Ограничения скорости — это не просто ошибки, которые нужно повторять. В производственных системах ИИ ошибка 429 может означать, что короткий всплеск активности превысил лимит токенов (token bucket), проект достиг потолка запросов в минуту, был достигнут лимит расходов или провайдер просит клиента замедлиться до восстановления мощностей. Хорошая обработка ограничений скорости AI API разделяет эти случаи, прежде чем тратить больше токенов.
Неправильный паттерн прост: каждый воркер видит ошибку 429, ждет одинаковую фиксированную задержку, повторяет запрос в одно и то же время, а затем переключается на другую модель, когда повторные попытки не удаются. Это превращает сигнал о недостаточной мощности в дублирующую нагрузку, более высокие затраты, несогласованный вывод и слабые доказательства инцидента.
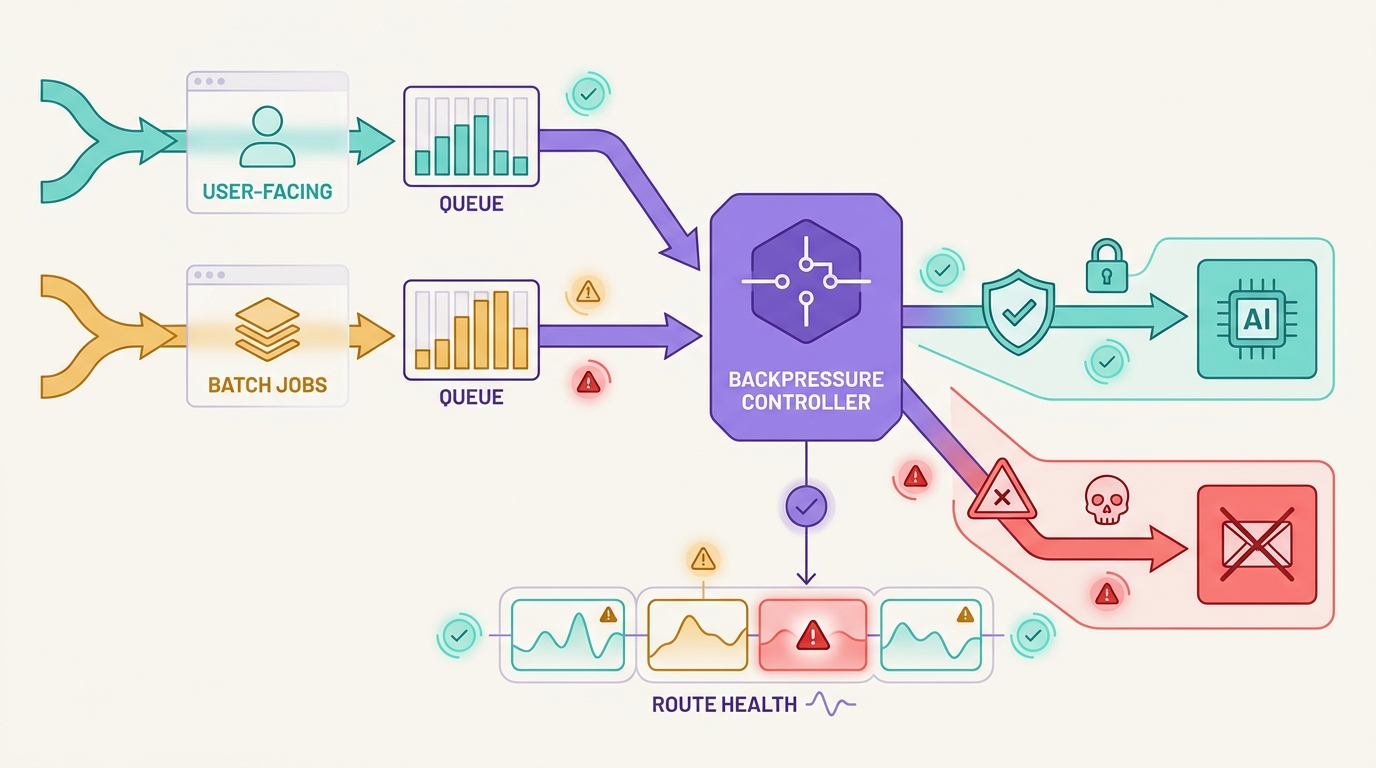
Цель обработки ограничений скорости AI API — удерживать работу в определенных рамках. Некоторые запросы должны использовать механизм backoff. Некоторые должны перемещаться в очередь. Некоторые могут переключаться на утвержденный резервный маршрут (fallback). Некоторые должны завершаться с ошибкой (fail closed), потому что изменение модели, поддержки инструментов, границ данных или стоимости было бы более рискованным, чем возврат контролируемой ошибки. Flatkey подходит для этой операционной модели, потому что команды могут управлять доступом к моделям, маршрутизацией, биллингом, аналитикой использования и операционным контролем в едином интерфейсе шлюза, пока они проверяют текущий каталог и доказательства запросов.
