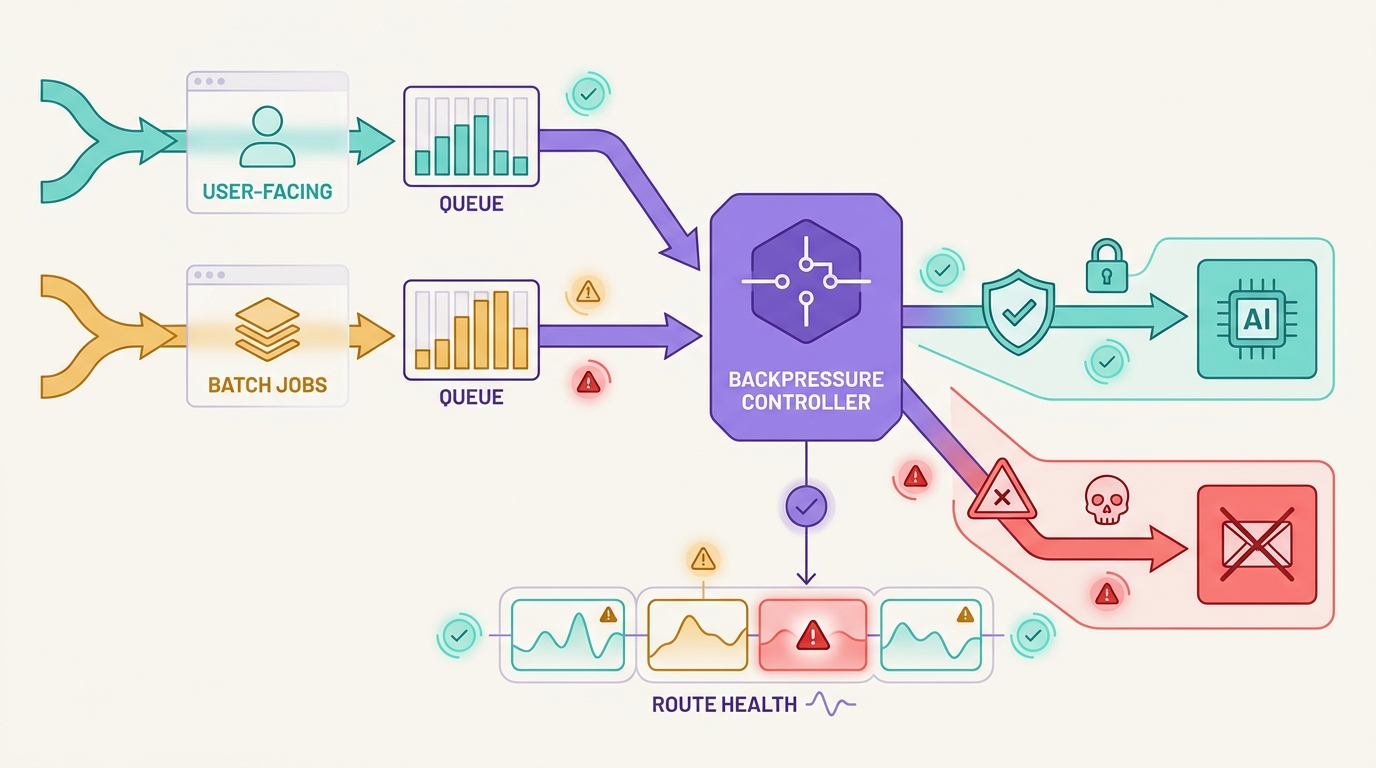
Una estrategia de colas para API de IA no es solo un patrón de trabajos en segundo plano. En los sistemas de IA en producción, la cola decide si el trabajo de cara al usuario debe esperar, reintentar, recurrir a una alternativa, reducir la carga o fallar en estado cerrado cuando un proveedor de modelos se ralentiza o una ruta ascendente deja de estar disponible.
El patrón peligroso es poner cada solicitud fallida en una única cola de reintentos y esperar que la capacidad se restablezca. Eso puede proteger un proceso de trabajo mientras perjudica al producto: los usuarios del chat esperan demasiado, las sesiones de streaming no pueden reanudarse limpiamente, los trabajos por lotes duplican prompts costosos y las rutas alternativas cambian el comportamiento del modelo sin suficiente evidencia.
