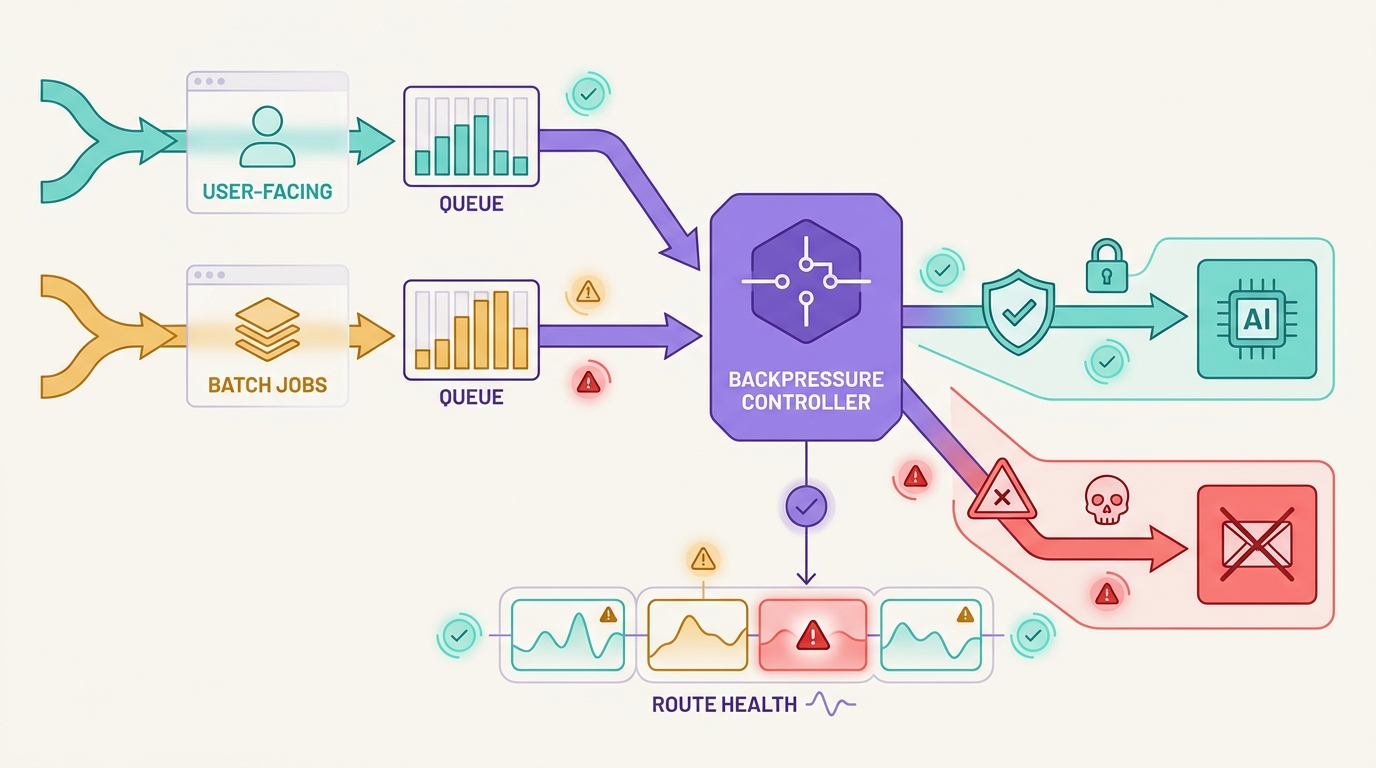
Стратегия организации очередей для AI API — это не просто шаблон для фоновых задач. В производственных системах ИИ очередь определяет, следует ли пользовательским задачам ожидать, повторять попытку, переключаться на резервный вариант, сбрасывать нагрузку или завершаться с ошибкой, когда провайдер модели замедляется или вышестоящий маршрут становится недоступным.
