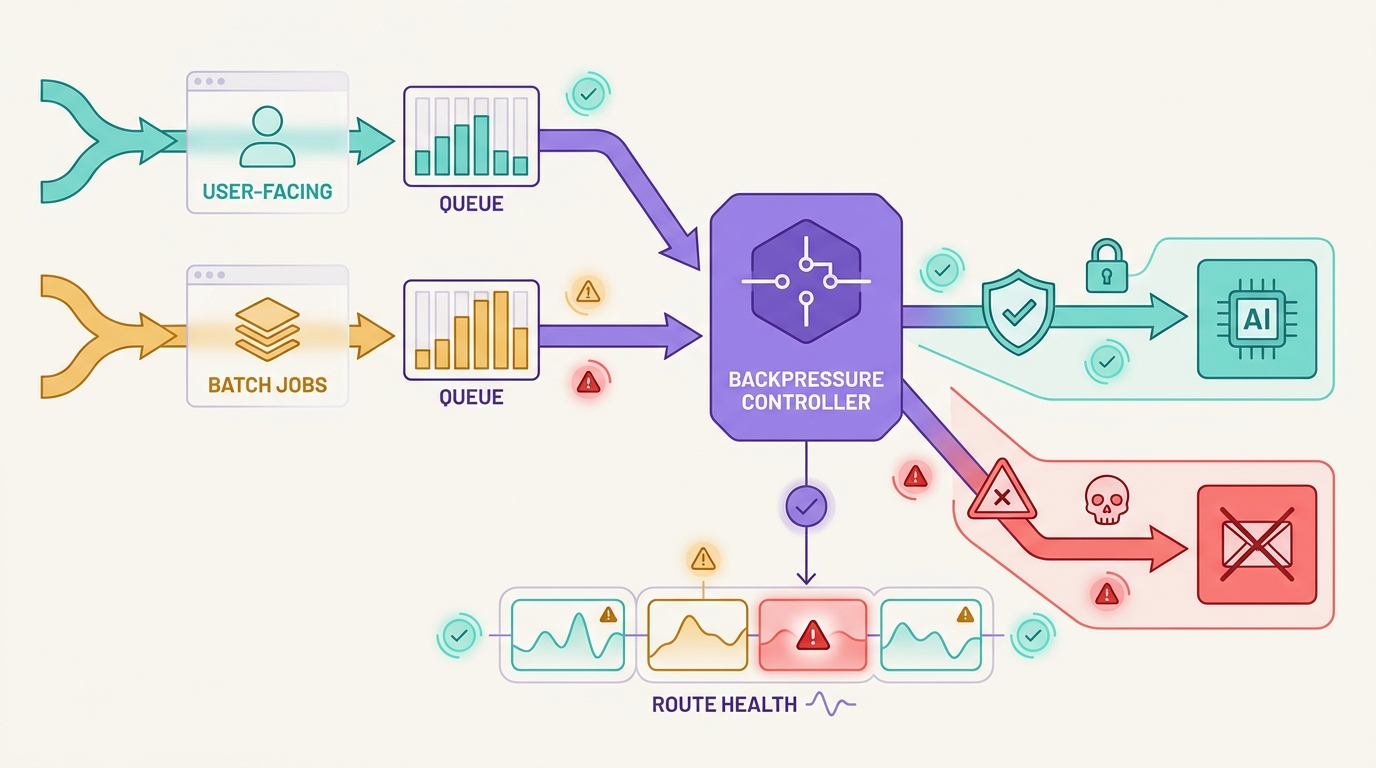
Los límites de tasa no son solo errores para reintentar. En los sistemas de IA en producción, un 429 puede significar que una ráfaga corta superó un cubo de tokens, que un proyecto alcanzó un límite de solicitudes por minuto, que se alcanzó un límite de gasto o que un proveedor está pidiendo al cliente que reduzca la velocidad antes de que se recupere la capacidad. Un buen manejo de los límites de tasa de la API de IA separa esos casos antes de gastar más tokens.
