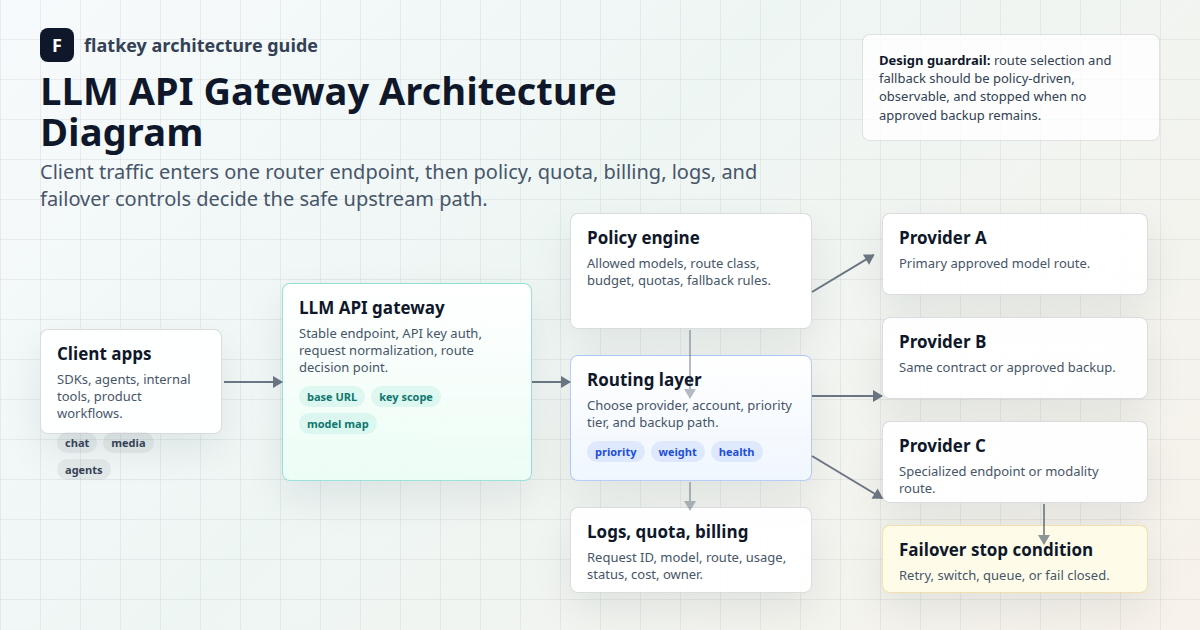
Les prompts longs ne sont pas automatiquement un problème de contexte long. Certains prompts doivent être raccourcis, d'autres doivent utiliser la recherche (retrieval), d'autres encore doivent réserver plus d'espace pour la sortie, et certains ont vraiment besoin d'une fenêtre de contexte plus grande. Le routage par fenêtre de contexte est la politique qui décide du chemin qu'une requête doit emprunter avant de gaspiller du budget sur le mauvais modèle.
L'objectif est simple : router en fonction de la taille réelle du prompt, de la forme de la réponse requise et des preuves dont vous avez besoin pour le contrôle des coûts. Une conversation de support de 6 000 tokens, une revue de contrat de 70 000 tokens et une analyse de base de code de 900 000 tokens ne devraient pas partager une seule route par défaut simplement parce qu'elles passent toutes par la même clé API.
Flatkey est utile dans cette conception car l'accès aux modèles, le routage, l'examen de l'utilisation, la facturation et les contrôles opérationnels sont plus faciles à gérer depuis une seule interface de passerelle que depuis des comptes de fournisseurs dispersés. Utilisez le cadre ci-dessous pour concevoir des règles de routage par fenêtre de contexte, puis validez la ligne de modèle actuelle, la famille de points de terminaison et l'unité d'utilisation sur la page tarifs de Flatkey avant le déploiement en production.