Опасный шаблон — помещать каждый неудачный запрос в одну очередь повторных попыток и надеяться на восстановление мощностей. Это может защитить рабочий процесс, но навредить продукту: пользователи чата ждут слишком долго, потоковые сессии не могут чисто возобновиться, пакетные задания дублируют дорогостоящие промпты, а резервные маршруты изменяют поведение модели без достаточных оснований.
Хорошая стратегия организации очередей для AI API разделяет работу до сбоя. Интерактивные запросы получают короткие бюджеты и четкие условия остановки. Пакетная работа получает идемпотентность, ограничения по возрасту очереди и правила повторного выполнения. Переключение на резервный вариант происходит только тогда, когда контракт вывода все еще соблюдается. Flatkey подходит для этой операционной модели, потому что команды могут управлять доступом к моделям, маршрутизацией, биллингом, аналитикой использования и операционным контролем в едином интерфейсе шлюза, одновременно просматривая текущий каталог моделей и данные запросов.
Стратегия организации очередей для AI API в одной таблице
Используйте эту таблицу для первоначальной оценки при решении, что следует помещать в очередь, а что должно оставаться на пути запроса.
| Рабочий процесс | Решение по очереди | Бюджет повторных попыток | Граница резервного переключения | Условие остановки |
|---|---|---|---|---|
| Чат с клиентом до первого токена | Короткая пауза или очередь на несколько секунд | 1 или 2 попытки в пределах дедлайна пользователя | Только на утвержденный маршрут с теми же инструментами, схемой и границами данных | Корректное завершение с ошибкой по истечении дедлайна пользователя |
| Чат с клиентом после начала потоковой передачи токенов | Не повторять автоматически | Обычно нет, так как вывод уже виден | Избегать смены маршрута в середине ответа | Завершить поток с контролируемой ошибкой и ID запроса |
| Суммаризация для поддержки в фоновом режиме | В очередь | Повторять до максимального возраста очереди или исчерпания бюджета попыток | Разрешено, если качество модели и класс затрат утверждены | В очередь „мертвых писем“, когда задача устарела или неидемпотентна |
| Задача оценки или бенчмаркинга | В очередь и регулировать по ключу модели/провайдера | Больший бюджет, но ограниченный | Обычно без резервного переключения, так как результаты должны быть сопоставимы | Остановить, если изменения маршрута сделают запуск недействительным |
| Генерация изображений или видео | В очередь со строгой идемпотентностью | Малое количество попыток из-за стоимости | Резервное переключение только после одобрения пользователя или владельца | Остановить, если дублирование генерации создаст риск затрат или ухудшения UX |
| Финансовый, юридический, закупочный или регуляторный обзор | В очередь для проверки владельцем или завершение с ошибкой | Минимальный | Только с явного одобрения | Завершение с ошибкой при несоответствии границ данных, затрат или одобрения |
В этом и заключается суть стратегии организации очередей для AI API: очередь — это уровень политик, а не место, где можно скрыть все проблемы вышестоящих систем.
Сначала классифицируйте сигнал от провайдера
Организация очереди должна начинаться с классификации ошибок. В официальной документации провайдеров используются разные термины для схожих состояний, поэтому приложение должно нормализовать их, прежде чем выбирать действие.
OpenAI разделяет регулирование скорости запросов и исчерпание квот или биллинга. В документации по ошибкам описываются ошибки 429 (rate-limit) за слишком быструю отправку запросов, отдельные случаи 429 для квот или биллинга, ошибки сервера 500, перегрузка 503 и состояние замедления 503 при резком увеличении трафика. Руководство OpenAI по ограничению скорости также рекомендует случайную экспоненциальную выдержку и предупреждает, что неудачные запросы все равно учитываются в поминутных лимитах.
Anthropic документирует ограничения скорости по количеству запросов и токенов, с ответами 429 и рекомендациями в retry-after. В документации по ошибкам также разделяются rate_limit_error и overloaded_error, где перегрузка соответствует HTTP 529. Это различие важно, потому что локальная очередь может замедлить ваш трафик, но не может восстановить мощности провайдера агрессивными повторными попытками.
