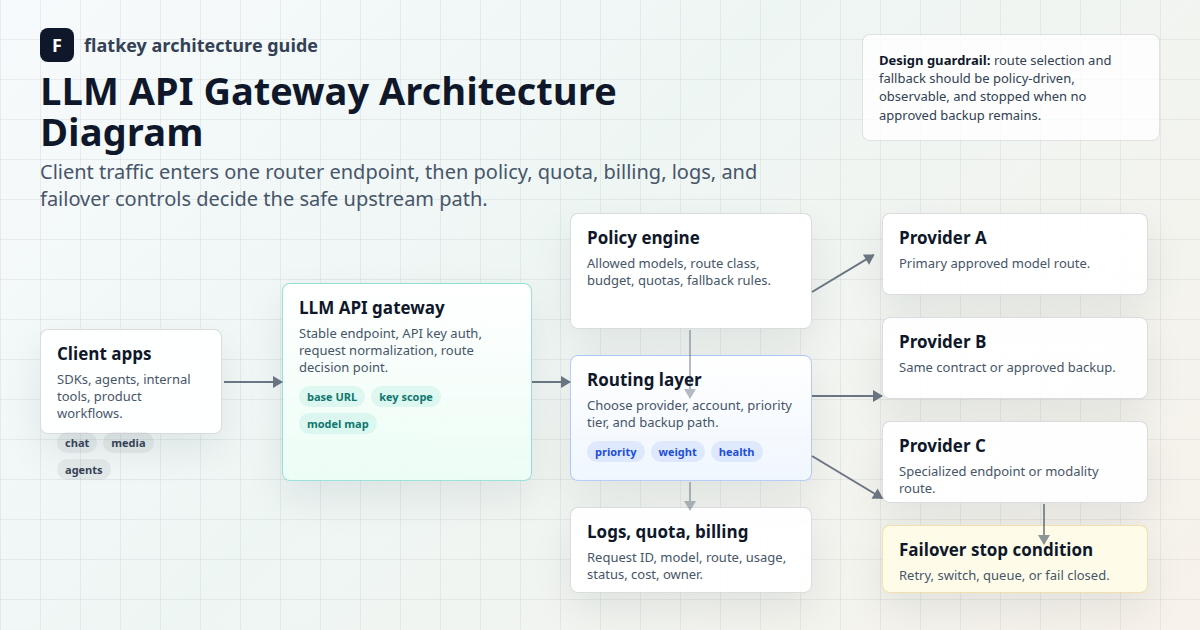
Prompt dài không tự động là vấn đề về ngữ cảnh dài. Một số prompt nên được cắt bớt, một số nên sử dụng truy xuất, một số nên dành nhiều không gian đầu ra hơn, và một số thực sự cần một cửa sổ ngữ cảnh lớn hơn. Định tuyến cửa sổ ngữ cảnh là chính sách quyết định đường đi của một yêu cầu trước khi nó tiêu tốn ngân sách vào sai mô hình.
Mục tiêu rất đơn giản: định tuyến theo kích thước prompt thực tế, hình dạng câu trả lời yêu cầu, và bằng chứng bạn cần để kiểm soát chi phí. Một cuộc trò chuyện hỗ trợ 6.000 token, một bài đánh giá hợp đồng 70.000 token, và một lần quét mã nguồn 900.000 token không nên chia sẻ cùng một tuyến mặc định chỉ vì chúng đều nằm sau cùng một khóa API.
Flatkey hữu ích trong thiết kế này vì việc truy cập mô hình, định tuyến, xem xét sử dụng, thanh toán và kiểm soát hoạt động dễ quản lý hơn từ một bề mặt cổng vào duy nhất so với từ các tài khoản nhà cung cấp rải rác. Sử dụng khung dưới đây để thiết kế các quy tắc định tuyến cửa sổ ngữ cảnh, sau đó xác thực hàng mô hình hiện tại, họ điểm cuối và đơn vị sử dụng trên bảng giá Flatkey trước khi triển khai sản xuất.
