Les limitations de débit ne sont pas de simples erreurs à réessayer. Dans les systèmes d'IA en production, un code 429 peut signifier qu'une courte rafale a dépassé un compartiment de jetons, qu'un projet a atteint un plafond de requêtes par minute, qu'un plafond de dépenses a été atteint ou qu'un fournisseur demande au client de ralentir avant que la capacité ne soit rétablie. Une bonne gestion de la limitation de débit des API d'IA distingue ces cas avant de dépenser plus de jetons.
Le mauvais schéma est simple : chaque worker voit un code 429, attend le même délai fixe, réessaie en même temps, puis se rabat sur un autre modèle lorsque les tentatives échouent. Cela transforme un signal de capacité en charge dupliquée, en coût plus élevé, en sortie incohérente et en preuves d'incident faibles.
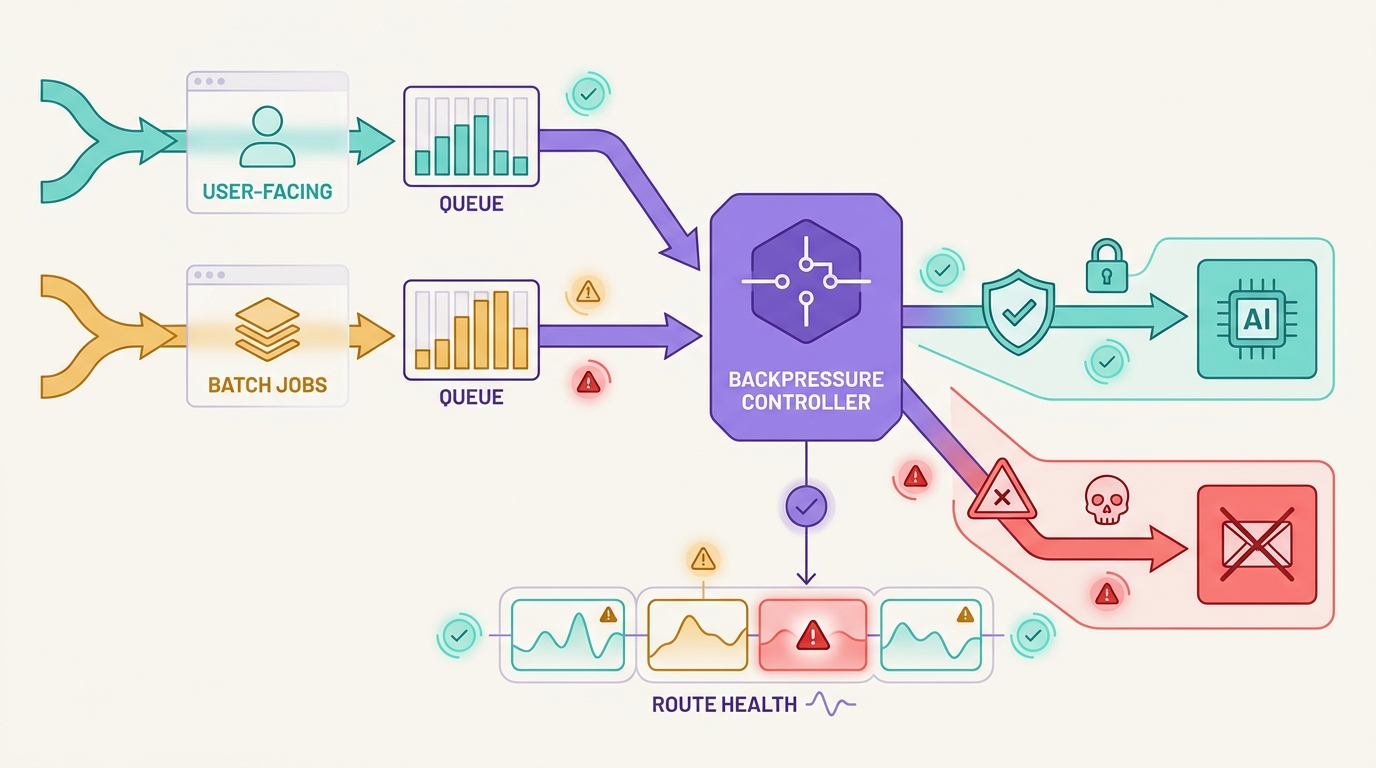
L'objectif de la gestion de la limitation de débit des API d'IA est de maintenir le travail dans des limites définies. Certaines requêtes devraient utiliser un backoff. D'autres devraient être placées dans une file d'attente. Certaines peuvent se rabattre sur une route approuvée. D'autres encore devraient échouer en mode fail-closed, car changer de modèle, de support d'outils, de limite de données ou de coût serait plus risqué que de renvoyer un échec contrôlé. Flatkey s'adapte à ce modèle de fonctionnement, car les équipes peuvent conserver l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels dans une seule interface de passerelle tout en validant le catalogue actuel et les preuves de requêtes.
