
Choosing an AI image generation API is not as simple as comparing one per-image number. OpenAI GPT Image estimates image output with tokens, Gemini image generation API pricing combines text, input-image, and output-image tokens, and Google Imagen is commonly listed at a per-image rate. A route that looks cheaper at first can cost more once resolution tiers, reference images, edits, batch or flex eligibility, and retries are included.
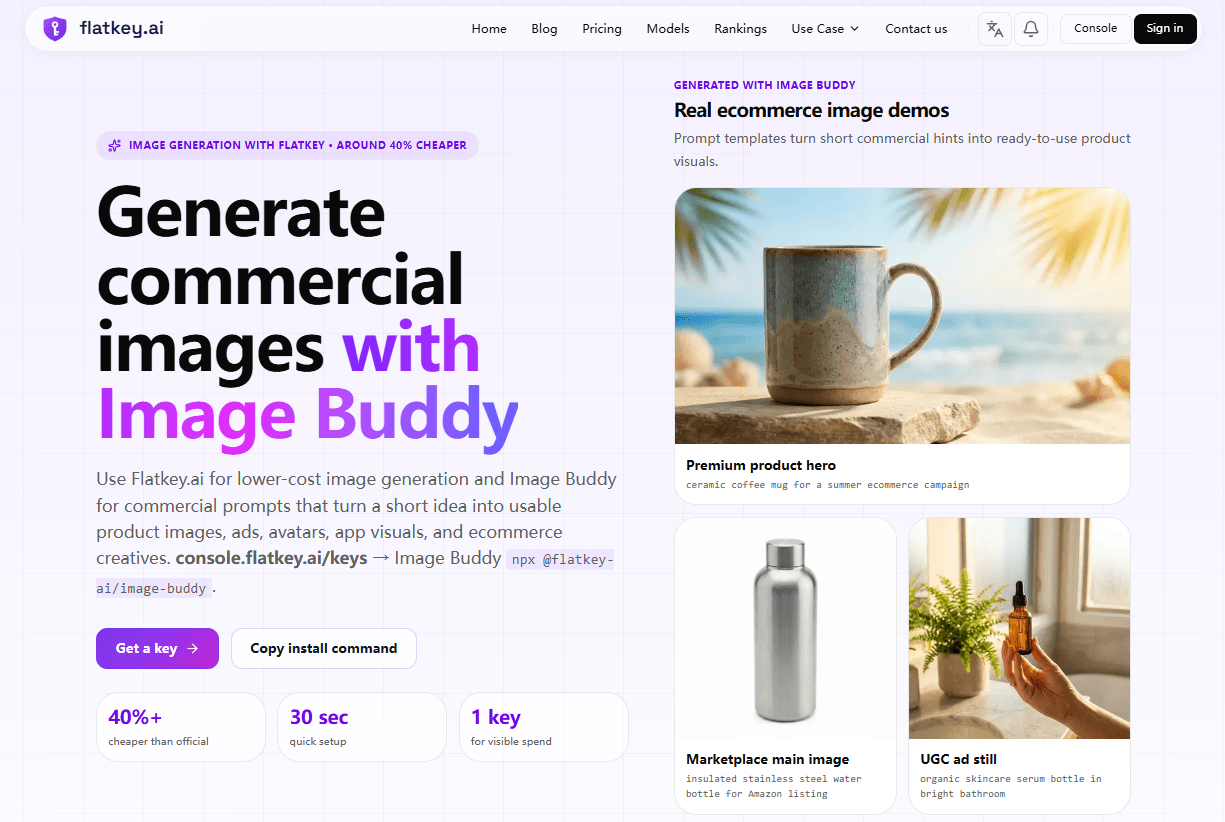
To make those prices comparable, this guide normalizes GPT Image, Gemini, and Imagen into practical planning units, then shows how to verify equivalent routes in Flatkey pricing. If you want to test the shortlist with a real commercial brief, Image Buddy provides a practical CLI workflow: use one Flatkey key and a short prompt or template to generate product images, marketplace main images, or UGC ad visuals through supported routes such as GPT-image-2 or Nano Banana Pro. You can then compare the published rate with the selected route and recorded usage for the same job.
The pricing and model-status check was completed on June 17, 2026, Asia/Shanghai, using official OpenAI image generation pricing guidance, Google Gemini API pricing, Google Vertex AI pricing, and a live Flatkey public pricing-page snapshot. Treat the figures below as point-in-time planning data, and verify the current provider price, model availability, and Flatkey dashboard row before sending production traffic.