Обработка ограничений скорости AI API в одной таблице
Используйте эту таблицу в качестве первого шага при разработке производственной политики.
| Сигнал | Вероятное значение | Backoff | Очередь | Fallback | Fail closed |
|---|---|---|---|---|---|
HTTP 429 с Retry-After | Провайдер или шлюз предоставил подсказку о времени ожидания | Учитывать заголовок, затем повторить, если позволяет бюджет рабочего процесса | Помещать неинтерактивную работу в очередь до времени повтора | Только если утвержденный маршрут может сохранить контракт вывода | Остановить, если время повтора превышает дедлайн пользователя или задания |
HTTP 429 без Retry-After | Достигнут лимит скорости, лимит токенов, уровень проекта или лимит расходов | Использовать ограниченный экспоненциальный backoff с джиттером | Помещать пакетную работу в очередь и снижать параллелизм | Избегать немедленного широкого fallback до выяснения источника лимита | Остановить, если лимит связан с расходами, квотой или политикой |
Специфичная для провайдера ошибка rate_limit_error | Провайдер сообщает, что запрос превысил определенный лимит | Повторять только в соответствии с рекомендациями провайдера | Снизить частоту запросов, объем токенов или параллелизм | Fallback только на модель с эквивалентными возможностями и одобрением | Остановить, если fallback изменяет соответствие требованиям, стоимость или класс качества |
Специфичная для провайдера ошибка RESOURCE_EXHAUSTED | Возможно, исчерпан лимит запросов, токенов, дневной лимит или лимит расходов | Кратковременно повторить, если документация рекомендует подождать и повторить | Переместить возобновляемые задания в очередь | Использовать другой маршрут только после проверки последствий для уровня и расходов | Остановить, когда исчерпан бюджет проекта или дневной лимит |
| Повторяющиеся ошибки 429 от разных провайдеров | Ваше приложение может генерировать слишком много работы | В первую очередь остановить шторм повторных запросов | Помещать в очередь и сбрасывать нагрузку перед изменением маршрута | Fallback — это последний шаг, а не первый | Использовать fail closed для высокорисковых рабочих процессов до проверки владельцами |
В этом суть обработки ограничений скорости AI API: решение о повторной попытке принимается после классификации сигнала, а не до.
Читайте сигнал от провайдера перед повторной попыткой
Официальная документация по ошибкам OpenAI использует HTTP 429 для слишком быстро отправленных запросов, а также различает исчерпанную квоту или лимиты биллинга и регулирование темпа запросов. Руководство OpenAI по ограничениям скорости рекомендует случайный экспоненциальный backoff и отмечает, что неудачные запросы все равно учитываются в поминутных лимитах. Это важно, потому что агрессивный цикл повторных попыток может усугубить ситуацию с лимитом.