Gestion de la limitation de débit des API d'IA en un tableau
Utilisez ce tableau comme première ébauche pour la conception de votre politique de production.
| Signal | Signification probable | Backoff | File d'attente | Fallback | Fail-closed |
|---|---|---|---|---|---|
HTTP 429 avec Retry-After | Le fournisseur ou la passerelle a donné une indication d'attente | Respecter l'en-tête, puis réessayer si le budget du workflow le permet | Mettre en file d'attente le travail non interactif jusqu'à l'heure de la nouvelle tentative | Uniquement si une route approuvée peut préserver le contrat de sortie | Arrêter si le temps de nouvelle tentative dépasse l'échéance de l'utilisateur ou de la tâche |
HTTP 429 sans Retry-After | Le compartiment de débit, le compartiment de jetons, le niveau du projet ou la protection des dépenses a été atteint | Utiliser un backoff exponentiel plafonné avec jitter | Mettre en file d'attente le travail par lots et réduire la simultanéité | Éviter un fallback large et immédiat tant que la source de la limite n'est pas connue | Arrêter si la limite est liée aux dépenses, au quota ou à une politique |
rate_limit_error spécifique au fournisseur | Le fournisseur indique que la requête a dépassé une limite définie | Réessayer uniquement en suivant les recommandations du fournisseur | Réduire le taux de requêtes, le volume de jetons ou la simultanéité | Fallback uniquement vers un modèle ayant une capacité et une approbation équivalentes | Arrêter si le fallback modifie la conformité, le coût ou la classe de qualité |
RESOURCE_EXHAUSTED spécifique au fournisseur | Une limite de requêtes, de jetons, quotidienne ou de dépenses peut être épuisée | Réessayer brièvement lorsque la documentation indique d'attendre et de réessayer | Déplacer les tâches pouvant être reprises dans une file d'attente | Utiliser une route différente uniquement après avoir vérifié les implications sur le niveau et les dépenses | Arrêter lorsque le budget du projet ou la limite quotidienne est épuisé |
| 429 répétés sur plusieurs fournisseurs | Votre application produit peut-être trop de travail | Arrêter d'abord les tempêtes de nouvelles tentatives | Mettre en file d'attente et délester la charge avant de changer de route | Le fallback est une dernière étape, pas la première | Utiliser le fail-closed pour les workflows à haut risque jusqu'à l'examen par les propriétaires |
C'est le cœur de la gestion de la limitation de débit des API d'IA : la décision de réessayer intervient après la classification du signal, et non avant.
Lire le signal du fournisseur avant de réessayer
La documentation officielle des erreurs d'OpenAI utilise le code HTTP 429 pour les requêtes envoyées trop rapidement et distingue également les quotas épuisés ou les limites de facturation de la régulation des requêtes. Les recommandations d'OpenAI sur la limitation de débit conseillent un backoff exponentiel aléatoire et notent que les requêtes infructueuses comptent toujours dans les limites par minute. C'est important, car une boucle de nouvelles tentatives agressive peut aggraver la limite.
La documentation d'Anthropic sur la limitation de débit décrit les limites en termes de requêtes par minute, de jetons d'entrée par minute et de jetons de sortie par minute. La même documentation indique que les limites dépassées renvoient un code 429 avec un en-tête retry-after indiquant combien de temps attendre. La documentation des erreurs d'Anthropic documente également rate_limit_error pour le code HTTP 429 et overloaded_error pour le code HTTP 529, qui doivent être traités différemment dans les rapports d'incident.