El patrón incorrecto es simple: cada trabajador ve un 429, espera el mismo retraso fijo, reintenta al mismo tiempo y luego hace un fallback a un modelo diferente cuando los reintentos fallan. Eso convierte una señal de capacidad en carga duplicada, mayor costo, resultados inconsistentes y evidencia débil del incidente.
El objetivo del manejo de límites de tasa de la API de IA es mantener el trabajo acotado. Algunas solicitudes deberían aplicar un backoff. Algunas deberían pasar a una cola. Algunas pueden usar un fallback a una ruta aprobada. Algunas deberían tener un fallo cerrado porque cambiar el modelo, el soporte de herramientas, los límites de datos o el costo sería más arriesgado que devolver un fallo controlado. Flatkey se ajusta a este modelo operativo porque los equipos pueden mantener el acceso al modelo, el enrutamiento, la facturación, el análisis de uso y los controles operativos en una única superficie de puerta de enlace mientras validan el catálogo actual y la evidencia de las solicitudes.
Manejo de límites de tasa de API de IA en una tabla
Utilice esta tabla como una primera aproximación para el diseño de políticas de producción.
| Señal | Significado probable | Backoff | Cola | Fallback | Fallo cerrado |
|---|---|---|---|---|---|
HTTP 429 con Retry-After | El proveedor o la puerta de enlace ha dado una sugerencia de espera | Respetar la cabecera y luego reintentar si el presupuesto del flujo de trabajo lo permite | Poner en cola el trabajo no interactivo hasta el momento del reintento | Solo si una ruta aprobada puede preservar el contrato de salida | Detener si el tiempo de reintento excede el plazo del usuario o del trabajo |
HTTP 429 sin Retry-After | Se alcanzó el límite de tasa, el cubo de tokens, el nivel del proyecto o el límite de gasto | Usar backoff exponencial limitado con jitter | Poner en cola el trabajo por lotes y reducir la concurrencia | Evitar un fallback amplio e inmediato hasta que se conozca el origen del límite | Detener si el límite está relacionado con el gasto, la cuota o la política |
rate_limit_error específico del proveedor | El proveedor indica que la solicitud excedió un límite definido | Reintentar solo siguiendo las indicaciones del proveedor | Reducir la tasa de solicitudes, el volumen de tokens o la concurrencia | Hacer fallback solo a un modelo con capacidad y aprobación equivalentes | Detener si el fallback cambia el cumplimiento, el costo o la clase de calidad |
RESOURCE_EXHAUSTED específico del proveedor | Es posible que se haya agotado un límite de solicitudes, de tokens, diario o de gasto | Reintentar brevemente cuando la documentación indique esperar y reintentar | Mover los trabajos reanudables a una cola | Usar una ruta diferente solo después de verificar las implicaciones de nivel y gasto | Detener cuando se agote el presupuesto del proyecto o el límite diario |
| 429 repetidos en varios proveedores | Es posible que su aplicación esté produciendo un exceso de trabajo | Detener primero las tormentas de reintentos | Poner en cola y reducir la carga antes de cambiar de ruta | El fallback es el último paso, no el primero | Aplicar un fallo cerrado para los flujos de trabajo de alto riesgo hasta que los responsables lo revisen |
Este es el núcleo del manejo de límites de tasa de la API de IA: la decisión de reintentar se toma después de clasificar la señal, no antes.
Leer la señal del proveedor antes de reintentar
La documentación oficial de errores de OpenAI utiliza HTTP 429 para las solicitudes enviadas demasiado rápido y también distingue entre cuotas agotadas o límites de facturación y el ritmo de las solicitudes. La guía de límites de tasa de OpenAI recomienda un backoff exponencial aleatorio y señala que las solicitudes sin éxito siguen contando para los límites por minuto. Esto es importante porque un bucle de reintentos agresivo puede empeorar el límite.
