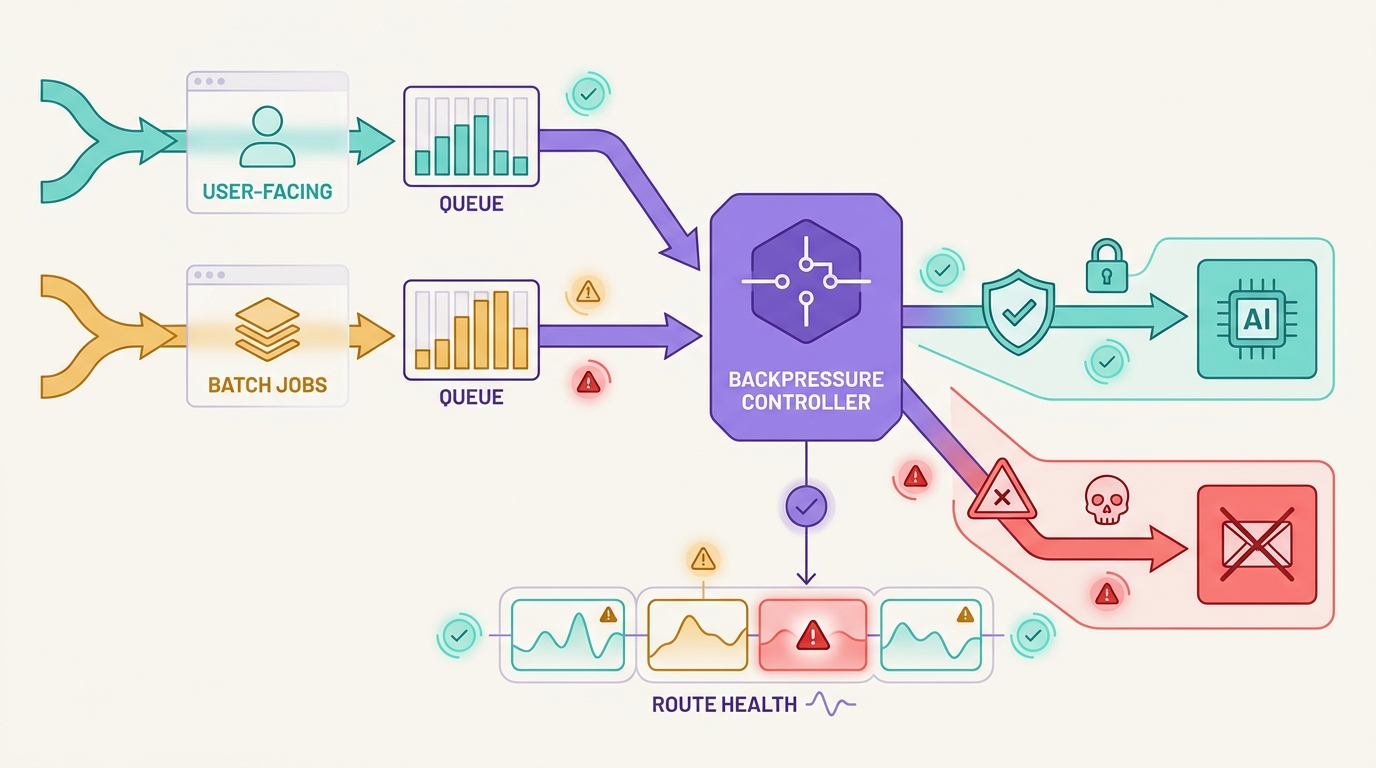
AI API 排队策略不仅仅是一种后台作业模式。在生产 AI 系统中,当模型提供商速度变慢或上游路由不可用时,队列会决定面向用户的工作是应该等待、重试、回退、减载还是直接失败。
危险的模式是将每个失败的请求都放入一个重试队列,并期望容量能够恢复。这虽然可以保护工作进程,但会损害产品:聊天用户等待时间过长,流式会话无法干净地恢复,批处理作业重复昂贵的提示,回退路由在没有足够证据的情况下改变模型行为。
一个好的 AI API 排队策略会在服务中断前就将工作分离开。交互式请求获得较短的预算和明确的停止条件。批处理工作获得幂等性、队列老化限制和重放规则。只有在输出契约仍然有效时才会发生回退。Flatkey 适合这种操作模型,因为团队可以在一个网关界面中保留模型访问、路由、计费、使用分析和操作控制,同时审查当前的模型目录和请求证据。
AI API 排队策略一览表
在决定哪些内容应放入队列,哪些内容应保留在请求路径上时,可将此表作为初步参考。
| 工作流 | 队列决策 | 重试预算 | 回退边界 | 停止条件 |
|---|---|---|---|---|
| 客户聊天(首个 token 前) | 短暂退避或排队几秒钟 | 在用户截止时间内尝试 1 或 2 次 | 仅限于具有相同工具、模式和数据边界的已批准路由 | 当用户截止时间过后,优雅地失败 |
| 客户聊天(token 已流式传输后) | 不自动重放 | 通常没有,因为输出已可见 | 避免在回答中途更改路由 | 以受控错误和请求 ID 结束流 |
| 后台支持摘要 | 排队 | 重试直至达到最大队列老化时间或尝试预算 | 如果模型质量和成本等级获批,则允许 | 当作业过时或非幂等时,进入死信队列 |
| 评估或基准测试作业 | 按模型/提供商密钥排队和节流 | 预算较大,但有界 | 通常不回退,因为结果必须具有可比性 | 当路由更改会使运行失效时停止 |
| 图像或视频生成 | 使用严格幂等性排队 | 由于成本原因,尝试次数较少 | 仅在用户或所有者批准后回退 | 当重复生成会产生高昂成本或用户体验风险时停止 |
| 财务、法律、采购或受监管的审查 | 排队等待所有者审查或直接失败 | 最少 | 仅在明确批准后 | 在数据边界、成本或批准不匹配时直接失败 |
这就是 AI API 排队策略的核心:队列是一个策略层,而不是一个隐藏所有上游问题的地方。
首先对提供商信号进行分类
排队应从错误分类开始。官方提供商文档对类似情况使用不同的术语,因此应用程序在选择操作之前应将其规范化。
OpenAI 将请求调速与配额或计费用尽区分开来。其错误文档描述了因发送请求过快而导致的 429 速率限制错误、单独的 429 配额或计费情况、500 服务器错误、503 过载以及针对流量突然增加的 503 减速情况。OpenAI 的速率限制指南还建议使用随机指数退避,并警告说不成功的请求仍计入每分钟的限制。
Anthropic 的文档记录了跨请求和 token 维度的速率限制,包括 429 响应和 retry-after 指南。其错误文档还将 rate_limit_error 与 overloaded_error 区分开来,其中过载映射到 HTTP 529。这种区分很重要,因为本地队列可以减慢您的流量,但无法通过激进的重试来恢复提供商的容量。
Gemini 故障排除将 429 映射到 RESOURCE_EXHAUSTED,并告知团队在重试前检查是否达到了速率限制、免费套餐限制或每日限制。Gemini 速率限制文档还描述了诸如每分钟请求数、每分钟 token 数、每日请求数和基于支出的限制等维度。
将这些信号规范化为一种内部形态:
| 字段 | 示例值 | 队列用途 |
|---|---|---|
http_status | 429, 500, 503, 529 | 区分调速、服务器故障和过载 |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | 防止将配额和支出问题当作临时问题进行重试 |