Định tuyến cửa sổ ngữ cảnh bắt đầu với ngân sách token
Bắt đầu mọi quyết định định tuyến bằng ngân sách, không phải tên mô hình.
required_context =
system_and_policy_tokens
+ user_input_tokens
+ retrieved_or_attached_context_tokens
+ tool_schema_and_tool_result_tokens
+ conversation_history_tokens
+ reserved_output_tokens
+ reserved_reasoning_tokens
+ safety_margin_tokensTuyến đường chỉ đủ điều kiện nếu ngữ cảnh yêu cầu vừa với cửa sổ ngữ cảnh có thể sử dụng của mô hình sau khi bạn đã dành không gian cho đầu ra và suy luận. Hướng dẫn về mô hình suy luận của OpenAI là một lời nhắc nhở hữu ích ở đây: khi các token được tạo ra đạt đến cửa sổ ngữ cảnh hoặc max_output_tokens, phản hồi có thể trở nên không hoàn chỉnh, và các nhóm nên để dành không gian cho suy luận và đầu ra trong khi họ hiệu chỉnh khối lượng công việc.
Việc dự trữ đó rất quan trọng để kiểm soát chi phí. Nếu một yêu cầu vừa khít với cửa sổ ngữ cảnh, mô hình vẫn có thể thất bại, cắt ngắn, hoặc chi tiêu nhiều vào các token đầu vào trước khi trả về một câu trả lời không thể sử dụng được. Định tuyến cửa sổ ngữ cảnh tốt sẽ bảo vệ chống lại điều đó bằng cách định tuyến các yêu cầu quá lớn đến đúng đường đi trước khi cuộc gọi được thực hiện.
Một ma trận định tuyến thực tế
Sử dụng ma trận này như là bước đầu tiên cho việc định tuyến cửa sổ ngữ cảnh. Điều chỉnh các ngưỡng dựa trên số lượng token thực tế, danh mục mô hình, SLO về độ trễ và các đánh giá chất lượng của bạn.
| Lớp prompt | Tín hiệu điển hình | Tuyến đề xuất | Quy tắc kiểm soát chi phí | Bằng chứng yêu cầu |
|---|---|---|---|---|
| Tác vụ ngắn | Prompt nhỏ, câu trả lời nhỏ, không có lịch sử dài | Tuyến nhanh, chi phí thấp | Tránh các mô hình ngữ cảnh dài trừ khi các đánh giá yêu cầu | Token prompt, token đầu ra, tỷ lệ thành công |
| Trò chuyện thông thường | Lịch sử vừa phải, công cụ, hoặc câu trả lời có cấu trúc | Tuyến cân bằng với hỗ trợ công cụ và schema | Giới hạn theo cuộc trò chuyện hoặc chủ sở hữu | Mô hình đã phục vụ, kích thước kết quả công cụ, tỷ lệ hợp lệ schema |
| Tài liệu dài | Tệp lớn, bản ghi, chính sách, hoặc hợp đồng | Tuyến ngữ cảnh dài hoặc tuyến truy xuất | So sánh chi phí ngữ cảnh đầy đủ với chi phí truy xuất | Token đầu vào, các đoạn được trích dẫn, chất lượng câu trả lời |
| Corpus khổng lồ | Nhiều tệp, mã nguồn, log, hoặc kho lưu trữ | Truy xuất, phân đoạn, nén, sau đó là tuyến ngữ cảnh dài có chọn lọc | Không nhồi nhét corpus theo mặc định | Các đoạn được truy xuất, ngữ cảnh bị loại bỏ, tỷ lệ trúng cache |
| Prompt nặng về suy luận | Tác vụ dài cộng với lập kế hoạch, công cụ, hoặc suy luận mã | Tuyến có dự trữ rõ ràng cho đầu ra và suy luận | Dành không gian đầu ra trước khi gửi prompt | Tỷ lệ không hoàn chỉnh, token suy luận/đầu ra, độ trễ p95 |
| Đánh giá tuân thủ hoặc tài chính | Nội dung nhạy cảm và yêu cầu kiểm toán | Tuyến đã được xem xét và ghim lại | Chặn dự phòng tự động trừ khi được phê duyệt | Mô hình yêu cầu, mô hình đã phục vụ, chủ sở hữu, dấu vết chi phí |
Đây là định tuyến cửa sổ ngữ cảnh ở dạng hoạt động: mỗi lớp có một tuyến, một quy tắc chi phí, và bằng chứng cho thấy tuyến đó đã hoạt động.
Đừng sử dụng cửa sổ ngữ cảnh lớn nhất làm mặc định
Các cửa sổ ngữ cảnh lớn rất hữu ích. Chúng không phải là sự thay thế miễn phí cho việc định tuyến.
