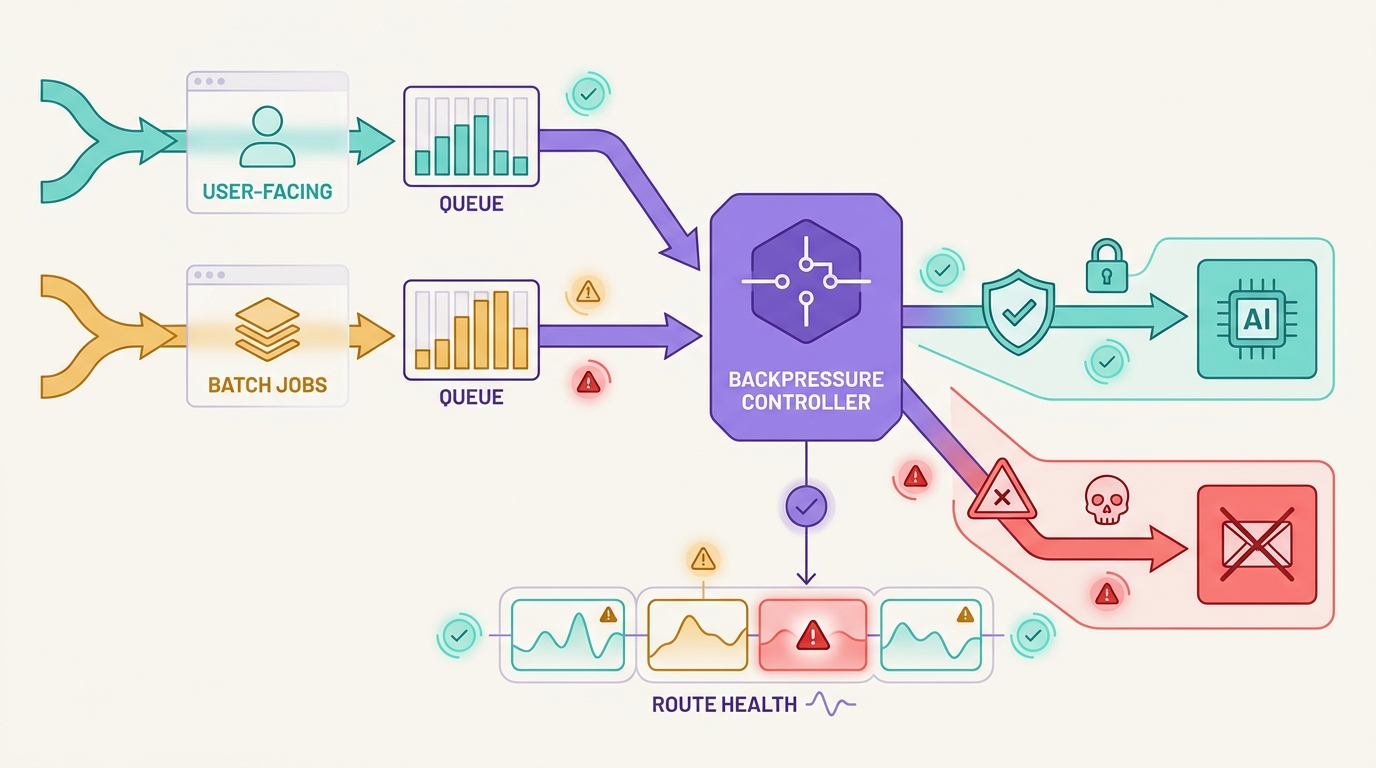
Uma estratégia de queueing para API de IA não é apenas um padrão de trabalho em segundo plano. Em sistemas de IA de produção, a fila decide se o trabalho voltado para o usuário deve esperar, tentar novamente, recorrer a um fallback, descartar carga ou falhar de forma fechada quando um provedor de modelo fica lento ou uma rota upstream se torna indisponível.
