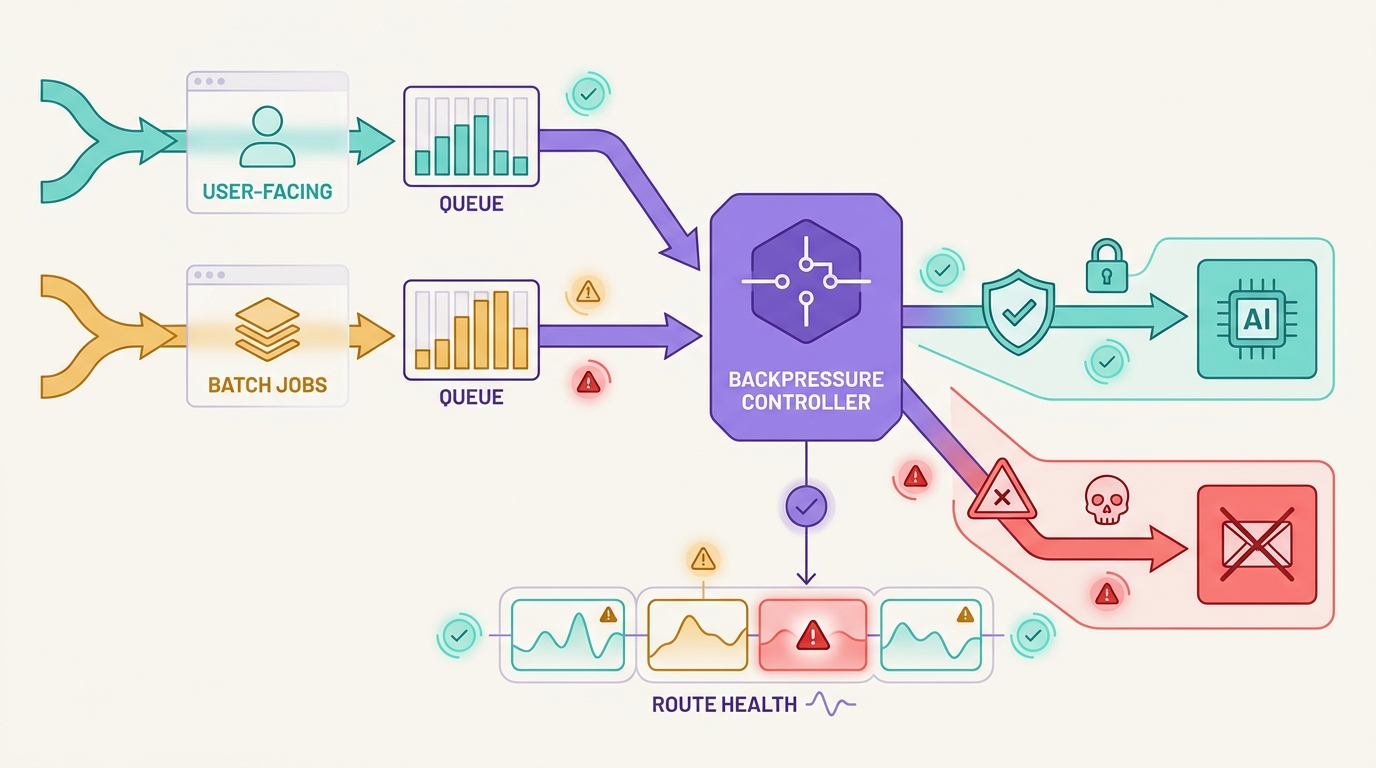
Une stratégie de mise en file d'attente pour les API d'IA n'est pas seulement un modèle de tâche d'arrière-plan. Dans les systèmes d'IA en production, la file d'attente décide si une tâche orientée utilisateur doit attendre, être réessayée, utiliser une solution de repli, délester la charge ou échouer en mode fermé lorsqu'un fournisseur de modèle ralentit ou qu'une route en amont devient indisponible.
