Prompts longos não são automaticamente um problema de contexto longo. Alguns prompts devem ser encurtados, outros devem usar recuperação (retrieval), outros devem reservar mais espaço para a saída e alguns realmente precisam de uma janela de contexto maior. O roteamento por janela de contexto é a política que decide qual caminho uma solicitação deve seguir antes de gastar orçamento no modelo errado.
O objetivo é simples: rotear pelo tamanho real do prompt, pelo formato da resposta necessária e pelas evidências que você precisa para o controle de custos. Uma conversa de suporte de 6.000 tokens, uma revisão de contrato de 70.000 tokens e uma varredura de código-fonte de 900.000 tokens não deveriam compartilhar uma rota padrão apenas porque todos cabem atrás da mesma chave de API.
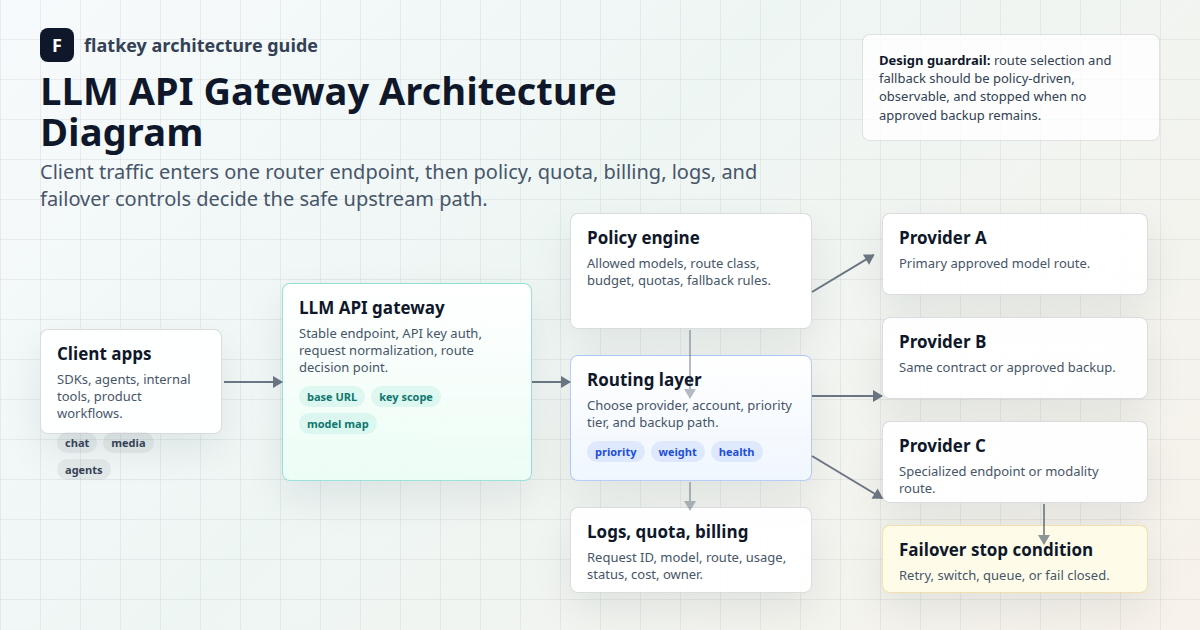
O Flatkey é útil neste design porque o acesso a modelos, o roteamento, a revisão de uso, o faturamento e os controles operacionais são mais fáceis de gerenciar a partir de uma única superfície de gateway do que de contas de provedores dispersas. Use a estrutura abaixo para projetar regras de roteamento por janela de contexto e, em seguida, valide a linha do modelo atual, a família de endpoints e a unidade de uso nos preços do Flatkey antes da implementação em produção.