If your budget also includes video generation, use the AI video generation API pricing comparison as a separate reference. Image and video APIs share several cost-control methods, but video also introduces duration, asynchronous job status, and retry costs that can change the budget much faster.
Quick Answer: How to Compare AI Image Generation API Pricing
Use four columns when comparing AI image generation API pricing:
- Generation unit: Image-output tokens, price per generated image, input-image tokens, or a route-specific billing unit.
- Resolution and quality: Aspect ratio, 1K, 2K, 4K, low, medium, high, standard, fast, or ultra.
- Billable extras: Prompt text, reference images, masks, edits, grounding or search, partial images, and retries.
- Route evidence: Exact model row, endpoint type, availability status, usage log, and current pricing label.
In practice, GPT Image requires token and quality calculations. Gemini Image requires separate text, input-image, and output-image calculations. Imagen usually starts with a per-image rate, but model status and feature-route availability still need to be checked.
After narrowing the list, keep the prompt, resolution, reference images, and retry policy consistent across tests. This is where the Image Buddy workflow becomes useful: its commercial templates and short hints reduce variation between product-image tests, while Flatkey model rows and usage logs provide route-level evidence.
Pricing Unit Comparison
The table below is the core normalization view for AI image generation API pricing. It intentionally avoids ranking the models by "cheapest" because each provider exposes different units and each model targets a different workflow.
| Provider Family | Current Official Unit | Example Public Price Points Checked | Hidden Cost Checks | Flatkey Check |
|---|---|---|---|---|
| OpenAI GPT Image 2 | Image output token estimate plus text and image input tokens. | OpenAI's image guide calculator lists GPT Image 2 at $0.006, $0.053, and $0.211 for 1024x1024 low, medium, and high examples; 1536x1024 medium is listed at $0.041. | Prompt tokens, reference-image input tokens, quality, size, output format, partial-image streaming, retries, and edits. | Check gpt-image-2 or openai/gpt-image-2, endpoint type, quota type, current pricing label, and status. |
| Google Gemini 3 Pro Image | Text/image input per 1M tokens and image output per 1M image tokens, expressed as image equivalents. | Google AI lists paid standard input at $2.00 per 1M text/image tokens and image output at $120 per 1M tokens, equivalent to $0.134 per 1K/2K image and $0.24 per 4K image. | Input image tokens, output resolution, web/image search grounding charges, tier type, and whether batch/flex or priority applies. | Check gemini-3-pro-image and gemini-3-pro-image-preview rows, endpoint type, and availability status. |
| Google Gemini 2.5 Flash Image | Text/image input per 1M tokens and output shown as a per-image equivalent. | Google AI lists standard input at $0.30 per 1M text/image tokens and output at $0.039 per 1024x1024 image; batch/flex output is $0.0195 per image. | Preview-model behavior, batch/flex eligibility, input tokens, output size, retries, and route support. | Flatkey's June 17 snapshot showed gemini-2.5-flash-image as available with gemini and openai endpoint types. |
| Google Imagen 4 | Per generated image in the Gemini API and Vertex AI pricing tables. | Google AI lists Imagen 4 Fast at $0.02, Standard at $0.04, and Ultra at $0.06 per image. | Deprecation timeline, feature type, upscaling, editing, product recontext, virtual try-on, and route status. | Flatkey's June 17 snapshot listed Imagen 4 rows with image-generation, gemini, and openai endpoint types, but with unknown_failure status. |
OpenAI GPT Image Pricing: Token Math First
OpenAI's current image generation guide says GPT Image models can generate and edit images through the Image API and can also be used through the Responses API image-generation tool. For gpt-image-2, the official cost section says to estimate output tokens from requested quality and size, then account for text input tokens and image input tokens if the request edits or references images.
That makes GPT Image different from a simple per-image SKU. The visible price for a generated asset can change when you change quality, size, input images, streaming partials, or retry behavior. For a deeper provider-specific version of this workflow, see OpenAI Image API Pricing and GPT Image 2 API Through Flatkey.
OpenAI's calculator examples show GPT Image 2 at these point-in-time estimates:
| GPT Image 2 Setting | 1024x1024 | 1024x1536 | 1536x1024 | Planning Note |
|---|---|---|---|---|
| Low | $0.006 | $0.005 | $0.005 | Useful for drafts, thumbnails, and fast iteration. |
| Medium | $0.053 | $0.041 | $0.041 | A practical default to benchmark before final quality. |
| High | $0.211 | $0.165 | $0.165 | Use for final assets, not every preview. |
Two details matter for AI image generation API pricing: OpenAI notes that edit requests with reference images can use more input tokens, and each partial image in streaming adds 100 image output tokens. For production budgets, separate "preview" and "final render" settings rather than letting every user action call a final-quality route.