Tài liệu về ngữ cảnh dài của Gemini của Google mô tả các cửa sổ ngữ cảnh 1 triệu token và giải thích cách ngữ cảnh dài có thể mở khóa các quy trình công việc trước đây cần tóm tắt, truy xuất hoặc lọc. Tài liệu về cửa sổ ngữ cảnh của Anthropic mô tả ngữ cảnh là bộ nhớ làm việc bao gồm nội dung yêu cầu, kết quả công cụ, tài liệu, định nghĩa công cụ và đầu ra. Cả hai điểm đều quan trọng: các cửa sổ lớn hơn mở rộng những gì có thể, nhưng mọi thứ bạn đặt vào cửa sổ vẫn cần được thanh toán, xác thực và ghi lại.
Mặc định an toàn nhất không phải là "gửi mọi thứ." Mặc định an toàn hơn là:
- Giữ các prompt ngắn trên các tuyến hiệu quả.
- Sử dụng truy xuất khi câu trả lời phụ thuộc vào một phần nhỏ của một corpus lớn.
- Sử dụng ngữ cảnh dài khi mô hình phải so sánh nhiều phần của nguồn cùng một lúc.
- Dành ngân sách cho đầu ra và suy luận trước khi gọi một mô hình suy luận.
- Ghi lại đủ chi tiết sử dụng để so sánh chi phí cho mỗi kết quả được chấp nhận.
Đó là cốt lõi kiểm soát chi phí của định tuyến cửa sổ ngữ cảnh.
Khi nào truy xuất tốt hơn ngữ cảnh dài
Truy xuất thường tốt hơn khi tác vụ có nhu cầu bằng chứng hẹp. Ví dụ bao gồm "tìm điều khoản gia hạn", "tóm tắt sự cố này từ ba dòng log liên quan" hoặc "trả lời từ tài liệu API hiện tại". Trong những trường hợp đó, việc gửi toàn bộ hợp đồng, kho lưu trữ log hoặc trang tài liệu có thể làm tăng chi phí mà không cải thiện độ chính xác.
Sử dụng truy xuất khi:
- Câu trả lời nên trích dẫn một số lượng nhỏ các đoạn văn.
- Hầu hết kho dữ liệu không liên quan đến câu hỏi của người dùng.
- Cùng một kho dữ liệu được nhiều người dùng truy vấn lặp đi lặp lại.
- Bạn cần hạn chế việc tiếp xúc dữ liệu theo đối tượng thuê, dự án, nhóm hoặc quyền.
- Chi phí đầu vào ngữ cảnh đầy đủ sẽ vượt trội so với giá trị của câu trả lời.
Định tuyến cửa sổ ngữ cảnh nên gửi yêu cầu qua truy xuất trước, sau đó chỉ chuyển các đoạn đã chọn, siêu dữ liệu và hướng dẫn cho mô hình. Ghi lại ID nguồn được truy xuất, số lượng token và kết quả chấp nhận câu trả lời. Nếu câu trả lời không thành công do thiếu quá nhiều ngữ cảnh, hãy nâng cấp quy trình công việc đó lên một tuyến ngữ cảnh lớn hơn và ghi lại lý do.
Khi nào ngữ cảnh dài vượt trội hơn truy xuất
Ngữ cảnh dài mạnh hơn khi tác vụ cần so sánh rộng. Ví dụ bao gồm xem xét một bộ chính sách đầy đủ để tìm mâu thuẫn, phân tích một bản ghi đầy đủ, so sánh các phần trong một hợp đồng lớn, hoặc sử dụng toàn bộ kho lưu trữ làm bộ tham chiếu cho một tác vụ lập kế hoạch.
Sử dụng tuyến ngữ cảnh dài khi:
- Tác vụ phụ thuộc vào các mối quan hệ giữa nhiều phần xa nhau.
- Mô hình cần toàn bộ cấu trúc tài liệu, không chỉ các đoạn văn riêng lẻ.
- Chất lượng truy xuất khó xác minh trước khi tạo ra.
- Nguồn là một tạo phẩm có giới hạn duy nhất, chẳng hạn như một tệp PDF, một bản ghi hoặc một gói mã.
- Giá trị kỳ vọng của câu trả lời xứng đáng với chi phí đầu vào lớn hơn.
Ngay cả khi đó, định tuyến cửa sổ ngữ cảnh cũng không nên bỏ qua việc kiểm tra chi phí. Đo lường toàn bộ token đầu vào, token được lưu trong bộ nhớ đệm nếu có, token đầu ra, độ trễ, tỷ lệ thử lại và tỷ lệ câu trả lời được chấp nhận. Chính sách định tuyến phải chứng minh rằng tuyến ngữ cảnh dài tốt hơn so với truy xuất, chứ không chỉ đơn giản là dễ triển khai hơn.