В руководстве по устранению неполадок Gemini код 429 сопоставляется с RESOURCE_EXHAUSTED и рекомендуется командам проверять, достигли ли они лимитов скорости, лимитов бесплатного уровня или дневных лимитов, прежде чем повторять попытку. В документации Gemini по ограничению скорости также описываются такие параметры, как запросы в минуту, токены в минуту, запросы в день и лимиты на основе расходов.
Нормализуйте эти сигналы в единую внутреннюю структуру:
| Поле | Примеры значений | Использование в очереди |
|---|---|---|
http_status | 429, 500, 503, 529 | Разделяет регулирование скорости, сбой сервера и перегрузку |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | Предотвращает повторные попытки при проблемах с квотами и расходами, как если бы они были временными |
retry_after_ms | Задержка из заголовка или null | Устанавливает самое раннее время выпуска для задач в очереди |
limit_dimension | запросы, входные токены, выходные токены, дневные запросы, расходы | Указывает системе, что именно нужно регулировать |
route_key | провайдер, модель, семейство эндпоинтов, ключ владельца | Группирует трафик для противодавления |
visibility_state | до первого токена, после частичного вывода, только фоновый режим | Предотвращает небезопасное повторное выполнение видимых пользователю задач |
Без этого слоя стратегия организации очередей для AI API превращается в гадание.
Разделяйте каналы для пользовательских и пакетных задач
Пользовательский трафик и пакетный трафик не должны использовать одну и ту же политику очереди. Они могут использовать общую инфраструктуру, но им нужны разные бюджеты.
Интерактивные рабочие процессы должны иметь короткую очередь приема. Если система не может начать обработку запроса в установленный для продукта срок, лучше вернуть контролируемый сбой, чем заставлять пользователя ждать из-за длительного сбоя у провайдера. Пользователь, ожидающий ответа в чате, помощи в написании кода, результатов поиска или сортировки запросов в техподдержку, обычно нуждается в четком ответе немедленно, а не в успешном ответе через десять минут.
Пакетные рабочие процессы могут ожидать дольше, но только с указанием максимального возраста в очереди. Задачи по созданию сводок, извлечению данных, обогащению, оценке и запланированные автоматизации должны содержать поле max_queue_age_ms, чтобы устаревшая работа могла быть отменена, а не выполнялась повторно после того, как бизнес-момент упущен.
Минимальный набор каналов очереди:
| Канал | Использование | Вопрос владельцу по умолчанию |
|---|---|---|
interactive_admission | Запросы, для которых еще не начался видимый вывод | Как долго пользователь может ждать, прежде чем продукт должен ответить контролируемым сбоем? |
stream_recovery | Потоки, которые прервались до отправки первого токена | Можно ли перезапустить запрос без дублирования видимого вывода или побочных эффектов инструментов? |
background_retry | Офлайн-задачи, которые безопасно выполнять повторно | Каковы максимальный возраст, максимальное количество попыток и ключ идемпотентности? |
owner_review | Задачи, заблокированные из-за расходов, квоты, необходимости утверждения или границ данных | Кто должен одобрить повторное выполнение или переход на резервный вариант? |
dead_letter | Задачи, исчерпавшие политику безопасных повторных попыток | Какие доказательства требуются, прежде чем человек выполнит задачу повторно? |
Такая структура каналов защищает работу, видимую пользователям, во время сбоев у провайдера, поскольку накопившиеся пакетные задачи не могут занять всю доступную мощность как раз в тот момент, когда пользователи пытаются восстановить работу.
Используйте Retry-After как время для возобновления
Поле HTTP Retry-After может содержать задержку в секундах или дату в формате HTTP. Обработчики очереди не должны воспринимать его как причину для ожидания (sleep) внутри обработчика запроса. Его следует преобразовать во время готовности, сохранить в задаче и возобновлять выполнение задачи только тогда, когда и подсказка от провайдера, и бюджет рабочего процесса позволяют сделать еще одну попытку.
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}Эта вспомогательная функция выносит рекомендации провайдера за пределы критического пути выполнения. Обработчик запроса может завершить работу, очередь может удерживать задачу до тех пор, пока она не будет готова, а системы наблюдаемости могут показать, учла ли система подсказку провайдера о времени ожидания.