Le modèle dangereux consiste à placer chaque requête échouée dans une seule file d'attente de relance et à espérer que la capacité revienne. Cela peut protéger un processus de travail tout en nuisant au produit : les utilisateurs de chat attendent trop longtemps, les sessions de streaming ne peuvent pas reprendre proprement, les tâches par lots dupliquent des prompts coûteux et les routes de repli modifient le comportement du modèle sans preuves suffisantes.
Une bonne stratégie de mise en file d'attente pour les API d'IA sépare le travail avant la panne. Les requêtes interactives obtiennent des budgets courts et des conditions d'arrêt claires. Le travail par lots bénéficie de l'idempotence, de limites d'âge dans la file d'attente et de règles de relecture. Le repli ne se produit que lorsque le contrat de sortie est toujours respecté. Flatkey correspond à ce modèle opérationnel car les équipes peuvent conserver l'accès au modèle, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels dans une seule surface de passerelle pendant qu'elles examinent le catalogue de modèles actuel et les preuves des requêtes.
Stratégie de mise en file d'attente pour les API d'IA en un tableau
Utilisez ce tableau comme première approche lorsque vous décidez ce qui doit être mis en file d'attente et ce qui doit rester sur le chemin de la requête.
| Workflow | Décision de mise en file d'attente | Budget de relance | Limite de repli | Condition d'arrêt |
|---|---|---|---|---|
| Chat client avant le premier jeton | Backoff court ou mise en file d'attente pour quelques secondes | 1 ou 2 tentatives dans le délai de l'utilisateur | Uniquement vers une route approuvée avec les mêmes outils, schéma et limite de données | Échouer proprement lorsque le délai de l'utilisateur est dépassé |
| Chat client après la diffusion des jetons | Ne pas relire automatiquement | Généralement aucune, car la sortie est déjà visible | Éviter les changements de route en cours de réponse | Terminer le flux avec une erreur contrôlée et un ID de requête |
| Résumé du support en arrière-plan | Mettre en file d'attente | Réessayer jusqu'à l'âge maximum de la file d'attente ou le budget de tentatives | Autorisé si la qualité du modèle et la classe de coût sont approuvées | Lettre morte lorsque la tâche est obsolète ou non idempotente |
| Tâche d'évaluation ou de benchmark | Mettre en file d'attente et réguler par clé de modèle/fournisseur | Budget plus important, mais limité | Généralement pas de repli, car les résultats doivent être comparables | Arrêter lorsque les changements de route invalideraient l'exécution |
| Génération d'images ou de vidéos | Mettre en file d'attente avec une idempotence stricte | Petit nombre de tentatives en raison du coût | Repli uniquement après approbation de l'utilisateur ou du propriétaire | Arrêter lorsque la génération de doublons créerait un risque de coût ou d'UX |
| Examen financier, juridique, d'approvisionnement ou réglementé | Mettre en file d'attente pour examen par le propriétaire ou échouer en mode fermé | Minimal | Uniquement avec une approbation explicite | Échouer en mode fermé en cas de non-concordance de la limite de données, du coût ou de l'approbation |
C'est le cœur d'une stratégie de mise en file d'attente pour les API d'IA : la file d'attente est une couche de politique, pas un endroit pour cacher tous les problèmes en amont.
Classifier d'abord le signal du fournisseur
La mise en file d'attente devrait commencer par la classification des erreurs. Les documentations officielles des fournisseurs utilisent des termes différents pour des conditions similaires, donc l'application devrait les normaliser avant de choisir une action.
OpenAI sépare la régulation des requêtes de l'épuisement des quotas ou de la facturation. Sa documentation sur les erreurs décrit les erreurs de limitation de débit 429 pour l'envoi de requêtes trop rapides, des cas distincts de quota ou de facturation 429, des erreurs de serveur 500, une surcharge 503 et une condition de ralentissement 503 pour les augmentations soudaines de trafic. Les directives de limitation de débit d'OpenAI recommandent également un backoff exponentiel aléatoire et avertissent que les requêtes infructueuses comptent toujours dans les limites par minute.