Документация Anthropic по ограничениям скорости описывает лимиты по запросам в минуту, входным токенам в минуту и выходным токенам в минуту. В той же документации говорится, что при превышении лимитов возвращается ошибка 429 с заголовком retry-after, указывающим, как долго нужно ждать. Документация Anthropic по ошибкам также описывает rate_limit_error для HTTP 429 и overloaded_error для HTTP 529, которые следует по-разному обрабатывать в отчетах об инцидентах.
Документация Google по Gemini API описывает ограничения скорости по таким параметрам, как запросы в минуту, токены в минуту, запросы в день и расходы. Руководство по устранению неполадок Gemini сопоставляет HTTP 429 с RESOURCE_EXHAUSTED и советует командам проверять ограничения скорости, ждать и повторять попытку, уменьшать частоту или размер запросов или запрашивать увеличение лимита.
Практический вывод заключается в том, что для обработки ограничений скорости AI API требуется нормализованная для разных провайдеров форма ошибки:
| Нормализованное поле | Примеры значений | Почему это важно |
|---|---|---|
http_status | 429, 503, 529 | Разделяет регулирование скорости клиента и перегрузку провайдера |
provider_error_type | rate_limit_error, RESOURCE_EXHAUSTED, insufficient_quota | Показывает, поможет ли повторная попытка |
retry_after_ms | Задержка, полученная из заголовка, или null | Предотвращает угадывание, когда провайдер указал время ожидания |
limit_dimension | запросы, входные токены, выходные токены, ежедневные запросы, расходы | Сообщает команде, что нужно сократить |
workflow_deadline_ms | оставшийся бюджет пользователя или задания | Определяет, следует ли использовать отсрочку, очередь или остановиться |
retry_scope | тот же запрос, тот же маршрут, утвержденный резервный маршрут | Предотвращает случайное изменение модели или провайдера |
Не скрывайте эти поля за общим сообщением об ошибке провайдера. Если единственный сохраненный факт — это сбой запроса к ИИ, команда не сможет настроить параллелизм, бюджеты, правила резервирования или контроль расходов.
Backoff: повторная попытка только при ограниченном ожидании
Backoff — это самый безопасный ответ, когда запрос все еще может быть завершен в рамках бюджета рабочего процесса, а повторная попыка не приведет к дублированию видимого вывода. Уровень backoff должен следовать трем правилам:
- Учитывать
Retry-After, если он присутствует. - Использовать джиттер, чтобы не все воркеры просыпались одновременно.
- Ограничивать как задержку, так и общее количество попыток.
Поле HTTP Retry-After может быть либо датой в формате HTTP, либо задержкой в секундах. Руководство по повторным попыткам Google Cloud рекомендует использовать усеченную экспоненциальную отсрочку с джиттером для ошибок, допускающих повторную попытку. Для обработки ограничений скорости AI API объедините эти идеи с крайним сроком выполнения рабочего процесса:
function retryDelayMs(response: Response, attempt: number, remainingBudgetMs: number) {
const header = response.headers.get("retry-after");
let providerDelayMs: number | null = null;
if (header) {
const seconds = Number(header);
providerDelayMs = Number.isFinite(seconds)
? seconds * 1000
: Math.max(0, Date.parse(header) - Date.now());
}
const exponentialCapMs = Math.min(60_000, 500 * 2 ** attempt);
const jitteredDelayMs = Math.floor(Math.random() * exponentialCapMs);
const delayMs = providerDelayMs ?? jitteredDelayMs;
if (delayMs <= 0 || delayMs > remainingBudgetMs) {
return null;
}
return delayMs;
}Эта вспомогательная функция намеренно возвращает null, когда повторная попытка превысит время выполнения рабочего процесса. В запросе, обращенном к пользователю, это может означать корректное сообщение об ошибке. В пакетном рабочем процессе это может означать постановку задания в очередь. В рабочем процессе, связанном с финансами или соответствием требованиям, это может означать остановку для проверки владельцем.