O padrão perigoso é colocar todas as solicitações com falha em uma única fila de novas tentativas e esperar que a capacidade retorne. Isso pode proteger um processo de trabalho enquanto prejudica o produto: os usuários de chat esperam demais, as sessões de streaming não podem ser retomadas de forma limpa, os trabalhos em lote duplicam prompts caros e as rotas de fallback alteram o comportamento do modelo sem evidências suficientes.
Uma boa estratégia de queueing para API de IA separa o trabalho antes da interrupção. Solicitações interativas recebem orçamentos curtos e condições de parada claras. O trabalho em lote recebe idempotência, limites de idade da fila e regras de repetição. O fallback só acontece quando o contrato de saída ainda é válido. O Flatkey se encaixa nesse modelo operacional porque as equipes podem manter o acesso ao modelo, roteamento, faturamento, análise de uso e controles operacionais em uma única superfície de gateway enquanto revisam o catálogo de modelos atual e as evidências de solicitação.
Estratégia de queueing para API de IA em uma tabela
Use esta tabela como uma primeira análise ao decidir o que pertence a uma fila e o que deve permanecer no caminho da solicitação.
| Fluxo de trabalho | Decisão da fila | Orçamento de nova tentativa | Limite de fallback | Condição de parada |
|---|---|---|---|---|
| Chat com o cliente antes do primeiro token | Backoff curto ou fila por alguns segundos | 1 ou 2 tentativas dentro do prazo do usuário | Apenas para uma rota aprovada com as mesmas ferramentas, esquema e limite de dados | Falhar graciosamente quando o prazo do usuário expirar |
| Chat com o cliente após o streaming de tokens | Não repetir automaticamente | Geralmente nenhuma, porque a saída já está visível | Evitar mudanças de rota no meio da resposta | Encerrar o stream com um erro controlado e ID da solicitação |
| Resumo de suporte em segundo plano | Fila | Tentar novamente até a idade máxima da fila ou o orçamento de tentativas | Permitido se a qualidade do modelo e a classe de custo forem aprovadas | Enviar para dead-letter quando o trabalho estiver obsoleto ou não for idempotente |
| Trabalho de avaliação ou benchmark | Colocar em fila e limitar por chave de modelo/provedor | Orçamento maior, mas limitado | Geralmente sem fallback, porque os resultados devem ser comparáveis | Parar quando mudanças de rota invalidariam a execução |
| Geração de imagem ou vídeo | Fila com idempotência estrita | Pequeno número de tentativas devido ao custo | Fallback apenas após aprovação do usuário ou proprietário | Parar quando a geração duplicada criaria custo ou risco de UX |
| Revisão financeira, jurídica, de aquisições ou regulamentada | Fila para revisão do proprietário ou falhar de forma fechada | Mínimo | Apenas com aprovação explícita | Falhar de forma fechada em caso de incompatibilidade de limite de dados, custo ou aprovação |
Este é o cerne de uma estratégia de queueing para API de IA: a fila é uma camada de política, não um lugar para esconder todos os problemas upstream.
Classifique primeiro o sinal do provedor
O queueing deve começar com a classificação de erros. Os documentos oficiais dos provedores usam termos diferentes para condições semelhantes, então a aplicação deve normalizá-los antes de escolher uma ação.
A OpenAI separa o ritmo das solicitações do esgotamento de cota ou faturamento. Seus documentos de erro descrevem erros de limite de taxa 429 para envio de solicitações muito rápidas, casos separados de cota ou faturamento 429, erros de servidor 500, sobrecarga 503 e uma condição de lentidão 503 para aumentos repentinos de tráfego. A orientação de limite de taxa da OpenAI também recomenda backoff exponencial aleatório e avisa que solicitações malsucedidas ainda contam para os limites por minuto.
A Anthropic documenta limites de taxa nas dimensões de solicitação e token, com respostas 429 e orientação retry-after. Seus documentos de erro também separam rate_limit_error de overloaded_error, onde a sobrecarga corresponde a HTTP 529. Essa distinção é importante porque uma fila local pode diminuir seu tráfego, mas não pode restaurar a capacidade do provedor tentando novamente de forma agressiva.