Противодавление предшествует переходу на резервный вариант
Переход на резервный вариант (fallback) — это не первый инструмент для разгрузки очереди. Он изменяет что-то в самой работе: модель, провайдера, стоимость, задержку, поведение инструмента, контекстное окно, границы данных или качество вывода. Во время сбоя автоматический переход на резервный вариант может создать видимость нормальной работы очереди, незаметно изменяя при этом поведение продукта.
Сначала примените противодавление:
- Приостановите новые несрочные задачи для затронутого
route_key. - Снизьте параллелизм обработчиков для затронутого провайдера, модели, семейства конечных точек, клиента или ключа владельца.
- Возобновляйте выполнение задач в соответствии с
ready_at, а не только по принципу FIFO. - Отбрасывайте низкоприоритетную работу до того, как она заблокирует ресурсы для интерактивных задач.
- Переходите на резервный вариант только тогда, когда контракт все еще соблюдается.
Именно здесь стратегия организации очередей для AI API связывается с вашей более общей стратегией повторных попыток для AI API. Повторные попытки управляют ограниченным числом попыток. Очереди поглощают спрос. Противодавление замедляет источник. Переход на резервный вариант изменяет маршрут только после того, как эти механизмы контроля защитили путь, видимый пользователю.
Поля очереди, которые упрощают отладку сбоев
Очередью, которая хранит только промпт и модель, сложно управлять. Добавьте поля, которые отвечают на вопросы, почему задача ожидает, кто ее владелец и что безопасно делать дальше.
| Поле | Обязательное правило |
|---|---|
job_id | Стабильный идентификатор для отслеживания и повторного выполнения |
idempotency_key | Формируется из рабочего процесса, пользователя или владельца, хеша входных данных и цели побочного эффекта |
workflow | Область продукта, например чат, сводка по поддержке, проверка счета или оценка |
owner_key | Команда, клиент, проект или среда, ответственные за затраты и ресурсы |
route_key | Провайдер, модель, семейство конечных точек и маршрут шлюза |
requested_model и served_model | Показывает, изменилось ли поведение из-за маршрутизации или резервного переключения |
attempt и max_attempts | Предотвращает бесконечные повторные попытки |
created_at, ready_at, expires_at | Контролирует возраст очереди и время выпуска |
retry_after_ms | Сохраняет рекомендации провайдера по ожиданию |
fallback_allowed | Ссылается на утвержденную политику резервного переключения, а не на логическое предположение |
partial_output_committed | Блокирует небезопасное повторное выполнение потоков и побочных эффектов инструментов |
last_error_type | Сохраняет видимость ошибок провайдера после повторных попыток |
estimated_cost и usage_units | Делает дублирующуюся работу видимой для финансового отдела и операторов |
Пользователям Flatkey следует поддерживать соответствие этих полей с данными шлюза: запрашиваемая модель, обслуживаемая модель, тип конечной точки, ключ владельца, единицы использования и результат маршрутизации. Текущий публичный сайт Flatkey позиционирует продукт как единый шлюз для доступа к моделям, маршрутизации, биллинга, аналитики использования и операционного контроля. Снимок API цен от 3 июля 2026 года вернул 45 строк моделей, пять идентификаторов поставщиков и поддерживаемые типы конечных точек, включая openai, anthropic, gemini и image-generation. Рассматривайте эти факты как устаревшие данные, а затем проверьте текущий каталог на странице цен, прежде чем изменять производственную политику.
Очереди недоставленных сообщений требуют правил повторного выполнения
Очереди недоставленных сообщений полезны только тогда, когда они предотвращают слепое повторное выполнение. Неудачное задание ИИ может содержать большой промпт, план использования инструмента, действие клиента или дорогостоящий запрос на изображение/видео. Повторное выполнение без контекста может привести к дублированию побочных эффектов или затрат.
Создавайте запись в очереди недоставленных сообщений при возникновении любого из следующих условий:
- Задание превысило
max_attempts. - Задание превысило
max_queue_age_ms. - Сигнал от провайдера указывает на сбой, связанный с квотой, расходами, разрешениями или границами данных.