Backoff также должен учитывать скрытые уровни повторных попыток. Повторные попытки SDK, шлюза, очереди и приложения — все они умножаются. Если SDK уже повторяет ошибки уровня 429 и 500, приложение должно уменьшить количество собственных попыток, а не добавлять еще один цикл повторов сверху. Используйте руководство Flatkey по стратегии повторных попыток для AI API, когда вам понадобится контрольный список только для повторных попыток.
Очередь: поглощение спроса, когда работа может подождать
Постановка в очередь лучше, чем повторная попытка, когда запрос действителен, но текущий момент неподходящий. Это характерно для пакетного суммирования, ночной выгрузки данных, задач оценки, анализа длинных документов и несрочных автоматизаций.
Политика очереди не должна быть "пробовать позже вечно". Ей нужен бюджет:
| Поле очереди | Правило для продакшена |
|---|---|
max_queue_age_ms | Отбрасывать или переклассифицировать работу, как только она устареет |
retry_after_ready_at | Не выпускать задание до истечения времени ожидания провайдера |
concurrency_key | Группировать по провайдеру, модели, семейству эндпоинтов, клиенту или ключу владельца |
token_budget | Уменьшать размер промпта или пакета перед повторной попыткой больших заданий |
idempotency_key | Предотвращать дублирование дорогостоящих заданий после перезапуска воркеров |
owner | Назначать ответственность за затраты и инциденты |
Очередь также является местом для контроля всплесков нагрузки. Если десять воркеров одновременно получают ошибку 429, очередь должна замедлить весь ключ параллелизма, а не только десять отдельных заданий. В противном случае каждый воркер будет выполнять отсрочку независимо, и следующая волна повторит ту же ошибку.
Для пользователей Flatkey именно здесь маршрутизация по одному ключу и данные об использовании становятся полезными в эксплуатации. Решение о постановке в очередь должно быть связано с ключом владельца, семейством эндпоинтов, запрошенной моделью, предоставленной моделью и сигналом о затратах. Тогда команда сможет проанализировать, было ли ограничение скорости вызвано одним клиентом, одной автоматизацией, одним классом моделей или общим всплеском активности продукта.
Fallback: изменение маршрутов только при сохранении контракта
Fallback — это не просто усиленная повторная попытка. Он что-то меняет: провайдера, модель, маршрут, стоимость, профиль задержки, поведение инструмента, границы данных, статус утверждения или качество вывода. Поэтому обработка ограничений скорости AI API должна требовать явного контракта на fallback.
Используйте этот контрольный список перед включением автоматического fallback:
| Проверка | Обязательный вопрос |
|---|---|
| Возможность | Поддерживает ли резервный маршрут ту же форму конечной точки, инструменты, режим потоковой передачи, структурированный вывод и требования к контексту? |
| Качество | Одобрена ли резервная модель для этого рабочего процесса, ориентированного на пользователя или внутреннего? |
| Стоимость | Может ли использование резервного варианта превысить бюджет, который вызвал инцидент? |
| Граница данных | Сохраняет ли маршрут требуемые ограничения по провайдеру, региону, поставщику и утверждению закупок? |
| Частичный вывод | Видел ли пользователь уже токены или результаты работы инструментов? |
| Наблюдаемость | Будут ли в логах отображаться запрошенная модель, обслуживаемая модель, причина перехода на резервный вариант и единицы использования? |
Переход на резервный вариант обычно безопасен до фиксации любого видимого вывода и рискован после начала частичного вывода. В чате поддержки часто можно более аккуратно показать короткий контролируемый сбой, чем вставить резервный ответ в середину потокового ответа. Если потоковая передача является основным режимом сбоя, сочетайте эту политику с надежностью потоковой передачи AI API. Задача структурированного извлечения часто может повторить попытку или встать в очередь; рабочий процесс закупки может потребовать отказа с закрытием (fail closed), потому что утвержденный список моделей/поставщиков важнее удобства.