A solução de problemas do Gemini mapeia 429 para RESOURCE_EXHAUSTED e instrui as equipes a verificar se atingiram os limites de taxa, limites da camada gratuita ou limites diários antes de tentar novamente. Os documentos de limite de taxa do Gemini também descrevem dimensões como solicitações por minuto, tokens por minuto, solicitações por dia e limites baseados em gastos.
Normalize esses sinais em uma única forma interna:
| Campo | Valores de exemplo | Uso da fila |
|---|---|---|
http_status | 429, 500, 503, 529 | Separa ritmo, falha do servidor e sobrecarga |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | Impede novas tentativas para problemas de cota e gastos como se fossem temporários |
retry_after_ms | Atraso derivado do cabeçalho ou nulo | Define o tempo de liberação mais cedo para o trabalho em fila |
limit_dimension | solicitações, tokens de entrada, tokens de saída, solicitações diárias, gastos | Informa ao sistema o que limitar |
route_key | provedor, modelo, família de endpoint, chave do proprietário | Agrupa o tráfego para contrapressão |
visibility_state | antes do primeiro token, após saída parcial, apenas em segundo plano | Impede a repetição insegura de trabalho visível ao usuário |
Sem essa camada, uma estratégia de queueing para API de IA se torna um exercício de adivinhação.
Separe as filas voltadas para o usuário das filas de lote
O tráfego voltado para o usuário e o tráfego em lote não devem compartilhar a mesma política de fila. Eles podem compartilhar a infraestrutura, mas precisam de orçamentos diferentes.
Workflows interativos devem ter uma fila de admissão curta. Se o sistema não puder iniciar a solicitação dentro do prazo do produto, retorne uma falha controlada em vez de manter o usuário esperando por uma longa interrupção do provedor. Um usuário aguardando por chat, assistência de codificação, pesquisa ou triagem de suporte geralmente precisa de uma resposta clara agora, não de uma resposta bem-sucedida dez minutos depois.
Workflows em lote podem esperar mais, mas apenas com uma idade máxima de fila. Sumarização, extração, enriquecimento, avaliações e automações agendadas devem conter um campo max_queue_age_ms para que o trabalho obsoleto possa expirar em vez de ser reexecutado após o momento de negócio ter passado.
As faixas mínimas da fila são:
| Faixa | Use para | Pergunta padrão do proprietário |
|---|---|---|
interactive_admission | Solicitações que não iniciaram a saída visível | Quanto tempo o usuário pode esperar antes que o produto deva responder com uma falha controlada? |
stream_recovery | Streams que falharam antes que qualquer token fosse enviado | A solicitação pode ser reiniciada sem duplicar a saída visível ou os efeitos colaterais da ferramenta? |
background_retry | Trabalhos offline que são seguros para reexecutar | Qual é a idade máxima, o número máximo de tentativas e a chave de idempotência? |
owner_review | Trabalhos bloqueados por gastos, cota, aprovação ou limite de dados | Quem deve aprovar a reexecução ou o fallback? |
dead_letter | Trabalhos que esgotaram a política de nova tentativa segura | Que evidência é necessária antes que um humano o reexecute? |
Este design de faixas protege o trabalho voltado para o usuário durante interrupções do provedor, pois o backlog em lote não pode consumir toda a capacidade justamente quando os usuários estão tentando se recuperar.
Use Retry-After como um tempo de liberação
O campo HTTP Retry-After pode ser um atraso em segundos ou uma data HTTP. Os workers da fila não devem tratá-lo como um motivo para dormir dentro de um manipulador de solicitações. Converta-o em um tempo de prontidão, armazene-o no trabalho e libere o trabalho somente quando tanto a dica do provedor quanto o orçamento do workflow permitirem outra tentativa.