Una buena estrategia de colas para API de IA separa el trabajo antes de la interrupción. Las solicitudes interactivas obtienen presupuestos cortos y condiciones de detención claras. El trabajo por lotes obtiene idempotencia, límites de antigüedad en la cola y reglas de repetición. La alternativa solo se activa cuando el contrato de salida sigue siendo válido. Flatkey se ajusta a este modelo operativo porque los equipos pueden mantener el acceso al modelo, el enrutamiento, la facturación, los análisis de uso y los controles operativos en una única superficie de puerta de enlace mientras revisan el catálogo de modelos actual y la evidencia de las solicitudes.
Estrategia de colas para API de IA en una tabla
Usa esta tabla como una primera aproximación cuando decidas qué pertenece a una cola y qué debe permanecer en la ruta de la solicitud.
| Flujo de trabajo | Decisión de la cola | Presupuesto de reintentos | Límite de la alternativa | Condición de detención |
|---|---|---|---|---|
| Chat con el cliente antes del primer token | Backoff corto o cola durante unos segundos | 1 o 2 intentos dentro del plazo del usuario | Solo a una ruta aprobada con las mismas herramientas, esquema y límite de datos | Fallar de forma controlada cuando se agote el plazo del usuario |
| Chat con el cliente después de transmitir tokens | No repetir automáticamente | Generalmente ninguno, porque la salida ya es visible | Evitar cambios de ruta a mitad de la respuesta | Terminar el stream con un error controlado y un ID de solicitud |
| Resumen de soporte en segundo plano | Poner en cola | Reintentar hasta la antigüedad máxima de la cola o el presupuesto de intentos | Permitido si la calidad del modelo y la clase de costo están aprobados | Enviar a la cola de mensajes fallidos (dead-letter) cuando el trabajo esté obsoleto o no sea idempotente |
| Trabajo de evaluación o benchmark | Poner en cola y limitar por clave de modelo/proveedor | Presupuesto mayor, pero acotado | Generalmente sin alternativa, porque los resultados deben ser comparables | Detener cuando los cambios de ruta invalidarían la ejecución |
| Generación de imágenes o video | Poner en cola con idempotencia estricta | Número reducido de intentos debido al costo | Alternativa solo después de la aprobación del usuario o propietario | Detener cuando la generación duplicada crearía un riesgo de costo o de experiencia de usuario (UX) |
| Revisión financiera, legal, de adquisiciones o regulada | Poner en cola para revisión del propietario o fallar en estado cerrado | Mínimo | Solo con aprobación explícita | Fallar en estado cerrado por discrepancia en el límite de datos, costo o aprobación |
Este es el núcleo de una estrategia de colas para API de IA: la cola es una capa de políticas, no un lugar para ocultar todos los problemas ascendentes.
Clasifica primero la señal del proveedor
La puesta en cola debe comenzar con la clasificación de errores. Los documentos oficiales de los proveedores utilizan diferentes términos para condiciones similares, por lo que la aplicación debe normalizarlos antes de elegir una acción.
OpenAI separa la regulación del ritmo de las solicitudes del agotamiento de la cuota o la facturación. Sus documentos de errores describen errores de límite de velocidad 429 por enviar solicitudes demasiado rápido, casos separados de cuota o facturación 429, errores de servidor 500, sobrecarga 503 y una condición de ralentización 503 por aumentos repentinos de tráfico. La guía de límites de velocidad de OpenAI también recomienda un backoff exponencial aleatorio y advierte que las solicitudes no exitosas siguen contando para los límites por minuto.
Anthropic documenta los límites de velocidad en las dimensiones de solicitudes y tokens, con respuestas 429 y orientación en retry-after. Sus documentos de errores también separan rate_limit_error de overloaded_error, donde la sobrecarga se corresponde con HTTP 529. Esa distinción es importante porque una cola local puede ralentizar tu tráfico, pero no puede restaurar la capacidad del proveedor reintentando agresivamente.