Le routage par fenêtre de contexte commence par un budget de tokens
Commencez chaque décision de routage avec un budget, pas un nom de modèle.
contexte_requis =
tokens_système_et_politique
+ tokens_entrée_utilisateur
+ tokens_contexte_récupéré_ou_joint
+ tokens_schéma_outil_et_résultat_outil
+ tokens_historique_conversation
+ tokens_sortie_réservés
+ tokens_raisonnement_réservés
+ tokens_marge_sécuritéLa route n'est éligible que si le contexte requis correspond à la fenêtre de contexte utilisable du modèle après avoir réservé de l'espace pour la sortie et le raisonnement. Les recommandations d'OpenAI sur les modèles de raisonnement sont un bon rappel ici : lorsque les tokens générés atteignent la fenêtre de contexte ou max_output_tokens, la réponse peut devenir incomplète, et les équipes doivent laisser de la place pour le raisonnement et la sortie pendant qu'elles calibrent la charge de travail.
Cette réserve est importante pour le contrôle des coûts. Si une requête entre à peine dans la fenêtre de contexte, le modèle peut toujours échouer, tronquer ou dépenser beaucoup en tokens d'entrée avant de renvoyer une réponse inutilisable. Un bon routage par fenêtre de contexte protège contre cela en dirigeant les requêtes surdimensionnées vers le bon chemin avant que l'appel ne soit effectué.
Une matrice de routage pratique
Utilisez cette matrice comme première approche pour le routage par fenêtre de contexte. Ajustez les seuils en fonction de vos décomptes de tokens réels, de votre catalogue de modèles, de vos SLO de latence et de vos évaluations de qualité.
| Classe de prompt | Signal typique | Route recommandée | Règle de contrôle des coûts | Preuve requise |
|---|---|---|---|---|
| Tâche courte | Prompt court, réponse courte, pas d'historique long | Route rapide à faible coût | Éviter les modèles à contexte long sauf si les évaluations l'exigent | Tokens de prompt, tokens de sortie, taux de réussite |
| Chat normal | Historique modéré, outils ou réponse structurée | Route équilibrée avec prise en charge des outils et des schémas | Plafonner par conversation ou propriétaire | Modèle servi, taille du résultat de l'outil, taux de validité du schéma |
| Document long | Fichier volumineux, transcription, politique ou contrat | Route à contexte long ou route de recherche (retrieval) | Comparer le coût du contexte complet au coût de la recherche (retrieval) | Tokens d'entrée, extraits cités, qualité de la réponse |
| Corpus énorme | Nombreux fichiers, base de code, journaux ou archives | Recherche (retrieval), découpage (chunking), compactage, puis route sélective à contexte long | Ne pas surcharger le corpus par défaut | Morceaux récupérés, contexte abandonné, taux de succès du cache |
| Prompt à fort raisonnement | Tâche longue plus planification, outils ou raisonnement sur le code | Route avec réserve explicite pour la sortie et le raisonnement | Réserver l'espace de sortie avant d'envoyer le prompt | Taux d'incomplétude, tokens de raisonnement/sortie, latence p95 |
| Examen de conformité ou financier | Contenu sensible et exigences d'audit | Route examinée et épinglée | Bloquer le repli automatique sauf approbation | Modèle demandé, modèle servi, propriétaire, trace des coûts |
Ceci est le routage par fenêtre de contexte sous forme opérationnelle : chaque classe a une route, une règle de coût et la preuve que la route a fonctionné.
N'utilisez pas la plus grande fenêtre de contexte par défaut
Les grandes fenêtres de contexte sont utiles. Elles ne remplacent pas gratuitement le routage.
La documentation de Google sur le contexte long de Gemini décrit des fenêtres de contexte de 1 million de tokens et explique comment le contexte long peut débloquer des flux de travail qui nécessitaient auparavant un résumé, une recherche (retrieval) ou un filtrage. La documentation d'Anthropic sur les fenêtres de contexte décrit le contexte comme la mémoire de travail qui inclut le contenu de la requête, les résultats des outils, les documents, les définitions des outils et la sortie. Ces deux points sont importants : des fenêtres plus grandes élargissent les possibilités, mais tout ce que vous placez dans la fenêtre doit toujours être payé, validé et enregistré.
Le paramètre par défaut le plus sûr n'est pas "tout envoyer". Le paramètre par défaut plus sûr est :
- Conserver les prompts courts sur des routes efficaces.
- Utiliser la recherche (retrieval) lorsque la réponse dépend d'une petite partie d'un grand corpus.
- Utiliser un contexte long lorsque le modèle doit comparer de nombreuses parties de la source en même temps.
- Réserver un budget pour la sortie et le raisonnement avant d'appeler un modèle de raisonnement.
- Enregistrer suffisamment de détails d'utilisation pour comparer le coût par résultat accepté.