O roteamento por janela de contexto começa com um orçamento de tokens
Comece cada decisão de rota com um orçamento, não com o nome de um modelo.
required_context =
system_and_policy_tokens
+ user_input_tokens
+ retrieved_or_attached_context_tokens
+ tool_schema_and_tool_result_tokens
+ conversation_history_tokens
+ reserved_output_tokens
+ reserved_reasoning_tokens
+ safety_margin_tokensA rota só é elegível se o contexto necessário couber na janela de contexto utilizável do modelo depois de você reservar espaço para saída e raciocínio. As orientações da OpenAI sobre modelos de raciocínio são um bom lembrete aqui: quando os tokens gerados atingem a janela de contexto ou o max_output_tokens, a resposta pode ficar incompleta, e as equipes devem deixar espaço para raciocínio e saída enquanto calibram a carga de trabalho.
Essa reserva é importante para o controle de custos. Se uma solicitação mal couber na janela de contexto, o modelo ainda pode falhar, truncar ou gastar muito em tokens de entrada antes de retornar uma resposta inutilizável. Um bom roteamento por janela de contexto protege contra isso, direcionando solicitações superdimensionadas para o caminho certo antes que a chamada seja feita.
Uma matriz de roteamento prática
Use esta matriz como uma primeira abordagem para o roteamento por janela de contexto. Ajuste os limites com base em suas contagens reais de tokens, catálogo de modelos, SLOs de latência e avaliações de qualidade.
| Classe de prompt | Sinal típico | Rota recomendada | Regra de controle de custos | Evidência necessária |
|---|---|---|---|---|
| Tarefa curta | Prompt pequeno, resposta pequena, sem histórico longo | Rota rápida de baixo custo | Evitar modelos de contexto longo, a menos que as avaliações exijam | Tokens de prompt, tokens de saída, taxa de sucesso |
| Chat normal | Histórico moderado, ferramentas ou resposta estruturada | Rota equilibrada com suporte a ferramentas e esquemas | Limitar por conversa ou proprietário | Modelo servido, tamanho do resultado da ferramenta, taxa de esquema válido |
| Documento longo | Arquivo grande, transcrição, política ou contrato | Rota de contexto longo ou rota de recuperação | Comparar o custo do contexto completo com o custo da recuperação | Tokens de entrada, trechos citados, qualidade da resposta |
| Corpus enorme | Muitos arquivos, código-fonte, logs ou arquivo morto | Recuperação, divisão (chunking), compactação e, em seguida, rota seletiva de contexto longo | Não preencher o corpus por padrão | Pedaços recuperados, contexto descartado, taxa de acerto do cache |
| Prompt com muito raciocínio | Tarefa longa mais planejamento, ferramentas ou raciocínio de código | Rota com reserva explícita para saída e raciocínio | Reservar espaço de saída antes de enviar o prompt | Taxa de incompletude, tokens de raciocínio/saída, latência p95 |
| Revisão de conformidade ou financeira | Conteúdo sensível e requisitos de auditoria | Rota revisada e fixada | Bloquear fallback automático, a menos que aprovado | Modelo solicitado, modelo servido, proprietário, rastreamento de custo |
Isso é o roteamento por janela de contexto em forma operacional: cada classe tem uma rota, uma regra de custo e uma prova de que a rota funcionou.
Não use a maior janela de contexto como padrão
Janelas de contexto grandes são úteis. Elas não são um substituto gratuito para o roteamento.
A documentação de contexto longo do Gemini do Google descreve janelas de contexto de 1 milhão de tokens e explica como o contexto longo pode desbloquear fluxos de trabalho que antes precisavam de sumarização, recuperação ou filtragem. A documentação de janela de contexto da Anthropic descreve o contexto como a memória de trabalho que inclui o conteúdo da solicitação, resultados de ferramentas, documentos, definições de ferramentas e saída. Ambos os pontos são importantes: janelas maiores expandem o que é possível, mas tudo o que você coloca na janela ainda precisa ser pago, validado e registrado.
O padrão mais seguro não é "enviar tudo". O padrão mais seguro é:
- Manter prompts curtos em rotas eficientes.
- Usar recuperação quando a resposta depende de uma pequena fatia de um corpus grande.