La documentation de l'API Gemini de Google décrit les limitations de débit selon des dimensions telles que les requêtes par minute, les jetons par minute, les requêtes par jour et les dépenses. Le dépannage de Gemini associe le code HTTP 429 à RESOURCE_EXHAUSTED et demande aux équipes de vérifier les limitations de débit, d'attendre et de réessayer, de réduire le taux ou la taille des requêtes, ou de demander une augmentation de la limitation de débit.
La conclusion pratique est que la gestion de la limitation de débit des API d'IA nécessite une forme d'erreur normalisée par fournisseur :
| Champ normalisé | Exemples de valeurs | Pourquoi c'est important |
|---|---|---|
http_status | 429, 503, 529 | Sépare la régulation du client de la surcharge du fournisseur |
provider_error_type | rate_limit_error, RESOURCE_EXHAUSTED, insufficient_quota | Indique si une nouvelle tentative est susceptible d'être utile |
retry_after_ms | Délai dérivé de l'en-tête ou nul | Empêche les estimations lorsque le fournisseur a donné un temps d'attente |
limit_dimension | requêtes, jetons d'entrée, jetons de sortie, requêtes quotidiennes, dépenses | Indique à l'équipe ce qu'il faut réduire |
workflow_deadline_ms | budget restant de l'utilisateur ou de la tâche | Décide s'il faut appliquer un backoff, mettre en file d'attente ou arrêter |
retry_scope | même requête, même route, route de fallback approuvée | Empêche les changements accidentels de modèle ou de fournisseur |
Ne masquez pas ces champs derrière un message générique « erreur du fournisseur ». Si le seul fait enregistré est qu'une requête d'IA a échoué, l'équipe ne peut pas ajuster la simultanéité, les budgets, les règles de fallback ou les contrôles de dépenses.
Backoff : nouvelle tentative uniquement lorsque l'attente est limitée
Le backoff est la réponse la plus sûre lorsque la requête peut encore se terminer dans les limites du budget du workflow et que la nouvelle tentative ne dupliquera pas de sortie visible. La couche de backoff doit suivre trois règles :
- Respecter
Retry-Afterlorsqu'il est présent. - Utiliser le jitter pour que tous les workers ne se réveillent pas en même temps.
- Plafonner à la fois le délai et le nombre total de tentatives.
Le champ HTTP Retry-After peut être soit une date HTTP, soit un délai en secondes. Les recommandations de nouvelle tentative de Google Cloud préconisent un backoff exponentiel tronqué avec jitter pour les échecs pouvant faire l'objet d'une nouvelle tentative. Pour la gestion de la limitation de débit des API d'IA, combinez ces idées avec une échéance de workflow :
function retryDelayMs(response: Response, attempt: number, remainingBudgetMs: number) {
const header = response.headers.get("retry-after");
let providerDelayMs: number | null = null;
if (header) {
const seconds = Number(header);
providerDelayMs = Number.isFinite(seconds)
? seconds * 1000
: Math.max(0, Date.parse(header) - Date.now());
}
const exponentialCapMs = Math.min(60_000, 500 * 2 ** attempt);
const jitteredDelayMs = Math.floor(Math.random() * exponentialCapMs);
const delayMs = providerDelayMs ?? jitteredDelayMs;
if (delayMs <= 0 || delayMs > remainingBudgetMs) {
return null;
}
return delayMs;
}Cette fonction d'assistance renvoie intentionnellement null lorsque la nouvelle tentative dépasserait la durée du workflow. Dans une requête destinée à l'utilisateur, cela peut signifier un message d'échec élégant. Dans un workflow par lots, cela peut signifier la mise en file d'attente de la tâche. Dans un workflow financier ou de conformité, cela peut signifier un arrêt pour examen par le propriétaire.