retry_after_ms | 从标头派生的延迟或 null | 为排队的工作设置最早的释放时间 |
limit_dimension | 请求、输入 token、输出 token、每日请求、支出 | 告知系统要对什么进行节流 |
route_key | 提供商、模型、端点族、所有者密钥 | 对流量进行分组以实现背压 |
visibility_state | 首个 token 前、部分输出后、仅后台 | 防止对用户可见的工作进行不安全的重放 |
没有这一层,AI API 排队策略就变成了猜测。
将面向用户的通道与批处理通道分开
面向用户的流量和批处理流量不应共享相同的队列策略。它们可以共享基础设施,但需要不同的预算。
交互式工作流应有一个短的准入队列。如果系统无法在产品截止日期内启动请求,应返回一个受控的失败,而不是让用户因提供商长时间中断而等待。等待聊天、编码辅助、搜索或支持分类的用户通常需要立即得到明确的答复,而不是十分钟后才得到成功的响应。
批处理工作流可以等待更长时间,但必须有最大队列存在时间。摘要、提取、丰富、评估和计划性自动化应携带一个 max_queue_age_ms 字段,以便过时的工作可以在业务时机过后过期,而不是重新执行。
最小队列通道包括:
| 通道 | 用途 | 默认所有者问题 |
|---|---|---|
interactive_admission | 尚未开始可见输出的请求 | 在产品应以受控失败方式应答之前,用户可以等待多长时间? |
stream_recovery | 在任何令牌发送前中断的流 | 请求能否在不重复可见输出或工具副作用的情况下重新启动? |
background_retry | 可安全重放的离线作业 | 最大存在时间、最大尝试次数和幂等性密钥是什么? |
owner_review | 因支出、配额、批准或数据边界而受阻的作业 | 谁必须批准重放或回退? |
dead_letter | 已用尽安全重试策略的作业 | 在人工重放之前需要什么证据? |
这种通道设计可以在提供商服务中断期间保护面向用户的工作,因为批处理积压不会在用户试图恢复时消耗所有容量。
使用 Retry-After 作为释放时间
HTTP Retry-After 字段可以是以秒为单位的延迟或是一个 HTTP 日期。队列工作程序不应将其视为在请求处理程序内休眠的理由。应将其转换为就绪时间,存储在作业上,并且仅当提供商提示和工作流预算都允许再次尝试时才释放该作业。
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}这个辅助函数将提供商的指导信息移出热路径。请求处理程序可以返回,队列可以持有作业直到其就绪,而可观测性可以显示系统是否遵守了提供商的等待提示。
先施加反压,再进行回退
回退不是首选的队列排空工具。它会改变工作的某些方面:模型、提供商、成本、延迟、工具行为、上下文窗口、数据边界或输出质量。在服务中断期间,自动回退可以使队列看起来更健康,但同时会悄悄地改变产品行为。
首先施加反压:
- 为受影响的
route_key暂停新的非紧急作业。 - 降低受影响的提供商、模型、端点族、客户或所有者密钥的工作程序并发性。
- 根据
ready_at释放作业,而不仅仅是先进先出 (FIFO)。 - 在低优先级工作阻塞交互式容量之前将其丢弃。
- 仅当合约仍然有效时才进行回退。
这就是 AI API 排队策略与您更广泛的AI API 重试策略相连接的地方。重试处理有界限的尝试。排队吸收需求。反压减慢源头。回退仅在这些控制措施保护了面向用户的路径之后才更改路由。
使服务中断易于调试的队列字段
一个只存储提示和模型的队列很难操作。应添加字段来回答作业为何等待、谁拥有它以及下一步可以安全地做什么。
| 字段 | 必需规则 |
|---|---|
job_id | 用于跟踪和重放的稳定标识符 |