- Usar contexto longo quando o modelo precisa comparar muitas partes da fonte de uma só vez.
- Reservar orçamento para saída e raciocínio antes de chamar um modelo de raciocínio.
- Registrar detalhes de uso suficientes para comparar o custo por resultado aceito.
Esse é o núcleo do controle de custos do roteamento por janela de contexto.
Quando a recuperação supera o contexto longo
A recuperação geralmente é melhor quando a tarefa tem uma necessidade de evidência restrita. Exemplos incluem "encontre a cláusula de renovação", "resuma este incidente a partir das três linhas de log relevantes" ou "responda com base na documentação atual da API". Nesses casos, enviar o contrato inteiro, o arquivo de log ou o site de documentação pode aumentar o custo sem melhorar a precisão.
Use a recuperação quando:
- A resposta deve citar um pequeno número de passagens.
- A maior parte do corpus é irrelevante para a pergunta do usuário.
- O mesmo corpus é consultado repetidamente por muitos usuários.
- Você precisa restringir a exposição de dados por locatário, projeto, equipe ou permissão.
- O custo da entrada de contexto completo superaria o valor da resposta.
O roteamento por janela de contexto deve enviar a solicitação primeiro pela recuperação e, em seguida, passar apenas os trechos selecionados, metadados e instruções para o modelo. Registre os IDs da fonte recuperada, a contagem de tokens e o resultado de aceitação da resposta. Se a resposta falhar por falta de contexto, promova esse fluxo de trabalho para uma rota de contexto maior e registre o motivo.
Quando o contexto longo supera a recuperação
O contexto longo é mais eficaz quando a tarefa exige uma comparação ampla. Exemplos incluem a revisão de um conjunto completo de políticas em busca de contradições, a análise de uma transcrição completa, a comparação de seções em um contrato extenso ou o uso de um repositório inteiro como conjunto de referência para uma tarefa de planejamento.
Use uma rota de contexto longo quando:
- A tarefa depende de relações entre muitas seções distantes.
- O modelo precisa da estrutura completa do documento, não apenas de passagens isoladas.
- A qualidade da recuperação é difícil de verificar antes da geração.
- A fonte é um único artefato delimitado, como um PDF, uma transcrição ou um pacote de código.
- O valor esperado da resposta justifica o maior custo de entrada.
Mesmo assim, o roteamento por janela de contexto não deve pular as verificações de custo. Meça os tokens de entrada totais, os tokens em cache, se disponíveis, os tokens de saída, a latência, a taxa de novas tentativas e a taxa de respostas aceitas. A política de roteamento deve provar que a rota de contexto longo foi melhor do que a recuperação, e não apenas mais fácil de implementar.
O cache de prompts faz parte da decisão de rota
O cache de prompts pode mudar a economia de prompts longos e repetidos. A documentação de cache de prompts da OpenAI explica que prompts longos elegíveis podem se beneficiar quando o conteúdo estático aparece primeiro e o conteúdo variável aparece depois; eles também expõem cached_tokens nos detalhes de uso para que as equipes possam monitorar o comportamento do cache.
O roteamento por janela de contexto deve tratar a capacidade de cache como um sinal de primeira classe:
| Padrão de prompt | Implicação de roteamento |
|---|---|
| Política de sistema estável mais muitas perguntas de usuários | Coloque o conteúdo estável primeiro e meça a participação de tokens em cache |
| Pacote de documentação grande e repetido | Considere uma rota de contexto longo ciente do cache |
| Dados altamente dinâmicos e específicos do usuário | Não presuma economia com o cache |
| Definições de ferramentas compartilhadas em muitas chamadas | Mantenha os esquemas de ferramentas estáveis sempre que possível |
| Prompt curto abaixo do limite de cache | Otimize a rota/modelo primeiro; o cache pode não ajudar |
Os tokens em cache podem reduzir o custo ou a latência, dependendo do comportamento do provedor, mas não tornam a janela de contexto infinita. A documentação da Anthropic faz a distinção importante diretamente: os prefixos de prompt em cache ainda podem ocupar a janela de contexto. A política de roteamento deve registrar os acertos de cache como evidência de custo, não como permissão para ignorar os limites de tokens.