La documentación sobre límites de tasa de Anthropic describe los límites en solicitudes por minuto, tokens de entrada por minuto y tokens de salida por minuto. La misma documentación indica que los límites excedidos devuelven un 429 con una cabecera retry-after que indica cuánto tiempo hay que esperar. La documentación de errores de Anthropic también documenta rate_limit_error para HTTP 429 y overloaded_error para HTTP 529, que deben tratarse de forma diferente en los informes de incidentes.
La documentación de la API Gemini de Google describe los límites de tasa en dimensiones como solicitudes por minuto, tokens por minuto, solicitudes por día y gasto. La guía de solución de problemas de Gemini asigna HTTP 429 a RESOURCE_EXHAUSTED e indica a los equipos que verifiquen los límites de tasa, esperen y reintenten, reduzcan la tasa o el tamaño de las solicitudes, o soliciten un aumento del límite de tasa.
La conclusión práctica es que el manejo de los límites de tasa de la API de IA necesita una forma de error normalizada por proveedor:
| Campo normalizado | Valores de ejemplo | Por qué es importante |
|---|---|---|
http_status | 429, 503, 529 | Separa el ritmo del cliente de la sobrecarga del proveedor |
provider_error_type | rate_limit_error, RESOURCE_EXHAUSTED, insufficient_quota | Muestra si es probable que un reintento ayude |
retry_after_ms | Retraso derivado de la cabecera o nulo | Evita adivinar cuando el proveedor ha dado un tiempo de espera |
limit_dimension | solicitudes, tokens de entrada, tokens de salida, solicitudes diarias, gasto | Indica al equipo qué reducir |
workflow_deadline_ms | presupuesto restante del usuario o del trabajo | Decide si hacer backoff, encolar o detenerse |
retry_scope | misma solicitud, misma ruta, ruta de fallback aprobada | Evita cambios accidentales de modelo o proveedor |
No ocultes estos campos detrás de un mensaje genérico de "error del proveedor". Si el único hecho almacenado es que una solicitud de IA falló, el equipo no puede ajustar la concurrencia, los presupuestos, las reglas de fallback o los controles de gasto.
Backoff: reintentar solo cuando la espera es limitada
El backoff es la respuesta más segura cuando la solicitud aún puede finalizar dentro del presupuesto del flujo de trabajo y el reintento no duplicará la salida visible. La capa de backoff debe seguir tres reglas:
- Respeta
Retry-Aftercuando esté presente. - Usa jitter para que no todos los workers se activen al mismo tiempo.
- Limita tanto el retraso como el número total de intentos.
El campo HTTP Retry-After puede ser una fecha HTTP o un retraso en segundos. La guía de reintentos de Google Cloud recomienda un backoff exponencial truncado con jitter para fallos que admiten reintentos. Para el manejo de límites de tasa en API de IA, combina esas ideas con un plazo de flujo de trabajo:
function retryDelayMs(response: Response, attempt: number, remainingBudgetMs: number) {
const header = response.headers.get("retry-after");
let providerDelayMs: number | null = null;
if (header) {
const seconds = Number(header);
providerDelayMs = Number.isFinite(seconds)
? seconds * 1000
: Math.max(0, Date.parse(header) - Date.now());
}
const exponentialCapMs = Math.min(60_000, 500 * 2 ** attempt);
const jitteredDelayMs = Math.floor(Math.random() * exponentialCapMs);
const delayMs = providerDelayMs ?? jitteredDelayMs;
if (delayMs <= 0 || delayMs > remainingBudgetMs) {
return null;
}
return delayMs;
}Esa función auxiliar devuelve intencionadamente null cuando el reintento excedería la duración del flujo de trabajo. En una solicitud de cara al usuario, eso puede significar un mensaje de fallo controlado. En un flujo de trabajo por lotes, puede significar encolar el trabajo. En un flujo de trabajo de finanzas o cumplimiento, puede significar detenerse para la revisión del propietario.