- Контракт резервного переключения не сохраняет возможности модели, поведение инструмента, схему или статус утверждения.
- Задание не является идемпотентным или уже зафиксировало частичный вывод.
Требуйте наличия этих полей перед повторным выполнением:
| Поле повторного выполнения | Почему это важно |
|---|---|
replay_owner | Назначает ответственность за затраты и влияние на клиента |
replay_reason | Отделяет восстановление после сбоя провайдера от ошибки продукта, изменения квоты или переопределения владельцем |
route_override | Показывает, используется ли при повторном выполнении та же модель или утвержденный резервный вариант |
idempotency_result | Доказывает, что повторное выполнение не приведет к дублированию внешних побочных эффектов |
cost_reviewed | Предотвращает превращение повторного выполнения из очереди в неожиданный счет |
Стратегия организации очередей для AI API должна делать повторное выполнение предсказуемым: у каждого повторного выполнения есть владелец, причина, маршрут и условие остановки.
Потоковые рабочие процессы требуют другой границы
Потоковая передача меняет решение об очередности. До первого токена запрос часто можно повторить, ненадолго поставить в очередь или переключиться на резервный вариант. После первого токена повторное выполнение может дублировать видимый вывод, перезапускать инструменты или объединять поведение двух моделей в одном ответе.
Используйте правило границы потока:
| Состояние потока | Поведение очереди |
|---|---|
| Запрос принят, токен не отправлен | Повторить или поставить в очередь в рамках короткого пользовательского дедлайна |
| Первый токен отправлен, побочного эффекта от инструмента нет | Предпочтительно контролируемое завершение потока с идентификатором запроса |
| Вызов инструмента выполнен или начался побочный эффект | Завершить с ошибкой (fail closed) и сохранить данные об инциденте |
| Тайм-аут простоя потока до появления видимого вывода | Повторить, если позволяют идемпотентность и дедлайн |
| Сбой провайдера после частичного ответа | Не выполнять автоматическое резервное переключение в рамках того же ответа |
Для более подробной сопутствующей политики используйте статью о надежности потоковых AI API. Организация очередей может защитить путь приема запросов, но не следует делать вид, что частичный потоковый вывод — это то же самое, что новое фоновое задание.
Контракты резервного переключения для работы в очереди
Задание в очереди может переключиться на резервный вариант только в том случае, если контракт все еще действителен. Используйте тот же подход, что и в чек-листе для оценки резервного переключения моделей, а затем прикрепите утвержденный контракт к политике очереди.
| Область контракта | Обязательный вопрос |
|---|---|
| Форма конечной точки | Поддерживает ли резервный вариант ту же форму чата, ответов, сообщений, изображений, видео или вызова инструментов? |
| Контракт на вывод | Сохраняет ли он схему JSON, поведение при вызове инструментов, обработку безопасности и требования к потоковой передаче? |
| Класс качества | Одобрена ли резервная модель для этого рабочего процесса? |
| Ограничение по стоимости | Может ли резервный вариант превысить бюджет, который вызвал постановку в очередь? |
| Граница данных | Сохраняет ли маршрут ограничения по провайдеру, поставщику, региону и закупкам? |
| Наблюдаемость | Будут ли в логах отображаться запрошенная модель, обслуживаемая модель, причина резервного переключения, возраст в очереди и использование? |
Если какой-либо ответ неизвестен, очередь должна остановиться или передать задачу на рассмотрение владельцу. Очередь, которая незаметно меняет маршрут во время сбоя у провайдера, может обменять видимую проблему надежности на скрытую проблему корректности.
Практический шаблон политики
Начните с файла политики, прежде чем подключать обработчики очередей в производственной среде. Приведенные ниже числа являются примерами; настройте их с учетом данных о трафике и инцидентах.
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatchЭтот шаблон делает политику очереди доступной для проверки. Команды продукта, платформы, финансов и закупок могут точно видеть, какая работа ожидает, какая меняет маршрут, а какая останавливается.