Gemini Image Pricing: Token Prices With Image Equivalents
Google's Gemini API pricing page separates native image-generation models from general text models. Gemini image models still use token pricing under the hood, but the pricing page often gives an equivalent per-image number so teams can plan without manually multiplying image output tokens.
For Gemini 3 Pro Image, Google AI lists the standard paid input price at $2.00 per 1M text/image tokens and says image input is set at 560 tokens, or $0.0011 per image. The same page lists image output at $120 per 1M tokens, with examples of $0.134 per 1K/2K output image and $0.24 per 4K output image. Batch/flex examples cut those output examples to $0.067 and $0.12 respectively.
For Gemini 2.5 Flash Image, Google AI lists standard paid input at $0.30 per 1M text/image tokens and output at $0.039 per image. The footnote says image output is priced at $30 per 1M tokens, with 1024x1024 output images consuming 1290 tokens. The same page lists batch and flex output at $0.0195 per image and priority at $0.0702 per image.
On Google Cloud Vertex AI pricing, Gemini image pricing can appear with different model naming and route context. For example, the Vertex page lists Gemini 3 Pro Image image output at $120 per 1M tokens and includes a footnote mapping 1120 tokens to $0.134 for 1K/2K and 2000 tokens to $0.24 for 4K. It also lists Gemini 3.1 Flash Image output examples by resolution. If your team uses Vertex AI instead of the Gemini API, do not assume the same route, model name, or tier behavior as the Gemini API page.
Imagen Pricing: Per Image, But Watch Deprecation And Feature Type
Imagen looks simpler because Google lists direct per-image prices. On the Gemini API pricing page checked for this article, Imagen 4 Fast is $0.02 per image, Imagen 4 Standard is $0.04 per image, and Imagen 4 Ultra is $0.06 per image. The Vertex AI pricing page also lists Imagen 4 Fast at $0.02, Imagen 4 at $0.04, and Imagen 4 Ultra at $0.06 per generated image.
The caveat is freshness. Google's Gemini API pricing page includes a warning that Imagen 4 models imagen-4.0-generate-001, imagen-4.0-ultra-generate-001, and imagen-4.0-fast-generate-001 are deprecated and scheduled to shut down on August 17, 2026, with migration guidance toward Gemini 2.5 Flash Image. That warning is a bigger operational issue than a one-cent price difference.
Feature type also matters. Vertex AI lists separate Imagen prices for upscaling, visual captioning, visual Q&A, product recontext, and virtual try-on. A "per image" price for text-to-image generation is not automatically the same price as an edit, upscaling step, or product-image workflow.
Flatkey Catalog Snapshot For Image Models
Flatkey's public pricing page was checked on June 17, 2026 Asia/Shanghai. The server-rendered pricing page reported 638 AI models and pricing version 5a90f2b86c08bd983a9a2e6d66c255f4eaef9c4bc934386d2b6ae84ef0ff1f1f. The same page exposed endpoint families including gemini, image-generation, openai, and openai-response. That matters because AI image generation API pricing through a gateway must match both the model row and the endpoint type.
| Flatkey Row Checked | Endpoint Types | Pricing Fields Seen | Status In Snapshot | Action Before Production |
|---|---|---|---|---|
gpt-image-2 |
openai |
model_ratio: 3.325, completion_ratio: 6, image_ratio: 1.6 |
unknown_failure |
Confirm whether the selected row supports your intended image request shape before any launch. |
openai/gpt-image-2 |
openai |
quota_type: 1, model_price: 0.063 |
unknown_failure |
Do not copy this number without confirming current dashboard unit and route behavior. |
gemini-2.5-flash-image |
gemini, openai |
model_ratio: 0.15, completion_ratio: 100 |
available |
Run a small route test and confirm whether the app should call the Gemini-style or OpenAI-style endpoint. |
gemini-3-pro-image-preview |
gemini, openai |
model_ratio: 1, completion_ratio: 60 |
available |
Confirm preview/stable naming and rate limits before building a long-lived route. |
imagen-4.0-fast-generate-001, imagen-4.0-generate-001, imagen-4.0-ultra-generate-001 |
image-generation, gemini, openai |
model_ratio: 37.5, completion_ratio: 1 |
unknown_failure |
Treat as dated catalog presence only; also account for Google's August 17, 2026 Imagen 4 shutdown warning. |
This Flatkey evidence does not mean every image row is production-ready today. It means the current catalog can be used as a starting point for provider comparison, route selection, quota review, and logging. The actual production gate is a current dashboard check plus a small smoke test.