El backoff también debe tener en cuenta las capas de reintento ocultas. Los reintentos del SDK, de la puerta de enlace, de la cola y de la aplicación se multiplican. Si el SDK ya reintenta los errores de nivel 429 y 500, la aplicación debería reducir sus propios intentos en lugar de apilar otro bucle de reintento encima. Usa la guía de Flatkey sobre estrategia de reintentos para API de IA cuando necesites una lista de verificación complementaria solo para reintentos.
Cola: absorber la demanda cuando el trabajo puede esperar
Encolar es mejor que reintentar cuando la solicitud es válida pero el momento actual no lo es. Esto es común para la sumarización por lotes, la extracción nocturna, los trabajos de evaluación, la revisión de documentos largos y las automatizaciones no urgentes.
Una política de cola no debe ser "intentar más tarde para siempre". Necesita un presupuesto:
| Campo de la cola | Regla de producción |
|---|---|
max_queue_age_ms | Descartar o reclasificar el trabajo una vez que esté obsoleto |
retry_after_ready_at | No liberar el trabajo antes del tiempo de espera del proveedor |
concurrency_key | Agrupar por proveedor, modelo, familia de endpoints, cliente o clave de propietario |
token_budget | Reducir el tamaño del prompt o del lote antes de reintentar trabajos grandes |
idempotency_key | Evitar trabajos costosos duplicados después de reinicios del worker |
owner | Asignar la responsabilidad de costos e incidentes |
El encolamiento es también el lugar para controlar los picos de demanda. Si diez workers reciben el mismo error 429, la cola debería ralentizar toda la clave de concurrencia, no solo los diez trabajos individuales. De lo contrario, cada worker hace backoff de forma independiente y la siguiente oleada repite el mismo error.
Para los usuarios de Flatkey, aquí es donde el enrutamiento de una sola clave y la evidencia de uso se vuelven operacionalmente útiles. Mantén la decisión de la cola vinculada a la clave del propietario, la familia de endpoints, el modelo solicitado, el modelo servido y la señal de costo. Luego, el equipo puede revisar si el límite de tasa provino de un cliente, una automatización, una clase de modelo o un pico general del producto.
Fallback: cambiar de ruta solo cuando el contrato aún se mantiene
El fallback no es un reintento más fuerte. Cambia algo: proveedor, modelo, ruta, costo, perfil de latencia, comportamiento de la herramienta, límite de datos, estado de aprobación o calidad de la salida. Por lo tanto, el manejo de límites de tasa en API de IA debería requerir un contrato de fallback explícito.
Usa esta lista de verificación antes de habilitar el fallback automático:
| Verificación | Pregunta requerida |
|---|---|
| Capacidad | ¿La ruta de fallback admite la misma forma de endpoint, herramientas, modo de streaming, salida estructurada y requisito de contexto? |
| Calidad | ¿Está aprobado el modelo de fallback para este flujo de trabajo interno o de cara al usuario? |
| Costo | ¿Podría el fallback exceder el presupuesto que desencadenó el incidente? |
| Límite de datos | ¿La ruta preserva las restricciones requeridas de proveedor, región, vendedor y aprobación de adquisiciones? |
| Salida parcial | ¿El usuario ya ha visto tokens o resultados de herramientas? |
| Observabilidad | ¿Mostrarán los registros el modelo solicitado, el modelo servido, el motivo del fallback y las unidades de uso? |
El fallback suele ser seguro antes de que se confirme cualquier salida visible y arriesgado después de que comience la salida parcial. Un chat de soporte a menudo puede mostrar un fallo corto y controlado de manera más limpia que empalmar una respuesta de fallback en medio de una respuesta transmitida. Si el streaming es el principal modo de fallo, combine esta política con la fiabilidad de la API de IA en streaming. Un trabajo de extracción estructurado a menudo puede reintentar o encolar; un flujo de trabajo de adquisiciones puede necesitar un fallo cerrado porque la lista de modelos/vendedores aprobados es más importante que la conveniencia.
Combine esta política con la guía de Flatkey sobre la evaluación de fallback de modelos cuando necesite una matriz de aprobación de rutas más profunda.
