Lange Prompts sind nicht automatisch ein Problem mit langem Kontext. Manche Prompts sollten gekürzt werden, manche sollten Retrieval verwenden, manche sollten mehr Platz für die Ausgabe reservieren und manche benötigen wirklich ein größeres Kontextfenster. Context Window Routing ist die Richtlinie, die entscheidet, welchen Weg eine Anfrage nehmen sollte, bevor sie Budget für das falsche Modell verbraucht.
Das Ziel ist einfach: Routen Sie nach der tatsächlichen Prompt-Größe, der erforderlichen Antwortform und den Nachweisen, die Sie für die Kostenkontrolle benötigen. Eine Support-Konversation mit 6.000 Token, eine Vertragsprüfung mit 70.000 Token und ein Codebasis-Scan mit 900.000 Token sollten nicht dieselbe Standardroute teilen, nur weil sie alle hinter denselben API-Schlüssel passen.
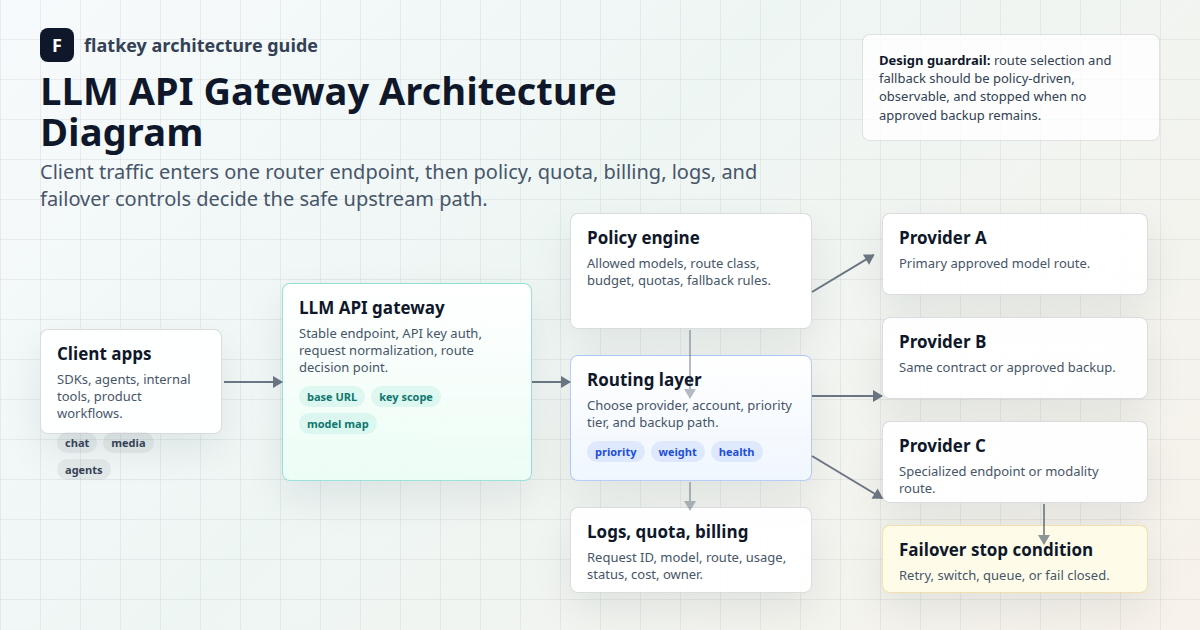
Flatkey ist bei diesem Design nützlich, da Modellzugriff, Routing, Nutzungsüberprüfung, Abrechnung und operative Kontrollen einfacher von einer einzigen Gateway-Oberfläche aus zu verwalten sind als von verstreuten Anbieterkonten. Verwenden Sie das nachstehende Framework, um Regeln für das Context Window Routing zu entwerfen, und validieren Sie dann die aktuelle Modellzeile, die Endpunktfamilie und die Nutzungseinheit auf der Flatkey-Preisseite vor dem Produktions-Rollout.
