速率限制不仅仅是需要重试的错误。在生产 AI 系统中,429 可能意味着短暂的突发流量超出了令牌桶限制,项目达到了每分钟请求上限,达到了支出上限,或者提供商要求客户端在容量恢复前放慢速度。良好的 AI API 速率限制处理会在花费更多令牌之前区分这些情况。
错误的模式很简单:每个工作程序都看到 429,休眠相同的固定延迟,同时重试,然后在重试失败时回退到不同的模型。这将容量信号转变为重复负载、更高成本、不一致的输出和薄弱的事件证据。
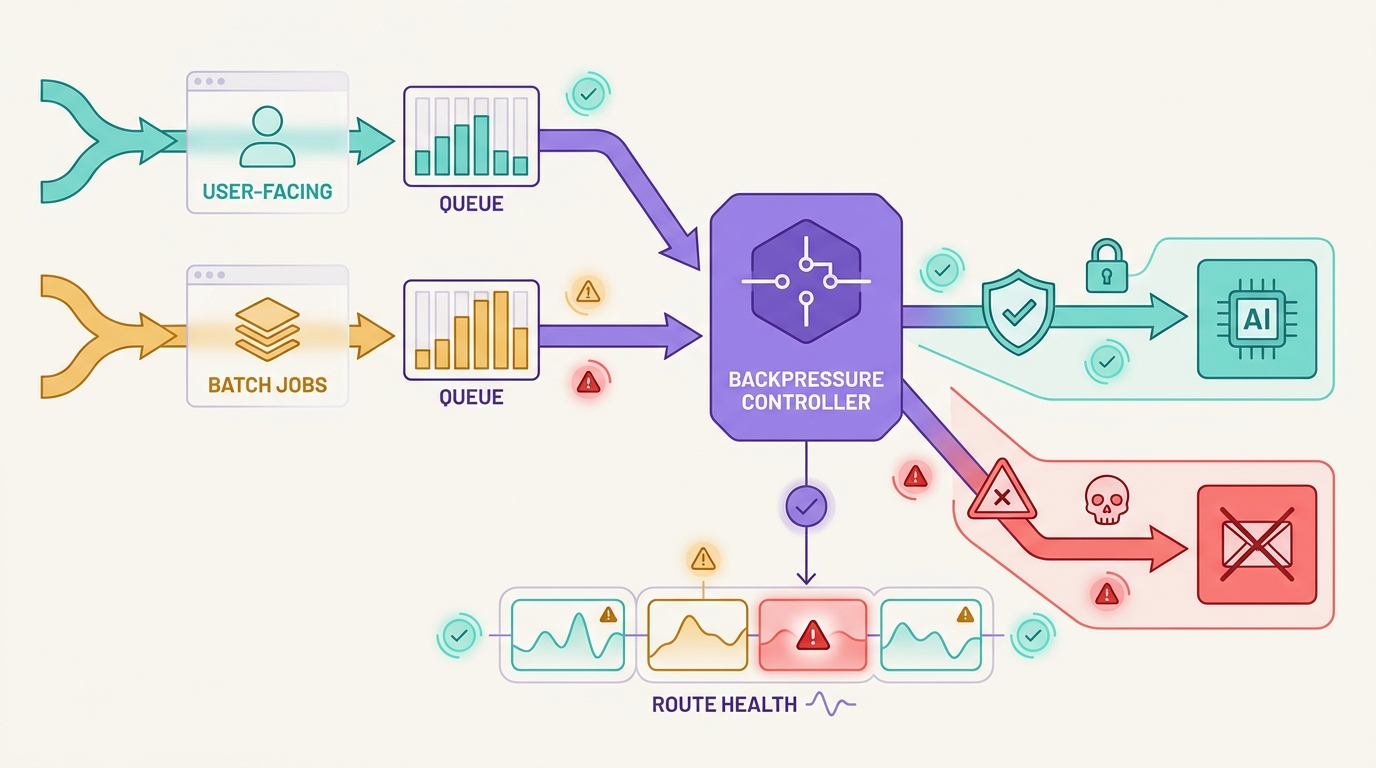
AI API 速率限制处理的目标是保持工作有界。一些请求应该退避。一些请求应该移入队列。一些可以回退到批准的路由。一些应该故障关闭,因为更改模型、工具支持、数据边界或成本比返回受控故障风险更大。Flatkey 适合这种操作模型,因为团队可以在一个网关界面中保留模型访问、路由、计费、使用分析和操作控制,同时验证当前目录和请求证据。
AI API 速率限制处理一览表
使用此表作为生产策略设计的初稿。
| 信号 | 可能的含义 | 退避 | 队列 | 回退 | 故障关闭 |
|---|---|---|---|---|---|
带 Retry-After 的 HTTP 429 | 提供商或网关已给出等待提示 | 遵守标头,然后在工作流预算允许的情况下重试 | 将非交互式工作排队,直到重试时间 | 仅当批准的路由可以保留输出合同时 | 如果重试时间超过用户或作业截止日期,则停止 |
不带 Retry-After 的 HTTP 429 | 达到了速率桶、令牌桶、项目层级或支出防护限制 | 使用带抖动的上限指数退避 | 将批处理工作排队并降低并发性 | 在确定限制来源之前,避免立即进行广泛回退 | 如果限制与支出、配额或策略相关,则停止 |
提供商特定的 rate_limit_error | 提供商表示请求超出了定义的限制 | 仅在提供商的指导范围内重试 | 降低请求速率、令牌量或并发性 | 仅回退到具有同等能力和批准的模型 | 如果回退改变了合规性、成本或质量等级,则停止 |
提供商特定的 RESOURCE_EXHAUSTED | 请求、令牌、每日或支出限制可能已用尽 | 当文档说等待并重试时,短暂重试 | 将可恢复的作业移至队列 | 仅在检查层级和支出影响后才使用不同的路由 | 当项目预算或每日限制用尽时停止 |
| 跨提供商重复出现 429 | 您的应用程序可能产生了过多的工作 | 首先停止重试风暴 | 在路由更改前排队并减载 | 回退是最后一步,而不是第一步 | 对于高风险工作流,在所有者审查前进行故障关闭 |
这是 AI API 速率限制处理的核心:重试决策是在对信号进行分类之后做出的,而不是之前。
重试前读取提供商信号
OpenAI 官方错误文档使用 HTTP 429 表示发送过快的请求,并区分了配额或计费限制用尽与请求节奏。OpenAI 的速率限制指南建议使用随机指数退避,并指出不成功的请求仍计入每分钟的限制。这一点很重要,因为激进的重试循环可能会使限制情况恶化。
Anthropic 的速率限制文档描述了每分钟请求数、每分钟输入令牌数和每分钟输出令牌数的限制。同一文档指出,超出限制会返回一个带有 retry-after 标头的 429 响应,指示需要等待多长时间。Anthropic 的错误文档还记录了用于 HTTP 429 的 rate_limit_error 和用于 HTTP 529 的 overloaded_error,在事件报告中应区别对待。
Google 的 Gemini API 文档描述了跨多个维度的速率限制,例如每分钟请求数、每分钟令牌数、每日请求数和支出。Gemini 故障排除将 HTTP 429 映射到 RESOURCE_EXHAUSTED,并告知团队验证速率限制、等待并重试、降低请求速率或大小,或请求提高速率限制。
实际的结论是,AI API 速率限制处理需要一个提供商标准化的错误形态:
| 规范化字段 | 示例值 | 重要性 |
|---|---|---|
http_status | 429, 503, 529 | 区分客户端调速和提供商过载 |
provider_error_type | rate_limit_error, RESOURCE_EXHAUSTED, insufficient_quota | 显示重试是否可能有效 |