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}Este auxiliar mantém a orientação do provedor fora do caminho crítico. O manipulador de solicitações pode retornar, a fila pode reter o trabalho até que esteja pronto, e a observabilidade pode mostrar se o sistema respeitou a dica de espera do provedor.
Backpressure vem antes do fallback
O fallback não é a primeira ferramenta para esvaziar a fila. Ele muda algo sobre o trabalho: modelo, provedor, custo, latência, comportamento da ferramenta, janela de contexto, limite de dados ou qualidade da saída. Durante uma interrupção, o fallback automático pode fazer a fila parecer mais saudável enquanto altera silenciosamente o comportamento do produto.
Aplique backpressure primeiro:
- Pause novos trabalhos não urgentes para a
route_keyafetada. - Reduza a concorrência de workers para o provedor, modelo, família de endpoints, cliente ou chave de proprietário afetados.
- Libere trabalhos de acordo com
ready_at, não apenas FIFO. - Descarte trabalhos de baixa prioridade antes que bloqueiem a capacidade interativa.
- Faça fallback apenas quando o contrato ainda for válido.
É aqui que uma estratégia de queueing para API de IA se conecta à sua estratégia de retry para API de IA mais ampla. O retry lida com tentativas limitadas. O queueing absorve a demanda. O backpressure desacelera a origem. O fallback muda a rota somente depois que esses controles protegeram o caminho voltado para o usuário.
Campos de fila que tornam as interrupções depuráveis
Uma fila que armazena apenas o prompt e o modelo é difícil de operar. Adicione os campos que respondem por que o trabalho está esperando, a quem pertence e o que é seguro fazer a seguir.
| Campo | Regra necessária |
|---|---|
job_id | Identificador estável para rastreamento e repetição |
idempotency_key | Derivado do workflow, usuário ou proprietário, hash de entrada e alvo do efeito colateral |
workflow | Superfície do produto, como chat, resumo de suporte, revisão de fatura ou avaliação |
owner_key | Equipe, cliente, projeto ou ambiente responsável pelo custo e capacidade |
route_key | Provedor, modelo, família de endpoints e rota do gateway |
requested_model e served_model | Mostra se o roteamento ou o fallback alterou o comportamento |
attempt e max_attempts | Evita novas tentativas infinitas |
created_at, ready_at, expires_at | Controla a idade da fila e o tempo de liberação |
retry_after_ms | Preserva a orientação de espera do provedor |
fallback_allowed | Vincula a uma política de fallback aprovada, não a uma suposição booleana |
partial_output_committed | Bloqueia a repetição insegura de streams e efeitos colaterais de ferramentas |
last_error_type | Mantém os erros do provedor visíveis após novas tentativas |
estimated_cost e usage_units | Torna o trabalho duplicado visível para as equipes financeiras e de operações |
Os usuários do Flatkey devem manter esses campos alinhados com as evidências do gateway: modelo solicitado, modelo servido, tipo de endpoint, chave do proprietário, unidades de uso e resultado da rota. O site público atual do Flatkey posiciona o produto como um gateway para acesso a modelos, roteamento, faturamento, análise de uso e controles operacionais. O snapshot da API de preços de 3 de julho de 2026 retornou 45 linhas de modelo, cinco IDs de fornecedor e tipos de endpoint suportados, incluindo openai, anthropic, gemini e image-generation. Trate esses fatos como evidências datadas e, em seguida, verifique o catálogo atual em preços antes de alterar a política de produção.
Filas de mensagens mortas precisam de regras de repetição
As filas de mensagens mortas (dead-letter queues) são úteis apenas quando evitam a repetição cega. Um trabalho de IA que falhou pode conter um prompt grande, um plano de ferramenta, uma ação do cliente ou uma solicitação cara de imagem/vídeo. Repeti-lo sem contexto pode duplicar efeitos colaterais ou gastos.
Crie um registro de mensagem morta quando qualquer uma destas condições ocorrer:
- O trabalho excedeu
max_attempts. - O trabalho excedeu
max_queue_age_ms. - O sinal do provedor indica falha de cota, gasto, permissão ou limite de dados.