Context Window Routing beginnt mit einem Token-Budget
Beginnen Sie jede Routing-Entscheidung mit einem Budget, nicht mit einem Modellnamen.
required_context =
system_and_policy_tokens
+ user_input_tokens
+ retrieved_or_attached_context_tokens
+ tool_schema_and_tool_result_tokens
+ conversation_history_tokens
+ reserved_output_tokens
+ reserved_reasoning_tokens
+ safety_margin_tokensDie Route ist nur dann zulässig, wenn der erforderliche Kontext in das nutzbare Kontextfenster des Modells passt, nachdem Sie Platz für Ausgabe und Reasoning reserviert haben. Die Anleitung von OpenAI zu Reasoning-Modellen ist hier eine gute Erinnerung: Wenn generierte Token das Kontextfenster oder max_output_tokens erreichen, kann die Antwort unvollständig werden, und Teams sollten Platz für Reasoning und Ausgabe lassen, während sie die Arbeitslast kalibrieren.
Diese Reserve ist für die Kostenkontrolle wichtig. Wenn eine Anfrage kaum in das Kontextfenster passt, kann das Modell dennoch fehlschlagen, kürzen oder viel für Eingabe-Token ausgeben, bevor es eine unbrauchbare Antwort zurückgibt. Gutes Context Window Routing schützt davor, indem es übergroße Anfragen auf den richtigen Weg leitet, bevor der Aufruf erfolgt.
Eine praktische Routing-Matrix
Verwenden Sie diese Matrix als ersten Durchgang für das Context Window Routing. Passen Sie die Schwellenwerte an Ihre tatsächlichen Token-Zahlen, Ihren Modellkatalog, Ihre Latenz-SLOs und Ihre Qualitätsbewertungen an.
| Prompt-Klasse | Typisches Signal | Empfohlene Route | Kostenkontrollregel | Erforderlicher Nachweis |
|---|---|---|---|---|
| Kurze Aufgabe | Kleiner Prompt, kleine Antwort, keine lange Historie | Schnelle, kostengünstige Route | Vermeiden Sie Modelle mit langem Kontext, es sei denn, Evaluierungen erfordern sie | Prompt-Token, Ausgabe-Token, Erfolgsrate |
| Normaler Chat | Mäßige Historie, Tools oder strukturierte Antwort | Ausgewogene Route mit Tool- und Schema-Unterstützung | Begrenzung nach Konversation oder Eigentümer | Verwendetes Modell, Größe des Tool-Ergebnisses, Rate der schema-validen Antworten |
| Langes Dokument | Große Datei, Transkript, Richtlinie oder Vertrag | Route mit langem Kontext oder Retrieval-Route | Vergleichen Sie die Kosten für den vollen Kontext mit den Retrieval-Kosten | Eingabe-Token, zitierte Abschnitte, Antwortqualität |
| Riesiger Korpus | Viele Dateien, Codebasis, Protokolle oder Archiv | Retrieval, Chunking, Komprimierung, dann selektive Route mit langem Kontext | Füllen Sie den Korpus nicht standardmäßig auf | Abgerufene Chunks, verworfener Kontext, Cache-Trefferquote |
| Prompt mit hohem Reasoning-Anteil | Lange Aufgabe plus Planung, Tools oder Code-Reasoning | Route mit expliziter Reserve für Ausgabe und Reasoning | Reservieren Sie Platz für die Ausgabe, bevor Sie den Prompt senden | Rate unvollständiger Antworten, Reasoning-/Ausgabe-Token, p95-Latenz |
| Compliance- oder Finanzprüfung | Sensible Inhalte und Audit-Anforderungen | Festgelegte, überprüfte Route | Blockieren Sie automatischen Fallback, sofern nicht genehmigt | Angefordertes Modell, verwendetes Modell, Eigentümer, Kostennachverfolgung |
Dies ist Context Window Routing in operativer Form: Jede Klasse hat eine Route, eine Kostenregel und einen Nachweis, dass die Route funktioniert hat.
Verwenden Sie nicht standardmäßig das größte Kontextfenster
Große Kontextfenster sind nützlich. Sie sind kein kostenloser Ersatz für Routing.