Lưu trữ prompt trong bộ nhớ đệm thuộc về quyết định định tuyến
Lưu trữ prompt trong bộ nhớ đệm có thể thay đổi tính kinh tế của các prompt dài lặp đi lặp lại. Tài liệu về lưu trữ prompt của OpenAI giải thích rằng các prompt dài đủ điều kiện có thể được hưởng lợi khi nội dung tĩnh xuất hiện trước và nội dung biến đổi xuất hiện sau; họ cũng hiển thị cached_tokens trong chi tiết sử dụng để các nhóm có thể theo dõi hành vi của bộ nhớ đệm.
Định tuyến cửa sổ ngữ cảnh nên coi khả năng lưu vào bộ nhớ đệm là một tín hiệu hàng đầu:
| Mẫu prompt | Hàm ý định tuyến |
|---|---|
| Chính sách hệ thống ổn định cộng với nhiều câu hỏi của người dùng | Đặt nội dung ổn định lên trước và đo lường tỷ lệ token được lưu trong bộ nhớ đệm |
| Gói tài liệu lớn lặp đi lặp lại | Xem xét tuyến ngữ cảnh dài có nhận biết bộ nhớ đệm |
| Dữ liệu dành riêng cho người dùng có tính động cao | Đừng cho rằng sẽ tiết kiệm được nhờ bộ nhớ đệm |
| Các định nghĩa công cụ được chia sẻ qua nhiều lệnh gọi | Giữ cho lược đồ công cụ ổn định nếu có thể |
| Prompt ngắn dưới ngưỡng lưu vào bộ nhớ đệm | Tối ưu hóa tuyến/mô hình trước; lưu vào bộ nhớ đệm có thể không hữu ích |
Các token được lưu trong bộ nhớ đệm có thể giảm chi phí hoặc độ trễ tùy thuộc vào hành vi của nhà cung cấp, nhưng chúng không làm cho cửa sổ ngữ cảnh trở nên vô hạn. Tài liệu của Anthropic đã chỉ ra sự khác biệt quan trọng này một cách trực tiếp: các tiền tố prompt được lưu trong bộ nhớ đệm vẫn có thể chiếm dụng cửa sổ ngữ cảnh. Chính sách định tuyến nên ghi lại các lần truy cập bộ nhớ đệm như bằng chứng về chi phí, chứ không phải là sự cho phép bỏ qua giới hạn token.
Dành không gian cho đầu ra, suy luận và công cụ
Định tuyến cửa sổ ngữ cảnh thường thất bại vì các nhóm chỉ đếm token đầu vào. Mô hình vẫn cần không gian để trả lời.
Đối với mỗi tuyến, hãy xác định:
- Token đầu vào tối đa: yêu cầu lớn nhất mà tuyến có thể chấp nhận.
- Token đầu ra dành riêng: không gian cho câu trả lời hiển thị, JSON, trích dẫn hoặc các đối số của công cụ.
- Token suy luận dành riêng: không gian bổ sung cho các mô hình suy luận hoặc các tác vụ khó.
- Chi phí công cụ: định nghĩa công cụ, lệnh gọi công cụ và kết quả công cụ.
- Biên độ an toàn: một vùng đệm cho sự thay đổi của tokenizer và sự gia tăng của prompt.
Sử dụng một bộ bảo vệ tuyến như sau:
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anywayCác con số trên là các giá trị giữ chỗ, không phải là giới hạn phổ quát. Phần quan trọng là hình dạng của lan can bảo vệ: tuyến có một giới hạn đầu vào, một khoản dự trữ cho câu trả lời, một khoản dự trữ cho suy luận và hành vi rõ ràng khi vượt quá ngân sách.
Kiểm soát chi phí cho định tuyến cửa sổ ngữ cảnh
Đừng chỉ đo lường chi phí trên mỗi token. Hãy đo lường chi phí trên mỗi kết quả được chấp nhận.