- O contrato de fallback não preserva a capacidade do modelo, o comportamento da ferramenta, o esquema ou o status de aprovação.
- O trabalho não é idempotente ou já confirmou uma saída parcial.
Exija estes campos antes da repetição:
| Campo de repetição | Por que é importante |
|---|---|
replay_owner | Atribui responsabilidade pelo custo e impacto no cliente |
replay_reason | Separa a recuperação do provedor de um bug do produto, alteração de cota ou substituição pelo proprietário |
route_override | Mostra se a repetição usa o mesmo modelo ou um fallback aprovado |
idempotency_result | Prova que a repetição não duplicará efeitos colaterais externos |
cost_reviewed | Evita que a repetição enfileirada se torne uma fatura surpresa |
Uma estratégia de queueing para API de IA deve tornar a repetição algo previsível: toda repetição tem um proprietário, um motivo, uma rota e uma condição de parada.
Workflows de streaming precisam de um limite diferente
O streaming muda a decisão da fila. Antes do primeiro token, a solicitação geralmente pode tentar novamente, entrar na fila brevemente ou usar um fallback. Após o primeiro token, a repetição pode duplicar a saída visível, executar novamente as ferramentas ou juntar dois comportamentos de modelo em uma única resposta.
Use uma regra de limite de stream:
| Estado do stream | Comportamento da fila |
|---|---|
| Solicitação aceita, nenhum token enviado | Tentar novamente ou enfileirar dentro de um prazo curto do usuário |
| Primeiro token enviado, sem efeito colateral da ferramenta | Preferir o encerramento controlado do stream com o ID da solicitação |
| Chamada de ferramenta emitida ou efeito colateral iniciado | Falhar de forma segura (fail-closed) e preservar as evidências do incidente |
| Tempo limite de inatividade do stream antes da saída visível | Tentar novamente se a idempotência e o prazo permitirem |
| Interrupção do provedor após resposta parcial | Não usar fallback automático para a mesma resposta |
Para uma política complementar mais aprofundada, use a confiabilidade da API de IA de streaming. O queueing pode proteger o caminho de admissão, mas não deve fingir que a saída parcial de streaming é o mesmo que um novo trabalho em segundo plano.
Contratos de fallback para trabalhos enfileirados
Um trabalho enfileirado só pode usar um fallback quando o contrato ainda for válido. Use a mesma disciplina que você usaria em uma lista de verificação de avaliação de fallback de modelo e, em seguida, anexe o contrato aprovado à política da fila.
| Área do contrato | Pergunta necessária |
|---|---|
| Formato do endpoint | O fallback suporta o mesmo formato de chat, respostas, mensagens, imagem, vídeo ou chamada de ferramenta? |
| Contrato de saída | Ele preserva o esquema JSON, o comportamento de chamada de ferramenta, o tratamento de segurança e os requisitos de streaming? |
| Classe de qualidade | O modelo de fallback está aprovado para este workflow? |
| Limite de custo | O fallback poderia exceder o orçamento que acionou o enfileiramento? |
| Limite de dados | A rota preserva as restrições de provedor, fornecedor, região e aquisição? |
| Observabilidade | Os logs mostrarão o modelo solicitado, o modelo servido, o motivo do fallback, a idade da fila e o uso? |
Se alguma resposta for desconhecida, a fila deve parar ou mover o trabalho para revisão do proprietário. Uma fila que altera silenciosamente a rota durante uma interrupção do provedor pode trocar um problema de confiabilidade visível por um problema de correção oculto.
Um modelo de política prático
Comece com um arquivo de política antes de conectar os workers da fila à produção. Os números abaixo são exemplos; ajuste-os com dados de tráfego e incidentes.
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatchEste modelo torna a política da fila revisável. As equipes de produto, plataforma, finanças e aquisições podem ver exatamente qual trabalho espera, qual trabalho muda de rota e qual trabalho para.