C'est le cœur du contrôle des coûts du routage par fenêtre de contexte.
Quand la recherche (retrieval) l'emporte sur le contexte long
L'extraction est généralement plus efficace lorsque la tâche nécessite une preuve ciblée. Par exemple : « trouver la clause de renouvellement », « résumer cet incident à partir des trois lignes de journal pertinentes » ou « répondre à partir de la documentation actuelle de l'API ». Dans ces cas, l'envoi de l'intégralité du contrat, de l'archive des journaux ou du site de documentation peut augmenter les coûts sans améliorer la précision.
Utilisez l'extraction lorsque :
- La réponse doit citer un petit nombre de passages.
- La majeure partie du corpus n'est pas pertinente pour la question de l'utilisateur.
- Le même corpus est interrogé à plusieurs reprises par de nombreux utilisateurs.
- Vous devez restreindre l'exposition des données par locataire, projet, équipe ou autorisation.
- Le coût de la saisie du contexte complet dépasserait la valeur de la réponse.
Le routage par fenêtre de contexte doit d'abord envoyer la requête via l'extraction, puis ne transmettre au modèle que les morceaux, métadonnées et instructions sélectionnés. Enregistrez les ID de source extraits, le nombre de jetons et le résultat d'acceptation de la réponse. Si la réponse échoue car il manque trop de contexte, faites passer ce flux de travail à une route de contexte plus large et enregistrez la raison.
Quand le contexte long l'emporte sur l'extraction
Le contexte long est plus puissant lorsque la tâche nécessite une comparaison étendue. Par exemple, l'examen d'un ensemble complet de politiques pour y déceler des contradictions, l'analyse d'une transcription complète, la comparaison de sections dans un contrat volumineux ou l'utilisation d'un référentiel entier comme ensemble de références pour une tâche de planification.
Utilisez une route de contexte long lorsque :
- La tâche dépend des relations entre de nombreuses sections éloignées.
- Le modèle a besoin de la structure complète du document, pas seulement de passages isolés.
- La qualité de l'extraction est difficile à vérifier avant la génération.
- La source est un artefact unique et délimité, tel qu'un PDF, une transcription ou un ensemble de code.
- La valeur attendue de la réponse justifie le coût d'entrée plus élevé.
Même dans ce cas, le routage par fenêtre de contexte ne doit pas ignorer les vérifications de coûts. Mesurez le nombre total de jetons d'entrée, les jetons mis en cache si disponibles, les jetons de sortie, la latence, le taux de nouvelles tentatives et le taux de réponses acceptées. La politique de routage doit prouver que la route de contexte long était meilleure que l'extraction, et pas seulement plus facile à mettre en œuvre.
La mise en cache des prompts fait partie de la décision de routage
La mise en cache des prompts peut modifier l'économie des prompts longs et répétés. La documentation d'OpenAI sur la mise en cache des prompts explique que les prompts longs éligibles peuvent en bénéficier lorsque le contenu statique apparaît en premier et le contenu variable plus tard ; elle expose également les cached_tokens dans les détails d'utilisation afin que les équipes puissent surveiller le comportement du cache.
Le routage par fenêtre de contexte doit traiter la possibilité de mise en cache comme un signal de premier ordre :
| Modèle de prompt | Implication pour le routage |
|---|---|
| Politique système stable plus de nombreuses questions d'utilisateurs | Mettre le contenu stable en premier et mesurer la part de jetons mis en cache |
| Ensemble de documentation volumineux et répété | Envisager une route de contexte long sensible au cache |
| Données hautement dynamiques et spécifiques à l'utilisateur | Ne pas présumer d'économies grâce au cache |
| Définitions d'outils partagées entre de nombreux appels | Garder les schémas d'outils stables lorsque c'est possible |
| Prompt court en dessous du seuil de mise en cache | Optimiser d'abord la route/le modèle ; la mise en cache peut ne pas aider |
Les jetons mis en cache peuvent réduire les coûts ou la latence en fonction du comportement du fournisseur, mais ils ne rendent pas la fenêtre de contexte infinie. La documentation d'Anthropic fait directement cette distinction importante : les préfixes de prompt mis en cache peuvent toujours occuper la fenêtre de contexte. La politique de routage doit enregistrer les réussites de cache comme une preuve de coût, et non comme une autorisation d'ignorer les limites de jetons.