retry_after_ms | 从标头派生的延迟或 null | 防止在提供商给出等待时间时进行猜测 |
limit_dimension | requests, input tokens, output tokens, daily requests, spend | 告知团队应减少什么 |
workflow_deadline_ms | 剩余的用户或作业预算 | 决定是退避、排队还是停止 |
retry_scope | same request, same route, approved fallback route | 防止意外的模型或提供商更改 |
不要将这些字段隐藏在通用的“提供商错误”消息后面。如果唯一存储的事实是 AI 请求失败,团队将无法调整并发性、预算、回退规则或支出控制。
退避:仅在等待时间有界时重试
当请求仍可在工作流预算内完成且重试不会重复产生可见输出时,退避是最安全的响应。退避层应遵循三条规则:
- 当
Retry-After存在时,请遵循它。 - 使用抖动,这样每个工作程序就不会在同一时间唤醒。
- 限制延迟和总尝试次数。
HTTP Retry-After 字段可以是 HTTP 日期或以秒为单位的延迟。Google Cloud 的重试指南建议对可重试的故障使用带抖动的截断指数退避。对于 AI API 速率限制处理,将这些想法与工作流截止时间相结合:
function retryDelayMs(response: Response, attempt: number, remainingBudgetMs: number) {
const header = response.headers.get("retry-after");
let providerDelayMs: number | null = null;
if (header) {
const seconds = Number(header);
providerDelayMs = Number.isFinite(seconds)
? seconds * 1000
: Math.max(0, Date.parse(header) - Date.now());
}
const exponentialCapMs = Math.min(60_000, 500 * 2 ** attempt);
const jitteredDelayMs = Math.floor(Math.random() * exponentialCapMs);
const delayMs = providerDelayMs ?? jitteredDelayMs;
if (delayMs <= 0 || delayMs > remainingBudgetMs) {
return null;
}
return delayMs;
}当重试将超出工作流的生命周期时,该辅助函数会特意返回 null。在面向用户的请求中,这可能意味着一条优雅的失败消息。在批处理工作流中,这可能意味着将作业加入队列。在财务或合规工作流中,这可能意味着停止以供所有者审查。
退避还应考虑隐藏的重试层。SDK 重试、网关重试、队列重试和应用程序重试都会成倍增加。如果 SDK 已经重试 429 和 500 级别的错误,应用程序应降低自己的尝试次数,而不是在上面再叠加一个重试循环。当您需要一个仅限重试的配套清单时,请使用 Flatkey 的 AI API 重试策略指南。
队列:当工作可以等待时吸收需求
当请求有效但当前时机不合适时,排队优于重试。这在批量摘要、夜间提取、评估作业、长文档审阅和非紧急自动化中很常见。
队列策略不应是“永远稍后重试”。它需要一个预算:
| 队列字段 | 生产规则 |
|---|---|
max_queue_age_ms | 工作一旦过时就丢弃或重新分类 |
retry_after_ready_at | 在提供商等待时间结束前不要释放作业 |
concurrency_key | 按提供商、模型、端点族、客户或所有者密钥分组 |
token_budget | 在重试大型作业前减少提示大小或批处理大小 |
idempotency_key | 防止工作程序重启后出现重复的昂贵作业 |
owner | 分配成本和事件责任 |