Anthropic documente les limitations de débit selon les dimensions de requêtes et de jetons, avec des réponses 429 et des directives retry-after. Sa documentation sur les erreurs sépare également rate_limit_error de overloaded_error, où la surcharge correspond à HTTP 529. Cette distinction est importante car une file d'attente locale peut ralentir votre trafic, mais elle ne peut pas restaurer la capacité du fournisseur en réessayant de manière agressive.
Le dépannage de Gemini associe le code 429 à RESOURCE_EXHAUSTED et demande aux équipes de vérifier si elles ont atteint les limites de débit, les limites du niveau gratuit ou les limites quotidiennes avant de réessayer. La documentation sur les limites de débit de Gemini décrit également des dimensions telles que les requêtes par minute, les jetons par minute, les requêtes par jour et les limites basées sur les dépenses.
Normalisez ces signaux en une seule forme interne :
| Champ | Valeurs d'exemple | Utilisation de la file d'attente |
|---|---|---|
http_status | 429, 500, 503, 529 | Sépare la régulation, la défaillance du serveur et la surcharge |
provider_error_type | rate_limit_error, overloaded_error, RESOURCE_EXHAUSTED, insufficient_quota | Empêche de réessayer les problèmes de quota et de dépenses comme s'ils étaient temporaires |
retry_after_ms | Délai dérivé de l'en-tête ou nul | Définit le temps de libération le plus précoce pour le travail en file d'attente |
limit_dimension | requêtes, jetons d'entrée, jetons de sortie, requêtes quotidiennes, dépenses | Indique au système ce qu'il faut réguler |
route_key | fournisseur, modèle, famille de points de terminaison, clé du propriétaire | Regroupe le trafic pour la contre-pression |
visibility_state | avant le premier jeton, après une sortie partielle, en arrière-plan uniquement | Empêche la relecture non sécurisée du travail visible par l'utilisateur |
Sans cette couche, une stratégie de mise en file d'attente pour les API d'IA devient une affaire de devinettes.
Séparer les files orientées utilisateur des files de traitement par lots
Le trafic orienté utilisateur et le trafic par lots ne devraient pas partager la même politique de file d'attente. Ils peuvent partager l'infrastructure, mais ils ont besoin de budgets différents.
Les workflows interactifs doivent avoir une file d'attente d'admission courte. Si le système ne peut pas démarrer la requête dans le délai imparti par le produit, il doit renvoyer un échec contrôlé plutôt que de faire attendre l'utilisateur derrière une longue panne de fournisseur. Un utilisateur qui attend une discussion, une assistance au codage, une recherche ou un triage de support a généralement besoin d'une réponse claire maintenant, et non d'une réponse réussie dix minutes plus tard.
Les workflows par lots peuvent attendre plus longtemps, mais uniquement avec un âge maximum de file d'attente. La résumé, l'extraction, l'enrichissement, les évaluations et les automatisations planifiées doivent comporter un champ max_queue_age_ms afin que le travail obsolète puisse expirer au lieu d'être rejoué une fois le moment opportun passé.
Les couloirs de file d'attente minimum sont :
| Couloir | Utilisation | Question par défaut du propriétaire |
|---|---|---|
interactive_admission | Requêtes qui n'ont pas encore commencé à produire de sortie visible | Combien de temps l'utilisateur peut-il attendre avant que le produit ne réponde par un échec contrôlé ? |
stream_recovery | Flux qui ont été interrompus avant l'envoi de tout jeton | La requête peut-elle redémarrer sans dupliquer la sortie visible ou les effets secondaires des outils ? |
background_retry | Tâches hors ligne qui peuvent être rejouées en toute sécurité | Quels sont l'âge maximum, le nombre maximum de tentatives et la clé d'idempotence ? |
owner_review | Tâches bloquées par les dépenses, le quota, l'approbation ou la limite de données | Qui doit approuver la relecture ou le basculement ? |
dead_letter | Tâches qui ont épuisé la politique de nouvelle tentative sécurisée | Quelles preuves sont requises avant qu'un humain ne la rejoue ? |
Cette conception en couloirs protège le travail orienté utilisateur pendant les pannes de fournisseur, car le backlog des lots ne peut pas consommer toute la capacité au moment même où les utilisateurs tentent de se rétablir.