Réserver de l'espace pour la sortie, le raisonnement et les outils
Le routage par fenêtre de contexte échoue souvent parce que les équipes ne comptent que les jetons d'entrée. Le modèle a toujours besoin de place pour répondre.
Pour chaque route, définissez :
- Jetons d'entrée maximum : la plus grande requête que la route peut accepter.
- Jetons de sortie réservés : espace pour la réponse visible, le JSON, les citations ou les arguments d'outils.
- Jetons de raisonnement réservés : espace supplémentaire pour les modèles de raisonnement ou les tâches difficiles.
- Surcharge des outils : définitions d'outils, appels d'outils et résultats d'outils.
- Marge de sécurité : un tampon pour la variance du tokenizer et la croissance du prompt.
Utilisez une protection de route comme celle-ci :
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anywayLes chiffres ci-dessus sont des exemples, pas des limites universelles. L'important est la forme de la protection : la route a un plafond d'entrée, une réserve pour la réponse, une réserve pour le raisonnement et un comportement explicite en cas de dépassement de budget.
Contrôles des coûts pour le routage par fenêtre de contexte
Ne mesurez pas le coût uniquement par jeton. Mesurez le coût par résultat accepté.
| Métrique de coût | Pourquoi c'est important |
|---|---|
| Coût par requête | Détecte les appels uniques surdimensionnés |
| Coût par réponse acceptée | Prend en compte les nouvelles tentatives, les extractions de mauvaise qualité et les échecs d'appels à contexte long |
| Coût par flux de travail | Montre le coût réel d'un ticket, d'une revue, d'une extraction ou d'un rapport |
| Coût par propriétaire | Relie l'utilisation à l'application, l'équipe, le client ou l'environnement |
| Coût d'entrée ajusté au cache | Sépare les préfixes stables répétés du contexte dynamique |
| Coût de repli | Indique si le repli sauve la fiabilité ou masque une mauvaise route principale |
La surface publique du produit Flatkey est pertinente car elle positionne la plateforme autour de l'accès unifié aux modèles, du routage, de la facturation, de l'analyse de l'utilisation et des contrôles opérationnels. La vérification de l'API de tarification en direct pour cet article le 2 juillet 2026 a renvoyé success: true et a exposé des familles de points de terminaison, notamment openai, anthropic, gemini, image-generation, openai-video et video. Considérez cela comme une preuve datée pour la planification des routes, et non comme une promesse que chaque modèle, prix ou point de terminaison restera inchangé.
Un modèle de politique de routage par fenêtre de contexte
Présentez les règles dans un format que l'ingénierie, la finance et les achats peuvent examiner.
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredCe modèle rend le routage par fenêtre de contexte testable. Si la route change, le propriétaire peut en voir la raison. Si le prompt s'allonge, la barrière de sécurité peut le bloquer. Si la requête se répète, les métriques de cache sont intégrées à l'examen.
Tests d'acceptation avant la mise en production
Exécutez ces tests avant de laisser le routage par fenêtre de contexte gérer le trafic de production :
- Envoyez un prompt court et confirmez qu'il n'emprunte pas la route à contexte long.
- Envoyez un prompt de chat normal avec des outils et confirmez que les définitions et les résultats des outils sont comptabilisés.
- Envoyez un prompt de document long et vérifiez que l'espace de sortie réservé reste disponible.
- Envoyez un prompt dépassant le budget et confirmez que la route résume, récupère ou demande une réduction de la portée au lieu d'envoyer aveuglément.
- Déclenchez une tâche nécessitant beaucoup de raisonnement et vérifiez la gestion des réponses incomplètes.
- Répétez un prompt long et stable et confirmez que les métriques de jetons mis en cache sont enregistrées lorsque le fournisseur les expose.
- Comparez les réponses basées sur la récupération d'informations (retrieval-first) et celles à contexte complet sur le même jeu d'évaluation.
- Examinez le modèle demandé, le modèle servi, la famille de points de terminaison, les unités d'utilisation, la raison du repli et l'impact sur le coût ou le solde dans les journaux.
Pour une architecture plus large, associez ces vérifications aux guides de Flatkey sur les passerelles d'API d'IA, l'architecture des passerelles d'API LLM, l'équilibrage de charge et le basculement des API d'IA et la conception de politiques de routage de modèles.