Сочетайте эту политику с руководством Flatkey по оценке резервных моделей, когда вам понадобится более подробная матрица утверждения маршрутов.
Fail closed: остановка, когда повторная попытка создает риск
Отказ с закрытием (Failing closed) звучит консервативно, но часто это самый дешевый и надежный исход при ограничении скорости. Останавливайтесь вместо повторных попыток или перехода на резервный вариант, когда:
- Ошибка указывает на исчерпание кредитов, месячного бюджета, дневной квоты запросов или лимитов на основе расходов.
Retry-Afterпревышает срок выполнения запроса пользователя или задания.- Рабочий процесс уже зафиксировал частичный вывод.
- Резервный маршрут изменяет схему, доступность инструментов, модальность, границу данных или утверждение закупки.
- Запрос является высокорисковым: финансовый анализ, юридическая проверка, автоматизация для клиентов, регулируемые данные или необратимые действия.
- Повторные попытки приведут к дублированию большого промпта, рабочего процесса инструмента, генерации изображений/видео или внешнего побочного эффекта.
Обработка с отказом и закрытием (Fail-closed) все равно требует проработки пользовательского и операторского опыта. Покажите полезное состояние ошибки, запишите источник ограничения, сохраните идентификатор запроса и сообщите владельцу, какой бюджет остановил запрос. Цель не в том, чтобы скрыть сбой, а в том, чтобы остановить неконтролируемую работу, сохранив при этом достаточно доказательств для устранения причины.
Практическая политика обработки ограничений скорости AI API
Начните с небольшого файла политики, прежде чем писать код для повторных попыток. Точные числа должны быть получены из производственного трафика, но структура должна существовать до первого инцидента:
workflow: customer_support_chat
rate_limit:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- requested_model
- served_model
- endpoint_family
backoff:
max_attempts_total: 2
respect_retry_after: true
jitter: full
max_delay_ms: 30000
retry_only_before_partial_output: true
queue:
enabled_for:
- batch_summary
- offline_extraction
- evaluation_job
max_queue_age_ms: 900000
concurrency_key:
- owner_key
- endpoint_family
- requested_model
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- quota_or_spend_exhausted
- retry_after_exceeds_deadline
- partial_output_committed
- fallback_contract_mismatch
- high_risk_workflowЭтот шаблон делает условия остановки видимыми. Он также помогает рецензентам понять, что обработка ограничений скорости AI API — это не просто настройка SDK, а политика, касающаяся продукта, надежности и контроля затрат.
Поля наблюдаемости для инцидентов с ограничением скорости
Инцидент с ограничением скорости можно отладить только в том случае, если логи могут ответить на вопрос, что было ограничено и что приложение сделало дальше.
| Поле | Зачем это логировать |
|---|---|
workflow | Связывает ограничение с интерфейсом продукта |
owner_key, team или customer_id | Назначает ответственных за затраты и ресурсы |
endpoint_family | Разделяет чат, ответы, сообщения, Gemini, изображения, видео и другие форматы |
requested_model и served_model | Показывает, изменили ли маршрутизация или переход на резервный вариант поведение |
http_status и provider_error_type | Различает ограничение скорости 429, квоту, перегрузку и сбой сервера |
retry_after_ms | Подтверждает, следовал ли клиент указаниям провайдера |
attempt_number и total_attempts | Обнаруживает усиление повторных попыток |
queue_age_ms | Показывает, защитила ли очередь или задержала рабочий процесс |
fallback_reason | Объясняет, почему изменился маршрут |
partial_output_committed | Предотвращает небезопасный дублирующийся вывод, видимый пользователю |
usage_units и estimated_cost | Делает дублирующуюся работу видимой для финансового отдела и операторов |
На текущем публичном сайте Flatkey продукт позиционируется как единый шлюз для доступа к моделям, маршрутизации, биллинга, аналитики использования и операционного контроля. Снимок API цен от 3 июля 2026 года вернул success: true, версию цен a42d372ccf0b5dd13ecf71203521f9d2, 45 строк моделей, 48 строк поставщиков и поддерживаемые семейства эндпоинтов, включая openai, anthropic, gemini, image-generation, openai-video и video. Рассматривайте эти факты как устаревшие данные, а не как постоянные заявления о доступности. Всегда проверяйте текущий каталог и проводите тест маршрута перед развертыванием в производственной среде.