For teams managing spend across many AI routes, cost visibility should be treated as an operating process, not a one-time spreadsheet. The FinOps Framework is a useful neutral reference for cloud and usage-based cost management practices such as allocation, forecasting, and accountability.
A Normalization Formula For Image Cost Planning
Use this normalized formula before choosing a provider or route:
Estimated image workflow cost = prompt text cost +input image or edit cost +generated image output cost +partial image or preview cost +retry and failure cost +gateway or route-specific unit cost
For GPT Image, the generated image output cost is driven by image output tokens. For Gemini Image, the published image-equivalent numbers are derived from token prices and expected token counts. For Imagen, the generated image cost is usually visible as a per-image price, but edits and related image features may have separate prices. Flatkey then adds the operational layer: exact row, endpoint support, group, quota type, route status, and actual usage log.
Pricing is also tied to model-risk management. If a route is preview-only, deprecated, or scheduled for shutdown, the cost model should include fallback testing and migration work. The NIST AI Risk Management Framework is a relevant governance reference for documenting model changes, monitoring, and operational controls around AI systems.
Procurement Checklist For Image Generation APIs
A team comparing AI image generation API pricing should collect these fields before approving a model for production:
| Field | Why Finance Cares | Why Engineering Cares |
|---|---|---|
| Exact model ID | Prevents budgeting against the wrong SKU. | Prevents calls to aliases, previews, or deprecated rows. |
| Endpoint path | Confirms which usage ledger will be billed. | Confirms request body, SDK behavior, and response shape. |
| Output resolution and quality | Separates preview spend from final-render spend. | Controls latency, UX, retry pressure, and storage. |
| Input-image handling | Edits and reference images can add cost. | Masks, references, and image uploads change request structure. |
| Deprecation or preview status | A cheap route can become a migration cost. | Preview and deprecated routes need fallbacks. |
| Flatkey usage logs | Shows actual cost after retries and failures. | Shows model row, route status, error rate, and rollback signal. |
Template: Compare One Prompt Across Routes
Use one controlled prompt and one output setting when you benchmark routes. Change only one variable at a time.
Benchmark run
- Prompt category: product concept, marketing asset, UI mockup, or edit
- Output target: draft, preview, or final
- Size: fixed across providers where possible
- Quality/tier: fixed or documented as provider-specific
- Input images: none, one reference, or edit with mask
- Route A: direct provider baseline
- Route B: Flatkey selected row and endpoint
- Log: status, latency, retries, output accepted, usage unit, final cost
This gives you a real AI image generation API pricing comparison instead of a spreadsheet that ignores rejected images, moderation blocks, retries, and routing differences. If your benchmark also covers text, vision, or video models, use the AI Model Pricing Comparison as the broader planning layer.
When Flatkey Helps With Image Pricing
Flatkey is useful when image generation is part of a larger multimodal workflow. A production app might use one model for prompt rewriting, GPT Image or Gemini Image for generation, an Imagen row for a specific creative route, and a vision-capable model for review. Flatkey's value is the shared API access layer: one key, model-row visibility, endpoint choices, usage logs, quotas, and a single pricing surface.
That does not remove provider-level due diligence. It makes the checks easier to repeat. For AI image generation API pricing, the safest Flatkey workflow is:
- Open Flatkey pricing and search the exact model row.
- Confirm provider family, endpoint types, group, quota type, and current price label.
- Compare against official OpenAI or Google pricing docs for the same model and route.
- Run one low-risk smoke test through the confirmed endpoint.
- Review Flatkey logs for model row, status, usage unit, and cost.
- Set quota limits before exposing the feature to production users.
- Document fallback routes for preview models or deprecated models.
Pricing Is Only One Part Of The Image Workflow
For many teams, AI image generation API pricing is only the first filter. The next question is whether the route can reliably turn a rough idea into a usable business asset without extra prompt engineering, repeated retries, or manual cleanup. That is especially true for teams creating product visuals, ad creatives, profile images, app graphics, and ecommerce assets at scale.
