長いプロンプトは、自動的に長文コンテキストの問題になるわけではありません。プロンプトによっては、トリミングすべきもの、検索を利用すべきもの、より多くの出力スペースを確保すべきもの、そして本当に大きなコンテキストウィンドウを必要とするものがあります。コンテキストウィンドウルーティングは、リクエストが間違ったモデルで予算を浪費する前に、どのパスをたどるべきかを決定するポリシーです。
目標はシンプルです。実際のプロンプトサイズ、必要な回答の形式、そしてコスト管理に必要なエビデンスによってルーティングすることです。6,000トークンのサポート会話、70,000トークンの契約書レビュー、900,000トークンのコードベーススキャンは、すべて同じAPIキーの背後に収まるからといって、単一のデフォルトルートを共有すべきではありません。
Flatkeyはこの設計において有用です。なぜなら、モデルアクセス、ルーティング、使用状況のレビュー、請求、運用管理は、散在するプロバイダーアカウントからよりも、単一のゲートウェイサーフェスから管理する方が簡単だからです。以下のフレームワークを使用してコンテキストウィンドウルーティングルールを設計し、本番環境への展開前にFlatkeyの料金で現在のモデル行、エンドポイントファミリー、および使用単位を検証してください。
コンテキストウィンドウルーティングはトークンバジェットから始まる
すべてのルート決定は、モデル名ではなく、バジェットから始めます。
required_context =
システムおよびポリシートークン
+ ユーザー入力トークン
+ 検索または添付されたコンテキストトークン
+ ツールスキーマおよびツール結果トークン
+ 会話履歴トークン
+ 予約済み出力トークン
+ 予約済み推論トークン
+ 安全マージントークンルートが適格となるのは、出力と推論のスペースを予約した後に、必要なコンテキストがモデルの使用可能なコンテキストウィンドウに収まる場合のみです。ここでOpenAIの推論モデルガイダンスは良いリマインダーになります。生成されたトークンがコンテキストウィンドウまたはmax_output_tokensに達すると、応答が不完全になる可能性があり、チームはワークロードを調整する際に推論と出力のための余地を残しておくべきです。
その予約はコスト管理にとって重要です。リクエストがコンテキストウィンドウにかろうじて収まる場合でも、モデルは失敗したり、応答を切り捨てたり、使用不能な回答を返す前に入力トークンに多額の費用を費やしたりする可能性があります。優れたコンテキストウィンドウルーティングは、呼び出しが行われる前に、大きすぎるリクエストを正しいパスにルーティングすることで、これを防ぎます。
実践的なルーティングマトリックス
このマトリックスをコンテキストウィンドウルーティングの第一段階として使用してください。実際のトークン数、モデルカタログ、レイテンシーSLO、および品質評価に対してしきい値を調整します。
| プロンプトクラス | 典型的なシグナル | 推奨ルート | コスト管理ルール | 必要なエビデンス |
|---|---|---|---|---|
| 短いタスク | 短いプロンプト、短い回答、長い履歴なし | 高速で低コストなルート | 評価で必要とされない限り、長文コンテキストモデルを避ける | プロンプトトークン、出力トークン、成功率 |
| 通常のチャット | 中程度の履歴、ツール、または構造化された回答 | ツールとスキーマをサポートするバランスの取れたルート | 会話または所有者ごとに上限を設定 | 提供されたモデル、ツール結果サイズ、スキーマ検証率 |
| 長文ドキュメント | 大きなファイル、トランスクリプト、ポリシー、または契約書 | 長文コンテキストルートまたは検索ルート | フルコンテキストのコストと検索コストを比較 | 入力トークン、引用スパン、回答品質 |