La solución de problemas de Gemini asigna el código 429 a RESOURCE_EXHAUSTED e indica a los equipos que verifiquen si alcanzaron los límites de velocidad, los límites del nivel gratuito o los límites diarios antes de reintentar. Los documentos de límites de velocidad de Gemini también describen dimensiones como solicitudes por minuto, tokens por minuto, solicitudes por día y límites basados en el gasto.
Normaliza esas señales en una única forma interna:
| Campo | Valores de ejemplo | Uso en la cola |
|---|---|---|
http_status | 429, 500, 503, 529 | Separa la regulación del ritmo, el fallo del servidor y la sobrecarga |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | Evita reintentar problemas de cuota y gasto como si fueran temporales |
retry_after_ms | Retraso derivado de la cabecera o nulo | Establece el tiempo de liberación más temprano para el trabajo en cola |
limit_dimension | solicitudes, tokens de entrada, tokens de salida, solicitudes diarias, gasto | Indica al sistema qué debe limitar |
route_key | proveedor, modelo, familia de endpoints, clave de propietario | Agrupa el tráfico para la contrapresión (backpressure) |
visibility_state | antes del primer token, después de la salida parcial, solo en segundo plano | Evita la repetición insegura del trabajo visible para el usuario |
Sin esta capa, una estrategia de colas para API de IA se convierte en una conjetura.
Separa las vías de cara al usuario de las vías por lotes
El tráfico de cara al usuario y el tráfico por lotes no deben compartir la misma política de cola. Pueden compartir infraestructura, pero necesitan presupuestos diferentes.
Los flujos de trabajo interactivos deben tener una cola de admisión corta. Si el sistema no puede iniciar la solicitud dentro del plazo del producto, devuelve un fallo controlado en lugar de retener al usuario detrás de una larga interrupción del proveedor. Un usuario que espera un chat, asistencia de codificación, búsqueda o clasificación de soporte generalmente necesita una respuesta clara ahora, no una respuesta exitosa diez minutos después.
Los flujos de trabajo por lotes pueden esperar más tiempo, pero solo con una antigüedad máxima de cola. La sumarización, extracción, enriquecimiento, evaluaciones y automatizaciones programadas deben llevar un campo max_queue_age_ms para que el trabajo obsoleto pueda expirar en lugar de reintentarse después de que haya pasado el momento de negocio.
Los carriles de cola mínimos son:
| Carril | Úsalo para | Pregunta predeterminada del propietario |
|---|---|---|
interactive_admission | Solicitudes que no han iniciado una salida visible | ¿Cuánto tiempo puede esperar el usuario antes de que el producto deba responder con un fallo controlado? |
stream_recovery | Flujos que se interrumpieron antes de que se enviara ningún token | ¿Puede reiniciarse la solicitud sin duplicar la salida visible ni los efectos secundarios de la herramienta? |
background_retry | Trabajos sin conexión que son seguros de reintentar | ¿Cuál es la antigüedad máxima, el número máximo de intentos y la clave de idempotencia? |
owner_review | Trabajos bloqueados por gasto, cuota, aprobación o límite de datos | ¿Quién debe aprobar el reintento o la conmutación por error? |
dead_letter | Trabajos que agotaron la política de reintentos seguros | ¿Qué evidencia se requiere antes de que un humano lo reintente? |
Este diseño de carriles protege el trabajo de cara al usuario durante las interrupciones del proveedor porque el trabajo pendiente por lotes no puede consumir toda la capacidad justo cuando los usuarios intentan recuperarse.
Usa Retry-After como tiempo de liberación
El campo HTTP Retry-After puede ser un retraso en segundos o una fecha HTTP. Los trabajadores de la cola no deben tratarlo como una razón para dormir dentro de un manejador de solicitudes. Conviértelo en un tiempo de disponibilidad, guárdalo en el trabajo y libera el trabajo solo cuando tanto la sugerencia del proveedor como el presupuesto del flujo de trabajo permitan otro intento.
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}Este ayudante mantiene la guía del proveedor fuera de la ruta crítica. El manejador de solicitudes puede retornar, la cola puede retener el trabajo hasta que esté listo y la observabilidad puede mostrar si el sistema respetó la sugerencia de espera del proveedor.