Le backoff doit également tenir compte des couches de nouvelles tentatives cachées. Les nouvelles tentatives du SDK, de la passerelle, de la file d'attente et de l'application se multiplient toutes. Si le SDK réessaye déjà les erreurs de niveau 429 et 500, l'application devrait réduire ses propres tentatives plutôt que d'empiler une autre boucle de nouvelle tentative par-dessus. Utilisez le guide Flatkey sur la stratégie de nouvelle tentative pour les API d'IA lorsque vous avez besoin d'une checklist complémentaire uniquement pour les nouvelles tentatives.
File d'attente : absorber la demande lorsque le travail peut attendre
La mise en file d'attente est préférable à la nouvelle tentative lorsque la requête est valide mais que le moment présent ne l'est pas. C'est courant pour la résumé par lots, l'extraction nocturne, les tâches d'évaluation, la révision de longs documents et les automatisations non urgentes.
Une politique de file d'attente ne doit pas être « réessayer plus tard indéfiniment ». Elle a besoin d'un budget :
| Champ de la file d'attente | Règle de production |
|---|---|
max_queue_age_ms | Abandonner ou reclassifier le travail une fois qu'il est obsolète |
retry_after_ready_at | Ne pas libérer la tâche avant le temps d'attente du fournisseur |
concurrency_key | Regrouper par fournisseur, modèle, famille de points de terminaison, client ou clé de propriétaire |
token_budget | Réduire la taille du prompt ou la taille du lot avant de réessayer les tâches volumineuses |
idempotency_key | Empêcher les tâches coûteuses en double après le redémarrage des workers |
owner | Attribuer la responsabilité des coûts et des incidents |
La mise en file d'attente est également l'endroit où contrôler les pics de charge. Si dix workers rencontrent tous le même code 429, la file d'attente doit ralentir l'ensemble de la clé de simultanéité, et pas seulement les dix tâches individuelles. Sinon, chaque worker applique un backoff indépendamment et la vague suivante répète la même erreur.
Pour les utilisateurs de Flatkey, c'est là que le routage à clé unique et les preuves d'utilisation deviennent opérationnellement utiles. Maintenez la décision de mise en file d'attente liée à la clé du propriétaire, à la famille de points de terminaison, au modèle demandé, au modèle servi et au signal de coût. L'équipe peut alors examiner si la limitation de débit provenait d'un seul client, d'une seule automatisation, d'une seule classe de modèle ou d'un pic général du produit.
Fallback : changer de route uniquement lorsque le contrat est toujours valable
Le fallback n'est pas une nouvelle tentative plus forte. Il change quelque chose : le fournisseur, le modèle, la route, le coût, le profil de latence, le comportement de l'outil, la frontière des données, le statut d'approbation ou la qualité de la sortie. La gestion de la limitation de débit des API d'IA devrait donc exiger un contrat de fallback explicite.
Utilisez cette checklist avant d'activer le fallback automatique :
| Vérification | Question requise |
|---|---|
| Capacité | La route de fallback prend-elle en charge la même forme de point de terminaison, les mêmes outils, le même mode de streaming, la même sortie structurée et les mêmes exigences de contexte ? |
| Qualité | Le modèle de fallback est-il approuvé pour ce workflow destiné à l'utilisateur ou interne ? |
| Coût | Le fallback pourrait-il dépasser le budget qui a déclenché l'incident ? |
| Frontière des données | La route préserve-t-elle les contraintes requises de fournisseur, de région, de vendeur et d'approbation d'achat ? |
| Sortie partielle | L'utilisateur a-t-il déjà vu des jetons ou des résultats d'outils ? |
| Observabilité | Les journaux afficheront-ils le modèle demandé, le modèle servi, la raison du fallback et les unités d'utilisation ? |
Le fallback est généralement sûr avant que toute sortie visible ne soit validée, et risqué après le début de la sortie partielle. Un chat de support peut souvent afficher une défaillance courte et contrôlée plus proprement qu'il ne peut insérer une réponse de fallback au milieu d'une réponse streamée. Si le streaming est le principal mode de défaillance, associez cette politique à la fiabilité des API d'IA en streaming. Une tâche d'extraction structurée peut souvent effectuer une nouvelle tentative ou être mise en file d'attente ; un workflow d'approvisionnement peut nécessiter un fail-closed car la liste des modèles/fournisseurs approuvés est plus importante que la commodité.