| Chỉ số chi phí | Tại sao nó quan trọng |
|---|---|
| Chi phí mỗi yêu cầu | Phát hiện các lệnh gọi đơn lẻ quá lớn |
| Chi phí mỗi câu trả lời được chấp nhận | Tính đến các lần thử lại, truy xuất kém và các lệnh gọi ngữ cảnh dài không thành công |
| Chi phí mỗi quy trình công việc | Hiển thị chi phí thực sự của một ticket, một bài đánh giá, một lần trích xuất hoặc một báo cáo |
| Chi phí mỗi chủ sở hữu | Kết nối việc sử dụng với ứng dụng, nhóm, khách hàng hoặc môi trường |
| Chi phí đầu vào đã điều chỉnh theo bộ nhớ đệm | Tách biệt các tiền tố ổn định lặp đi lặp lại khỏi ngữ cảnh động |
| Chi phí dự phòng | Cho thấy liệu phương án dự phòng đang cứu vãn độ tin cậy hay che giấu một tuyến chính tồi |
Bề mặt sản phẩm công khai của Flatkey có liên quan vì nó định vị nền tảng xoay quanh việc truy cập mô hình hợp nhất, định tuyến, thanh toán, phân tích sử dụng và kiểm soát vận hành. Việc kiểm tra API giá trực tiếp cho bài viết này vào ngày 2 tháng 7 năm 2026 đã trả về success: true và hiển thị các họ điểm cuối bao gồm openai, anthropic, gemini, image-generation, openai-video, và video. Hãy coi đó là bằng chứng đã lỗi thời cho việc lập kế hoạch định tuyến, không phải là lời hứa rằng mọi mô hình, giá cả hoặc điểm cuối sẽ không thay đổi.
Mẫu chính sách định tuyến cửa sổ ngữ cảnh
Đặt các quy tắc ở định dạng mà các bộ phận kỹ thuật, tài chính và mua sắm có thể xem xét.
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredMẫu này giúp cho việc định tuyến cửa sổ ngữ cảnh có thể kiểm thử được. Nếu tuyến đường thay đổi, chủ sở hữu có thể thấy lý do. Nếu prompt tăng lên, hàng rào bảo vệ có thể chặn nó. Nếu yêu cầu lặp lại, các chỉ số bộ nhớ đệm sẽ trở thành một phần của quá trình xem xét.
Kiểm thử nghiệm thu trước khi đưa vào sản xuất
Chạy các kiểm thử này trước khi bạn để định tuyến cửa sổ ngữ cảnh xử lý lưu lượng sản xuất:
- Gửi một prompt ngắn và xác nhận nó không đi vào tuyến ngữ cảnh dài.
- Gửi một prompt trò chuyện thông thường với các công cụ và xác nhận các định nghĩa và kết quả của công cụ được tính toán.
- Gửi một prompt tài liệu dài và xác minh không gian đầu ra dành riêng vẫn còn trống.
- Gửi một prompt vượt ngân sách và xác nhận tuyến đường sẽ tóm tắt, truy xuất hoặc yêu cầu giảm phạm vi thay vì gửi một cách mù quáng.
- Kích hoạt một tác vụ đòi hỏi nhiều suy luận và kiểm tra việc xử lý phản hồi không hoàn chỉnh.
- Lặp lại một prompt dài ổn định và xác nhận các chỉ số token được lưu trong bộ nhớ đệm được ghi lại khi nhà cung cấp hiển thị chúng.
- So sánh các câu trả lời ưu tiên truy xuất và ngữ cảnh đầy đủ trên cùng một bộ đánh giá.
- Xem xét mô hình được yêu cầu, mô hình đã phục vụ, họ điểm cuối, đơn vị sử dụng, lý do dự phòng và tác động đến chi phí hoặc số dư trong nhật ký.
Để có kiến trúc rộng hơn, hãy kết hợp các kiểm tra này với hướng dẫn của Flatkey về cổng API AI, kiến trúc cổng API LLM, cân bằng tải và chuyển đổi dự phòng API AI, và thiết kế chính sách định tuyến mô hình.
Vai trò của Flatkey
Flatkey không nên là nơi duy nhất tồn tại chính sách. Nó nên là nơi các nhóm có thể làm cho chính sách dễ chạy và xem xét hơn.
Sử dụng Flatkey để tập trung hóa việc truy cập mô hình, xem xét tuyến đường, kiểm tra giá hiện tại, khả năng hiển thị mức sử dụng, hạn ngạch, nhật ký yêu cầu và xem xét thanh toán. Sau đó, giữ chính sách định tuyến cửa sổ ngữ cảnh trong mã nguồn hoặc cấu hình để các quyết định định tuyến có thể lặp lại. Cổng cung cấp cho bộ phận tài chính và vận hành một nơi rõ ràng hơn để kiểm tra việc sử dụng; chính sách cho bộ phận kỹ thuật biết tuyến đường nào được phép.
Một lần chạy thử Flatkey thực tế sẽ trông như thế này:
- Chọn một quy trình công việc với các phạm vi kích thước prompt đã biết.