Reserve espaço para saída, raciocínio e ferramentas
O roteamento por janela de contexto geralmente falha porque as equipes contam apenas os tokens de entrada. O modelo ainda precisa de espaço para responder.
Para cada rota, defina:
- Tokens de entrada máximos: a maior solicitação que a rota pode aceitar.
- Tokens de saída reservados: espaço para a resposta visível, JSON, citações ou argumentos de ferramentas.
- Tokens de raciocínio reservados: espaço extra para modelos de raciocínio ou tarefas difíceis.
- Sobrecarga de ferramentas: definições de ferramentas, chamadas de ferramentas e resultados de ferramentas.
- Margem de segurança: um buffer para a variação do tokenizador e o crescimento do prompt.
Use um protetor de rota como este:
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anywayOs números acima são espaços reservados, não limites universais. A parte importante é a forma da barreira de proteção: a rota tem um teto de entrada, reserva de resposta, reserva de raciocínio e um comportamento explícito para quando o orçamento é excedido.
Controles de custo para o roteamento por janela de contexto
Não meça o custo apenas por token. Meça o custo por resultado aceito.
| Métrica de custo | Por que é importante |
|---|---|
| Custo por solicitação | Detecta chamadas únicas superdimensionadas |
| Custo por resposta aceita | Leva em conta novas tentativas, recuperação ruim e chamadas de contexto longo com falha |
| Custo por fluxo de trabalho | Mostra o custo real de um tíquete, revisão, extração ou relatório |
| Custo por proprietário | Conecta o uso ao aplicativo, equipe, cliente ou ambiente |
| Custo de entrada ajustado pelo cache | Separa prefixos estáveis repetidos do contexto dinâmico |
| Custo de fallback | Mostra se o fallback está resgatando a confiabilidade ou ocultando uma rota principal ruim |
A superfície pública do produto da Flatkey é relevante porque posiciona a plataforma em torno de acesso unificado a modelos, roteamento, faturamento, análise de uso e controles operacionais. A verificação da API de preços em tempo real para este artigo em 2 de julho de 2026 retornou success: true e expôs famílias de endpoints, incluindo openai, anthropic, gemini, image-generation, openai-video e video. Considere isso como uma evidência datada para o planejamento de rotas, não uma promessa de que todos os modelos, preços ou endpoints permanecerão inalterados.
Um modelo de política de roteamento por janela de contexto
Coloque as regras em um formato que engenharia, finanças e compras possam revisar.
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredEste modelo torna o roteamento por janela de contexto testável. Se a rota mudar, o proprietário pode ver o porquê. Se o prompt crescer, a barreira de proteção pode bloqueá-lo. Se a solicitação se repetir, as métricas de cache se tornam parte da revisão.
Testes de aceitação antes da produção
Execute estes testes antes de permitir que o roteamento por janela de contexto lide com o tráfego de produção:
- Envie um prompt curto e confirme que ele permanece fora da rota de contexto longo.
- Envie um prompt de chat normal com ferramentas e confirme que as definições e os resultados das ferramentas são contados.
- Envie um prompt de documento longo e verifique se o espaço de saída reservado permanece disponível.
- Envie um prompt acima do orçamento e confirme que a rota resume, recupera ou solicita uma redução de escopo em vez de enviar cegamente.
- Acione uma tarefa com uso intensivo de raciocínio e verifique o tratamento de respostas incompletas.
- Repita um prompt longo e estável e confirme que as métricas de tokens em cache são registradas quando o provedor as expõe.
- Compare as respostas de recuperação primeiro e de contexto completo no mesmo conjunto de avaliação.
- Revise o modelo solicitado, o modelo servido, a família de endpoints, as unidades de uso, o motivo do fallback e o impacto no custo ou saldo nos logs.