排队也是控制激增的地方。如果十个工作程序都遇到相同的 429 错误,队列应该减慢整个并发密钥的速度,而不仅仅是十个单独的作业。否则,每个工作程序都会独立退避,下一波将重复同样的错误。
对于 Flatkey 用户来说,这就是单密钥路由和使用证据在操作上变得有用的地方。将队列决策与所有者密钥、端点族、请求的模型、服务的模型和成本信号绑定。然后团队可以审查速率限制是来自一个客户、一个自动化、一个模型类别,还是广泛的产品高峰。
回退:仅在合约仍然有效时更改路由
回退不是更强的重试。它会改变一些东西:提供商、模型、路由、成本、延迟概况、工具行为、数据边界、批准状态或输出质量。因此,AI API 速率限制处理应要求明确的回退合约。
在启用自动回退之前,请使用此清单:
| 检查项 | 必要问题 |
|---|---|
| 能力 | 回退路由是否支持相同的端点形态、工具、流式模式、结构化输出和上下文要求? |
| 质量 | 回退模型是否已获准用于此面向用户或内部的工作流? |
| 成本 | 回退是否可能超出引发事件的预算? |
| 数据边界 | 该路由是否保留了所需的提供商、区域、供应商和采购批准限制? |
| 部分输出 | 用户是否已经看到了令牌或工具结果? |
| 可观测性 | 日志是否会显示请求的模型、服务的模型、回退原因和使用单位? |
在提交任何可见输出之前,回退通常是安全的;在部分输出开始后则存在风险。与将回退答案拼接到流式响应中间相比,支持聊天通常可以更清晰地显示一个简短的受控故障。如果流式传输是主要的故障模式,请将此策略与流式 AI API 可靠性相结合。结构化提取作业通常可以重试或排队;而采购工作流可能需要故障关闭,因为批准的模型/供应商列表比便利性更重要。
当您需要更深入的路由批准矩阵时,请将此策略与 Flatkey 的模型回退评估指南结合使用。
故障关闭:当重试会产生风险时停止
故障关闭听起来很保守,但它通常是成本最低、最可靠的速率限制处理结果。在以下情况下,应停止而不是重试或回退:
- 错误表明信用额度、月度预算、每日请求配额或基于支出的限制已用尽。
Retry-After的时间长于用户请求或作业的截止日期。- 工作流已经提交了部分输出。
- 回退路由改变了模式、工具可用性、模态、数据边界或采购批准。
- 请求属于高风险类型:财务审查、法律审查、面向客户的自动化、受监管数据或不可逆操作。
- 重试会复制大型提示、工具工作流、图像/视频生成或外部副作用。
故障关闭处理仍然需要考虑用户和操作员的体验。显示有用的错误状态,记录限制来源,保留请求 ID,并告知所有者是哪个预算停止了该请求。目标不是隐藏故障,而是在停止不受控制的工作的同时,保留足够的证据来修复原因。
一个实用的 AI API 速率限制处理策略
在编写重试代码之前,先从一个小的策略文件开始。确切的数字应来自生产流量,但结构应在第一次事件发生前就已存在:
workflow: customer_support_chat
rate_limit:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- requested_model
- served_model
- endpoint_family
backoff:
max_attempts_total: 2
respect_retry_after: true
jitter: full
max_delay_ms: 30000
retry_only_before_partial_output: true
queue:
enabled_for:
- batch_summary
- offline_extraction
- evaluation_job
max_queue_age_ms: 900000
concurrency_key:
- owner_key
- endpoint_family
- requested_model
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- quota_or_spend_exhausted
- retry_after_exceeds_deadline
- partial_output_committed
- fallback_contract_mismatch
- high_risk_workflow这个模板使停止条件变得可见。它还帮助审查人员看到,AI API 速率限制处理不仅仅是一个 SDK 设置,它是一项涉及产品、可靠性和成本控制的策略。