Associez cette politique au guide Flatkey sur l'évaluation du fallback de modèle lorsque vous avez besoin d'une matrice d'approbation de route plus approfondie.
Fail-closed : s'arrêter lorsqu'une nouvelle tentative créerait un risque
Le fail-closed peut sembler conservateur, mais c'est souvent le résultat le plus économique et le plus fiable en cas de limitation de débit. Arrêtez-vous au lieu de réessayer ou de basculer sur un fallback lorsque :
- L'erreur indique des crédits épuisés, un budget mensuel dépassé, un quota de requêtes quotidien atteint ou des limites basées sur les dépenses.
Retry-Afterest plus long que la requête de l'utilisateur ou l'échéance de la tâche.- Le workflow a déjà validé une sortie partielle.
- La route de fallback modifie le schéma, la disponibilité des outils, la modalité, la frontière des données ou l'approbation d'achat.
- La requête est à haut risque : examen financier, examen juridique, automatisation destinée aux clients, données réglementées ou actions irréversibles.
- Les nouvelles tentatives dupliqueraient un grand prompt, un workflow d'outil, une génération d'image/vidéo ou un effet de bord externe.
La gestion en fail-closed nécessite toujours une expérience utilisateur et opérateur. Affichez un état d'erreur utile, enregistrez la source de la limite, conservez l'ID de la requête et indiquez au propriétaire quel budget a arrêté la requête. L'objectif n'est pas de cacher l'échec ; l'objectif est d'arrêter le travail non contrôlé tout en conservant suffisamment de preuves pour en corriger la cause.
Une politique pratique de gestion de la limitation de débit des API d'IA
Commencez avec un petit fichier de politique avant d'écrire du code de nouvelle tentative. Les chiffres exacts devraient provenir du trafic de production, mais la structure doit exister avant le premier incident :
workflow: customer_support_chat
rate_limit:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- requested_model
- served_model
- endpoint_family
backoff:
max_attempts_total: 2
respect_retry_after: true
jitter: full
max_delay_ms: 30000
retry_only_before_partial_output: true
queue:
enabled_for:
- batch_summary
- offline_extraction
- evaluation_job
max_queue_age_ms: 900000
concurrency_key:
- owner_key
- endpoint_family
- requested_model
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- quota_or_spend_exhausted
- retry_after_exceeds_deadline
- partial_output_committed
- fallback_contract_mismatch
- high_risk_workflowCe modèle rend les conditions d'arrêt visibles. Il aide également les relecteurs à voir que la gestion de la limitation de débit des API d'IA n'est pas seulement un paramètre de SDK ; c'est une politique de produit, de fiabilité et de contrôle des coûts.
Champs d'observabilité pour les incidents de limitation de débit
Un incident de limitation de débit n'est débogable que si les journaux peuvent répondre à ce qui a été limité et à ce que l'application a fait ensuite.
| Champ | Pourquoi le journaliser |
|---|---|
workflow | Relie la limite à une surface produit |
owner_key, team, ou customer_id | Attribue la responsabilité des coûts et de la capacité |
endpoint_family | Sépare le chat, les réponses, les messages, Gemini, l'image, la vidéo et d'autres formes |
requested_model et served_model | Indique si le routage ou le fallback a modifié le comportement |
http_status et provider_error_type | Distingue la régulation 429, le quota, la surcharge et la défaillance du serveur |
retry_after_ms | Prouve si le client a respecté les directives du fournisseur |
attempt_number et total_attempts | Détecte l'amplification des nouvelles tentatives |
queue_age_ms | Indique si la mise en file d'attente a protégé ou retardé le workflow |
fallback_reason | Explique pourquoi la route a changé |
partial_output_committed | Empêche la duplication non sécurisée de la sortie visible par l'utilisateur |
usage_units et estimated_cost | Rend le travail dupliqué visible pour la finance et les opérateurs |
Le site public actuel de Flatkey positionne le produit comme une passerelle unique pour l'accès aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. L'instantané de l'API de tarification du 3 juillet 2026 a renvoyé success: true, la version de tarification a42d372ccf0b5dd13ecf71203521f9d2, 45 lignes de modèles, 48 lignes de fournisseurs et des familles de points de terminaison prises en charge, notamment openai, anthropic, gemini, image-generation, openai-video et video. Considérez ces faits comme des preuves datées, et non comme des affirmations de disponibilité permanente. Validez toujours le catalogue actuel et effectuez un test de routage avant le déploiement en production.