Para uma arquitetura mais ampla, combine essas verificações com os guias da Flatkey sobre gateways de API de IA, arquitetura de gateway de API de LLM, balanceamento de carga e failover de API de IA e design de política de roteamento de modelos.
Onde a Flatkey se encaixa
A Flatkey não deve ser o único lugar onde a política existe. Deve ser o lugar onde as equipes podem tornar a política mais fácil de executar e revisar.
Use a Flatkey para centralizar o acesso a modelos, revisão de rotas, verificações de preços atuais, visibilidade de uso, cotas, logs de solicitações e revisão de faturamento. Em seguida, mantenha a política de roteamento por janela de contexto em código ou configuração para que as decisões de rota sejam repetíveis. O gateway oferece a finanças e operações um lugar mais claro para inspecionar o uso; a política informa à engenharia qual rota é permitida.
Uma prova de conceito prática com a Flatkey se parece com isto:
- Escolha um fluxo de trabalho com faixas de tamanho de prompt conhecidas.
- Verifique as opções atuais de modelo e endpoint em preços da Flatkey.
- Execute prompts curtos, normais, longos, acima do orçamento e repetidos que possam ser armazenados em cache.
- Revise os logs de solicitação para decisão de rota, modelo servido, uso, campos de cache onde disponíveis, motivo do fallback e chave do proprietário.
- Confirme o comportamento da cota e da revisão de custos com o proprietário do fluxo de trabalho.
- Mova apenas as rotas testadas para a produção e, em seguida, expanda o roteamento por janela de contexto linha por linha.
Quando a prova de conceito for aprovada, obtenha uma chave e mantenha o primeiro lançamento restrito. O objetivo do roteamento por janela de contexto não é adicionar complexidade; é impedir que o crescimento do prompt se transforme silenciosamente em custos descontrolados, respostas incompletas e escolhas de modelo não revisáveis.
FAQ
O que é roteamento por janela de contexto?
O roteamento por janela de contexto é uma política que escolhe a rota do modelo, o caminho de recuperação, o caminho de compactação ou o comportamento de rejeição com base no tamanho do prompt, reserva de saída, reserva de raciocínio, sobrecarga de ferramentas, controles de custo e evidências necessárias.
Como o roteamento por janela de contexto é diferente do roteamento de modelos?
O roteamento de modelos pode escolher por qualidade, preço, latência, modalidade, região ou provedor. O roteamento por janela de contexto foca em se a solicitação se encaixa no orçamento de contexto utilizável e se uma rota menor, de recuperação primeiro, em cache ou de contexto longo é a escolha certa para o controle de custos.
Quando uma equipe deve usar recuperação em vez de um modelo de contexto longo?
Use a recuperação quando a resposta depender de uma pequena parte de um grande corpus, quando as permissões forem importantes ou quando a entrada repetida de contexto completo for cara. Use o contexto longo quando a tarefa precisar de uma comparação ampla entre muitas partes distantes da fonte.
Por que reservar tokens de saída e de raciocínio?
Um prompt pode caber no lado de entrada da janela de contexto e ainda assim falhar porque não há espaço suficiente restante para o raciocínio ou a resposta visível. Reservar tokens de saída e de raciocínio reduz respostas incompletas e gastos desperdiçados.
O cache de prompts remove a necessidade de roteamento por janela de contexto?
Não. O cache de prompts pode reduzir a latência ou o custo de entrada para prefixos repetidos, mas os tokens em cache ainda precisam ser considerados na janela de contexto. O roteamento por janela de contexto deve registrar métricas de tokens em cache enquanto ainda impõe limites de orçamento.
Como o Flatkey ajuda com o roteamento por janela de contexto?
O Flatkey oferece às equipes uma superfície de gateway única para acesso a modelos, revisão de rotas, verificações de preços, análise de uso, registros de solicitações, cotas e revisão de faturamento. Isso facilita a validação se o roteamento por janela de contexto está controlando o tamanho do prompt e o custo conforme projetado.