La contrapresión viene antes que la conmutación por error
La conmutación por error no es la primera herramienta para vaciar la cola. Cambia algo sobre el trabajo: modelo, proveedor, costo, latencia, comportamiento de la herramienta, ventana de contexto, límite de datos o calidad de la salida. Durante una interrupción, la conmutación por error automática puede hacer que la cola parezca más saludable mientras cambia silenciosamente el comportamiento del producto.
Aplica primero la contrapresión:
- Pausa los nuevos trabajos no urgentes para la
route_keyafectada. - Reduce la concurrencia de los trabajadores para el proveedor, modelo, familia de puntos de conexión, cliente o clave de propietario afectados.
- Libera los trabajos según
ready_at, no solo FIFO. - Descarta el trabajo de baja prioridad antes de que bloquee la capacidad interactiva.
- Realiza la conmutación por error solo cuando el contrato aún se mantiene.
Aquí es donde una estrategia de colas para API de IA se conecta con tu estrategia de reintentos para API de IA más amplia. Los reintentos manejan intentos acotados. Las colas absorben la demanda. La contrapresión ralentiza la fuente. La conmutación por error cambia la ruta solo después de que esos controles hayan protegido la ruta de cara al usuario.
Campos de cola que hacen que las interrupciones sean depurables
Una cola que almacena solo el prompt y el modelo es difícil de operar. Agrega los campos que responden por qué el trabajo está esperando, a quién pertenece y qué es seguro hacer a continuación.
| Campo | Regla requerida |
|---|---|
job_id | Identificador estable para seguimiento y repetición |
idempotency_key | Derivado del flujo de trabajo, usuario o propietario, hash de entrada y objetivo del efecto secundario |
workflow | Superficie del producto como chat, resumen de soporte, revisión de facturas o evaluación |
owner_key | Equipo, cliente, proyecto o entorno responsable del costo y la capacidad |
route_key | Proveedor, modelo, familia de puntos de conexión y ruta de la puerta de enlace |
requested_model y served_model | Muestra si el enrutamiento o la conmutación por error cambiaron el comportamiento |
attempt y max_attempts | Evita reintentos infinitos |
created_at, ready_at, expires_at | Controla la antigüedad de la cola y el momento de la liberación |
retry_after_ms | Conserva la guía de espera del proveedor |
fallback_allowed | Se vincula a una política de conmutación por error aprobada, no a una suposición booleana |
partial_output_committed | Bloquea la repetición insegura de flujos y efectos secundarios de herramientas |
last_error_type | Mantiene visibles los errores del proveedor después de los reintentos |
estimated_cost y usage_units | Hace visible el trabajo duplicado para finanzas y operadores |
Los usuarios de Flatkey deben mantener estos campos alineados con la evidencia de la puerta de enlace: modelo solicitado, modelo servido, tipo de punto de conexión, clave de propietario, unidades de uso y resultado de la ruta. El sitio público actual de Flatkey posiciona el producto como una puerta de enlace única para el acceso a modelos, enrutamiento, facturación, análisis de uso y controles operativos. La instantánea de la API de precios del 3 de julio de 2026 devolvió 45 filas de modelos, cinco ID de proveedores y tipos de puntos de conexión compatibles, incluidos openai, anthropic, gemini e image-generation. Trata esos datos como evidencia desactualizada y luego verifica el catálogo actual en la página de precios antes de cambiar la política de producción.
Las colas de mensajes fallidos necesitan reglas de repetición
Las colas de mensajes fallidos solo son útiles cuando evitan la repetición a ciegas. Un trabajo de IA fallido puede contener un prompt extenso, un plan de herramientas, una acción del cliente o una solicitud de imagen/video costosa. Repetirlo sin contexto puede duplicar los efectos secundarios o el gasto.
Crea un registro de mensaje fallido cuando se cumpla cualquiera de estas condiciones:
- El trabajo excedió
max_attempts. - El trabajo excedió
max_queue_age_ms. - La señal del proveedor indica un fallo de cuota, gasto, permiso o límite de datos.