Utiliser Retry-After comme heure de libération
Le champ HTTP Retry-After peut être un délai en secondes ou une date HTTP. Les workers de la file d'attente ne doivent pas le considérer comme une raison de se mettre en veille à l'intérieur d'un gestionnaire de requêtes. Convertissez-le en une heure de disponibilité, stockez-le sur la tâche et ne libérez la tâche que lorsque l'indice du fournisseur et le budget du workflow autorisent une nouvelle tentative.
type QueueDecision =
| { action: "retry_now"; reason: string }
| { action: "queue"; readyAt: number; reason: string }
| { action: "fallback"; reason: string }
| { action: "fail_closed"; reason: string };
function retryAfterMs(value: string | null, now = Date.now()) {
if (!value) return null;
const seconds = Number(value);
if (Number.isFinite(seconds)) return Math.max(0, seconds * 1000);
const dateMs = Date.parse(value);
if (Number.isFinite(dateMs)) return Math.max(0, dateMs - now);
return null;
}
function decideQueueAction(input: {
retryAfterHeader: string | null;
attempt: number;
maxAttempts: number;
remainingWorkflowMs: number;
visibleOutputStarted: boolean;
fallbackContractOk: boolean;
}): QueueDecision {
if (input.visibleOutputStarted) {
return { action: "fail_closed", reason: "partial_output_committed" };
}
if (input.attempt >= input.maxAttempts) {
return input.fallbackContractOk
? { action: "fallback", reason: "attempt_budget_exhausted" }
: { action: "fail_closed", reason: "attempt_budget_exhausted" };
}
const providerDelayMs = retryAfterMs(input.retryAfterHeader);
const jitterMs = Math.floor(Math.random() * Math.min(30_000, 500 * 2 ** input.attempt));
const delayMs = providerDelayMs ?? jitterMs;
if (delayMs > input.remainingWorkflowMs) {
return { action: "fail_closed", reason: "retry_after_exceeds_deadline" };
}
if (delayMs > 2_000) {
return { action: "queue", readyAt: Date.now() + delayMs, reason: "provider_wait_hint" };
}
return { action: "retry_now", reason: "short_bounded_wait" };
}Cette fonction d'assistance maintient les directives du fournisseur en dehors du chemin critique. Le gestionnaire de requêtes peut retourner une réponse, la file d'attente peut conserver la tâche jusqu'à ce qu'elle soit prête, et l'observabilité peut indiquer si le système a respecté l'indice d'attente du fournisseur.
La contre-pression avant le basculement
Le basculement n'est pas le premier outil pour vider la file d'attente. Il modifie un aspect du travail : le modèle, le fournisseur, le coût, la latence, le comportement de l'outil, la fenêtre de contexte, la limite des données ou la qualité de la sortie. Pendant une panne, le basculement automatique peut donner l'impression que la file d'attente est plus saine tout en modifiant silencieusement le comportement du produit.
Appliquez d'abord la contre-pression :
- Mettez en pause les nouvelles tâches non urgentes pour la
route_keyaffectée. - Réduisez la simultanéité des workers pour le fournisseur, le modèle, la famille de points de terminaison, le client ou la clé propriétaire affecté(e).
- Libérez les tâches en fonction de
ready_at, et non uniquement selon le principe FIFO. - Délester le travail de faible priorité avant qu'il ne bloque la capacité interactive.
- N'effectuez un basculement que lorsque le contrat est toujours valable.
C'est là qu'une stratégie de mise en file d'attente pour les API d'IA se connecte à votre stratégie de nouvelle tentative pour les API d'IA plus large. La nouvelle tentative gère les essais limités. La mise en file d'attente absorbe la demande. La contre-pression ralentit la source. Le basculement ne change de route qu'après que ces contrôles ont protégé le chemin orienté utilisateur.