- Kiểm tra các tùy chọn mô hình và điểm cuối hiện tại trên bảng giá Flatkey.
- Chạy các prompt ngắn, bình thường, dài, vượt ngân sách và có thể lưu vào bộ nhớ đệm lặp lại.
- Xem xét nhật ký yêu cầu về quyết định định tuyến, mô hình đã phục vụ, mức sử dụng, các trường bộ nhớ đệm nếu có, lý do dự phòng và khóa chủ sở hữu.
- Xác nhận hạn ngạch và hành vi xem xét chi phí với chủ sở hữu quy trình công việc.
- Chỉ chuyển các tuyến đường đã được kiểm thử sang môi trường sản xuất, sau đó mở rộng định tuyến cửa sổ ngữ cảnh từng hàng một.
Khi quá trình thử nghiệm thành công, hãy lấy một khóa và giữ cho lần triển khai đầu tiên có phạm vi hẹp. Mục đích của định tuyến cửa sổ ngữ cảnh không phải là để tăng thêm sự phức tạp; mà là để ngăn chặn sự tăng trưởng của prompt âm thầm biến thành chi phí vượt kiểm soát, câu trả lời không hoàn chỉnh và các lựa chọn mô hình không thể xem xét.
Câu hỏi thường gặp
Định tuyến cửa sổ ngữ cảnh là gì?
Định tuyến cửa sổ ngữ cảnh là một chính sách lựa chọn tuyến đường mô hình, đường dẫn truy xuất, đường dẫn nén hoặc hành vi từ chối dựa trên kích thước prompt, dự trữ đầu ra, dự trữ suy luận, chi phí công cụ, kiểm soát chi phí và bằng chứng yêu cầu.
Định tuyến cửa sổ ngữ cảnh khác với định tuyến mô hình như thế nào?
Định tuyến mô hình có thể lựa chọn theo chất lượng, giá cả, độ trễ, phương thức, khu vực hoặc nhà cung cấp. Định tuyến cửa sổ ngữ cảnh tập trung vào việc liệu yêu cầu có phù hợp với ngân sách ngữ cảnh có thể sử dụng hay không và liệu một tuyến đường nhỏ hơn, ưu tiên truy xuất, được lưu trong bộ nhớ đệm hay ngữ cảnh dài có phải là lựa chọn kiểm soát chi phí đúng đắn hay không.
Khi nào một nhóm nên sử dụng truy xuất thay vì mô hình ngữ cảnh dài?
Sử dụng truy xuất khi câu trả lời phụ thuộc vào một phần nhỏ của một kho dữ liệu lớn, khi quyền truy cập quan trọng, hoặc khi việc nhập liệu ngữ cảnh đầy đủ lặp đi lặp lại sẽ tốn kém. Sử dụng ngữ cảnh dài khi tác vụ cần so sánh rộng rãi trên nhiều phần xa nhau của nguồn.
Tại sao cần dành riêng token cho đầu ra và suy luận?
Một prompt có thể vừa với phần đầu vào của cửa sổ ngữ cảnh nhưng vẫn thất bại vì không còn đủ chỗ cho việc suy luận hoặc câu trả lời hiển thị. Việc dành riêng token cho đầu ra và suy luận giúp giảm thiểu các phản hồi không hoàn chỉnh và chi tiêu lãng phí.
Việc lưu trữ prompt vào bộ nhớ đệm có loại bỏ sự cần thiết của định tuyến cửa sổ ngữ cảnh không?
Không. Việc lưu trữ prompt vào bộ nhớ đệm có thể giảm độ trễ hoặc chi phí đầu vào cho các tiền tố lặp lại, nhưng các token đã được lưu trong bộ nhớ đệm vẫn cần được tính đến trong cửa sổ ngữ cảnh. Định tuyến cửa sổ ngữ cảnh nên ghi lại các chỉ số về token đã lưu trong bộ nhớ đệm trong khi vẫn thực thi các giới hạn ngân sách.
Flatkey giúp ích như thế nào với việc định tuyến cửa sổ ngữ cảnh?
Flatkey cung cấp cho các nhóm một bề mặt cổng vào duy nhất để truy cập mô hình, xem xét định tuyến, kiểm tra giá cả, phân tích sử dụng, ghi lại yêu cầu, hạn ngạch và xem xét thanh toán. Điều đó giúp việc xác thực trở nên dễ dàng hơn liệu việc định tuyến cửa sổ ngữ cảnh có đang kiểm soát kích thước prompt và chi phí như đã thiết kế hay không.