idempotency_key | 源自工作流、用户或所有者、输入哈希和副作用目标 |
workflow | 产品界面,例如聊天、支持摘要、发票审查或评估 |
owner_key | 负责成本和容量的团队、客户、项目或环境 |
route_key | 提供商、模型、端点系列和网关路由 |
requested_model 和 served_model | 显示路由或回退是否改变了行为 |
attempt 和 max_attempts | 防止无限次重试 |
created_at、ready_at、expires_at | 控制队列老化和释放时机 |
retry_after_ms | 保留提供商的等待指导 |
fallback_allowed | 链接到已批准的回退策略,而不是布尔值的猜测 |
partial_output_committed | 阻止对流和工具副作用的不安全重放 |
last_error_type | 在重试后保持提供商错误可见 |
estimated_cost 和 usage_units | 使重复工作对财务和运营人员可见 |
Flatkey 用户应保持这些字段与网关证据一致:请求的模型、服务的模型、端点类型、所有者密钥、使用单位和路由结果。Flatkey 当前的公共网站将该产品定位为用于模型访问、路由、计费、使用分析和运营控制的统一网关。2026 年 7 月 3 日的定价 API 快照返回了 45 个模型行、五个供应商 ID,并支持包括 openai、anthropic、gemini 和 image-generation 在内的端点类型。请将这些事实视为过时证据,然后在更改生产策略之前,在定价页面上验证当前目录。
死信队列需要重放规则
死信队列只有在能防止盲目重放时才有用。一个失败的 AI 作业可能包含一个大的提示、一个工具计划、一个客户操作或一个昂贵的图像/视频请求。在没有上下文的情况下重放它可能会导致重复的副作用或开销。
当出现以下任何一种情况时,创建一个死信记录:
- 作业超出了
max_attempts。 - 作业超出了
max_queue_age_ms。 - 提供商信号指示配额、开销、权限或数据边界故障。
- 回退合同未保留模型能力、工具行为、模式或批准状态。
- 作业不是幂等的或已经提交了部分输出。
在重放前需要以下字段:
| 重放字段 | 重要性 |
|---|---|
replay_owner | 分配成本和客户影响的责任 |
replay_reason | 将提供商恢复与产品错误、配额更改或所有者覆盖区分开 |
route_override | 显示重放是使用相同的模型还是已批准的回退模型 |
idempotency_result | 证明重放不会重复产生外部副作用 |
cost_reviewed | 防止排队的重放变成意外账单 |
一个好的 AI API 排队策略应该让重放变得简单乏味:每次重放都有一个所有者、一个原因、一个路由和一个停止条件。
流式工作流需要不同的边界
流式处理改变了排队决策。在第一个令牌出现之前,请求通常可以重试、短暂排队或回退。在第一个令牌出现之后,重放可能会复制可见的输出、重新运行工具,或在一个答案中拼接两种模型的行为。
使用流边界规则:
| 流状态 | 队列行为 |
|---|---|
| 请求已接受,未发送令牌 | 在短暂的用户截止时间内重试或排队 |
| 已发送第一个令牌,无工具副作用 | 首选使用请求 ID 进行受控的流终止 |
| 已发出工具调用或已开始副作用 | 故障关闭并保留事件证据 |
| 在可见输出前流空闲超时 | 如果幂等性和截止时间允许,则重试 |
| 在部分回答后提供商服务中断 | 不要自动回退到同一个答案中 |
要了解更深入的配套策略,请参阅流式 AI API 可靠性。排队可以保护准入路径,但不应假装部分流式输出与新的后台作业相同。
排队工作的回退合同
只有当合同仍然有效时,排队的作业才能回退。请遵循与模型回退评估清单中相同的原则,然后将批准的合同附加到队列策略中。