Champs de file d'attente qui rendent les pannes débogables
Une file d'attente qui ne stocke que le prompt et le modèle est difficile à gérer. Ajoutez les champs qui répondent à la question de savoir pourquoi la tâche attend, à qui elle appartient et ce qu'il est sûr de faire ensuite.
| Champ | Règle requise |
|---|---|
job_id | Identifiant stable pour le suivi et la relecture |
idempotency_key | Dérivé du workflow, de l'utilisateur ou du propriétaire, du hachage de l'entrée et de la cible de l'effet secondaire |
workflow | Surface du produit telle que le chat, le résumé du support, l'examen de facture ou l'évaluation |
owner_key | Équipe, client, projet ou environnement responsable des coûts et de la capacité |
route_key | Fournisseur, modèle, famille de points de terminaison et route de la passerelle |
requested_model et served_model | Indique si le routage ou le repli a modifié le comportement |
attempt et max_attempts | Empêche les tentatives de relance infinies |
created_at, ready_at, expires_at | Contrôle l'âge de la file d'attente et le moment de la libération |
retry_after_ms | Conserve les instructions d'attente du fournisseur |
fallback_allowed | Lien vers une politique de repli approuvée, pas une supposition booléenne |
partial_output_committed | Bloque la relecture non sécurisée des flux et des effets secondaires des outils |
last_error_type | Maintient les erreurs du fournisseur visibles après les tentatives de relance |
estimated_cost et usage_units | Rend le travail en double visible pour les finances et les opérateurs |
Les utilisateurs de Flatkey doivent maintenir ces champs alignés avec les preuves de la passerelle : modèle demandé, modèle servi, type de point de terminaison, clé du propriétaire, unités d'utilisation et résultat de la route. Le site public actuel de Flatkey positionne le produit comme une passerelle unique pour l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. L'instantané de l'API de tarification du 3 juillet 2026 a renvoyé 45 lignes de modèles, cinq identifiants de fournisseurs et des types de points de terminaison pris en charge, notamment openai, anthropic, gemini et image-generation. Considérez ces faits comme des preuves datées, puis vérifiez le catalogue actuel sur la page de tarification avant de modifier la politique de production.
Les files d'attente de lettres mortes nécessitent des règles de relecture
Les files d'attente de lettres mortes ne sont utiles que lorsqu'elles empêchent la relecture à l'aveugle. Une tâche d'IA ayant échoué peut contenir une grande invite, un plan d'outil, une action client ou une requête d'image/vidéo coûteuse. La relire sans contexte peut dupliquer les effets secondaires ou les dépenses.
Créez un enregistrement de lettre morte lorsque l'une de ces conditions se produit :
- La tâche a dépassé
max_attempts. - La tâche a dépassé
max_queue_age_ms. - Le signal du fournisseur indique un échec de quota, de dépense, d'autorisation ou de limite de données.
- Le contrat de repli ne préserve pas la capacité du modèle, le comportement de l'outil, le schéma ou le statut d'approbation.
- La tâche n'est pas idempotente ou a déjà validé une sortie partielle.
Exigez ces champs avant la relecture :
| Champ de relecture | Pourquoi c'est important |
|---|---|
replay_owner | Attribue la responsabilité du coût et de l'impact sur le client |
replay_reason | Sépare la récupération du fournisseur d'un bogue de produit, d'un changement de quota ou d'une dérogation du propriétaire |
route_override | Indique si la relecture utilise le même modèle ou un repli approuvé |
idempotency_result | Prouve que la relecture ne dupliquera pas les effets secondaires externes |
cost_reviewed | Empêche la relecture en file d'attente de devenir une facture surprise |
Une stratégie de mise en file d'attente pour les API d'IA devrait rendre la relecture ennuyeuse : chaque relecture a un propriétaire, une raison, une route et une condition d'arrêt.
Les workflows de streaming nécessitent une limite différente
Le streaming modifie la décision de mise en file d'attente. Avant le premier jeton, la requête peut souvent être relancée, mise en file d'attente brièvement ou se replier. Après le premier jeton, la relecture peut dupliquer la sortie visible, réexécuter des outils ou assembler deux comportements de modèle en une seule réponse.