- El contrato de conmutación por error no preserva la capacidad del modelo, el comportamiento de la herramienta, el esquema o el estado de aprobación.
- El trabajo no es idempotente o ya ha confirmado una salida parcial.
Requiere estos campos antes de la repetición:
| Campo de repetición | Por qué es importante |
|---|---|
replay_owner | Asigna la responsabilidad del costo y el impacto en el cliente |
replay_reason | Separa la recuperación del proveedor de un error del producto, un cambio de cuota o una anulación del propietario |
route_override | Muestra si la repetición utiliza el mismo modelo o una conmutación por error aprobada |
idempotency_result | Prueba que la repetición no duplicará los efectos secundarios externos |
cost_reviewed | Evita que la repetición en cola se convierta en una factura sorpresa |
Una estrategia de colas para API de IA debe hacer que la repetición sea aburrida: cada repetición tiene un propietario, una razón, una ruta y una condición de detención.
Los flujos de trabajo de streaming necesitan un límite diferente
El streaming cambia la decisión de la cola. Antes del primer token, la solicitud a menudo puede reintentarse, ponerse en cola brevemente o conmutar por error. Después del primer token, la repetición puede duplicar la salida visible, volver a ejecutar herramientas o unir dos comportamientos de modelo en una sola respuesta.
Usa una regla de límite de flujo:
| Estado del flujo | Comportamiento de la cola |
|---|---|
| Solicitud aceptada, no se ha enviado ningún token | Reintentar o poner en cola dentro de un plazo de usuario corto |
| Primer token enviado, sin efecto secundario de la herramienta | Preferir la terminación controlada del flujo con el ID de la solicitud |
| Llamada a la herramienta emitida o efecto secundario iniciado | Fallo cerrado y conservar la evidencia del incidente |
| Tiempo de espera de inactividad del flujo antes de la salida visible | Reintentar si la idempotencia y el plazo lo permiten |
| Interrupción del proveedor después de una respuesta parcial | No conmutar por error automáticamente a la misma respuesta |
Para una política complementaria más detallada, consulta fiabilidad de la API de IA de streaming. El encolamiento puede proteger la ruta de admisión, pero no debe pretender que la salida parcial de streaming es lo mismo que un trabajo en segundo plano nuevo.
Contratos de conmutación por error para trabajos en cola
Un trabajo en cola solo puede conmutar por error cuando el contrato sigue siendo válido. Usa la misma disciplina que usarías en una lista de verificación para la evaluación de la conmutación por error de modelos, y luego adjunta el contrato aprobado a la política de la cola.
| Área del contrato | Pregunta requerida |
|---|---|
| Forma del endpoint | ¿El respaldo es compatible con la misma forma de chat, respuestas, mensajes, imagen, video o llamada a herramientas? |
| Contrato de salida | ¿Conserva el esquema JSON, el comportamiento de llamada a herramientas, el manejo de la seguridad y los requisitos de transmisión? |
| Clase de calidad | ¿Está aprobado el modelo de respaldo para este flujo de trabajo? |
| Límite de costo | ¿Podría el respaldo exceder el presupuesto que activó la puesta en cola? |
| Límite de datos | ¿La ruta conserva las restricciones de proveedor, vendedor, región y adquisición? |
| Observabilidad | ¿Los registros mostrarán el modelo solicitado, el modelo servido, el motivo del respaldo, la antigüedad en la cola y el uso? |
Si alguna respuesta es desconocida, la cola debe detenerse o mover el trabajo a revisión del propietario. Una cola que cambia de ruta silenciosamente durante una interrupción del proveedor puede cambiar un problema de fiabilidad visible por un problema de corrección oculto.
Una plantilla de política práctica
Comienza con un archivo de políticas antes de conectar los trabajadores de la cola a producción. Los números a continuación son ejemplos; ajústalos con datos de tráfico e incidentes.
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatchEsta plantilla hace que la política de colas sea revisable. Los equipos de producto, plataforma, finanzas y adquisiciones pueden ver exactamente qué trabajo espera, qué trabajo cambia de ruta y qué trabajo se detiene.