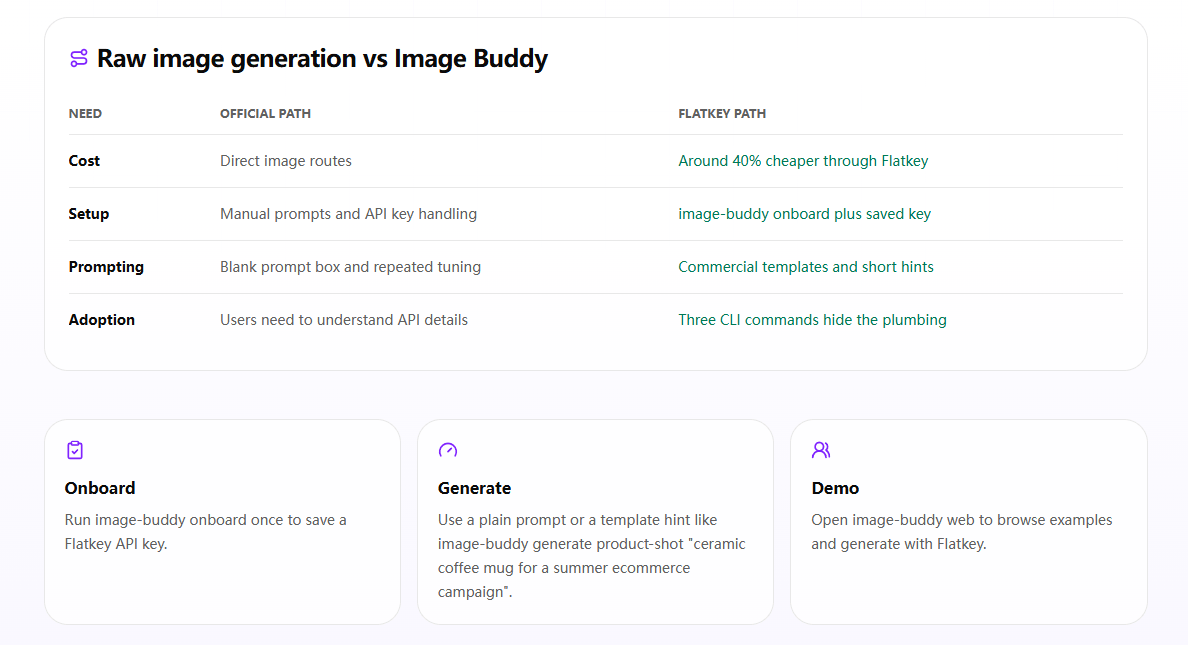 If that is your use case, Image Buddy is the more practical next step after pricing research. Instead of stopping at model comparison, Image Buddy helps turn a simple prompt into more commercially usable image outputs with a business-oriented prompt library and a workflow designed for real marketing and product-image scenarios. In other words: this pricing guide helps you choose the right route, while Image Buddy helps you get from “which API is cheaper?” to “which image can I actually publish?”
If that is your use case, Image Buddy is the more practical next step after pricing research. Instead of stopping at model comparison, Image Buddy helps turn a simple prompt into more commercially usable image outputs with a business-oriented prompt library and a workflow designed for real marketing and product-image scenarios. In other words: this pricing guide helps you choose the right route, while Image Buddy helps you get from “which API is cheaper?” to “which image can I actually publish?”
Related Pricing Guides
If you are building a broader cost model, pair this page with OpenAI Image API Pricing, AI Model Pricing Comparison, GPT Image 2 API Through Flatkey, and the AI video generation API pricing comparison. Those articles cover provider-specific checks, broader model pricing patterns, and adjacent multimodal cost planning; this guide focuses on cross-provider image pricing units. If your goal is not just to compare costs but to generate business-ready visuals faster, see Image Buddy.
FAQ
What is the best way to compare AI image generation API pricing?
Compare normalized units, not just headline prices. Record prompt text cost, input image cost, generated output cost, resolution, quality, retry behavior, and the exact Flatkey or provider route used.
Is GPT Image priced per image?
OpenAI's current GPT Image 2 guidance uses output-token estimates from quality and size, plus text and image input tokens. The guide provides per-image calculator examples, but the cost model is token-driven.
Is Gemini Image priced per image?
Google lists token prices and image-equivalent outputs. Gemini 3 Pro Image uses image output token pricing with examples such as $0.134 for 1K/2K standard outputs, while Gemini 2.5 Flash Image lists output examples such as $0.039 per 1024x1024 image.
Is Imagen priced per image?
Google's Gemini API and Vertex AI pricing pages list Imagen 4 generation as direct per-image prices, such as $0.02 for Fast, $0.04 for Standard, and $0.06 for Ultra. Check feature type and deprecation status before relying on Imagen 4 for new production work.
How should I check AI image generation API pricing in Flatkey?
Search the exact model row in Flatkey pricing, confirm endpoint type, group, quota type, availability status, and current pricing label, then run a small smoke test and compare the usage log against your estimate.