用于速率限制事件的可观测性字段
只有当日志能够回答“什么受到了限制”以及“应用程序接下来做了什么”时,速率限制事件才是可调试的。
| 字段 | 记录原因 |
|---|---|
workflow | 将限制与产品界面关联起来 |
owner_key, team, 或 customer_id | 分配成本和容量所有权 |
endpoint_family | 区分聊天、响应、消息、Gemini、图像、视频和其他形态 |
requested_model 和 served_model | 显示路由或回退是否改变了行为 |
http_status 和 provider_error_type | 区分 429 调速、配额、过载和服务器故障 |
retry_after_ms | 证明客户端是否遵守了提供商的指导 |
attempt_number 和 total_attempts | 发现重试放大效应 |
queue_age_ms | 显示排队是保护了还是延迟了工作流 |
fallback_reason | 解释路由改变的原因 |
partial_output_committed | 防止不安全的、对用户可见的重复输出 |
usage_units 和 estimated_cost | 使重复的工作对财务和操作人员可见 |
Flatkey 目前的公开网站将该产品定位为模型访问、路由、计费、使用分析和操作控制的统一网关。2026 年 7 月 3 日的定价 API 快照返回了 success: true,定价版本为 a42d372ccf0b5dd13ecf71203521f9d2,包含 45 个模型行、48 个供应商行,并支持包括 openai、anthropic、gemini、image-generation、openai-video 和 video 在内的端点系列。请将这些事实视为过时证据,而非永久可用性声明。在生产部署前,请务必验证当前目录并运行路由测试。
部署清单
在添加或修订 AI API 速率限制处理时,请使用此部署路径:
- 选择一个工作流并指定负责人。
- 将提供商错误规范化为一种内部速率限制格式。
- 将
Retry-After解析为延迟秒数或 HTTP 日期。 - 设置带有总尝试预算上限的抖动退避。
- 将非交互式工作移入具有最大时效和幂等性密钥的队列。
- 根据端点格式、模型能力、成本和数据边界定义回退合约。
- 在启用回退前定义故障关闭条件。
- 为限制维度、重试延迟、队列时效、回退原因和成本添加日志。
- 测试带和不带
Retry-After的 429 错误、配额耗尽、突发流量、部分流式输出以及提供商过载等情况。 - 在将策略扩展到下一个工作流之前,在 Flatkey 中审查使用情况和路由证据。
最佳的 AI API 速率限制处理能让容量压力变得平淡无奇。应用程序在等待安全时会等待,在可以等待时将工作排入队列,仅在合约仍然有效时更改路由,并在继续操作会产生隐藏成本或风险时停止。
常见问题解答
什么是 AI API 速率限制处理?
AI API 速率限制处理是指对速率限制信号进行分类、遵守提供商的等待提示、应用有界退避、在适当时将工作排入队列、控制回退,并在重试会产生额外成本或风险时安全停止的策略和代码。
每个 429 错误都应该重试吗?
不应该。仅当请求仍可在工作流预算内完成且错误可能是临时性的时候才进行重试。配额、支出、每日限制、部分输出和合约不匹配等情况通常应排队或故障关闭。
指数退避对于 AI 工作负载足够吗?
不够。带抖动的指数退避很有用,但 AI 工作负载还需要令牌和支出感知、队列预算、回退合约、部分输出保护以及请求级别的可观察性。
速率受限的 AI 请求应在何时回退到另一个模型?
仅当回退路由保留了所需的端点格式、质量等级、工具行为、数据边界和成本上限时。回退通常应在可见输出开始之前发生。
Flatkey 如何帮助处理 AI API 速率限制?
Flatkey 为团队提供了一个统一的网关界面,用于连接模型访问、路由、计费、使用分析和操作控制。使用它可将速率限制决策与模型、端点系列、所有者密钥、路由证据和成本审查联系起来。
从 Flatkey 定价开始,选择一个工作流,然后获取密钥,并在通过它发送生产流量之前测试您的 AI API 速率限制处理策略。