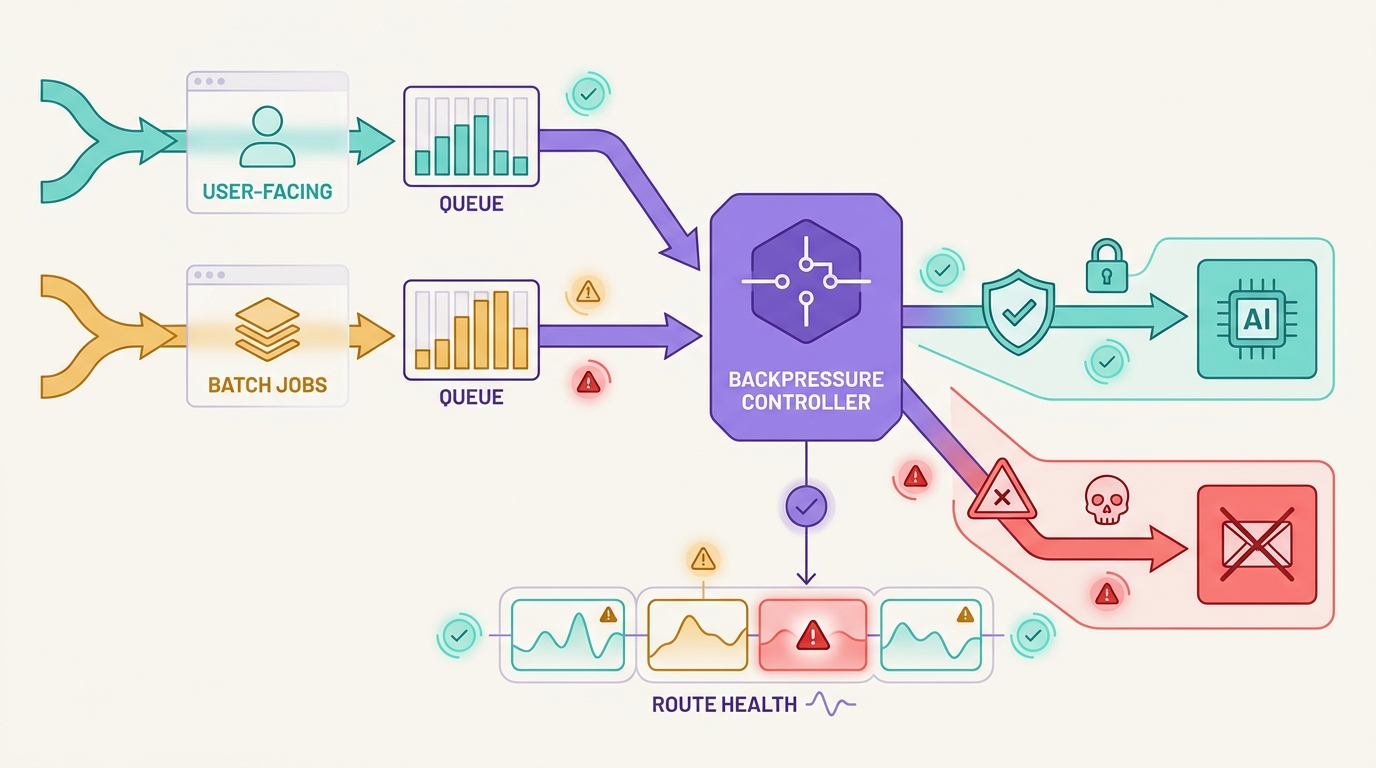
An AI API queueing strategy is not just a background-job pattern. In production AI systems, the queue decides whether user-facing work should wait, retry, fall back, shed load, or fail closed when a model provider slows down or an upstream route becomes unavailable.
The dangerous pattern is to put every failed request into one retry queue and hope capacity returns. That can protect a worker process while hurting the product: chat users wait too long, streaming sessions cannot resume cleanly, batch jobs duplicate expensive prompts, and fallback routes change model behavior without enough evidence.
A good AI API queueing strategy separates the work before the outage. Interactive requests get short budgets and clear stop conditions. Batch work gets idempotency, queue age limits, and replay rules. Fallback only happens when the output contract still holds. Flatkey fits this operating model because teams can keep model access, routing, billing, usage analytics, and operational controls in one gateway surface while they review the current model catalog and request evidence.