Die Dokumentation von Google Gemini zu langem Kontext beschreibt Kontextfenster mit 1 Million Token und erklärt, wie langer Kontext Workflows ermöglichen kann, die zuvor Zusammenfassung, Retrieval oder Filterung erforderten. Die Dokumentation von Anthropic zu Kontextfenstern beschreibt den Kontext als den Arbeitsspeicher, der Anfrageinhalte, Tool-Ergebnisse, Dokumente, Tool-Definitionen und die Ausgabe umfasst. Beide Punkte sind wichtig: Größere Fenster erweitern die Möglichkeiten, aber alles, was Sie in das Fenster einfügen, muss dennoch bezahlt, validiert und protokolliert werden.
Die sicherste Standardeinstellung ist nicht „alles senden“. Die sicherere Standardeinstellung ist:
- Leiten Sie kurze Prompts über effiziente Routen.
- Verwenden Sie Retrieval, wenn die Antwort von einem kleinen Teil eines großen Korpus abhängt.
- Verwenden Sie langen Kontext, wenn das Modell viele Teile der Quelle gleichzeitig vergleichen muss.
- Reservieren Sie Budget für Ausgabe und Reasoning, bevor Sie ein Reasoning-Modell aufrufen.
- Protokollieren Sie genügend Nutzungsdetails, um die Kosten pro akzeptiertem Ergebnis zu vergleichen.
Das ist der Kern der Kostenkontrolle beim Context Window Routing.
Wann Retrieval besser ist als langer Kontext
Retrieval ist in der Regel besser, wenn für die Aufgabe nur wenige Belege erforderlich sind. Beispiele sind „die Verlängerungsklausel finden“, „diesen Vorfall aus den drei relevanten Protokollzeilen zusammenfassen“ oder „aus den aktuellen API-Dokumenten antworten“. In diesen Fällen kann das Senden des gesamten Vertrags, des Protokollarchivs oder der Dokumentationsseite die Kosten erhöhen, ohne die Genauigkeit zu verbessern.
Verwenden Sie Retrieval, wenn:
- Die Antwort eine kleine Anzahl von Passagen zitieren sollte.
- Der größte Teil des Korpus für die Benutzerfrage irrelevant ist.
- Derselbe Korpus wiederholt von vielen Benutzern abgefragt wird.
- Sie die Datenexposition nach Mandant, Projekt, Team oder Berechtigung einschränken müssen.
- Die Kosten für die Eingabe des vollständigen Kontexts den Wert der Antwort übersteigen würden.
Context Window Routing sollte die Anfrage zuerst durch das Retrieval senden und dann nur die ausgewählten Chunks, Metadaten und Anweisungen an das Modell weitergeben. Protokollieren Sie die abgerufenen Quell-IDs, die Token-Anzahl und das Ergebnis der Antwortakzeptanz. Wenn die Antwort fehlschlägt, weil zu viel Kontext fehlte, stufen Sie diesen Workflow auf eine Route mit größerem Kontext hoch und zeichnen Sie den Grund dafür auf.
Wann ein langer Kontext das Retrieval übertrifft
Ein langer Kontext ist stärker, wenn die Aufgabe einen breiten Vergleich erfordert. Beispiele hierfür sind die Überprüfung eines vollständigen Richtliniensatzes auf Widersprüche, die Analyse eines vollständigen Transkripts, der Vergleich von Abschnitten in einem großen Vertrag oder die Verwendung eines gesamten Repositorys als Referenzsatz für eine Planungsaufgabe.
Verwenden Sie eine Route mit langem Kontext, wenn:
- Die Aufgabe von Beziehungen zwischen vielen weit entfernten Abschnitten abhängt.
- Das Modell die gesamte Dokumentstruktur benötigt, nicht nur isolierte Passagen.
- Die Retrieval-Qualität vor der Generierung schwer zu überprüfen ist.
- Die Quelle ein einzelnes, begrenztes Artefakt ist, wie z. B. eine PDF-Datei, ein Transkript oder ein Code-Bundle.
- Der erwartete Wert der Antwort die höheren Eingabekosten rechtfertigt.