Lista de verificación para el despliegue
Utiliza esta lista de verificación de la estrategia de colas para API de IA cuando agregues controles de cola a una ruta de producción:
- Elige un flujo de trabajo y nombra al propietario del producto.
- Define el plazo del usuario y la antigüedad máxima de la cola en segundo plano.
- Normaliza los errores del proveedor en una única forma de decisión de cola interna.
- Analiza
Retry-Afterenready_at. - Agrega claves de idempotencia antes de habilitar la repetición.
- Divide los carriles interactivos, en segundo plano, de revisión del propietario y de mensajes fallidos (dead-letter).
- Aplica contrapresión por clave de ruta antes de habilitar el respaldo.
- Adjunta los contratos de respaldo a las políticas de la cola, no al código del trabajador.
- Bloquea la repetición automática después de una salida de transmisión parcial o efectos secundarios externos.
- Registra la antigüedad de la cola, el recuento de intentos, el motivo del respaldo, el modelo solicitado, el modelo servido, las unidades de uso y el costo estimado.
- Prueba los fallos 429, 503, 529, tiempo de espera de la red, agotamiento de la cuota,
Retry-Afterlargos y fallos de transmisión parcial. - Revisa el uso de Flatkey y la evidencia de la ruta antes de expandir la política al siguiente flujo de trabajo.
La mejor estrategia de colas para API de IA hace que las interrupciones sean menos dramáticas. Los usuarios obtienen plazos claros. El trabajo por lotes espera sin duplicar costos. Los respaldos se mantienen dentro de los contratos aprobados. Los operadores obtienen evidencia en lugar de una acumulación de trabajos misteriosos.
Comienza con los precios y el catálogo de modelos actuales de Flatkey, elige un flujo de trabajo, luego obtén una clave y prueba tu estrategia de colas para API de IA antes de enviar tráfico de producción a través de ella.
Preguntas frecuentes
¿Qué es una estrategia de colas para API de IA?
Una estrategia de colas para API de IA es la política que decide si las solicitudes de modelos deben reintentarse, esperar en una cola, recurrir a otra ruta aprobada, desechar la carga o fallar en estado cerrado durante límites de velocidad, sobrecargas, interrupciones y errores del proveedor.
¿Deberían las solicitudes de IA de cara al usuario entrar en una cola?
Solo brevemente. Las solicitudes de cara al usuario necesitan plazos estrictos. Pon en cola antes de que comience la salida visible, pero devuelve un fallo controlado cuando la espera en la cola o el Retry-After del proveedor exceda el plazo del producto.
¿En qué se diferencia la puesta en cola de los reintentos?
Reintentar repite una solicitud después de un retraso acotado. La puesta en cola admite trabajo en un carril gestionado con tiempo de liberación, propiedad, antigüedad máxima, idempotencia, prioridad y reglas de repetición. Una buena estrategia de colas para API de IA utiliza ambos, pero no los confunde.
¿Cuándo deberían los trabajos de IA en cola recurrir a otro modelo?
Solo cuando la ruta de respaldo conserva la forma del endpoint, el esquema, el comportamiento de la herramienta, el límite de datos, la clase de calidad y el límite de costo. Si el contrato de respaldo es desconocido, mueve el trabajo a revisión del propietario o falla en estado cerrado.
¿Qué debería ir a una cola de mensajes fallidos (dead-letter)?
Los trabajos que exceden los presupuestos de intentos o de antigüedad en la cola, alcanzan fallos de cuota o de gasto, violan contratos de respaldo, carecen de idempotencia o ya han confirmado una salida parcial deben moverse a la cola de mensajes fallidos con suficiente evidencia para una repetición manual segura.
¿Cómo ayuda Flatkey con la estrategia de colas para API de IA?
Flatkey ofrece a los equipos una única puerta de enlace para el acceso a modelos conectados, el enrutamiento, la facturación, el análisis de uso y los controles operativos. Utilízala para mantener las decisiones de la cola vinculadas al modelo solicitado, el modelo servido, el tipo de punto final, la clave de propietario, el resultado de la ruta y la evidencia de uso.