AI API queueing strategy in one table
Use this table as the first pass when you are deciding what belongs in a queue and what should stay on the request path.
| Workflow | Queue decision | Retry budget | Fallback boundary | Stop condition |
|---|---|---|---|---|
| Customer chat before first token | Short backoff or queue for a few seconds | 1 or 2 attempts inside the user deadline | Only to an approved route with the same tools, schema, and data boundary | Fail gracefully when the user deadline is gone |
| Customer chat after tokens streamed | Do not replay automatically | Usually none, because output is already visible | Avoid route changes mid-answer | End the stream with a controlled error and request ID |
| Support summarization in the background | Queue | Retry until max queue age or attempt budget | Allowed if model quality and cost class are approved | Dead-letter when the job is stale or non-idempotent |
| Evaluation or benchmark job | Queue and throttle by model/provider key | Larger budget, but bounded | Usually no fallback, because results must be comparable | Stop when route changes would invalidate the run |
| Image or video generation | Queue with strict idempotency | Small attempt count due to cost | Fallback only after user or owner approval | Stop when duplicate generation would create cost or UX risk |
| Finance, legal, procurement, or regulated review | Queue for owner review or fail closed | Minimal | Only with explicit approval | Fail closed on data-boundary, cost, or approval mismatch |
This is the core of an AI API queueing strategy: the queue is a policy layer, not a place to hide every upstream problem.
Classify the provider signal first
Queueing should begin with error classification. Official provider docs use different terms for similar conditions, so the application should normalize them before choosing an action.
OpenAI separates request pacing from quota or billing exhaustion. Its error docs describe 429 rate-limit errors for sending requests too quickly, separate 429 quota or billing cases, 500 server errors, 503 overload, and a 503 slow-down condition for sudden traffic increases. OpenAI's rate-limit guidance also recommends random exponential backoff and warns that unsuccessful requests still count toward per-minute limits.
Anthropic documents rate limits across request and token dimensions, with 429 responses and retry-after guidance. Its error docs also separate rate_limit_error from overloaded_error, where overload maps to HTTP 529. That distinction matters because a local queue can slow your traffic, but it cannot restore provider capacity by retrying aggressively.
Gemini troubleshooting maps 429 to RESOURCE_EXHAUSTED and tells teams to check whether they hit rate limits, free-tier limits, or daily limits before retrying. Gemini rate-limit docs also describe dimensions such as requests per minute, tokens per minute, requests per day, and spend-based limits.
Normalize those signals into one internal shape:
| Field | Example values | Queue use |
|---|---|---|
http_status | 429, 500, 503, 529 | Separates pacing, server failure, and overload |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | Prevents retrying quota and spend problems as if they were temporary |
retry_after_ms | Header-derived delay or null | Sets the earliest release time for queued work |
limit_dimension | requests, input tokens, output tokens, daily requests, spend | Tells the system what to throttle |
route_key | provider, model, endpoint family, owner key | Groups traffic for backpressure |
visibility_state | before first token, after partial output, background-only | Prevents unsafe replay of user-visible work |
Without this layer, an AI API queueing strategy becomes guesswork.
Separate user-facing lanes from batch lanes
User-facing traffic and batch traffic should not share the same queue policy. They can share infrastructure, but they need different budgets.
Interactive workflows should have a short admission queue. If the system cannot start the request within the product deadline, return a controlled failure rather than holding the user behind a long provider outage. A user waiting for chat, coding assistance, search, or support triage usually needs a clear answer now, not a successful response ten minutes later.
Batch workflows can wait longer, but only with a max queue age. Summarization, extraction, enrichment, evaluations, and scheduled automations should carry a max_queue_age_ms field so stale work can expire instead of replaying after the business moment has passed.
The minimum queue lanes are:
| Lane | Use it for | Default owner question |
|---|---|---|
interactive_admission | Requests that have not started visible output | How long can the user wait before the product should answer with a controlled failure? |
stream_recovery | Streams that broke before any token was sent | Can the request restart without duplicating visible output or tool side effects? |
background_retry | Offline jobs that are safe to replay | What is the max age, max attempts, and idempotency key? |
owner_review | Jobs blocked by spend, quota, approval, or data boundary | Who must approve replay or fallback? |
dead_letter | Jobs that exhausted safe retry policy | What evidence is required before a human replays it? |
This lane design protects user-facing work during provider outages because batch backlog cannot consume all capacity just as users are trying to recover.