Le rôle de Flatkey
Flatkey ne doit pas être le seul endroit où la politique existe. Ce doit être l'endroit où les équipes peuvent rendre la politique plus facile à exécuter et à examiner.
Utilisez Flatkey pour centraliser l'accès aux modèles, l'examen des routes, les vérifications des prix actuels, la visibilité de l'utilisation, les quotas, les journaux de requêtes et l'examen de la facturation. Ensuite, conservez la politique de routage par fenêtre de contexte dans le code ou la configuration afin que les décisions de routage soient reproductibles. La passerelle offre à la finance et aux opérations un endroit plus clair pour inspecter l'utilisation ; la politique indique à l'ingénierie quelle route est autorisée.
Un test de validation pratique avec Flatkey se déroule comme suit :
- Choisissez un flux de travail avec des plages de taille de prompt connues.
- Vérifiez les options de modèles et de points de terminaison actuelles sur la page des tarifs de Flatkey.
- Exécutez des prompts courts, normaux, longs, dépassant le budget et répétitifs pouvant être mis en cache.
- Examinez les journaux de requêtes pour la décision de routage, le modèle servi, l'utilisation, les champs de cache disponibles, la raison du repli et la clé du propriétaire.
- Confirmez le comportement des quotas et de l'examen des coûts avec le propriétaire du flux de travail.
- Ne déplacez que les routes testées en production, puis étendez le routage par fenêtre de contexte ligne par ligne.
Lorsque le test est concluant, obtenez une clé et limitez la portée du premier déploiement. L'objectif du routage par fenêtre de contexte n'est pas d'ajouter de la complexité ; il s'agit d'empêcher que l'augmentation de la taille des prompts ne se transforme silencieusement en coûts exorbitants, en réponses incomplètes et en choix de modèles impossibles à examiner.
FAQ
Qu'est-ce que le routage par fenêtre de contexte ?
Le routage par fenêtre de contexte est une politique qui choisit la route du modèle, le chemin de récupération, le chemin de compactage ou le comportement de rejet en fonction de la taille du prompt, de la réserve de sortie, de la réserve de raisonnement, de la surcharge des outils, des contrôles de coûts et des preuves requises.
En quoi le routage par fenêtre de contexte est-il différent du routage de modèles ?
Le routage de modèles peut choisir en fonction de la qualité, du prix, de la latence, de la modalité, de la région ou du fournisseur. Le routage par fenêtre de contexte se concentre sur la question de savoir si la requête correspond au budget de contexte utilisable et si une route plus petite, basée sur la récupération d'informations (retrieval-first), mise en cache ou à contexte long est le bon choix pour le contrôle des coûts.
Quand une équipe doit-elle utiliser la récupération d'informations plutôt qu'un modèle à contexte long ?
Utilisez la récupération d'informations lorsque la réponse dépend d'une petite partie d'un grand corpus, lorsque les autorisations sont importantes ou lorsque des entrées répétées à contexte complet seraient coûteuses. Utilisez un contexte long lorsque la tâche nécessite une comparaison large entre de nombreuses parties éloignées de la source.
Pourquoi réserver des jetons pour la sortie et le raisonnement ?
Un prompt peut tenir dans la partie entrée de la fenêtre de contexte et tout de même échouer, car il ne reste pas assez de place pour le raisonnement ou la réponse visible. Réserver des jetons pour la sortie et le raisonnement réduit les réponses incomplètes et les dépenses inutiles.
La mise en cache des prompts supprime-t-elle le besoin de routage par fenêtre de contexte ?
Non. La mise en cache des prompts peut réduire la latence ou le coût d'entrée pour les préfixes répétés, mais les jetons mis en cache doivent toujours être pris en compte dans la fenêtre de contexte. Le routage par fenêtre de contexte doit enregistrer les métriques des jetons mis en cache tout en continuant d'appliquer les limites budgétaires.
Comment Flatkey aide-t-il avec le routage par fenêtre de contexte ?
Flatkey fournit aux équipes une passerelle unique pour l'accès aux modèles, l'examen des routes, la vérification des prix, l'analyse de l'utilisation, les journaux de requêtes, les quotas et l'examen de la facturation. Cela facilite la validation pour savoir si le routage par fenêtre de contexte contrôle la taille des prompts et les coûts comme prévu.