Контрольный список развертывания
Используйте этот план развертывания при добавлении или пересмотре обработки ограничений скорости AI API:
- Выберите один рабочий процесс и назначьте ответственного.
- Нормализуйте ошибки провайдеров в единый внутренний формат ограничения скорости.
- Разбирайте
Retry-Afterкак задержку в секундах или как дату HTTP. - Установите ограниченный backoff с джиттером и общим бюджетом попыток.
- Переместите неинтерактивную работу в очередь с максимальным временем жизни и ключами идемпотентности.
- Определите контракты для fallback по формату эндпоинта, возможностям модели, стоимости и границам данных.
- Определите условия для fail-closed перед включением fallback.
- Добавьте логи для размерности лимита, задержки повтора, времени нахождения в очереди, причины fallback и стоимости.
- Протестируйте ошибку 429 с
Retry-Afterи без него, исчерпание квоты, всплески трафика, частичный потоковый вывод и перегрузку провайдера. - Проанализируйте данные об использовании и маршрутизации в Flatkey перед распространением политики на следующий рабочий процесс.
Лучшая обработка ограничений скорости AI API делает проблемы с производительностью предсказуемыми. Приложение ожидает, когда ожидание безопасно, ставит работу в очередь, когда она может подождать, меняет маршрут только тогда, когда контракт все еще соблюдается, и останавливается, когда продолжение создаст скрытые затраты или риски.
Часто задаваемые вопросы
Что такое обработка ограничений скорости AI API?
Обработка ограничений скорости AI API — это политика и код, которые классифицируют сигналы об ограничении скорости, учитывают указания провайдера на ожидание, применяют ограниченный backoff, при необходимости ставят работу в очередь, контролируют fallback и безопасно останавливаются, когда повторные попытки могут создать затраты или риски.
Следует ли повторять каждый запрос с ошибкой 429?
Нет. Повторяйте запрос только тогда, когда он все еще может завершиться в рамках бюджета рабочего процесса, а ошибка, скорее всего, временная. Случаи с исчерпанием квоты, бюджета, дневного лимита, частичным выводом и несоответствием контракта обычно должны ставиться в очередь или завершаться с отказом (fail closed).
Достаточно ли экспоненциального backoff для рабочих нагрузок ИИ?
Нет. Экспоненциальный backoff с джиттером полезен, но рабочие нагрузки ИИ также требуют учета токенов и затрат, бюджетов очередей, контрактов для fallback, защиты от частичного вывода и наблюдаемости на уровне запросов.
Когда запрос к AI API с ограничением скорости должен переключаться на другую модель (fallback)?
Только когда альтернативный маршрут (fallback) сохраняет требуемый формат эндпоинта, класс качества, поведение инструментов, границы данных и предел стоимости. Fallback обычно должен происходить до начала видимого вывода.
Как Flatkey помогает с обработкой ограничений скорости AI API?
Flatkey предоставляет командам единый шлюз для доступа к подключенным моделям, маршрутизации, биллинга, аналитики использования и операционного контроля. Используйте его, чтобы решения об ограничении скорости были связаны с моделью, семейством эндпоинтов, ключом владельца, данными о маршрутах и анализом затрат.
Начните с цен Flatkey, выберите один рабочий процесс, затем получите ключ и протестируйте свою политику обработки ограничений скорости AI API, прежде чем направлять через нее производственный трафик.