| 巨大なコーパス | 多数のファイル、コードベース、ログ、またはアーカイブ | 検索、チャンキング、圧縮、そして選択的な長文コンテキストルート | デフォルトでコーパスを詰め込まない | 検索されたチャンク、ドロップされたコンテキスト、キャッシュヒット率 |
| 推論を多用するプロンプト | 長いタスクに加えて、計画、ツール、またはコードの推論 | 明示的な出力と推論の予約を持つルート | プロンプトを送信する前に出力スペースを予約 | 不完全率、推論/出力トークン、p95レイテンシー |
| コンプライアンスまたは財務レビュー | 機密コンテンツと監査要件 | レビュー済みの固定ルート | 承認されない限り、自動フォールバックをブロック | リクエストされたモデル、提供されたモデル、所有者、コストトレース |
これが運用形式でのコンテキストウィンドウルーティングです。各クラスにはルート、コストルール、そしてルートが機能したことの証明があります。
最大のコンテキストウィンドウをデフォルトとして使用しない
大きなコンテキストウィンドウは有用です。しかし、ルーティングの無料の代替品ではありません。
GoogleのGemini長文コンテキストドキュメントは、100万トークンのコンテキストウィンドウについて説明し、長文コンテキストが以前は要約、検索、またはフィルタリングを必要としていたワークフローをどのように解放できるかを説明しています。Anthropicのコンテキストウィンドウドキュメントは、コンテキストをリクエスト内容、ツール結果、ドキュメント、ツール定義、および出力を含むワーキングメモリとして説明しています。両方の点が重要です。より大きなウィンドウは可能なことを広げますが、ウィンドウに入れるすべてのものには依然として支払い、検証、ログ記録が必要です。
最も安全なデフォルトは「すべてを送信する」ことではありません。より安全なデフォルトは次のとおりです。
- 短いプロンプトは効率的なルートに維持します。
- 回答が大規模なコーパスの小さな断片に依存する場合は、検索を使用します。
- モデルがソースの多くの部分を一度に比較する必要がある場合は、長文コンテキストを使用します。
- 推論モデルを呼び出す前に、出力と推論のバジェットを予約します。
- 承認された結果あたりのコストを比較するために、十分な使用詳細をログに記録します。
それがコンテキストウィンドウルーティングのコスト管理の中核です。
検索が長文コンテキストに勝る場合
タスクが必要とする証拠が限定的な場合、通常は検索の方が優れています。例としては、「更新条項を見つける」、「関連する3行のログからこのインシデントを要約する」、「現在のAPIドキュメントから回答する」などが挙げられます。このような場合、契約書全体、ログアーカイブ、またはドキュメントサイト全体を送信すると、精度を向上させることなくコストが増加する可能性があります。
次の場合に検索を使用します。
- 回答が少数の文章を引用すべき場合。
- コーパスの大部分がユーザーの質問と無関係な場合。
- 同じコーパスが多くのユーザーによって繰り返しクエリされる場合。
- テナント、プロジェクト、チーム、または権限によってデータへのアクセスを制限する必要がある場合。
- フルコンテキスト入力のコストが回答の価値を上回る場合。
コンテキストウィンドウルーティングでは、まずリクエストを検索に送り、選択されたチャンク、メタデータ、および指示のみをモデルに渡すべきです。取得されたソースID、トークン数、および回答の受け入れ結果をログに記録します。コンテキストが不足しすぎて回答が失敗した場合は、そのワークフローをより大きなコンテキストルートに昇格させ、その理由を記録します。
長いコンテキストが検索に勝る場合
タスクが広範な比較を必要とする場合、長いコンテキストの方が強力です。例としては、矛盾がないかポリシーセット全体を確認する、完全なトランスクリプトを分析する、大規模な契約書全体でセクションを比較する、計画タスクの参照セットとしてリポジトリ全体を使用する、などが挙げられます。