Контрольный список для развертывания
Используйте этот контрольный список стратегии организации очередей для AI API при добавлении элементов управления очередью в производственный маршрут:
- Выберите один рабочий процесс и укажите владельца продукта.
- Определите крайний срок для пользователя и максимальный возраст фоновой очереди.
- Нормализуйте ошибки провайдера в единую внутреннюю форму для принятия решений в очереди.
- Разбирайте
Retry-Afterвready_at. - Добавьте ключи идемпотентности перед включением повторного выполнения.
- Разделите потоки на интерактивные, фоновые, для рассмотрения владельцем и для неразрешимых сообщений.
- Примените противодавление по ключу маршрута перед включением резервного переключения.
- Привязывайте контракты резервного переключения к политикам очереди, а не к коду обработчика.
- Блокируйте автоматическое повторное выполнение после частичного потокового вывода или внешних побочных эффектов.
- Логируйте возраст в очереди, количество попыток, причину резервного переключения, запрошенную модель, обслуживаемую модель, единицы использования и предполагаемую стоимость.
- Протестируйте ошибки 429, 503, 529, сетевой тайм-аут, исчерпание квоты, длительный
Retry-Afterи сбои частичной потоковой передачи. - Проверьте использование Flatkey и данные о маршрутах перед расширением политики на следующий рабочий процесс.
Лучшая стратегия организации очередей для AI API делает сбои менее драматичными. Пользователи получают четкие сроки. Пакетная работа ожидает без дублирования затрат. Резервные варианты остаются в рамках утвержденных контрактов. Операторы получают доказательства вместо накопившихся загадочных задач.
Начните с текущих цен и каталога моделей Flatkey, выберите один рабочий процесс, затем получите ключ и протестируйте свою стратегию организации очередей для AI API, прежде чем направлять через нее производственный трафик.
Часто задаваемые вопросы
Что такое стратегия организации очередей для AI API?
Стратегия организации очередей для AI API — это политика, которая определяет, следует ли запросам к модели повторяться, ожидать в очереди, переключаться на другой утвержденный маршрут, сбрасывать нагрузку или завершаться с ошибкой во время ограничений скорости, перегрузок, сбоев и ошибок провайдера.
Должны ли запросы к ИИ, обращенные к пользователю, попадать в очередь?
Только на короткое время. Запросы, обращенные к пользователю, требуют строгих сроков. Ставьте в очередь до начала видимого вывода, но возвращайте контролируемую ошибку, когда ожидание в очереди или Retry-After от провайдера превышает установленный для продукта срок.
Чем организация очереди отличается от повторных попыток?
Повторная попытка — это повторение запроса после ограниченной задержки. Организация очереди — это прием работы в управляемый поток с временем выпуска, владением, максимальным возрастом, идемпотентностью, приоритетом и правилами повторного выполнения. Хорошая стратегия организации очередей для AI API использует оба подхода, но не путает их.
Когда задачи ИИ в очереди должны переключаться на другую модель?
Только когда резервный маршрут сохраняет форму конечной точки, схему, поведение инструментов, границу данных, класс качества и ограничение по стоимости. Если контракт резервного переключения неизвестен, передайте задачу на рассмотрение владельцу или завершите с ошибкой.
Что должно попадать в очередь неразрешимых сообщений?
Задачи, которые превышают бюджеты по количеству попыток или возрасту в очереди, сталкиваются с исчерпанием квоты или лимита затрат, нарушают контракты резервного переключения, не обладают идемпотентностью или уже зафиксировали частичный вывод, должны перемещаться в очередь неразрешимых сообщений с достаточными данными для безопасного ручного повторного выполнения.
Как Flatkey помогает со стратегией организации очередей для AI API?
Flatkey предоставляет командам единый шлюз для доступа к подключенным моделям, маршрутизации, биллинга, аналитики использования и операционного контроля. Используйте его, чтобы решения по организации очереди были привязаны к запрошенной модели, обслуживаемой модели, типу конечной точки, ключу владельца, результату маршрутизации и данным об использовании.


