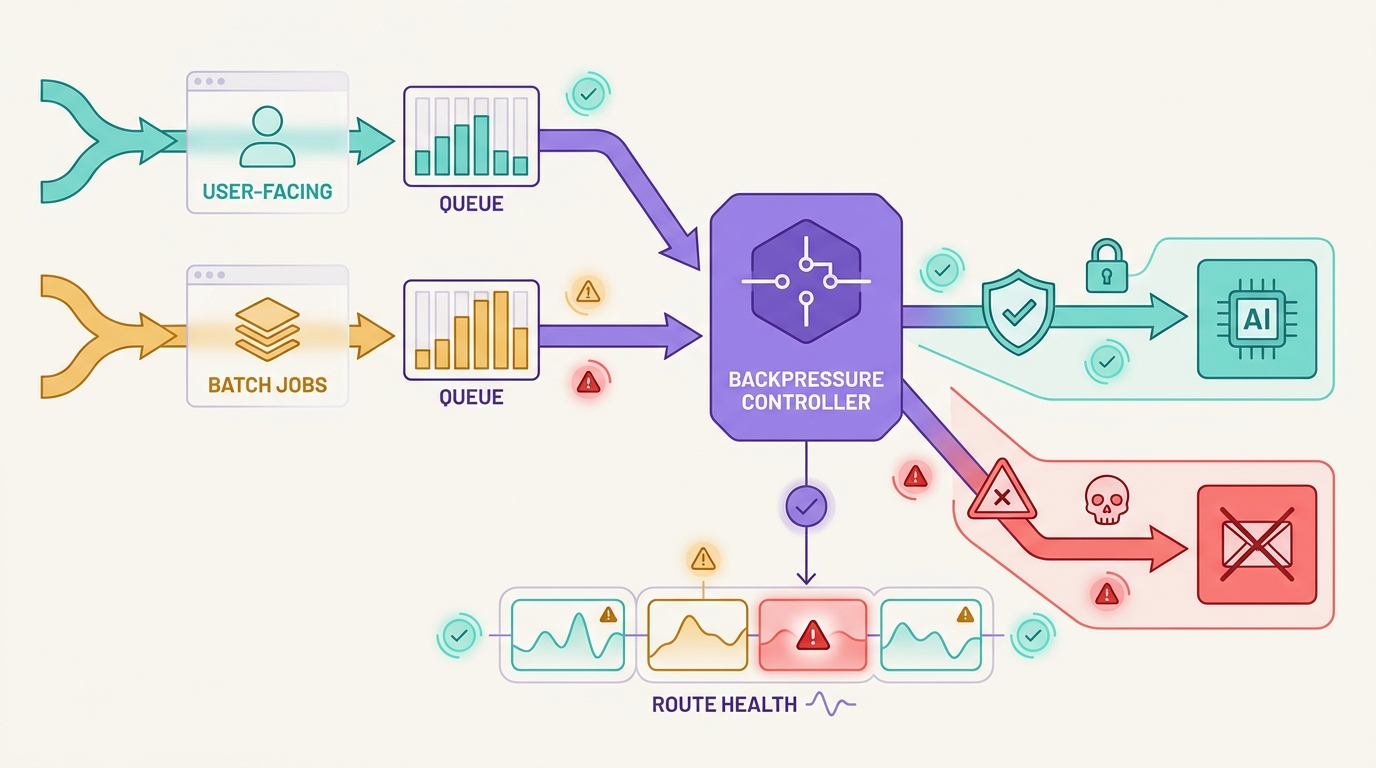
Rate limits are not just errors to retry. In production AI systems, a 429 can mean a short burst crossed a token bucket, a project hit a requests-per-minute ceiling, a spend cap was reached, or a provider is asking the client to slow down before capacity recovers. Good AI API rate limit handling separates those cases before it spends more tokens.
The wrong pattern is simple: every worker sees a 429, sleeps for the same fixed delay, retries at the same time, and then falls back to a different model when the retries fail. That turns a capacity signal into duplicate load, higher cost, inconsistent output, and weak incident evidence.
The goal of AI API rate limit handling is to keep work bounded. Some requests should back off. Some should move into a queue. Some can fall back to an approved route. Some should fail closed because changing model, tool support, data boundary, or cost would be riskier than returning a controlled failure. Flatkey fits this operating model because teams can keep model access, routing, billing, usage analytics, and operational controls in one gateway surface while they validate the current catalog and request evidence.