Selbst dann sollte das Context Window Routing die Kostenprüfungen nicht überspringen. Messen Sie die vollständigen Eingabe-Tokens, zwischengespeicherte Tokens (falls verfügbar), Ausgabe-Tokens, Latenz, Wiederholungsrate und die Rate der akzeptierten Antworten. Die Routing-Richtlinie sollte beweisen, dass die Route mit langem Kontext besser war als das Retrieval und nicht nur einfacher zu implementieren.
Prompt-Caching gehört in die Routenentscheidung
Prompt-Caching kann die Wirtschaftlichkeit von wiederholten langen Prompts verändern. Die Dokumentation zum Prompt-Caching von OpenAI erklärt, dass geeignete lange Prompts davon profitieren können, wenn statischer Inhalt zuerst und variabler Inhalt später erscheint; sie legen auch cached_tokens in den Nutzungsdetails offen, damit Teams das Cache-Verhalten überwachen können.
Context Window Routing sollte die Cache-Fähigkeit als erstrangiges Signal behandeln:
| Prompt-Muster | Auswirkung auf das Routing |
|---|---|
| Stabile Systemrichtlinie plus viele Benutzerfragen | Stabile Inhalte an den Anfang stellen und den Anteil der zwischengespeicherten Tokens messen |
| Wiederholtes großes Dokumentationspaket | Cache-bewusste Route mit langem Kontext in Betracht ziehen |
| Hochdynamische benutzerspezifische Daten | Keine Cache-Einsparungen annehmen |
| Gemeinsame Tool-Definitionen über viele Aufrufe hinweg | Tool-Schemata nach Möglichkeit stabil halten |
| Kurzer Prompt unterhalb der Cache-Schwelle | Zuerst Route/Modell optimieren; Caching hilft möglicherweise nicht |
Zwischengespeicherte Tokens können je nach Anbieterverhalten die Kosten oder die Latenz senken, aber sie machen das Kontextfenster nicht unendlich. Die Dokumentation von Anthropic trifft die wichtige Unterscheidung direkt: Zwischengespeicherte Prompt-Präfixe können immer noch das Kontextfenster belegen. Die Routing-Richtlinie sollte Cache-Treffer als Kostennachweis aufzeichnen, nicht als Erlaubnis, Token-Limits zu ignorieren.
Platz für Ausgabe, Schlussfolgerungen und Tools reservieren
Context Window Routing schlägt oft fehl, weil Teams nur die Eingabe-Tokens zählen. Das Modell benötigt aber noch Platz zum Antworten.
Definieren Sie für jede Route:
- Maximale Eingabe-Tokens: die größte Anfrage, die die Route akzeptieren darf.
- Reservierte Ausgabe-Tokens: Platz für die sichtbare Antwort, JSON, Zitate oder Tool-Argumente.
- Reservierte Tokens für Schlussfolgerungen: zusätzlicher Platz für schlussfolgernde Modelle oder schwierige Aufgaben.
- Tool-Overhead: Tool-Definitionen, Tool-Aufrufe und Tool-Ergebnisse.
- Sicherheitsmarge: ein Puffer für Tokenizer-Varianzen und Prompt-Wachstum.
Verwenden Sie einen Routenschutz wie diesen:
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anywayDie obigen Zahlen sind Platzhalter, keine universellen Grenzwerte. Wichtig ist die Form des Schutzmechanismus: Die Route hat eine Obergrenze für die Eingabe, eine Reserve für die Antwort, eine Reserve für Schlussfolgerungen und ein explizites Verhalten bei Budgetüberschreitung.