Utilisez une règle de limite de flux :
| État du flux | Comportement de la file d'attente |
|---|---|
| Requête acceptée, aucun jeton envoyé | Relancer ou mettre en file d'attente dans un court délai utilisateur |
| Premier jeton envoyé, aucun effet secondaire de l'outil | Préférer une terminaison de flux contrôlée avec l'ID de la requête |
| Appel d'outil émis ou effet secondaire démarré | Échouer en mode fermé et conserver les preuves de l'incident |
| Délai d'inactivité du flux avant la sortie visible | Relancer si l'idempotence et le délai le permettent |
| Panne du fournisseur après une réponse partielle | Ne pas se replier automatiquement dans la même réponse |
Pour une politique complémentaire plus approfondie, consultez la page sur la fiabilité des API d'IA en streaming. La mise en file d'attente peut protéger le chemin d'admission, mais elle ne doit pas prétendre qu'une sortie de streaming partielle est la même chose qu'une nouvelle tâche en arrière-plan.
Contrats de repli pour le travail en file d'attente
Une tâche en file d'attente ne peut se replier que si le contrat est toujours valable. Utilisez la même discipline que celle que vous utiliseriez dans une liste de contrôle pour l'évaluation du repli de modèle, puis attachez le contrat approuvé à la politique de la file d'attente.
| Zone du contrat | Question requise |
|---|---|
| Forme du point de terminaison | La solution de secours prend-elle en charge la même forme de chat, de réponses, de messages, d'images, de vidéos ou d'appels d'outils ? |
| Contrat de sortie | Préserve-t-elle le schéma JSON, le comportement des appels d'outils, la gestion de la sécurité et les exigences de streaming ? |
| Classe de qualité | Le modèle de secours est-il approuvé pour ce workflow ? |
| Plafond de coût | La solution de secours pourrait-elle dépasser le budget qui a déclenché la mise en file d'attente ? |
| Frontière des données | L'itinéraire préserve-t-il les contraintes de fournisseur, de vendeur, de région et d'approvisionnement ? |
| Observabilité | Les journaux afficheront-ils le modèle demandé, le modèle servi, la raison du basculement, l'âge dans la file d'attente et l'utilisation ? |
Si une réponse est inconnue, la file d'attente doit s'arrêter ou déplacer la tâche vers une révision par le propriétaire. Une file d'attente qui change silencieusement d'itinéraire lors d'une panne de fournisseur peut échanger un problème de fiabilité visible contre un problème de justesse caché.
Un modèle de politique pratique
Commencez par un fichier de politique avant de connecter les workers de la file d'attente à la production. Les chiffres ci-dessous sont des exemples ; ajustez-les avec les données de trafic et d'incidents.
workflow: support_chat
ai_api_queueing_strategy:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- route_key
- visibility_state
lanes:
interactive_admission:
max_wait_ms: 4000
max_attempts: 2
shed_priority_below: normal
background_retry:
max_queue_age_ms: 900000
max_attempts: 5
require_idempotency_key: true
owner_review:
enter_when:
- quota_or_spend_exhausted
- fallback_contract_unknown
- data_boundary_mismatch
dead_letter:
enter_when:
- max_attempts_exhausted
- max_queue_age_exceeded
- partial_output_committed
backpressure:
concurrency_key:
- owner_key
- provider
- requested_model
- endpoint_type
release_order:
- ready_at
- priority
- created_at
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_schema_match: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- retry_after_exceeds_deadline
- partial_output_committed
- quota_or_spend_exhausted
- fallback_contract_mismatchCe modèle rend la politique de la file d'attente révisable. Les équipes produit, plateforme, finance et approvisionnement peuvent voir exactement quelles tâches attendent, lesquelles changent d'itinéraire et lesquelles s'arrêtent.
Checklist de déploiement
Utilisez cette checklist de stratégie de mise en file d'attente pour les API d'IA lorsque vous ajoutez des contrôles de file d'attente à un itinéraire de production :
- Choisissez un workflow et nommez le propriétaire du produit.
- Définissez le délai de l'utilisateur et l'âge maximum de la file d'attente en arrière-plan.