| 合约范围 | 必要问题 |
|---|---|
| 端点形态 | 备用方案是否支持相同的聊天、响应、消息、图像、视频或工具调用形态? |
| 输出合约 | 它是否保留了 JSON 模式、工具调用行为、安全处理和流式传输要求? |
| 质量等级 | 备用模型是否已获准用于此工作流? |
| 成本上限 | 备用方案是否会超出触发排队的预算? |
| 数据边界 | 该路由是否保留了提供商、供应商、区域和采购限制? |
| 可观测性 | 日志是否会显示请求的模型、服务的模型、备用原因、队列存在时间和使用情况? |
如果任何答案未知,队列应停止或将作业移交所有者审查。在提供商服务中断期间静默更改路由的队列可能会用一个可见的可靠性问题换来一个隐藏的正确性问题。
一个实用的策略模板
在将队列工作程序接入生产环境之前,先从一个策略文件开始。下面的数字是示例;请根据流量和事件数据进行调整。
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatch此模板使队列策略可供审查。产品、平台、财务和采购团队可以确切地看到哪些工作在等待、哪些工作更改了路由以及哪些工作停止了。
上线清单
在向生产路由添加队列控制时,请使用此 AI API 排队策略清单:
- 选择一个工作流并指定产品负责人。
- 定义用户截止时间和后台最大队列存在时间。
- 将提供商错误规范化为一种内部队列决策形态。
- 将
Retry-After解析为ready_at。 - 在启用重放之前添加幂等性密钥。
- 拆分交互式、后台、所有者审查和死信通道。
- 在启用备用方案之前,按路由密钥应用背压。
- 将备用合约附加到队列策略,而不是工作程序代码。
- 在部分流式输出或产生外部副作用后,阻止自动重放。
- 记录队列存在时间、尝试次数、备用原因、请求的模型、服务的模型、使用单位和估算成本。
- 测试 429、503、529、网络超时、配额耗尽、长
Retry-After和部分流式传输失败。 - 在将策略扩展到下一个工作流之前,审查 Flatkey 使用情况和路由证据。
最佳的 AI API 排队策略可以降低服务中断的戏剧性。用户可以获得明确的截止时间。批处理工作在等待时不会重复产生费用。备用方案保持在已批准的合约范围内。操作员可以获得证据,而不是积压的神秘作业。
从当前的 Flatkey 定价和模型目录开始,选择一个工作流,然后获取密钥,并在通过它发送生产流量之前测试您的 AI API 排队策略。
常见问题解答
什么是 AI API 排队策略?
AI API 排队策略是一种策略,用于决定在遇到速率限制、过载、服务中断和提供商错误时,模型请求是应该重试、在队列中等待、回退到另一个已批准的路由、减载还是快速失败。
面向用户的 AI 请求应该进入队列吗?
只能短暂进入。面向用户的请求需要严格的截止时间。在可见输出开始前排队,但当队列等待时间或提供商的 Retry-After 超过产品截止时间时,返回一个受控的失败。
排队与重试有何不同?
重试是在有限的延迟后重复一个请求。排队是将工作接纳到一个受管理的通道中,该通道具有发布时间、所有权、最大存在时间、幂等性、优先级和重放规则。一个好的 AI API 排队策略会同时使用两者,但不会混淆它们。
排队的 AI 作业何时应回退到另一个模型?
仅当备用路由保留了端点形态、模式、工具行为、数据边界、质量等级和成本上限时。如果备用合约未知,则将作业移交所有者审查或快速失败。
什么应该进入死信队列?
超出尝试次数或队列存在时间预算、遇到配额或支出失败、违反备用合约、缺乏幂等性或已提交部分输出的作业,应移至死信队列,并附有足够证据以供安全手动重放。
Flatkey 如何帮助制定 AI API 排队策略?
Flatkey 为团队提供了一个统一的网关界面,用于连接模型访问、路由、计费、使用情况分析和操作控制。使用它,可以将排队决策与请求的模型、服务的模型、端点类型、所有者密钥、路由结果和使用证据关联起来。