Fallo cerrado: detenerse cuando el reintento crearía un riesgo
El fallo cerrado suena conservador, pero a menudo es el resultado más económico y fiable ante un límite de tasa. Deténgase en lugar de reintentar o usar un fallback cuando:
- El error indica créditos agotados, presupuesto mensual, cuota de solicitudes diarias o límites basados en el gasto.
Retry-Afteres más largo que la solicitud del usuario o el plazo del trabajo.- El flujo de trabajo ya ha confirmado una salida parcial.
- La ruta de fallback cambia el esquema, la disponibilidad de herramientas, la modalidad, el límite de datos o la aprobación de adquisiciones.
- La solicitud es de alto riesgo: revisión financiera, revisión legal, automatización de cara al cliente, datos regulados o acciones irreversibles.
- Los reintentos duplicarían un prompt grande, un flujo de trabajo de herramientas, la generación de imágenes/video o un efecto secundario externo.
El manejo de fallo cerrado todavía necesita una experiencia para el usuario y el operador. Muestre un estado de error útil, registre el origen del límite, conserve el ID de la solicitud e informe al propietario qué presupuesto detuvo la solicitud. El objetivo no es ocultar el fallo; el objetivo es detener el trabajo no controlado mientras se conservan suficientes pruebas para solucionar la causa.
Una política práctica para el manejo de límites de tasa en API de IA
Comience con un pequeño archivo de políticas antes de escribir el código de reintento. Los números exactos deben provenir del tráfico de producción, pero la estructura debe existir antes del primer incidente:
workflow: customer_support_chat
rate_limit:
classify:
fields:
- http_status
- provider_error_type
- retry_after_ms
- limit_dimension
- requested_model
- served_model
- endpoint_family
backoff:
max_attempts_total: 2
respect_retry_after: true
jitter: full
max_delay_ms: 30000
retry_only_before_partial_output: true
queue:
enabled_for:
- batch_summary
- offline_extraction
- evaluation_job
max_queue_age_ms: 900000
concurrency_key:
- owner_key
- endpoint_family
- requested_model
fallback:
allowed_before_first_token: true
require_equivalent_tools: true
require_cost_cap: true
require_data_boundary_match: true
fail_closed_when:
- quota_or_spend_exhausted
- retry_after_exceeds_deadline
- partial_output_committed
- fallback_contract_mismatch
- high_risk_workflowEsta plantilla hace visibles las condiciones de detención. También ayuda a los revisores a ver que el manejo de límites de tasa en API de IA no es solo una configuración del SDK; es una política de producto, fiabilidad y control de costos.
Campos de observabilidad para incidentes de límite de tasa
Un incidente de límite de tasa solo se puede depurar si los registros pueden responder qué se limitó y qué hizo la aplicación a continuación.
| Campo | Por qué registrarlo |
|---|---|
workflow | Conecta el límite con una superficie del producto |
owner_key, team, o customer_id | Asigna la propiedad del costo y la capacidad |
endpoint_family | Separa chat, respuestas, mensajes, Gemini, imagen, video y otras formas |
requested_model y served_model | Muestra si el enrutamiento o el fallback cambiaron el comportamiento |
http_status y provider_error_type | Distingue entre control de ritmo 429, cuota, sobrecarga y fallo del servidor |
retry_after_ms | Prueba si el cliente respetó la guía del proveedor |
attempt_number y total_attempts | Encuentra la amplificación de reintentos |
queue_age_ms | Muestra si el encolamiento protegió o retrasó el flujo de trabajo |
fallback_reason | Explica por qué cambió la ruta |
partial_output_committed | Evita la duplicación insegura de salidas visibles para el usuario |
usage_units y estimated_cost | Hace visible el trabajo duplicado para finanzas y operadores |
El sitio público actual de Flatkey posiciona el producto como una puerta de enlace única para el acceso a modelos, enrutamiento, facturación, análisis de uso y controles operativos. La instantánea de la API de precios del 3 de julio de 2026 devolvió success: true, versión de precios a42d372ccf0b5dd13ecf71203521f9d2, 45 filas de modelos, 48 filas de proveedores y familias de endpoints compatibles, incluyendo openai, anthropic, gemini, image-generation, openai-video y video. Trate esos datos como evidencia fechada, no como afirmaciones de disponibilidad permanente. Valide siempre el catálogo actual y ejecute una prueba de ruta antes del despliegue en producción.