- Normalisez les erreurs du fournisseur en une seule forme de décision de file d'attente interne.
- Analysez
Retry-Afterenready_at. - Ajoutez des clés d'idempotence avant d'activer la relecture.
- Séparez les couloirs interactifs, d'arrière-plan, de révision par le propriétaire et de lettre morte.
- Appliquez une contre-pression par clé d'itinéraire avant d'activer la solution de secours.
- Attachez les contrats de secours aux politiques de la file d'attente, pas au code du worker.
- Bloquez la relecture automatique après une sortie de streaming partielle ou des effets de bord externes.
- Journalisez l'âge dans la file d'attente, le nombre de tentatives, la raison du basculement, le modèle demandé, le modèle servi, les unités d'utilisation et le coût estimé.
- Testez les erreurs 429, 503, 529, les délais d'attente réseau, l'épuisement des quotas, les longs
Retry-Afteret les échecs de streaming partiel. - Examinez l'utilisation de Flatkey et les preuves de l'itinéraire avant d'étendre la politique au workflow suivant.
La meilleure stratégie de mise en file d'attente pour les API d'IA rend les pannes moins dramatiques. Les utilisateurs obtiennent des délais clairs. Le travail par lots attend sans dupliquer les coûts. Les solutions de secours restent dans le cadre des contrats approuvés. Les opérateurs obtiennent des preuves au lieu d'un arriéré de tâches mystérieuses.
Commencez avec la tarification et le catalogue de modèles actuels de Flatkey, choisissez un workflow, puis obtenez une clé et testez votre stratégie de mise en file d'attente pour les API d'IA avant d'y envoyer du trafic de production.
FAQ
Qu'est-ce qu'une stratégie de mise en file d'attente pour les API d'IA ?
Une stratégie de mise en file d'attente pour les API d'IA est la politique qui décide si les requêtes de modèle doivent être réessayées, attendre dans une file d'attente, basculer vers un autre itinéraire approuvé, délester la charge ou échouer en mode fermé lors de limitations de débit, de surcharges, de pannes et d'erreurs du fournisseur.
Les requêtes d'IA orientées utilisateur doivent-elles aller dans une file d'attente ?
Seulement brièvement. Les requêtes orientées utilisateur nécessitent des délais stricts. Mettez en file d'attente avant que la sortie visible ne commence, mais retournez un échec contrôlé lorsque l'attente dans la file ou le Retry-After du fournisseur dépasse le délai du produit.
En quoi la mise en file d'attente est-elle différente de la nouvelle tentative ?
La nouvelle tentative répète une requête après un délai limité. La mise en file d'attente admet le travail dans un couloir géré avec une heure de libération, une propriété, un âge maximum, une idempotence, une priorité et des règles de relecture. Une bonne stratégie de mise en file d'attente pour les API d'IA utilise les deux, mais ne les confond pas.
Quand les tâches d'IA en file d'attente doivent-elles basculer vers un autre modèle ?
Uniquement lorsque l'itinéraire de secours préserve la forme du point de terminaison, le schéma, le comportement de l'outil, la frontière des données, la classe de qualité et le plafond de coût. Si le contrat de secours est inconnu, déplacez la tâche vers une révision par le propriétaire ou échouez en mode fermé.
Que doit-on mettre dans une file d'attente de lettres mortes ?
Les tâches qui dépassent les budgets de tentatives ou d'âge dans la file d'attente, qui rencontrent des échecs de quota ou de dépenses, qui violent les contrats de secours, qui manquent d'idempotence ou qui ont déjà validé une sortie partielle doivent être déplacées vers la file de lettres mortes avec suffisamment de preuves pour une relecture manuelle sûre.
Comment Flatkey aide-t-il avec la stratégie de mise en file d'attente pour les API d'IA ?
Flatkey fournit aux équipes une passerelle unique pour l'accès aux modèles connectés, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. Utilisez-la pour que les décisions de mise en file d'attente restent liées au modèle demandé, au modèle servi, au type de point de terminaison, à la clé du propriétaire, au résultat de la route et aux preuves d'utilisation.