次の場合に長いコンテキストルートを使用します。
- タスクが遠く離れた多くのセクション間の関係に依存する場合。
- モデルが分離された文章だけでなく、ドキュメント全体の構造を必要とする場合。
- 生成前に検索の品質を検証するのが難しい場合。
- ソースが単一の限定された成果物(1つのPDF、1つのトランスクリプト、1つのコードバンドルなど)である場合。
- 回答の期待値がより大きな入力コストを正当化する場合。
その場合でも、コンテキストウィンドウルーティングはコストチェックを省略すべきではありません。完全な入力トークン、利用可能な場合はキャッシュされたトークン、出力トークン、レイテンシー、再試行率、および回答の受け入れ率を測定します。ルーティングポリシーは、長いコンテキストルートが単に実装が容易であるだけでなく、検索よりも優れていたことを証明する必要があります。
プロンプトのキャッシュはルート決定に含めるべき
プロンプトのキャッシュは、繰り返される長いプロンプトの経済性を変える可能性があります。OpenAIのプロンプトキャッシュに関するドキュメントでは、対象となる長いプロンプトは、静的なコンテンツが先に、可変的なコンテンツが後に現れる場合にメリットがあると説明されています。また、使用状況の詳細でcached_tokensを公開しているため、チームはキャッシュの動作を監視できます。
コンテキストウィンドウルーティングは、キャッシュ可能性を第一級のシグナルとして扱うべきです。
| プロンプトのパターン | ルーティングへの影響 |
|---|---|
| 安定したシステムポリシーと多数のユーザー質問 | 安定したコンテンツを先に配置し、キャッシュされたトークンの割合を測定する |
| 繰り返される大規模なドキュメントバンドル | キャッシュを意識した長いコンテキストルートを検討する |
| 非常に動的なユーザー固有のデータ | キャッシュによる節約を前提としない |
| 多くの呼び出しで共有されるツール定義 | 可能な限りツールスキーマを安定させる |
| キャッシュのしきい値を下回る短いプロンプト | まずルート/モデルを最適化する。キャッシュは役立たない可能性がある |
キャッシュされたトークンは、プロバイダーの動作によってはコストやレイテンシーを低下させる可能性がありますが、コンテキストウィンドウを無限にするわけではありません。Anthropicのドキュメントでは、この重要な区別が直接的に述べられています。キャッシュされたプロンプトのプレフィックスは、依然としてコンテキストウィンドウを占有する可能性があります。ルーティングポリシーは、キャッシュヒットをトークン制限を無視する許可としてではなく、コストの証拠として記録すべきです。
出力、推論、およびツール用のスペースを確保する
コンテキストウィンドウルーティングは、チームが入力トークンのみをカウントするために失敗することがよくあります。モデルにはまだ回答するためのスペースが必要です。
各ルートについて、以下を定義します。
- 最大入力トークン数: ルートが受け入れることができる最大のリクエスト。
- 予約済み出力トークン数: 表示される回答、JSON、引用、またはツール引数のためのスペース。
- 予約済み推論トークン数: 推論モデルや困難なタスクのための追加スペース。
- ツールオーバーヘッド: ツール定義、ツール呼び出し、およびツール結果。
- 安全マージン: トークナイザーのばらつきやプロンプトの増加に対するバッファ。
次のようなルートガードを使用します。
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anyway上記の数値はプレースホルダーであり、普遍的な制限ではありません。重要なのはガードレールの形状です。ルートには入力の上限、回答用の予約、推論用の予約、そして予算超過時の明確な動作が設定されています。