AI API rate limit handling in one table
Use this table as the first pass for production policy design.
| Signal | Likely meaning | Backoff | Queue | Fallback | Fail closed |
|---|---|---|---|---|---|
HTTP 429 with Retry-After |
Provider or gateway has given a wait hint | Respect the header, then retry if the workflow budget allows | Queue non-interactive work until the retry time | Only if an approved route can preserve the output contract | Stop if retry time exceeds user or job deadline |
HTTP 429 without Retry-After |
Rate bucket, token bucket, project tier, or spend guard was hit | Use capped exponential backoff with jitter | Queue batch work and reduce concurrency | Avoid immediate broad fallback until the limit source is known | Stop if the limit is spend, quota, or policy-related |
Provider-specific rate_limit_error |
Provider says the request exceeded a defined limit | Retry only inside the provider's guidance | Lower request rate, token volume, or concurrency | Fallback only to a model with equivalent capability and approval | Stop if fallback changes compliance, cost, or quality class |
Provider-specific RESOURCE_EXHAUSTED |
A request, token, daily, or spend limit may be exhausted | Retry briefly when the docs say wait and retry | Move resumable jobs to a queue | Use a different route only after checking tier and spend implications | Stop when the project budget or daily limit is exhausted |
| Repeated 429 across providers | Your app may be overproducing work | Stop retry storms first | Queue and shed load before route changes | Fallback is a last step, not the first step | Fail closed for high-risk workflows until owners review |
This is the core of AI API rate limit handling: the retry decision comes after the signal is classified, not before.
Read the provider signal before retrying
Official provider docs use different names for similar capacity problems. OpenAI documents HTTP 429 for requests sent too quickly and also distinguishes exhausted quota or billing limits from request pacing. Its rate-limit guidance recommends random exponential backoff and notes that unsuccessful requests still count toward per-minute limits. That matters because an aggressive retry loop can make the limit worse.
Anthropic's rate-limit docs describe limits across requests per minute, input tokens per minute, and output tokens per minute. The same docs say that exceeded limits return a 429 with a retry-after header indicating how long to wait. Anthropic also documents rate_limit_error for HTTP 429 and overloaded_error for HTTP 529, which should be treated differently in incident reports.
Google's Gemini API docs describe rate limits across dimensions such as requests per minute, tokens per minute, requests per day, and spend. Gemini troubleshooting maps HTTP 429 to RESOURCE_EXHAUSTED and tells teams to verify rate limits, wait and retry, reduce request rate or size, or request a rate-limit increase.
The practical takeaway is that AI API rate limit handling needs a provider-normalized error shape:
| Normalized field | Example values | Why it matters |
|---|---|---|
http_status |
429, 503, 529 |
Separates client pacing from provider overload |
provider_error_type |
rate_limit_error, RESOURCE_EXHAUSTED, insufficient_quota |
Shows whether retry is likely to help |
retry_after_ms |
Header-derived delay or null | Prevents guessing when the provider has given a wait time |
limit_dimension |
requests, input tokens, output tokens, daily requests, spend | Tells the team what to reduce |
workflow_deadline_ms |
remaining user or job budget | Decides whether to back off, queue, or stop |
retry_scope |
same request, same route, approved fallback route | Prevents accidental model or provider changes |
Do not hide these fields behind a generic "provider error" message. If the only stored fact is that an AI request failed, the team cannot tune concurrency, budgets, fallback rules, or spend controls.
Backoff: retry only when the wait is bounded
Backoff is the safest response when the request can still finish inside the workflow budget and retrying will not duplicate visible output. The backoff layer should follow three rules:
- Respect
Retry-Afterwhen it is present. - Use jitter so every worker does not wake up at the same time.
- Cap both the delay and the total number of attempts.