Kostenkontrollen für das Context Window Routing
Messen Sie die Kosten nicht nur pro Token. Messen Sie die Kosten pro akzeptiertem Ergebnis.
| Kostenmetrik | Warum sie wichtig ist |
|---|---|
| Kosten pro Anfrage | Erfasst übergroße Einzelaufrufe |
| Kosten pro akzeptierter Antwort | Berücksichtigt Wiederholungsversuche, schlechtes Retrieval und fehlgeschlagene Aufrufe mit langem Kontext |
| Kosten pro Workflow | Zeigt die wahren Kosten eines Tickets, einer Überprüfung, einer Extraktion oder eines Berichts |
| Kosten pro Eigentümer | Verbindet die Nutzung mit App, Team, Kunde oder Umgebung |
| Cache-bereinigte Eingabekosten | Trennt wiederholte stabile Präfixe von dynamischem Kontext |
| Fallback-Kosten | Zeigt, ob der Fallback die Zuverlässigkeit rettet oder eine schlechte primäre Route verbirgt |
Die öffentliche Produktoberfläche von Flatkey ist relevant, da sie die Plattform auf einheitlichen Modellzugriff, Routing, Abrechnung, Nutzungsanalysen und operative Kontrollen ausrichtet. Die Live-Preisabfrage der API für diesen Artikel am 2. Juli 2026 lieferte success: true zurück und legte Endpunktfamilien wie openai, anthropic, gemini, image-generation, openai-video und video offen. Betrachten Sie dies als veralteten Beleg für die Routenplanung und nicht als Versprechen, dass jedes Modell, jeder Preis oder jeder Endpunkt unverändert bleibt.
Eine Vorlage für eine Context-Window-Routing-Richtlinie
Fassen Sie die Regeln in einem Format zusammen, das von den Abteilungen Technik, Finanzen und Beschaffung überprüft werden kann.
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredDiese Vorlage macht das Context-Window-Routing testbar. Wenn sich die Route ändert, kann der Verantwortliche den Grund dafür erkennen. Wenn der Prompt wächst, kann die Leitplanke ihn blockieren. Wenn die Anfrage wiederholt wird, werden Cache-Metriken Teil der Überprüfung.
Abnahmetests vor der Produktion
Führen Sie diese Tests aus, bevor Sie das Context-Window-Routing für den Produktionsverkehr einsetzen:
- Senden Sie einen kurzen Prompt und bestätigen Sie, dass er nicht über die Long-Context-Route geleitet wird.
- Senden Sie einen normalen Chat-Prompt mit Tools und bestätigen Sie, dass Tool-Definitionen und Ergebnisse gezählt werden.
- Senden Sie einen langen Dokumenten-Prompt und überprüfen Sie, ob der reservierte Ausgabespeicherplatz verfügbar bleibt.
- Senden Sie einen Prompt, der das Budget überschreitet, und bestätigen Sie, dass die Route zusammenfasst, abruft oder eine Reduzierung des Umfangs anfordert, anstatt blind zu senden.
- Lösen Sie eine aufwändige Reasoning-Aufgabe aus und überprüfen Sie die Handhabung unvollständiger Antworten.
- Wiederholen Sie einen stabilen langen Prompt und bestätigen Sie, dass die Metriken für zwischengespeicherte Token erfasst werden, wenn der Anbieter sie bereitstellt.
- Vergleichen Sie Retrieval-First-Antworten mit Full-Context-Antworten auf demselben Evaluierungsset.
- Überprüfen Sie das angeforderte Modell, das bereitgestellte Modell, die Endpunktfamilie, die Nutzungseinheiten, den Fallback-Grund und die Kosten- oder Budgetauswirkungen in den Protokollen.
Für eine umfassendere Architektur kombinieren Sie diese Prüfungen mit den Anleitungen von Flatkey zu KI-API-Gateways, LLM-API-Gateway-Architektur, KI-API-Lastenausgleich und Failover und Design von Modell-Routing-Richtlinien.
Wo Flatkey ins Spiel kommt
Flatkey sollte nicht der einzige Ort sein, an dem die Richtlinie existiert. Es sollte der Ort sein, an dem Teams die Ausführung und Überprüfung der Richtlinie vereinfachen können.
Nutzen Sie Flatkey, um den Modellzugriff, die Routenüberprüfung, aktuelle Preisprüfungen, die Nutzungstransparenz, Kontingente, Anforderungsprotokolle und die Rechnungsprüfung zu zentralisieren. Bewahren Sie die Context-Window-Routing-Richtlinie dann im Code oder in der Konfiguration auf, damit Routenentscheidungen wiederholbar sind. Das Gateway bietet den Finanz- und Betriebsabteilungen einen übersichtlicheren Ort zur Überprüfung der Nutzung; die Richtlinie teilt der Technik mit, welche Route zulässig ist.