Lista de verificación para el despliegue
Utilice esta ruta de despliegue cuando agregue o revise el manejo de límites de tasa de la API de IA:
- Elija un flujo de trabajo y nombre al propietario.
- Normalice los errores del proveedor en una única forma interna de límite de tasa.
- Analice
Retry-Aftercomo segundos de retraso o como fecha HTTP. - Establezca un backoff con jitter limitado y un presupuesto total de intentos.
- Mueva el trabajo no interactivo a una cola con una antigüedad máxima y claves de idempotencia.
- Defina contratos de fallback por forma de endpoint, capacidad del modelo, costo y límite de datos.
- Defina las condiciones de fallo cerrado antes de habilitar el fallback.
- Agregue registros para la dimensión del límite, el retraso del reintento, la antigüedad de la cola, el motivo del fallback y el costo.
- Pruebe el error 429 con y sin
Retry-After, agotamiento de cuota, tráfico en ráfagas, salida de streaming parcial y sobrecarga del proveedor. - Revise la evidencia de uso y enrutamiento en Flatkey antes de expandir la política al siguiente flujo de trabajo.
El mejor manejo de los límites de tasa de la API de IA hace que la presión sobre la capacidad sea algo sin importancia. La aplicación espera cuando es seguro hacerlo, pone el trabajo en cola cuando puede esperar, cambia de ruta solo cuando el contrato aún se mantiene y se detiene cuando continuar crearía costos o riesgos ocultos.
Preguntas frecuentes
¿Qué es el manejo de límites de tasa de la API de IA?
El manejo de límites de tasa de la API de IA es la política y el código que clasifica las señales de límite de tasa, respeta las sugerencias de espera del proveedor, aplica un backoff limitado, pone el trabajo en cola cuando es apropiado, controla el fallback y se detiene de forma segura cuando los reintentos crearían costos o riesgos.
¿Debería reintentarse cada error 429?
No. Reintente solo cuando la solicitud aún pueda finalizar dentro del presupuesto del flujo de trabajo y el error sea probablemente temporal. Los casos de cuota, gasto, límite diario, salida parcial y discrepancia de contrato generalmente deberían ponerse en cola o fallar en modo cerrado.
¿Es suficiente el backoff exponencial para las cargas de trabajo de IA?
No. El backoff exponencial con jitter es útil, pero las cargas de trabajo de IA también necesitan conocimiento de tokens y gastos, presupuestos de cola, contratos de fallback, protección contra salidas parciales y observabilidad a nivel de solicitud.
¿Cuándo debería una solicitud de IA con límite de tasa recurrir a otro modelo (fallback)?
Solo cuando la ruta de fallback preserva la forma de endpoint requerida, la clase de calidad, el comportamiento de la herramienta, el límite de datos y el tope de costo. El fallback normalmente debería ocurrir antes de que comience la salida visible.
¿Cómo ayuda Flatkey con el manejo de límites de tasa de la API de IA?
Flatkey ofrece a los equipos una superficie de puerta de enlace única para el acceso a modelos conectados, enrutamiento, facturación, análisis de uso y controles operativos. Úselo para mantener las decisiones de límite de tasa vinculadas al modelo, la familia de endpoints, la clave del propietario, la evidencia de la ruta y la revisión de costos.
Comience con los precios de Flatkey, elija un flujo de trabajo, luego obtenga una clave y pruebe su política de manejo de límites de tasa de la API de IA antes de enviar tráfico de producción a través de ella.