Checklist de implementação
Use este checklist de estratégia de enfileiramento de API de IA ao adicionar controles de fila a uma rota de produção:
- Escolha um workflow e nomeie o proprietário do produto.
- Defina o prazo do usuário e a idade máxima da fila em segundo plano.
- Normalize os erros do provedor em um único formato de decisão de fila interna.
- Analise
Retry-Afterparaready_at. - Adicione chaves de idempotência antes de habilitar a repetição.
- Divida as faixas interativas, de segundo plano, de revisão do proprietário e de mensagens mortas (dead-letter).
- Aplique contrapressão (backpressure) pela chave de rota antes de habilitar o fallback.
- Anexe contratos de fallback às políticas de fila, não ao código do worker.
- Bloqueie a repetição automática após saída de streaming parcial ou efeitos colaterais externos.
- Registre a idade da fila, a contagem de tentativas, o motivo do fallback, o modelo solicitado, o modelo servido, as unidades de uso e o custo estimado.
- Teste 429, 503, 529, tempo limite de rede, esgotamento de cota,
Retry-Afterlongo e falhas de streaming parcial. - Revise o uso do Flatkey e as evidências da rota antes de expandir a política para o próximo workflow.
A melhor estratégia de enfileiramento de API de IA torna as interrupções menos dramáticas. Os usuários recebem prazos claros. O trabalho em lote aguarda sem duplicar custos. Os fallbacks permanecem dentro dos contratos aprovados. Os operadores obtêm evidências em vez de um backlog de trabalhos misteriosos.
Comece com os preços e o catálogo de modelos atuais do Flatkey, escolha um workflow, depois obtenha uma chave e teste sua estratégia de enfileiramento de API de IA antes de enviar tráfego de produção por ela.
FAQ
O que é uma estratégia de enfileiramento de API de IA?
Uma estratégia de enfileiramento de API de IA é a política que decide se as solicitações de modelo devem tentar novamente, esperar em uma fila, recorrer a outra rota aprovada (fallback), descartar carga (shed load) ou falhar fechado (fail closed) durante limites de taxa, sobrecarga, interrupções e erros do provedor.
As solicitações de IA voltadas para o usuário devem ir para uma fila?
Apenas brevemente. As solicitações voltadas para o usuário precisam de prazos rigorosos. Coloque na fila antes que a saída visível comece, mas retorne uma falha controlada quando a espera na fila ou o Retry-After do provedor exceder o prazo do produto.
Qual a diferença entre enfileiramento e nova tentativa?
A nova tentativa (retrying) repete uma solicitação após um atraso limitado. O enfileiramento (queueing) admite o trabalho em uma faixa gerenciada com tempo de liberação, propriedade, idade máxima, idempotência, prioridade e regras de repetição. Uma boa estratégia de enfileiramento de API de IA usa ambos, mas não os confunde.
Quando os trabalhos de IA enfileirados devem recorrer a outro modelo?
Apenas quando a rota de fallback preserva o formato do endpoint, o esquema, o comportamento da ferramenta, o limite de dados, a classe de qualidade e o limite de custo. Se o contrato de fallback for desconhecido, mova o trabalho para revisão do proprietário ou falhe fechado.
O que deve ir para uma fila de mensagens mortas (dead-letter queue)?
Trabalhos que excedem os orçamentos de tentativa ou idade da fila, atingem falhas de cota ou gastos, violam contratos de fallback, não têm idempotência ou já confirmaram uma saída parcial devem ser movidos para a fila de mensagens mortas com evidências suficientes para uma repetição manual segura.
Como o Flatkey ajuda com a estratégia de enfileiramento de API de IA?
O Flatkey oferece às equipes uma interface de gateway única para acesso a modelos conectados, roteamento, faturamento, análise de uso e controles operacionais. Use-o para manter as decisões da fila vinculadas ao modelo solicitado, modelo servido, tipo de endpoint, chave do proprietário, resultado da rota e evidência de uso.