コンテキストウィンドウルーティングのコスト管理
コストをトークン単位でのみ測定しないでください。受け入れられた成果あたりのコストを測定してください。
| コスト指標 | 重要である理由 |
|---|---|
| リクエストあたりのコスト | 大きすぎる単一の呼び出しを検出する |
| 受け入れられた回答あたりのコスト | 再試行、不適切な検索、失敗した長いコンテキストの呼び出しを考慮に入れる |
| ワークフローあたりのコスト | チケット、レビュー、抽出、またはレポートの真のコストを示す |
| 所有者あたりのコスト | 使用状況をアプリ、チーム、顧客、または環境に結び付ける |
| キャッシュ調整後の入力コスト | 繰り返される安定したプレフィックスを動的なコンテキストから分離する |
| フォールバックコスト | フォールバックが信頼性を救っているのか、それとも不適切なプライマリルートを隠しているのかを示す |
Flatkeyの公開製品サーフェスが関連するのは、プラットフォームが統一されたモデルアクセス、ルーティング、請求、使用状況分析、運用管理を中心に位置づけられているためです。2026年7月2日にこの記事のために行われたライブ価格APIチェックでは、success: trueが返され、openai、anthropic、gemini、image-generation、openai-video、videoなどのエンドポイントファミリーが公開されました。これはルート計画のための古い証拠として扱い、すべてのモデル、価格、またはエンドポイントが変更されないという約束ではありません。
コンテキストウィンドウルーティングポリシーのテンプレート
エンジニアリング、財務、調達の各部門がレビューできる形式でルールを記述します。
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredこのテンプレートにより、コンテキストウィンドウルーティングがテスト可能になります。ルートが変更された場合、所有者はその理由を確認できます。プロンプトが大きくなった場合、ガードレールがそれをブロックできます。リクエストが繰り返される場合、キャッシュメトリクスがレビューの一部になります。
本番稼働前の受け入れテスト
コンテキストウィンドウルーティングで本番トラフィックを処理する前に、これらのテストを実行してください:
- 短いプロンプトを送信し、それが長文コンテキストルートから外れていることを確認します。
- ツール付きの通常のチャットプロンプトを送信し、ツールの定義と結果がカウントされていることを確認します。
- 長いドキュメントのプロンプトを送信し、予約された出力スペースが利用可能なままであることを確認します。
- 予算超過のプロンプトを送信し、ルートが盲目的に送信するのではなく、要約、検索、またはスコープの縮小を要求することを確認します。
- 推論を多用するタスクをトリガーし、不完全な応答の処理を確認します。
- 安定した長いプロンプトを繰り返し、プロバイダーが公開している場合にキャッシュされたトークンのメトリクスが記録されることを確認します。
- 同じ評価セットで、検索優先の回答と全文コンテキストの回答を比較します。
- ログで、要求されたモデル、提供されたモデル、エンドポイントファミリー、使用単位、フォールバック理由、コストまたは残高への影響を確認します。
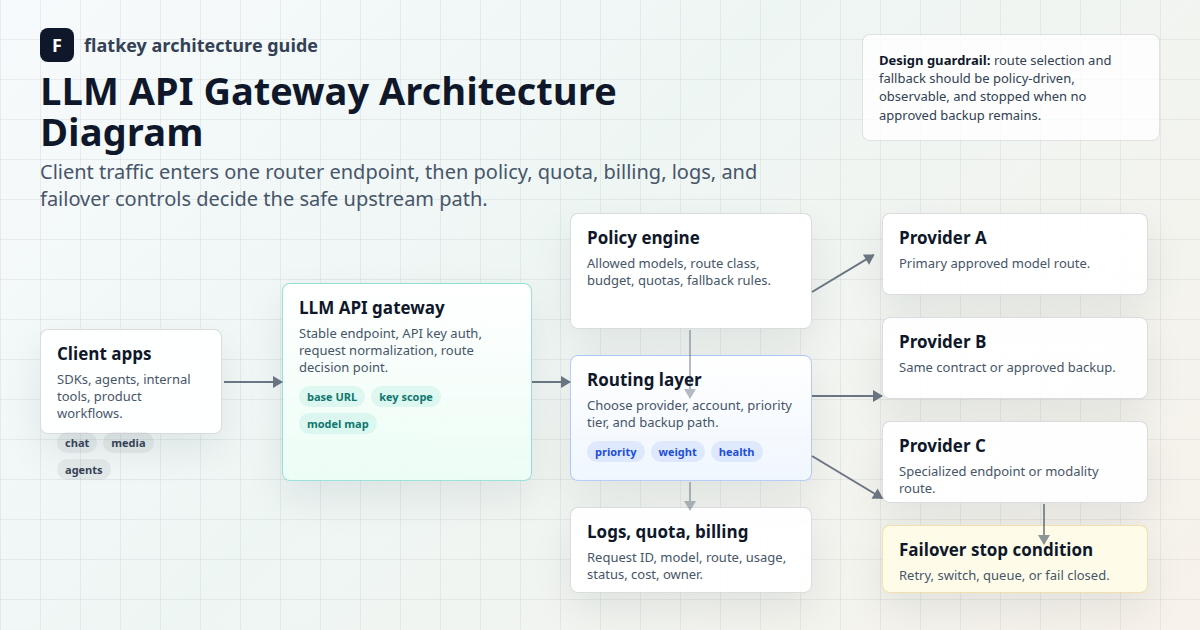
より広範なアーキテクチャについては、これらのチェックをFlatkeyのAI APIゲートウェイ、LLM APIゲートウェイアーキテクチャ、AI APIの負荷分散とフェイルオーバー、およびモデルルーティングポリシーの設計に関するガイドと組み合わせてください。
Flatkeyの位置づけ