The HTTP Retry-After field can be either an HTTP date or a delay in seconds. Google Cloud's retry guidance recommends truncated exponential backoff with jitter for retryable failures. For AI API rate limit handling, combine those ideas with a workflow deadline:
function retryDelayMs(response: Response, attempt: number, remainingBudgetMs: number) {
const header = response.headers.get("retry-after");
let providerDelayMs: number | null = null;
if (header) {
const seconds = Number(header);
providerDelayMs = Number.isFinite(seconds)
? seconds * 1000
: Math.max(0, Date.parse(header) - Date.now());
}
const exponentialCapMs = Math.min(60_000, 500 * 2 ** attempt);
const jitteredDelayMs = Math.floor(Math.random() * exponentialCapMs);
const delayMs = providerDelayMs ?? jitteredDelayMs;
if (delayMs <= 0 || delayMs > remainingBudgetMs) {
return null;
}
return delayMs;
}
That helper intentionally returns null when the retry would outlive the workflow. In a user-facing request, that may mean a graceful failure message. In a batch workflow, it may mean enqueueing the job. In a finance or compliance workflow, it may mean stopping for owner review.
Backoff should also account for hidden retry layers. SDK retries, gateway retries, queue retries, and application retries all multiply. If the SDK already retries 429 and 500-level errors, the application should lower its own attempts rather than stacking another retry loop on top. Use the Flatkey guide on AI API retry strategy when you need a retry-only companion checklist.
Queue: absorb demand when work can wait
Queueing is better than retrying when the request is valid but the current moment is not. That is common for batch summarization, nightly extraction, evaluation jobs, long document review, and non-urgent automations.
A queue policy should not be "try later forever." It needs a budget:
| Queue field | Production rule |
|---|---|
max_queue_age_ms |
Drop or reclassify work once it is stale |
retry_after_ready_at |
Do not release the job before the provider wait time |
concurrency_key |
Group by provider, model, endpoint family, customer, or owner key |
token_budget |
Reduce prompt size or batch size before retrying large jobs |
idempotency_key |
Prevent duplicate expensive jobs after worker restarts |
owner |
Assign cost and incident responsibility |
Queueing is also the place to control surge. If ten workers all hit the same 429, the queue should slow the whole concurrency key, not just the ten individual jobs. Otherwise each worker backs off independently and the next wave repeats the same mistake.
For Flatkey users, this is where one-key routing and usage evidence become operationally useful. Keep the queue decision tied to the owner key, endpoint family, requested model, served model, and cost signal. Then the team can review whether the rate limit came from one customer, one automation, one model class, or a broad product spike.
Fallback: change routes only when the contract still holds
Fallback is not a stronger retry. It changes something: provider, model, route, cost, latency profile, tool behavior, data boundary, approval status, or output quality. AI API rate limit handling should therefore require an explicit fallback contract.
Use this checklist before enabling automatic fallback:
| Check | Required question |
|---|---|
| Capability | Does the fallback route support the same endpoint shape, tools, streaming mode, structured output, and context requirement? |
| Quality | Is the fallback model approved for this user-facing or internal workflow? |
| Cost | Could fallback exceed the budget that triggered the incident? |
| Data boundary | Does the route preserve the required provider, region, vendor, and procurement approval constraints? |
| Partial output | Has the user already seen tokens or tool results? |
| Observability | Will logs show requested model, served model, fallback reason, and usage units? |
Fallback is usually safe before any visible output is committed and risky after partial output starts. A support chat can often show a short controlled failure more cleanly than it can splice a fallback answer into the middle of a streamed response. If streaming is the main failure mode, pair this policy with streaming AI API reliability. A structured extraction job can often retry or queue; a procurement workflow may need to fail closed because the approved model/vendor list matters more than convenience.
Pair this policy with the Flatkey guide on model fallback evaluation when you need a deeper route approval matrix.
Fail closed: stop when retry would create risk
Failing closed sounds conservative, but it is often the cheapest and most reliable rate-limit outcome. Stop instead of retrying or falling back when:
- The error indicates exhausted credits, monthly budget, daily request quota, or spend-based limits.
Retry-Afteris longer than the user request or job deadline.- The workflow has already committed partial output.
- The fallback route changes schema, tool availability, modality, data boundary, or procurement approval.
- The request is high-risk: finance review, legal review, customer-facing automation, regulated data, or irreversible actions.
- Retries would duplicate a large prompt, tool workflow, image/video generation, or external side effect.
Fail-closed handling still needs a user and operator experience. Show a useful error state, record the limit source, preserve the request ID, and tell the owner which budget stopped the request. The goal is not to hide failure; the goal is to stop uncontrolled work while keeping enough evidence to fix the cause.