Checklist de déploiement
Utilisez ce parcours de déploiement lorsque vous ajoutez ou révisez la gestion de la limitation de débit des API d'IA :
- Choisissez un workflow et nommez le propriétaire.
- Normalisez les erreurs des fournisseurs en un format interne unique de limitation de débit.
- Analysez
Retry-Aftersoit comme un délai en secondes, soit comme une date HTTP. - Définissez un backoff avec jitter plafonné avec un budget total de tentatives.
- Déplacez le travail non interactif dans une file d'attente avec un âge maximum et des clés d'idempotence.
- Définissez des contrats de fallback par format de point de terminaison, capacité du modèle, coût et frontière des données.
- Définissez les conditions de fail-closed avant d'activer le fallback.
- Ajoutez des journaux pour la dimension de la limite, le délai de nouvelle tentative, l'âge dans la file d'attente, la raison du fallback et le coût.
- Testez les erreurs 429 avec et sans
Retry-After, l'épuisement des quotas, le trafic en rafale, la sortie de streaming partielle et la surcharge du fournisseur. - Examinez les preuves d'utilisation et de routage dans Flatkey avant d'étendre la politique au workflow suivant.
La meilleure gestion de la limitation de débit des API d'IA rend la pression sur la capacité sans histoire. L'application attend lorsque l'attente est sûre, met le travail en file d'attente lorsqu'il peut attendre, change de route uniquement lorsque le contrat est toujours respecté, et s'arrête lorsque la poursuite créerait un coût ou un risque caché.
FAQ
Qu'est-ce que la gestion de la limitation de débit des API d'IA ?
La gestion de la limitation de débit des API d'IA est la politique et le code qui classifient les signaux de limitation de débit, respectent les indications d'attente du fournisseur, appliquent un backoff limité, mettent le travail en file d'attente le cas échéant, contrôlent le fallback et s'arrêtent en toute sécurité lorsque de nouvelles tentatives créeraient un coût ou un risque.
Faut-il relancer chaque erreur 429 ?
Non. Ne relancez que lorsque la requête peut encore se terminer dans le budget du workflow et que l'erreur est probablement temporaire. Les cas de quota, de dépense, de limite quotidienne, de sortie partielle et de non-concordance de contrat devraient généralement être mis en file d'attente ou échouer en mode fail-closed.
Le backoff exponentiel est-il suffisant pour les charges de travail d'IA ?
Non. Le backoff exponentiel avec jitter est utile, mais les charges de travail d'IA nécessitent également une connaissance des jetons et des dépenses, des budgets de file d'attente, des contrats de fallback, une protection contre les sorties partielles et une observabilité au niveau de la requête.
Quand une requête d'IA limitée en débit doit-elle basculer vers un autre modèle ?
Uniquement lorsque la route de fallback préserve le format de point de terminaison requis, la classe de qualité, le comportement de l'outil, la frontière des données et le plafond de coût. Le fallback devrait normalement se produire avant que la sortie visible ne commence.
Comment Flatkey aide-t-il à la gestion de la limitation de débit des API d'IA ?
Flatkey offre aux équipes une surface de passerelle unique pour l'accès connecté aux modèles, le routage, la facturation, l'analyse de l'utilisation et les contrôles opérationnels. Utilisez-la pour lier les décisions de limitation de débit au modèle, à la famille de points de terminaison, à la clé du propriétaire, aux preuves de routage et à l'examen des coûts.
Commencez par la tarification de Flatkey, choisissez un workflow, puis obtenez une clé et testez votre politique de gestion de la limitation de débit des API d'IA avant d'y envoyer du trafic de production.