Flatkeyは、ポリシーが存在する唯一の場所であるべきではありません。チームがポリシーの実行とレビューを容易にできる場所であるべきです。
Flatkeyを使用して、モデルアクセス、ルートレビュー、現在の価格チェック、使用状況の可視化、クォータ、リクエストログ、請求レビューを一元化します。次に、ルート決定が再現可能になるように、コンテキストウィンドウルーティングポリシーをコードまたは構成で保持します。ゲートウェイは財務および運用部門に使用状況を検査するためのより明確な場所を提供し、ポリシーはエンジニアリング部門に許可されるルートを伝えます。
Flatkeyでの実践的な検証は次のようになります:
- 既知のプロンプトサイズ範囲を持つワークフローを1つ選択します。
- Flatkeyの価格で現在のモデルとエンドポイントのオプションを確認します。
- 短い、通常の、長い、予算超過の、そして繰り返しキャッシュ可能なプロンプトを実行します。
- リクエストログで、ルート決定、提供されたモデル、使用状況、利用可能な場合はキャッシュフィールド、フォールバック理由、所有者キーを確認します。
- ワークフローの所有者とクォータおよびコストレビューの動作を確認します。
- テスト済みのルートのみを本番環境に移行し、その後コンテキストウィンドウルーティングを一行ずつ拡張します。
検証に合格したら、キーを取得し、最初の展開は小規模に保ちます。コンテキストウィンドウルーティングの要点は、複雑さを加えることではなく、プロンプトの増大が静かに暴走コスト、不完全な回答、レビュー不可能なモデル選択に変わるのを防ぐことです。
FAQ
コンテキストウィンドウルーティングとは何ですか?
コンテキストウィンドウルーティングは、プロンプトサイズ、出力予約、推論予約、ツールオーバーヘッド、コスト管理、および必要な証拠に基づいて、モデルルート、検索パス、圧縮パス、または拒否動作を選択するポリシーです。
コンテキストウィンドウルーティングはモデルルーティングとどう違いますか?
モデルルーティングは、品質、価格、レイテンシー、モダリティ、地域、またはプロバイダーによって選択できます。コンテキストウィンドウルーティングは、リクエストが利用可能なコンテキスト予算に収まるかどうか、そしてより小さい、検索優先、キャッシュされた、または長文コンテキストのルートが適切なコスト管理の選択肢であるかどうかに焦点を当てます。
チームは長文コンテキストモデルの代わりに検索を使用すべきなのはいつですか?
回答が大規模なコーパスの小さな部分に依存する場合、権限が重要である場合、または全文コンテキストの入力の繰り返しが高価になる場合に検索を使用します。タスクがソースの多くの離れた部分にわたる広範な比較を必要とする場合に長文コンテキストを使用します。
なぜ出力トークンと推論トークンを予約するのですか?
プロンプトがコンテキストウィンドウの入力側に収まっても、推論や表示される回答のための十分なスペースが残っていないために失敗することがあります。出力トークンと推論トークンを予約することで、不完全な応答や無駄な支出を減らすことができます。
プロンプトのキャッシュは、コンテキストウィンドウルーティングの必要性をなくしますか?
いいえ。プロンプトのキャッシュは、繰り返されるプレフィックスのレイテンシーや入力コストを削減できますが、キャッシュされたトークンもコンテキストウィンドウで考慮する必要があります。コンテキストウィンドウルーティングは、予算制限を適用しながら、キャッシュされたトークンのメトリクスをログに記録する必要があります。
Flatkeyはコンテキストウィンドウルーティングにどのように役立ちますか?
Flatkeyは、モデルアクセス、ルートレビュー、価格チェック、使用状況分析、リクエストログ、クォータ、請求レビューのための単一のゲートウェイサーフェスをチームに提供します。これにより、コンテキストウィンドウルーティングが設計どおりにプロンプトサイズとコストを制御しているかどうかを簡単に検証できます。