Use Retry-After as a release time
The HTTP Retry-After field can be a delay in seconds or an HTTP date. Queue workers should not treat it as a reason to sleep inside a request handler. Convert it into a ready time, store it on the job, and release the job only when both the provider hint and the workflow budget allow another attempt.
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}This helper keeps provider guidance out of the hot path. The request handler can return, the queue can hold the job until it is ready, and observability can show whether the system respected the provider wait hint.
Backpressure comes before fallback
Fallback is not the first queue-drain tool. It changes something about the work: model, provider, cost, latency, tool behavior, context window, data boundary, or output quality. During an outage, automatic fallback can make the queue appear healthier while silently changing product behavior.
Apply backpressure first:
- Pause new non-urgent jobs for the affected
route_key. - Lower worker concurrency for the affected provider, model, endpoint family, customer, or owner key.
- Release jobs according to
ready_at, not FIFO alone. - Shed low-priority work before it blocks interactive capacity.
- Fallback only when the contract still holds.
This is where an AI API queueing strategy connects to your broader AI API retry strategy. Retry handles bounded attempts. Queueing absorbs demand. Backpressure slows the source. Fallback changes route only after those controls have protected the user-facing path.
Queue fields that make outages debuggable
A queue that stores only prompt and model is hard to operate. Add the fields that answer why the job is waiting, who owns it, and what is safe to do next.
| Field | Required rule |
|---|---|
job_id | Stable identifier for tracking and replay |
idempotency_key | Derived from workflow, user or owner, input hash, and side-effect target |
workflow | Product surface such as chat, support summary, invoice review, or evaluation |
owner_key | Team, customer, project, or environment responsible for cost and capacity |
route_key | Provider, model, endpoint family, and gateway route |
requested_model and served_model | Shows whether routing or fallback changed behavior |
attempt and max_attempts | Prevents infinite retries |
created_at, ready_at, expires_at | Controls queue age and release timing |
retry_after_ms | Preserves provider wait guidance |
fallback_allowed | Links to an approved fallback policy, not a boolean guess |
partial_output_committed | Blocks unsafe replay of streams and tool side effects |
last_error_type | Keeps provider errors visible after retries |
estimated_cost and usage_units | Makes duplicate work visible to finance and operators |
Flatkey users should keep these fields aligned with gateway evidence: requested model, served model, endpoint type, owner key, usage units, and route outcome. Flatkey's current public site positions the product as one gateway for model access, routing, billing, usage analytics, and operational controls. The July 3, 2026 pricing API snapshot returned 45 model rows, five vendor IDs, and supported endpoint types including openai, anthropic, gemini, and image-generation. Treat those facts as dated evidence, then verify the current catalog on pricing before changing production policy.
Dead-letter queues need replay rules
Dead-letter queues are useful only when they prevent blind replay. A failed AI job may contain a large prompt, a tool plan, a customer action, or an expensive image/video request. Replaying it without context can duplicate side effects or spend.
Create a dead-letter record when any of these conditions occur:
- The job exceeded
max_attempts. - The job exceeded
max_queue_age_ms. - The provider signal indicates quota, spend, permission, or data-boundary failure.
- The fallback contract does not preserve model capability, tool behavior, schema, or approval status.
- The job is non-idempotent or has already committed partial output.
Require these fields before replay:
| Replay field | Why it matters |
|---|---|
replay_owner | Assigns responsibility for cost and customer impact |
replay_reason | Separates provider recovery from product bug, quota change, or owner override |
route_override | Shows whether the replay uses the same model or an approved fallback |
idempotency_result | Proves the replay will not duplicate external side effects |
cost_reviewed | Prevents queued replay from becoming a surprise bill |
An AI API queueing strategy should make replay boring: every replay has an owner, a reason, a route, and a stop condition.
Streaming workflows need a different boundary
Streaming changes the queue decision. Before the first token, the request can often retry, queue briefly, or fall back. After the first token, replay can duplicate visible output, rerun tools, or stitch together two model behaviors in one answer.