Ein praktischer Testlauf mit Flatkey sieht wie folgt aus:
- Wählen Sie einen Workflow mit bekannten Prompt-Größenbereichen.
- Überprüfen Sie die aktuellen Modell- und Endpunktoptionen auf der Flatkey-Preisseite.
- Führen Sie kurze, normale, lange, budgetüberschreitende und wiederholte, zwischenspeicherbare Prompts aus.
- Überprüfen Sie die Anforderungsprotokolle auf Routenentscheidung, bereitgestelltes Modell, Nutzung, verfügbare Cache-Felder, Fallback-Grund und Eigentümerschlüssel.
- Bestätigen Sie das Kontingent- und Kostenüberprüfungsverhalten mit dem Workflow-Verantwortlichen.
- Übertragen Sie nur die getesteten Routen in die Produktion und erweitern Sie dann das Context-Window-Routing Zeile für Zeile.
Wenn der Test erfolgreich ist, holen Sie sich einen Schlüssel und halten Sie den ersten Rollout eng begrenzt. Der Zweck des Context-Window-Routings besteht nicht darin, die Komplexität zu erhöhen, sondern zu verhindern, dass das Wachstum von Prompts unbemerkt zu ausufernden Kosten, unvollständigen Antworten und nicht überprüfbaren Modellentscheidungen führt.
FAQ
Was ist Context-Window-Routing?
Context-Window-Routing ist eine Richtlinie, die die Modellroute, den Abrufpfad, den Komprimierungspfad oder das Ablehnungsverhalten basierend auf der Prompt-Größe, der Ausgabereserve, der Reasoning-Reserve, dem Tool-Overhead, den Kostenkontrollen und den erforderlichen Nachweisen auswählt.
Wie unterscheidet sich Context-Window-Routing vom Modell-Routing?
Modell-Routing kann nach Qualität, Preis, Latenz, Modalität, Region oder Anbieter auswählen. Context-Window-Routing konzentriert sich darauf, ob die Anfrage in das nutzbare Kontextbudget passt und ob eine kleinere, Retrieval-First-, zwischengespeicherte oder Long-Context-Route die richtige Wahl zur Kostenkontrolle ist.
Wann sollte ein Team Retrieval anstelle eines Long-Context-Modells verwenden?
Verwenden Sie Retrieval, wenn die Antwort von einem kleinen Teil eines großen Korpus abhängt, wenn Berechtigungen eine Rolle spielen oder wenn wiederholte Full-Context-Eingaben teuer wären. Verwenden Sie Long Context, wenn die Aufgabe einen breiten Vergleich über viele weit voneinander entfernte Teile der Quelle erfordert.
Warum sollte man Ausgabe- und Reasoning-Tokens reservieren?
Ein Prompt kann in die Eingabeseite des Kontextfensters passen und trotzdem fehlschlagen, weil nicht genügend Platz für das Reasoning oder die sichtbare Antwort übrig ist. Das Reservieren von Ausgabe- und Reasoning-Tokens reduziert unvollständige Antworten und verschwendete Ausgaben.
Hebt Prompt-Caching die Notwendigkeit für Context Window Routing auf?
Nein. Prompt-Caching kann die Latenz oder die Eingabekosten für wiederholte Präfixe reduzieren, aber gecachte Tokens müssen trotzdem im Kontextfenster berücksichtigt werden. Context Window Routing sollte Metriken für gecachte Tokens protokollieren und gleichzeitig die Budgetgrenzen durchsetzen.
Wie hilft Flatkey beim Context Window Routing?
Flatkey bietet Teams eine einzige Gateway-Oberfläche für den Modellzugriff, die Überprüfung von Routen, Preiskontrollen, Nutzungsanalysen, Anfrageprotokolle, Kontingente und die Rechnungsprüfung. Das macht es einfacher zu überprüfen, ob das Context Window Routing die Prompt-Größe und die Kosten wie vorgesehen steuert.