A practical AI API rate limit handling policy
Start with a small policy file before writing retry code. The exact numbers should come from production traffic, but the structure should exist before the first incident:
workflow: customer_support_chat
rate_limit:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- requested_model
- served_model
- endpoint_family
backoff:
max_attempts_total: 2
respect_retry_after: true
jitter: full
max_delay_ms: 30000
retry_only_before_partial_output: true
queue:
enabled_for:
- batch_summary
- offline_extraction
- evaluation_job
max_queue_age_ms: 900000
concurrency_key:
- owner_key
- endpoint_family
- requested_model
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- quota_or_spend_exhausted
- retry_after_exceeds_deadline
- partial_output_committed
- fallback_contract_mismatch
- high_risk_workflow
This template makes the stop conditions visible. It also helps reviewers see that AI API rate limit handling is not just an SDK setting; it is a product, reliability, and cost-control policy.
Observability fields for rate-limit incidents
A rate-limit incident is only debuggable if the logs can answer what was limited and what the application did next.
| Field | Why to log it |
|---|---|
workflow |
Connects the limit to a product surface |
owner_key, team, or customer_id |
Assigns cost and capacity ownership |
endpoint_family |
Separates chat, responses, messages, Gemini, image, video, and other shapes |
requested_model and served_model |
Shows whether routing or fallback changed behavior |
http_status and provider_error_type |
Distinguishes 429 pacing, quota, overload, and server failure |
retry_after_ms |
Proves whether the client respected provider guidance |
attempt_number and total_attempts |
Finds retry amplification |
queue_age_ms |
Shows whether queueing protected or delayed the workflow |
fallback_reason |
Explains why the route changed |
partial_output_committed |
Prevents unsafe duplicate user-visible output |
usage_units and estimated_cost |
Makes duplicate work visible to finance and operators |
For teams that need one place to manage model access, Flatkey is positioned as more than a simple API gateway. It brings routing, billing, usage analytics, and operational controls into the same workflow, which matters when a product depends on multiple model providers instead of a single fixed endpoint.
Rollout checklist
Use this rollout path when you add or revise AI API rate limit handling:
- Pick one workflow and name the owner.
- Normalize provider errors into one internal rate-limit shape.
- Parse
Retry-Afteras either delay seconds or HTTP date. - Set capped jittered backoff with a total attempt budget.
- Move non-interactive work into a queue with max age and idempotency keys.
- Define fallback contracts by endpoint shape, model capability, cost, and data boundary.
- Define fail-closed conditions before enabling fallback.
- Add logs for limit dimension, retry delay, queue age, fallback reason, and cost.
- Test 429 with and without
Retry-After, quota exhaustion, burst traffic, partial streaming output, and provider overload. - Review usage and routing evidence in Flatkey before expanding the policy to the next workflow.
The best AI API rate limit handling makes capacity pressure boring. The app waits when waiting is safe, queues work when it can wait, changes route only when the contract still holds, and stops when continuing would create hidden cost or risk.
FAQ
What is AI API rate limit handling?
AI API rate limit handling is the policy and code that classifies rate-limit signals, respects provider wait hints, applies bounded backoff, queues work when appropriate, controls fallback, and stops safely when retries would create cost or risk.
Should every 429 be retried?
No. Retry only when the request can still finish inside the workflow budget and the error is likely temporary. Quota, spend, daily-limit, partial-output, and contract-mismatch cases should usually queue or fail closed.
Is exponential backoff enough for AI workloads?
No. Exponential backoff with jitter is useful, but AI workloads also need token and spend awareness, queue budgets, fallback contracts, partial-output protection, and request-level observability.
When should a rate-limited AI request fall back to another model?
Only when the fallback route preserves the required endpoint shape, quality class, tool behavior, data boundary, and cost cap. Fallback should normally happen before visible output begins.
How does Flatkey help with AI API rate limit handling?
Flatkey gives teams one gateway surface for connected model access, routing, billing, usage analytics, and operational controls. Use it to keep rate-limit decisions tied to model, endpoint family, owner key, route evidence, and cost review.
Start with Flatkey pricing, choose one workflow, then get a key and test your AI API rate limit handling policy before sending production traffic through it.