Use a stream boundary rule:
| Stream state | Queue behavior |
|---|---|
| Request accepted, no token sent | Retry or queue inside a short user deadline |
| First token sent, no tool side effect | Prefer controlled stream termination with request ID |
| Tool call emitted or side effect started | Fail closed and preserve incident evidence |
| Stream idle timeout before visible output | Retry if idempotency and deadline allow |
| Provider outage after partial answer | Do not auto-fallback into the same answer |
For a deeper companion policy, use streaming AI API reliability. Queueing can protect the admission path, but it should not pretend that partial streaming output is the same as a fresh background job.
Fallback contracts for queued work
A queued job can fall back only when the contract still holds. Use the same discipline you would use in a model fallback evaluation checklist, then attach the approved contract to the queue policy.
| Contract area | Required question |
|---|---|
| Endpoint shape | Does the fallback support the same chat, responses, messages, image, video, or tool-calling shape? |
| Output contract | Does it preserve JSON schema, tool call behavior, safety handling, and streaming requirements? |
| Quality class | Is the fallback model approved for this workflow? |
| Cost cap | Could fallback exceed the budget that triggered queueing? |
| Data boundary | Does the route preserve provider, vendor, region, and procurement constraints? |
| Observability | Will logs show requested model, served model, fallback reason, queue age, and usage? |
If any answer is unknown, the queue should stop or move the job to owner review. A queue that silently changes route during a provider outage may trade a visible reliability problem for a hidden correctness problem.
A practical policy template
Start with a policy file before wiring queue workers into production. The numbers below are examples; tune them with traffic and incident data.
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatchThis template makes the queue policy reviewable. Product, platform, finance, and procurement teams can see exactly which work waits, which work changes route, and which work stops.
Rollout checklist
Use this AI API queueing strategy checklist when you add queue controls to a production route:
- Pick one workflow and name the product owner.
- Define the user deadline and the background max queue age.
- Normalize provider errors into one internal queue decision shape.
- Parse
Retry-Afterintoready_at. - Add idempotency keys before enabling replay.
- Split interactive, background, owner-review, and dead-letter lanes.
- Apply backpressure by route key before enabling fallback.
- Attach fallback contracts to queue policies, not worker code.
- Block automatic replay after partial streaming output or external side effects.
- Log queue age, attempt count, fallback reason, requested model, served model, usage units, and estimated cost.
- Test 429, 503, 529, network timeout, quota exhaustion, long
Retry-After, and partial streaming failures. - Review Flatkey usage and route evidence before expanding the policy to the next workflow.
The best AI API queueing strategy makes outages less dramatic. Users get clear deadlines. Batch work waits without duplicating cost. Fallbacks stay inside approved contracts. Operators get evidence instead of a backlog of mystery jobs.
Start with the current Flatkey pricing and model catalog, choose one workflow, then get a key and test your AI API queueing strategy before sending production traffic through it.
FAQ
What is an AI API queueing strategy?
An AI API queueing strategy is the policy that decides whether model requests should retry, wait in a queue, fall back to another approved route, shed load, or fail closed during rate limits, overload, outages, and provider errors.
Should user-facing AI requests go into a queue?
Only briefly. User-facing requests need strict deadlines. Queue before visible output starts, but return a controlled failure when the queue wait or provider Retry-After exceeds the product deadline.
How is queueing different from retrying?
Retrying repeats a request after a bounded delay. Queueing admits work into a managed lane with release time, ownership, max age, idempotency, priority, and replay rules. A good AI API queueing strategy uses both, but does not confuse them.
When should queued AI jobs fall back to another model?
Only when the fallback route preserves the endpoint shape, schema, tool behavior, data boundary, quality class, and cost cap. If the fallback contract is unknown, move the job to owner review or fail closed.
What should go into a dead-letter queue?
Jobs that exceed attempt or queue-age budgets, hit quota or spend failures, violate fallback contracts, lack idempotency, or already committed partial output should move to dead letter with enough evidence for safe manual replay.
How does Flatkey help with AI API queueing strategy?
Flatkey gives teams one gateway surface for connected model access, routing, billing, usage analytics, and operational controls. Use it to keep queue decisions tied to requested model, served model, endpoint type, owner key, route result, and usage evidence.


